このドキュメントでは、AI Platform Prediction にデプロイされた機械学習(ML)モデルのオンライン サービング パフォーマンスのテストとモニタリングの方法について説明します。このドキュメントでは、負荷テスト用のオープンソース ツールである Locust を使用します。
このドキュメントは、本番環境での ML モデルのサービス ワークロード、レイテンシ、リソース使用率をモニタリングするデータ サイエンティストと MLOps エンジニア向けです。
このドキュメントは、 Google Cloud、TensorFlow、AI Platform Prediction、Cloud Monitoring、Jupyter ノートブックについて、ある程度経験があることを前提としています。
このドキュメントに付属の GitHub リポジトリに、このドキュメントで説明するシステムを実装するためのコードとデプロイガイドが含まれています。タスクは Jupyter ノートブックに組み込まれています。
費用
このドキュメントで扱うノートブックでは、 Google Cloudの次の課金対象のコンポーネントを使用します。
- Vertex AI Workbench ユーザー管理ノートブック
- AI Platform Prediction
- Cloud Storage
- Cloud Monitoring
- Google Kubernetes Engine(GKE)
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
アーキテクチャの概要
次の図は、オンライン予測用の ML モデルのデプロイ、負荷テストの実行、ML モデルのサービス パフォーマンスの指標の収集と分析を行うシステム アーキテクチャを示しています。
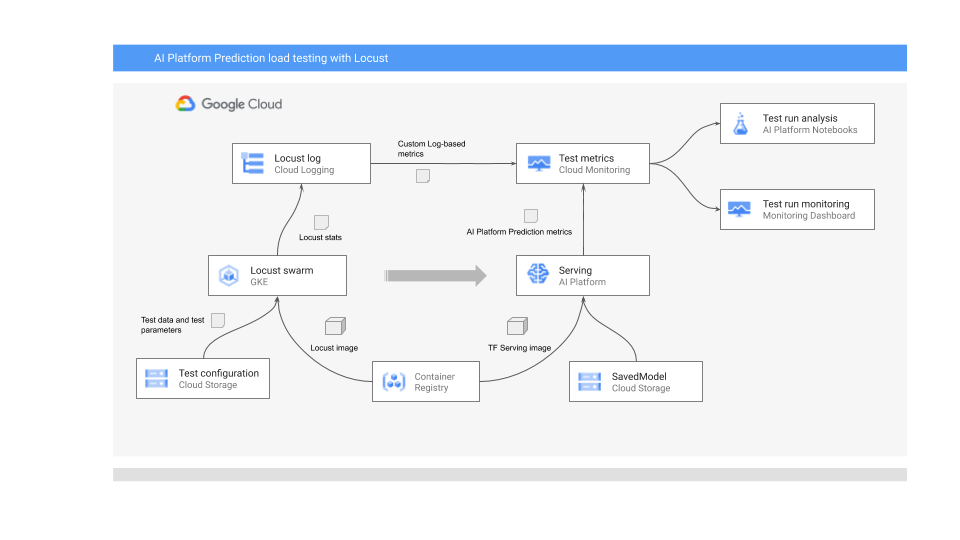
図は次のフローを示しています。
- トレーニング済みモデルは Cloud Storage 内にある場合もあります(TensorFlow SavedModel や scikit-learn joblib など)。また、Container Registry のカスタム サービング コンテナに組み込まれている場合もあります(PyTorch モデルを提供する TorchServe など)。
- モデルは、REST API として AI Platform Prediction にデプロイされています。AI Platform Prediction はモデル サービング用のフルマネージド サービスで、さまざまなマシンタイプに対応しています。また、リソース使用率に基づく自動スケーリングとさまざまな GPU アクセラレータをサポートしています。
- Locust は、テストタスク(つまり、ユーザーの行動)を実装するために使用されます。これは、AI Platform Prediction にデプロイされた ML モデルを呼び出して、Google Kubernetes Engine(GKE)上で大規模に実行することで実装します。これにより、モデル予測サービスの負荷テストのために、多くの同時ユーザー呼び出しがシミュレートされます。Locust ウェブ インターフェースを使用して、テストの進行状況をモニタリングできます。
- Locust は、テストの統計情報を Cloud Logging に記録します。Locust テストによって作成されたログエントリは、Cloud Monitoring で一連のログベースの指標を定義するために使用されます。これらの指標は、標準の AI Platform Prediction 指標を補完します。
- AI Platform の指標とカスタム Locust の指標のどちらも Cloud Monitoring ダッシュボードでのリアルタイムの可視化に使用できます。テストが終了すると、指標はプログラムで収集され、Vertex AI Workbench のユーザー管理のノートブックで指標を分析して可視化できます。
このシナリオの Jupyter ノートブック
モデルの準備とデプロイ、Locust テストの実行、テスト結果の収集と分析のすべてのタスクは、以下の Jupyter ノートブックでコード化されています。タスクを実施するには、各ノートブックで一連のセルを実行します。
01-prepare-and-deploy.ipynb。このノートブックを実行して、サービス提供用の TensorFlow SavedModel を作成し、モデルを AI Platform Prediction にデプロイします。02-perf-testing.ipynb。このノートブックを使用して、Locust テストの Cloud Monitoring にログベースの指標を作成し、Locust テストを GKE にデプロイして実行します。03-analyze-results.ipynb。このノートブックを実行して、Cloud Monitoring によって作成された標準の AI Platform 指標と Locust のカスタム指標から Locust の負荷テスト結果を収集、分析します。
環境を初期化する
関連する GitHub リポジトリの README.md ファイルで説明したように、ノートブックを実行する環境を準備するには、次の手順を実施する必要があります。
- Google Cloud プロジェクトでトレーニング済みモデルと Locust テスト構成を保存するために必要な Cloud Storage バケットを作成します。バケットで使用する名前は後で必要になるため、メモしておきます。
- プロジェクトに Cloud Monitoring ワークスペースを作成します。
- 必要な CPU を備えた Google Kubernetes Engine クラスタを作成します。ノードプールには Cloud APIs へのアクセス権が必要です。
- TensorFlow 2 を使用する Vertex AI Workbench のユーザー管理ノートブック インスタンスを作成します。このチュートリアルではモデルをトレーニングしないため、GPU は必要ありません(GPU は、特にモデルのトレーニングを高速化する場合のようなシナリオで役立ちます)。
JupyterLab を開く
このシナリオのタスクを行うには、JupyterLab 環境を開いてノートブックを取得する必要があります。
Google Cloud コンソールで [Notebooks] ページに移動します。
[ユーザー管理のノートブック] タブで、作成したノートブック環境の横にある [Jupyterlab を開く] をクリックします。
クリックすると、ブラウザで JupyterLab 環境が開きます。
ターミナル タブを起動するには、[ランチャー] タブの [ターミナル] アイコンをクリックします。
ターミナルで、
mlops-on-gcpGitHub リポジトリのクローンを作成します。git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.gitコマンドが終了すると、ファイル ブラウザに
mlops-on-gcpフォルダが表示されます。このドキュメントで扱うノートブックがフォルダに表示されます。
ノートブック設定の構成
このセクションでは、コンテキストに固有の値でノートブックに変数を設定し、このシナリオ用のコードを実行する環境を準備します。
model_serving/caip-load-testingディレクトリに移動します。- 3 つのノートブックのそれぞれに対して、次の操作を行います。
- ノートブックを開きます。
- [Configure Google Cloud environment settings] のセルを実行します。
以下のセクションでは、プロセスの重要な部分に焦点を当てて、設計とコードの特徴について説明します。
オンライン予測用のモデルの提供
このドキュメントで使用する ML モデルは、TensorFlow Hub の事前トレーニング済み ResNet V2 101 画像分類モデルを使用します。ただし、このドキュメントのシステム設計パターンと手法は、他のドメインやその他のタイプのモデルにも適応できます。
ResNet 101 モデルの準備と提供を行うコードは、01-prepare-and-deploy.ipynb ノートブックにあります。ノートブックのセルを実行して、次のタスクを実行します。
- TensorFlow Hub から ResNet モデルをダウンロードして実行します。
- モデルにサービス提供の署名を作成します。
- SavedModel としてモデルをエクスポートします。
- SavedModel を AI Platform Prediction にデプロイします。
- デプロイされたモデルを検証します。
このドキュメントの以降のセクションでは、ResNet モデルの作成とデプロイについて詳しく説明します。
デプロイする ResNet モデルを準備する
TensorFlow Hub からの ResNet モデルは、再構成と微調整に最適化されているため、サービス提供の署名がありません。したがって、モデルにサービス提供署名を作成して、オンライン予測用にモデルを提供できるようにする必要があります。
さらに、モデルを提供するには、特徴量エンジニアリング ロジックをサービス インターフェースに埋め込むことをおすすめします。こうすることで、必要な形式のデータを前処理するためのクライアント アプリケーションに依存する代わりに、前処理とモデル提供の間のアフィニティが保証されます。また、クラス ID をクラスラベルに変換するなど、後処理をサービス提供インターフェースに含める必要もあります。
ResNet モデルをサービス可能にするには、モデルの推論方法を記述するサービス提供署名を実装する必要があります。したがって、このノートブック コードは次の 2 つの署名を追加します。
- デフォルトの署名。この署名は、ResNet V2 101 モデルのデフォルトの
predictメソッドを公開します。デフォルト メソッドに前処理ロジックと後処理ロジックはありません。 - 前処理と後処理の署名。このインターフェースに対して想定される入力には、画像のエンコード、スケーリング、正規化など、比較的複雑な前処理が必要になります。そのため、モデルは、前処理と後処理のロジックが埋め込まれた代替署名も公開します。この署名は、未処理の画像を処理し、ランク付けされたクラスラベルとそれに関連するラベルの確率のリストを返します。
これらの署名はカスタム モジュール クラスで作成されます。このクラスは、ResNet モデルをカプセル化する tf.Module 基本クラスから派生しています。カスタムクラスは、画像の前処理と出力の後処理のロジックを実装するメソッドにより、基本クラスを拡張します。カスタム モジュールのデフォルト メソッドは、基本 ResNet モデルのデフォルト メソッドにマッピングされ、類似のインターフェースが維持されます。カスタム モジュールは、元のモデル、前処理ロジック、2 つのサービス提供署名を含む SavedModel としてエクスポートされます。
次のコード スニペットは、カスタム モジュール クラスの実装を示しています。
LABELS_KEY = 'labels'
PROBABILITIES_KEY = 'probabilities'
NUM_LABELS = 5
class ServingModule(tf.Module):
"""
A custom tf.Module that adds image preprocessing and output post processing to
a base TF 2 image classification model from TensorFlow Hub.
"""
def __init__(self, base_model, input_size, output_labels):
super(ServingModule, self).__init__()
self._model = base_model
self._input_size = input_size
self._output_labels = tf.constant(output_labels, dtype=tf.string)
def _decode_and_scale(self, raw_image):
"""
Decodes, crops, and resizes a single raw image.
"""
image = tf.image.decode_image(raw_image, dtype=tf.dtypes.uint8, expand_animations=False)
image_shape = tf.shape(image)
image_height = image_shape[0]
image_width = image_shape[1]
crop_size = tf.minimum(image_height, image_width)
offset_height = ((image_height - crop_size) + 1) // 2
offset_width = ((image_width - crop_size) + 1) // 2
image = tf.image.crop_to_bounding_box(image, offset_height, offset_width, crop_size, crop_size)
image = tf.image.resize(image, [self._input_size, self._input_size])
image = tf.cast(image, tf.uint8)
return image
def _preprocess(self, raw_inputs):
"""
Preprocesses raw inputs as sent by the client.
"""
# A mitigation for https://github.com/tensorflow/tensorflow/issues/28007
with tf.device('/cpu:0'):
images = tf.map_fn(self._decode_and_scale, raw_inputs, dtype=tf.uint8)
images = tf.image.convert_image_dtype(images, tf.float32)
return images
def _postprocess(self, model_outputs):
"""
Postprocess outputs returned by the base model.
"""
probabilities = tf.nn.softmax(model_outputs)
indices = tf.argsort(probabilities, axis=1, direction='DESCENDING')
return {
LABELS_KEY: tf.gather(self._output_labels, indices, axis=-1)[:,:NUM_LABELS],
PROBABILITIES_KEY: tf.sort(probabilities, direction='DESCENDING')[:,:NUM_LABELS]
}
@tf.function(input_signature=[tf.TensorSpec([None, 224, 224, 3], tf.float32)])
def __call__(self, x):
"""
A pass-through to the base model.
"""
return self._model(x)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def predict_labels(self, raw_images):
"""
Preprocesses inputs, calls the base model
and postprocess outputs from the base model.
"""
# Call the preprocessing handler
images = self._preprocess(raw_images)
# Call the base model
logits = self._model(images)
# Call the postprocessing handler
outputs = self._postprocess(logits)
return outputs
serving_module = ServingModule(model, 224, imagenet_labels)
次のコード スニペットは、以前に定義したサービス提供署名を使用して、SavedModel としてモデルをエクスポートする方法を示しています。
...
default_signature = serving_module.__call__.get_concrete_function()
preprocess_signature = serving_module.predict_labels.get_concrete_function()
signatures = {
'serving_default': default_signature,
'serving_preprocess': preprocess_signature
}
tf.saved_model.save(serving_module, model_path, signatures=signatures)
AI Platform Prediction にモデルをデプロイする
モデルが SavedModel としてエクスポートされると、次のタスクが実行されます。
- モデルが Cloud Storage にアップロードされます。
- AI Platform Prediction でモデル オブジェクトが作成されます。
- SavedModel 用にモデル バージョンが作成されます。
ノートブックの次のコード スニペットは、これらのタスクを実行するコマンドを示しています。
gcloud storage cp {model_path} {GCS_MODEL_LOCATION} --recursive
gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT_ID} \
--regions {REGION}
MACHINE_TYPE='n1-standard-8'
ACCELERATOR='count=1,type=nvidia-tesla-p4'
gcloud beta ai-platform versions create {MODEL_VERSION} \
--model={MODEL_NAME} \
--origin={GCS_MODEL_LOCATION} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--machine-type={MACHINE_TYPE} \
--accelerator={ACCELERATOR} \
--project={PROJECT_ID}
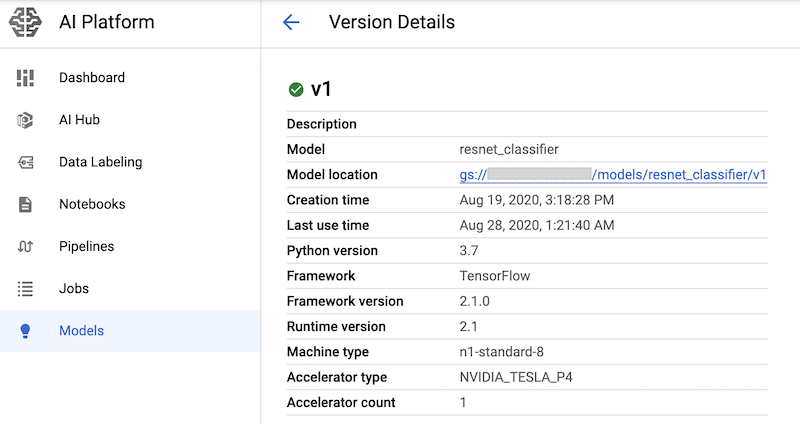
このコマンドは、nvidia-tesla-p4 GPU アクセラレータとともに、モデル予測サービス用の n1-standard-8 マシンタイプを作成します。
これらのコマンドを含むノートブック セルを実行した後、Google Cloud コンソールの AI Platform モデルページでモデル バージョンを表示することで、モデル バージョンがデプロイされていることを確認できます。出力は次のようになります。
Cloud Monitoring の指標の作成
サービス提供用のモデルを設定したら、サービス提供のパフォーマンスをモニタリングできる指標を構成できます。指標を構成するためのコードは 02-perf-testing.ipynb ノートブックにあります。
02-perf-testing.ipynb ノートブックの最初の部分では、Python Cloud Logging SDK を使用して Cloud Monitoring にカスタムのログベースの指標を作成します。指標は、Locust タスクによって生成されたログエントリに基づいています。log_stats メソッドは、ログエントリを locust という名前の Cloud Logging ログに書き込みます。
次の表に示すように、各ログエントリには JSON 形式の Key-Value ペアが含まれています。この指標は、ログエントリのキーのサブセットに基づいています。
| キー | 値の説明 | 使用量 |
|---|---|---|
test_id
|
テストの ID | 属性の フィルタ |
model |
AI Platform Prediction モデル名 | |
model_version |
AI Platform Prediction モデル バージョン | |
latency
|
95 パーセンタイルのレスポンス時間(10 秒のスライディング ウィンドウで計算) | 指標 値 |
num_requests |
テスト開始以降のリクエストの合計数 | |
num_failures |
テスト開始以降の失敗の合計数 | |
user_count |
シミュレーションが行われたユーザー数 | |
rps |
1 秒あたりのリクエスト数 |
次のコード スニペットは、カスタム ログベースの指標を作成するノートブック内の create_locust_metric 関数を示しています。
def create_locust_metric(
metric_name:str,
log_path:str,
value_field:str,
bucket_bounds:List[int]):
metric_path = logging_client.metric_path(PROJECT_ID, metric_name)
log_entry_filter = 'resource.type=global AND logName={}'.format(log_path)
metric_descriptor = {
'metric_kind': 'DELTA',
'value_type': 'DISTRIBUTION',
'labels': [{'key': 'test_id', 'value_type': 'STRING'},
{'key': 'signature', 'value_type': 'STRING'}]}
bucket_options = {
'explicit_buckets': {'bounds': bucket_bounds}}
value_extractor = 'EXTRACT(jsonPayload.{})'.format(value_field)
label_extractors = {
'test_id': 'EXTRACT(jsonPayload.test_id)',
'signature': 'EXTRACT(jsonPayload.signature)'}
metric = logging_v2.types.LogMetric(
name=metric_name,
filter=log_entry_filter,
value_extractor=value_extractor,
bucket_options=bucket_options,
label_extractors=label_extractors,
metric_descriptor=metric_descriptor,
)
try:
logging_client.get_log_metric(metric_path)
print('Metric: {} already exists'.format(metric_path))
except:
logging_client.create_log_metric(parent, metric)
print('Created metric {}'.format(metric_path))
次のコード スニペットは、ノートブックで create_locust_metric メソッドが呼び出され、上記の表に示されている 4 つのカスタム Locust 指標を作成する方法を示しています。
# user count metric
metric_name = 'locust_users'
value_field = 'user_count'
bucket_bounds = [1, 16, 32, 64, 128]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# latency metric
metric_name = 'locust_latency'
value_field = 'latency'
bucket_bounds = [1, 50, 100, 200, 500]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# failure count metric
metric_name = 'num_failures'
value_field = 'num_failures'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# request count metric
metric_name = 'num_requests'
value_field = 'num_requests'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
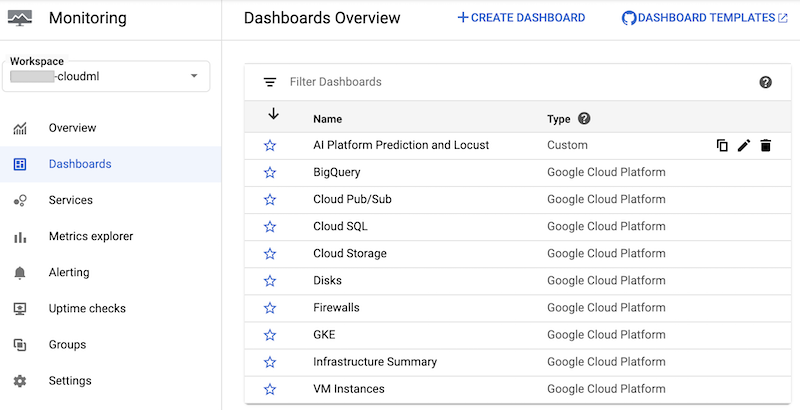
このノートブックは、AI Platform Prediction と Locust と呼ばれるカスタムの Cloud Monitoring ダッシュボードを作成します。ダッシュボードでは、標準の AI Platform Prediction 指標と Locust ログに基づいて作成されたカスタム指標が組み合わされています。
詳細については、Cloud Logging API のドキュメントをご覧ください。
このダッシュボードとそのグラフは手動で作成できます。
ただし、ノートブックでは、monitoring-template.json JSON テンプレートを使用してプログラムによって作成します。このコードは、次のコード スニペットに示すように、DashboardsServiceClient クラスを使用して JSON テンプレートを読み込み、Cloud Monitoring にダッシュボードを作成します。
parent = 'projects/{}'.format(PROJECT_ID)
dashboard_template_file = 'monitoring-template.json'
with open(dashboard_template_file) as f:
dashboard_template = json.load(f)
dashboard_proto = Dashboard()
dashboard_proto = ParseDict(dashboard_template, dashboard_proto)
dashboard = dashboard_service_client.create_dashboard(parent, dashboard_proto)
ダッシュボードを作成すると、Google Cloud コンソールの Cloud Monitoring ダッシュボードのリストで、そのダッシュボードを確認できます。
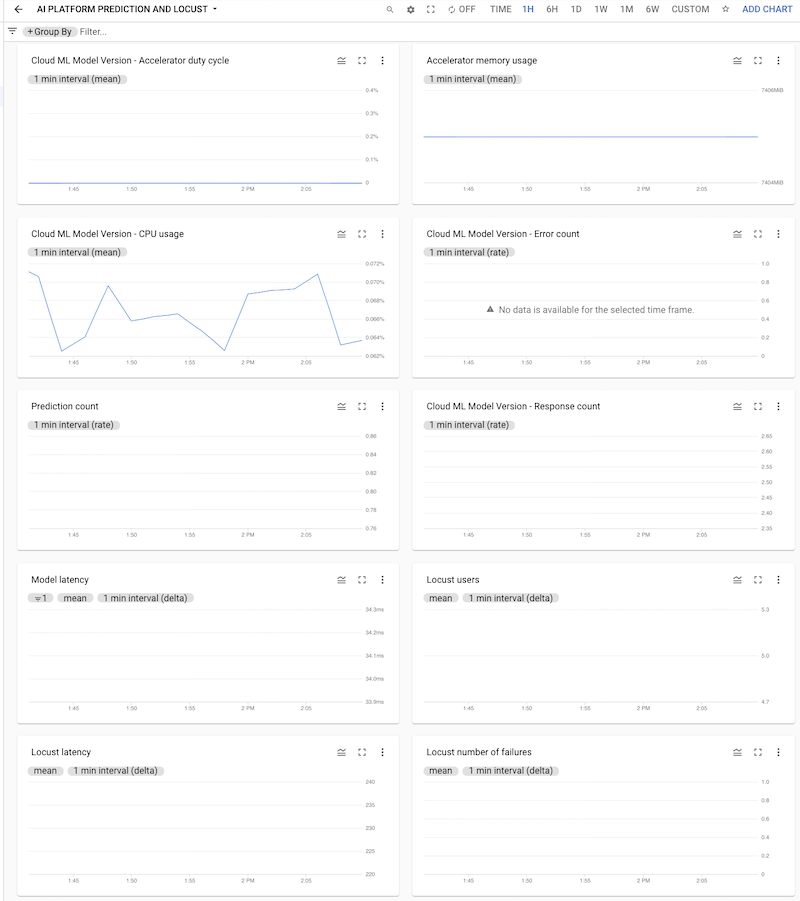
ダッシュボードをクリックして開くと、グラフを表示できます。次のスクリーンショットに示すように、各グラフには AI Platform Prediction または Locust のいずれかのログの指標が表示されます。
GKE クラスタへの Locust テストのデプロイ
Locust システムを GKE にデプロイする前に、task.py ファイルに組み込まれたテストロジックを含む Docker コンテナ イメージをビルドする必要があります。このイメージは baseline locust.io イメージから派生しており、Locust のマスター Pod とワーカー Pod に使用されます。
ビルドとデプロイのロジックは、ノートブックの 3. Locust を GKE クラスタにデプロイする」にあります。イメージは、次のコードを使用してビルドされます。
image_uri = 'gcr.io/{}/locust'.format(PROJECT_ID)
!gcloud builds submit --tag {image_uri} locust/locust-image
ノートブックで説明されているデプロイ プロセスは、Kustomize を使用して定義されています。Locust Kustomize デプロイ マニフェストでは、コンポーネントを定義する次のファイルを定義します。
locust-master。このファイルは、テストを開始してライブ統計情報を表示するウェブ インターフェースをホストするデプロイを定義します。locust-worker。このファイルは、ML モデル予測サービスの負荷テストを実行する Deployment を定義します。通常、複数のワーカーを作成すると、複数の同時ユーザーが予測サービス API を呼び出す影響をシミュレートできます。locust-worker-service。このファイルは、HTTP ロードバランサを通じてlocust-masterのウェブ インターフェースにアクセスするサービスを定義します。
クラスタをデプロイする前に、デフォルトのマニフェストを更新する必要があります。デフォルトのマニフェストは、kustomization.yaml ファイルと patch.yaml ファイルで構成されています。この両方のファイルを変更する必要があります。
kustomization.yaml ファイルで、次のことをします。
- Locust カスタム イメージの名前を設定します。
imagesセクションのnewNameフィールドに、前に作成したカスタム イメージの名前を設定します。 - 必要に応じて、ワーカー Pod の数を設定します。デフォルト構成では、32 個のワーカー Pod がデプロイされます。数を変更する場合は、
replicasセクションのcountフィールドを変更します。GKE クラスタに Locust ワーカー用の十分な CPU があることを確認します。 - テスト構成ファイルとペイロード ファイルの Cloud Storage バケットを設定します。
configMapGeneratorセクションで、次のものが設定されていることを確認します。LOCUST_TEST_BUCKET。前の手順で作成した Cloud Storage バケットの名前を設定します。LOCUST_TEST_CONFIG。テスト構成ファイルの名前を設定します。YAML ファイルでは、これはtest-config.jsonに設定されていますが、別の名前を使用したい場合は変更できます。LOCUST_TEST_PAYLOAD。テスト ペイロード ファイル名を設定します。YAML ファイルでは、これはtest-payload.jsonに設定されていますが、別の名前を使用したい場合は変更できます。
patch.yaml ファイルで、次のことをします。
- 必要に応じて、Locust マスターとワーカーをホストするノードプールを修正します。Locust ワークロードを
default-pool以外のノードプールにデプロイする場合は、matchExpressionsセクションを探して、valuesの下に移動し、Locust ワークロードをデプロイするノードプールの名前を更新します。
変更を行ったら、Kustomize マニフェストにカスタマイズを組み込んで Locust のデプロイ(locust-master、locust-worker、locust-master-service)を GKE クラスタに適用します。ノートブックの次のコマンドは、これらのタスクを実行します。
!kustomize build locust/manifests | kubectl apply -f -
デプロイされたワークロードは Google Cloud コンソールで確認できます。出力は次のようになります。
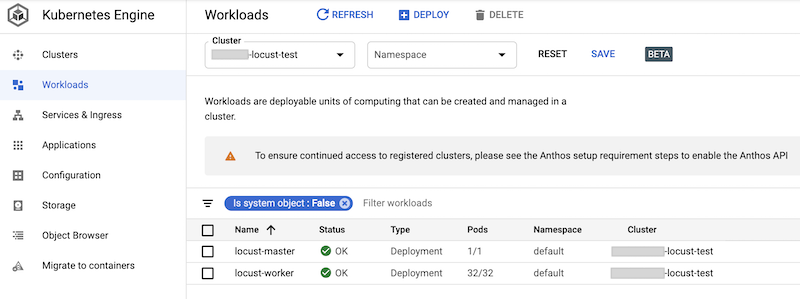
Locust 負荷テストの実装
Locust のテストタスクは、AI Platform Prediction にデプロイされたモデルを呼び出すことです。
このタスクは、/locust/locust-image/ フォルダ内にある task.py モジュールの AIPPClient クラスに実装されます。次のコード スニペットは、このクラスの実装を示しています。
class AIPPClient(object):
"""
A convenience wrapper around AI Platform Prediction REST API.
"""
def __init__(self, service_endpoint):
logging.info(
"Setting the AI Platform Prediction service endpoint: {}".format(service_endpoint))
credentials, _ = google.auth.default()
self._authed_session = AuthorizedSession(credentials)
self._service_endpoint = service_endpoint
def predict(self, project_id, model, version, signature, instances):
"""
Invokes the predict method on the specified signature.
"""
url = '{}/v1/projects/{}/models/{}/versions/{}:predict'.format(
self._service_endpoint, project_id, model, version)
request_body = {
'signature_name': signature,
'instances': instances
}
response = self._authed_session.post(url, data=json.dumps(request_body))
return response
task.py ファイル内の AIPPUser クラスは、locust.User クラスから継承して、AI Platform Prediction モデルを呼び出すユーザーの行動をシミュレートします。この行動は、predict_task メソッドに実装されます。AIPPUser クラスの on_start メソッドは、task.py ファイル内の LOCUST_TEST_BUCKET 変数で指定された Cloud Storage バケットから次のファイルをダウンロードします。
test-config.json。この JSON ファイルには、テスト用の次の構成が含まれています。test_id、project_id、model、version。test-payload.json。この JSON ファイルには、AI Platform Prediction で想定される形式のデータ インスタンスがターゲット署名とともに含まれています。
テストデータとテスト構成を準備するためのコードは、「4. Locust テストを構成する」の 02-perf-testing.ipynb ノートブックに含まれています。
テスト構成とデータ インスタンスは、AIPPClient クラスの predict メソッドのパラメータとして使用され、必要なテストデータを使用してターゲット モデルをテストします。AIPPUser は、単一ユーザーからの呼び出しの間の 1~2 秒の待機時間をシミュレートします。
Locust テストの実施
ノートブック セルを実行して Locust ワークロードを GKE クラスタにデプロイし、test-config.json ファイルと test-payload.json ファイルが作成されて Cloud Storage にアップロードされると、ウェブ インターフェースを使用して、新しい Locust 負荷テストを開始、停止、構成できます。ノートブックのコードは、次のコマンドを使用して、ウェブ インターフェースを公開する外部ロードバランサの URL を取得します。
%%bash
IP_ADDRESS=$(kubectl get service locust-master | awk -v col=4 'FNR==2{print $col}')
echo http://$IP_ADDRESS:8089
テストを実行するには、次の操作を行います。
- 取得した URL をブラウザに入力します。
さまざまな構成を使用してテスト ワークロードのシミュレーションを行うには、次のように Locust インターフェースに値を入力します。
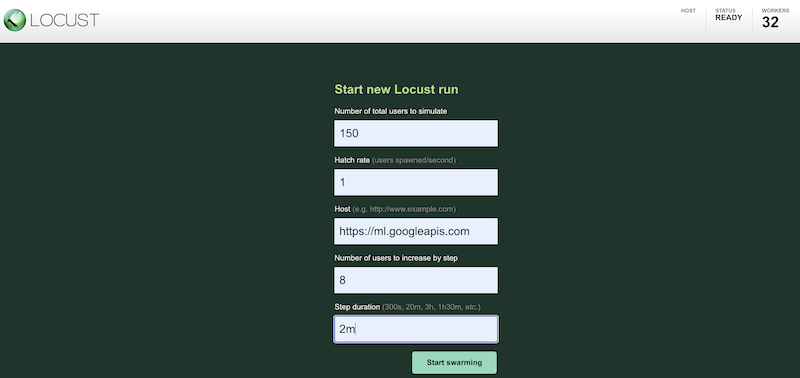
上記のスクリーンショットは、次の構成値を示しています。
- シミュレーションを行う合計ユーザー数:
150 - 生成率:
1 - ホスト:
http://ml.googleapis.com - ステップごとに増加するユーザーの数:
10 - ステップの期間:
2m
- シミュレーションを行う合計ユーザー数:
テスト実行中は、Locust グラフを調べることでテストをモニタリングできます。次のスクリーンショットは、値の表示方法を示しています。
1 つのグラフには、1 秒あたりのリクエストの合計数が表示されます。
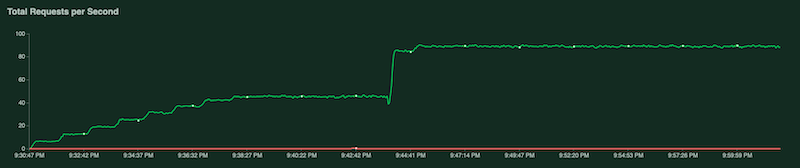
別のグラフは、応答時間をミリ秒単位で示しています。
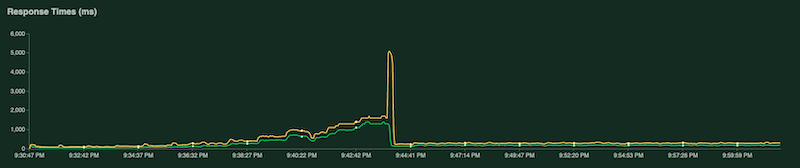
前述のように、これらの統計情報は Cloud Logging にも記録されるため、カスタムの Cloud Monitoring のログベースの指標を作成できます。
テスト結果の収集と分析
次のタスクでは、結果ログから計算された Cloud Monitoring 指標を pandas DataFrame オブジェクトとして収集して分析します。これにより、ノートブックで結果の可視化と分析を行うことができます。このタスクを実行するコードは、03-analyze-results.ipynb ノートブックにあります。
このコードは Cloud Monitoring Query Python SDK を使用して、project_id、test_id、start_time、end_time、model、model_version、log_name パラメータで渡される特定の値である指標値をフィルタし、取得します。
次のコード スニペットは、AI Platform Prediction の指標とカスタムの Locust ログベースの指標を取得する方法を示しています。
import pandas as pd
from google.cloud.monitoring_v3.query import Query
def _get_aipp_metric(metric_type: str, labels: List[str]=[], metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified AIPP metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_resources(model_id=model)
query = query.select_resources(version_id=model_version)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.set_index(df.index.round('T'))
return df
def _get_locust_metric(metric_type: str, labels: List[str]=[],
metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified custom logs-based metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_metrics(log=log_name)
query = query.select_metrics(test_id=test_id)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.apply(lambda row: [metric.mean for metric in row])
df = df.set_index(df.index.round('T'))
return df
指標データは、指標ごとに pandas DataFrame オブジェクトとして取得されてから、個別のデータフレームが単一の DataFrame オブジェクトに結合されます。結合された結果を含む最終的な DataFrame オブジェクトは、ノートブックでは次のようになります。
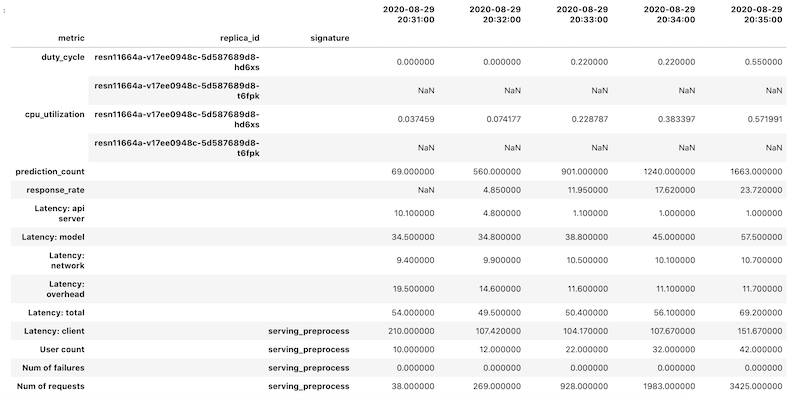
取得した DataFrame オブジェクトは、列名に階層型インデックスを使用します。これは、一部の指標に複数の時系列が含まれていることが原因です。
たとえば、GPU の duty_cycle 指標には、デプロイで使用される各 GPU の時系列の測定値(replica_id)が表示されます。列インデックスの最上位には、個々の指標の名前が表示されます。第 2 レベルはレプリカ ID です。3 つ目のレベルはモデルの署名を示します。すべての指標が同じタイムラインで表示されます。
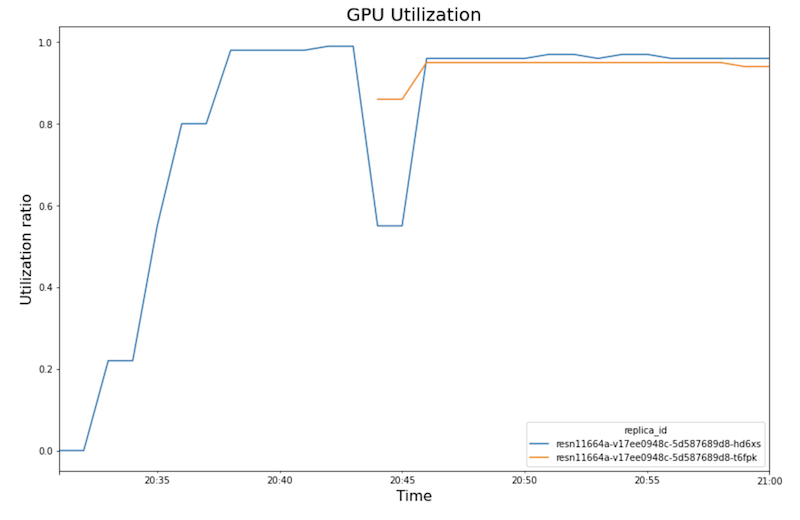
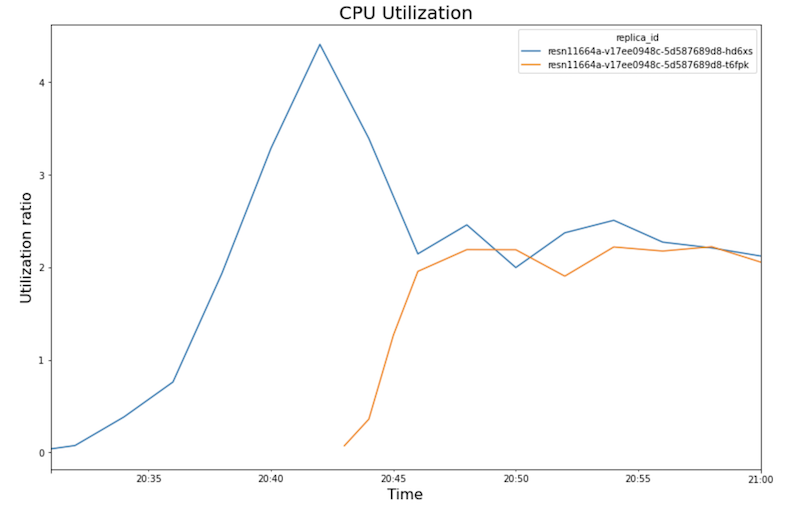
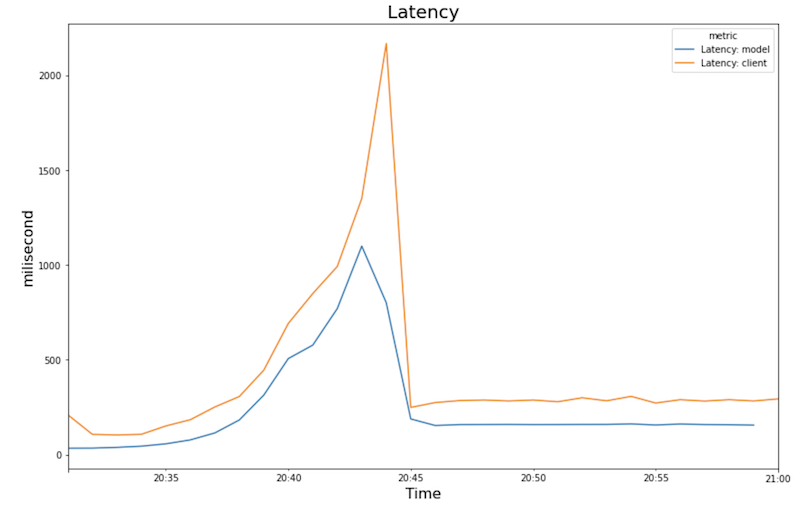
次のグラフは、ノートブックで表示される GPU 使用率、CPU 使用率、レイテンシを示しています。
GPU 使用率:
CPU 使用率:
レイテンシ:
これらのグラフは、次の動作とシーケンスを示しています。
- ワークロード(ユーザー数)が増加すると、CPU と GPU の使用率が上がります。その結果、レイテンシが増加し、20:40 頃のピークまで、モデルのレイテンシと合計レイテンシの差が大きくなります。
- 20:40 には、GPU 使用率が 100% に達する一方、CPU グラフは CPU 使用率が 4 CPU に達していることを示しています。サンプルでは、このテストで
n1-standard-8マシンを使用しています。このマシンは 8 CPU を搭載しています。したがって、CPU 使用率は 50% になります。 - この時点で、自動スケーリングは容量を追加します。つまり、新しい処理ノードが追加の GPU レプリカとともに追加されます。最初の GPU レプリカ使用率は減少し、2 番目の GPU レプリカ使用率は増加します。
- 新しいレプリカが予測の提供を開始すると、レイテンシは約 200 ミリ秒に収束して減少します。
- CPU 使用率はレプリカごとに約 250% に収束します。つまり、8 つの CPU のうち 2.5 の CPU を使用します。この値は、
n1-standard-8マシンの代わりにn1-standard-4マシンを使用できることを示しています。
クリーンアップ
このドキュメントで使用したリソースについて、 Google Cloud に課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Google Cloud プロジェクトを維持したまま作成したリソースを削除する場合は、Google Kubernetes Engine クラスタとデプロイした AI Platform モデルを削除します。
次のステップ
- 機械学習における MLOps、継続的デリバリー、自動化のパイプラインについて学習する。
- TFX、Kubeflow Pipelines、Cloud Build を使用した MLOps のアーキテクチャについて学習する。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。