Auf dieser Seite wird erläutert, wie Sie die paarweise modellbasierte Bewertung mit AutoSxS ausführen. Dies ist ein Tool, das über den Bewertungspipelinedienst ausgeführt wird. Wir erklären, wie Sie AutoSxS über die Vertex AI API, das Vertex AI SDK für Python oder die Google Cloud Console verwenden können.
AutoSxS
Automatic Side-by-Side (AutoSxS) ist ein paarweises modellbasiertes Bewertungstool, das den Bewertungspipelinedienst durchläuft. Mit AutoSxS kann die Leistung von generativen KI-Modellen in Vertex AI Model Registry oder vorab generierten Vorhersagen bewertet werden. Dies ermöglicht es, Vertex AI-Grundlagenmodelle, generative KI-Modelle und Sprachmodelle von Drittanbietern zu unterstützen. Bei AutoSxS wird ein Autorater verwendet, um zu entscheiden, welches Modell die bessere Antwort auf einen Prompt liefert. Sie ist bei Bedarf verfügbar und bewertet Sprachmodelle mit einer Leistung, die mit der von menschlichen Prüfern vergleichbar ist.
Der Autorater
Das Diagramm zeigt auf übergeordneter Ebene, wie AutoSxS die Vorhersagen der Modelle A und B mit einem dritten Modell, dem Autorater, vergleicht.
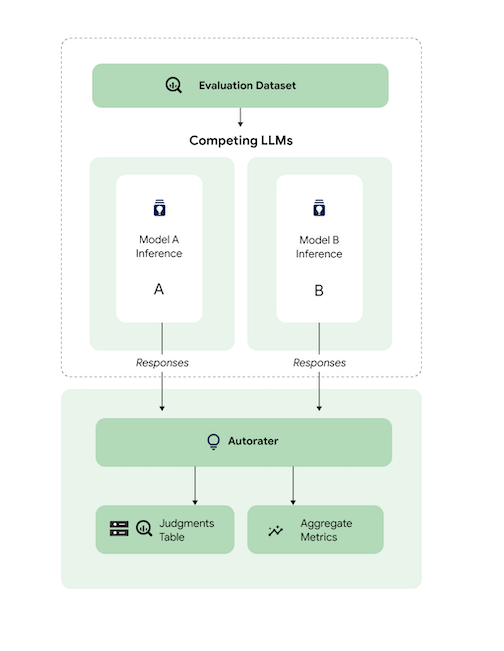
Die Modelle A und B erhalten Prompts. Jedes Modell generiert Antworten, die an den Autorater gesendet werden. Ähnlich wie ein menschlicher Beurteiler ist ein Autorater ein Sprachmodell, das die Qualität der Modellantworten anhand eines ursprünglichen Inferenz-Prompts bewertet. Bei AutoSxS vergleicht der Autorater die Qualität von zwei Modellantworten anhand der Inferenzanweisung mithilfe einer Reihe von Kriterien. Anhand der Kriterien wird bestimmt, welches Modell die beste Leistung erzielt hat. Dazu werden die Ergebnisse von Modell A mit den Ergebnissen von Modell B verglichen. Der Autorater gibt Antwortpräferenzen als aggregierte Messwerte aus und gibt für jedes Beispiel Erläuterungen zu den Präferenzen und Konfidenzwerte aus. Weitere Informationen finden Sie in der Tabelle mit den Urteilen.
Unterstützte Modelle
AutoSxS unterstützt die Bewertung jedes Modells, wenn vorab generierte Vorhersagen bereitgestellt werden. AutoSxS unterstützt auch das automatische Generieren von Antworten für jedes Modell in Vertex AI Model Registry, das Batchvorhersagen in Vertex AI unterstützt.
Wenn Ihr Textmodell von Vertex AI Model Registry nicht unterstützt wird, akzeptiert AutoSxS auch vorab generierte Vorhersagen, die als JSONL in Cloud Storage gespeichert sind, oder eine BigQuery-Tabelle. Preisinformationen finden Sie unter Textgenerierung.
Unterstützte Aufgaben und Kriterien
AutoSxS unterstützt die Bewertung von Modellen für Zusammenfassungs- und Frage-Antwort-Aufgaben. Die Bewertungskriterien sind für jede Aufgabe vordefiniert. Dadurch wird die Sprachbewertung objektiver und die Qualität der Antworten verbessert.
Die Kriterien sind nach Aufgabe aufgeführt.
Zusammenfassung
Für die Aufgabe summarization gilt ein Token-Limit von 4.096 Eingaben.
Die Liste der Bewertungskriterien für summarization sieht so aus:
| Kriterien | |
|---|---|
| 1. Folgt der Anleitung | Inwieweit zeigt die Antwort des Modells, dass es die Anweisung im Prompt verstanden hat? |
| 2. Grounded | Enthält die Antwort nur Informationen aus dem Inferenzkontext und der Inferenzanweisung? |
| 3. Umfassend | Inwieweit werden wichtige Details in der Zusammenfassung berücksichtigt? |
| 4. Kurz | Ist die Zusammenfassung zu ausführlich? Enthält sie floskelhafte Sprache? Ist es zu kurz gefasst? |
Question + Answer
Für die Aufgabe question_answering gilt ein Token-Limit von 4.096 Eingaben.
Die Liste der Bewertungskriterien für question_answering sieht so aus:
| Kriterien | |
|---|---|
| 1. Beantwortet die Frage vollständig | Die Antwort geht vollständig auf die Frage ein. |
| 2. Grounded | Enthält die Antwort nur Informationen aus dem Befehlskontext und der Inferenzanweisung? |
| 3. Relevanz | Bezieht sich der Inhalt der Antwort auf die Frage? |
| 4. Umfassend | Inwieweit werden wichtige Details in der Frage vom Modell erfasst? |
Bewertungs-Dataset für AutoSxS vorbereiten
In diesem Abschnitt werden die Daten beschrieben, die Sie in Ihrem AutoSxS-Bewertungs-Dataset angeben sollten, sowie Best Practices für die Dataset-Erstellung. Die Beispiele sollten reale Eingaben widerspiegeln, mit denen Ihre Modelle in der Produktion konfrontiert werden könnten, und am besten zeigen, wie sich Ihre Live-Modelle verhalten.
Dataset-Format
AutoSxS akzeptiert ein einzelnes Bewertungs-Dataset mit einem flexiblen Schema. Das Dataset kann eine BigQuery-Tabelle sein oder als JSON-Zeilen in Cloud Storage gespeichert werden.
Jede Zeile des Bewertungsdatasets stellt ein einzelnes Beispiel dar. Die Spalten sind eine der folgenden:
- ID-Spalten: Dienen zur Identifizierung der einzelnen eindeutigen Beispiele.
- Datenspalten: Werden verwendet, um Promptvorlagen auszufüllen. Weitere Informationen
- Vorgefertigte Vorhersagen: Vorhersagen, die vom selben Modell mit demselben Prompt erstellt wurden. Durch die Verwendung von vorab generierten Vorhersagen sparen Sie Zeit und Ressourcen.
- Ground-Truth-Daten zu menschlichen Präferenzen: Werden verwendet, um AutoSxS mit Ihren Ground-Truth-Präferenzdaten zu vergleichen, wenn für beide Modelle vorab generierte Vorhersagen bereitgestellt werden.
Hier sehen Sie ein Beispiel für ein Bewertungs-Dataset, in dem context und question Datenspalten sind und model_b_response vorab generierte Vorhersagen enthält.
context |
question |
model_b_response |
|---|---|---|
| Manche mögen denken, dass Stahl oder Titan das härteste Material ist, aber Diamant ist tatsächlich das härteste Material. | Was ist das härteste Material? | Diamant ist das härteste Material. Es ist härter als Stahl oder Titan. |
Weitere Informationen zum Aufrufen von AutoSxS finden Sie unter Modellbewertung durchführen. Weitere Informationen zur Tokenlänge finden Sie unter Unterstützte Aufgaben und Kriterien. Informationen zum Hochladen von Daten in Cloud Storage finden Sie unter Bewertungs-Dataset in Cloud Storage hochladen.
Prompt-Parameter
Viele Sprachmodelle verwenden Aufforderungsparameter als Eingaben anstelle eines einzelnen Aufforderungsstrings. chat-bison verwendet beispielsweise mehrere Prompt-Parameter (messages, examples, context), die Teile des Prompts bilden. text-bison hat jedoch nur einen Prompt-Parameter mit dem Namen prompt, der den gesamten Prompt enthält.
Wir zeigen, wie Sie Parameter für Modellprompts flexibel zum Zeitpunkt der Inferenz und Evaluation angeben können. Mit AutoSxS können Sie Sprachmodelle mit unterschiedlichen erwarteten Eingaben über Vorlagen-Prompt-Parameter aufrufen.
Inferenz
Wenn für eines der Modelle keine vorab generierten Vorhersagen vorhanden sind, verwendet AutoSxS Vertex AI Batch Prediction, um Antworten zu generieren. Die Prompt-Parameter jedes Modells müssen angegeben werden.
In AutoSxS können Sie eine einzelne Spalte im Bewertungs-Dataset als Promptparameter angeben.
{'some_parameter': {'column': 'my_column'}}
Alternativ können Sie Vorlagen definieren, in denen Spalten aus dem Bewertungs-Dataset als Variablen verwendet werden, um Promptparameter anzugeben:
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
Wenn Nutzer Modell-Prompt-Parameter für die Inferenz bereitstellen, können sie das geschützte Keyword default_instruction als Vorlagenargument verwenden. Es wird durch die Standard-Inferenzanweisung für die jeweilige Aufgabe ersetzt:
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
Geben Sie beim Generieren von Vorhersagen Parameter für den Modell-Prompt und eine Ausgabespalte an. Betrachten Sie die folgenden Beispiele:
Gemini
Bei Gemini-Modellen lauten die Schlüssel für Modell-Prompt-Parameter contents (erforderlich) und system_instruction (optional), die dem Gemini-Anfragetextschema entsprechen.
model_a_prompt_parameters={
'contents': {
'column': 'context'
},
'system_instruction': {'template': '{{ default_instruction }}'},
},
text-bison
Beispiel: text-bison verwendet „Prompt“ für die Eingabe und „Inhalt“ für die Ausgabe. Gehen Sie dazu so vor:
- Ermitteln Sie die Eingaben und Ausgaben, die für die zu bewertenden Modelle erforderlich sind.
- Definieren Sie die Eingaben als Modell-Prompt-Parameter.
- Geben Sie die Ausgabe in die Antwortspalte ein.
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
Bewertung
Genauso wie Sie Prompt-Parameter für die Inferenz angeben müssen, müssen Sie auch Prompt-Parameter für die Bewertung angeben. Für autorater sind die folgenden Prompt-Parameter erforderlich:
| Autorater-Prompt-Parameter | Vom Nutzer konfigurierbar? | Beschreibung | Beispiel |
|---|---|---|---|
| Autorater-Anweisung | Nein | Eine kalibrierte Anweisung, die die Kriterien beschreibt, mit denen der Autorater nun die Antworten bewerten soll. | Wählen Sie die Antwort aus, die die Frage beantwortet und die Anweisungen am besten befolgt. |
| Inferenzanweisung | Ja | Eine Beschreibung der Aufgabe, die jedes Kandidatenmodell ausführen soll. | Beantworten Sie die folgende Frage korrekt: Was ist das härteste Material? |
| Inferenzkontext | Ja | Zusätzlicher Kontext für die auszuführende Aufgabe. | Titan und Diamant sind zwar beide härter als Kupfer, aber Diamant hat einen Härtegrad von 98, während Titan einen Wert von 36 hat. Eine höhere Bewertung bedeutet einen höheren Härtegrad. |
| Antworten | Nein1 | Ein Paar von Antworten, die bewertet werden sollen, eine von jedem Kandidatenmodell. | Raute |
1: Sie können den Parameter „prompt“ nur über vorab generierte Antworten konfigurieren.
Beispielcode mit den Parametern:
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
Die Modelle A und B können Inferenzanweisungen und -kontext haben, die unterschiedlich formatiert sind, unabhängig davon, ob dieselben Informationen bereitgestellt werden oder nicht. Das bedeutet, dass der Autorater eine separate, aber einzige Inferenzanweisung und einen einzigen Kontext verwendet.
Beispiel für ein Bewertungs-Dataset
Dieser Abschnitt enthält ein Beispiel für ein Dataset zur Bewertung einer Frage-Antwort, einschließlich vorab generierter Vorhersagen für Modell B. In diesem Beispiel führt AutoSxS nur für Modell A Inferenz aus. Wir stellen eine id-Spalte zur Verfügung, um zwischen Beispielen mit derselben Frage und demselben Kontext zu unterscheiden.
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
Best Practices
Beachten Sie beim Definieren des Bewertungsdatasets die folgenden Best Practices:
- Geben Sie Beispiele für die Arten von Eingaben an, die Ihre Modelle in der Produktion verarbeiten.
- Ihr Dataset muss mindestens ein Bewertungsbeispiel enthalten. Wir empfehlen etwa 100 Beispiele, um qualitativ hochwertige aggregierte Messwerte zu gewährleisten. Wenn mehr als 400 Beispiele zur Verfügung gestellt werden, sinkt die Verbesserungsrate bei den aggregierten Messwerten tendenziell.
- Eine Anleitung zum Schreiben von Prompts finden Sie unter Text-Prompts erstellen.
- Wenn Sie für eines der Modelle vorab generierte Vorhersagen verwenden, fügen Sie diese in eine Spalte Ihres Bewertungs-Datasets ein. Die Bereitstellung von vorab generierten Vorhersagen ist nützlich, da Sie damit die Ausgabe von Modellen vergleichen können, die nicht in der Vertex Model Registry enthalten sind, und Antworten wiederverwenden können.
Modellbewertung durchführen
Sie können Modelle mit der REST API, dem Vertex AI SDK für Python oder derGoogle Cloud Console bewerten.
Verwenden Sie diese Syntax, um den Pfad zu Ihrem Modell anzugeben:
- Publisher-Modell:
publishers/PUBLISHER/models/MODELBeispiel:publishers/google/models/text-bison Abgestimmtes Modell:
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSIONBeispiel:projects/123456789012/locations/us-central1/models/1234567890123456789
REST
Senden Sie zum Erstellen eines Modellbewertungsjobs eine POST-Anfrage mit der Methode PipelineJobs.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PIPELINEJOB_DISPLAYNAME : Der Anzeigename für
pipelineJob. - PROJECT_ID :Das Google Cloud -Projekt, in dem die Pipelinekomponenten ausgeführt werden.
- LOCATION: Die Region, in der die Pipelinekomponenten ausgeführt werden.
us-central1wird unterstützt. - OUTPUT_DIR : Cloud Storage-URI zum Speichern der Bewertungsausgabe.
- EVALUATION_DATASET : BigQuery-Tabelle oder eine durch Kommas getrennte Liste von Cloud Storage-Pfaden zu einem JSONL-Dataset mit Bewertungsbeispielen.
- TASK: Bewertungsaufgabe, die eine der folgenden sein kann:
[summarization, question_answering]. - ID_COLUMNS : Spalten, die zwischen eindeutigen Bewertungsbeispielen unterscheiden.
- AUTORATER_PROMPT_PARAMETERS : Die Parameter des Autorater-Prompts, die Spalten oder Vorlagen zugeordnet sind. Die erwarteten Parameter sind:
inference_instruction(Details zur Ausführung einer Aufgabe) undinference_context(Inhalte, auf die sich bei der Ausführung der Aufgabe bezogen werden soll). Zum Beispiel verwendet{'inference_context': {'column': 'my_prompt'}}die Spalte „my_prompt“ des Bewertungs-Datasets für den Kontext des Autoraters. - RESPONSE_COLUMN_A : Entweder der Name einer Spalte im Bewertungs-Dataset, das vordefinierte Vorhersagen enthält, oder der Name der Spalte in der Modell-A-Ausgabe, die Vorhersagen enthält. Wenn kein Wert angegeben wird, versucht das System, den richtigen Namen der Modellausgabespalte abzuleiten.
- RESPONSE_COLUMN_B : Entweder der Name einer Spalte im Bewertungs-Dataset, das vordefinierte Vorhersagen enthält, oder der Name der Spalte in der Ausgabe von Modell B mit Vorhersagen. Wenn kein Wert angegeben wird, versucht das System, den richtigen Namen der Modellausgabespalte abzuleiten.
- MODEL_A (optional): Ein voll qualifizierter Name für die Modellressource (
projects/{project}/locations/{location}/models/{model}@{version}) oder der Ressourcenname des Publisher-Modells (publishers/{publisher}/models/{model}). Wenn Antworten von Modell A angegeben werden, sollte dieser Parameter nicht angegeben werden. - MODEL_B (optional): Ein voll qualifizierter Name für die Modellressource (
projects/{project}/locations/{location}/models/{model}@{version}) oder der Ressourcenname des Publisher-Modells (publishers/{publisher}/models/{model}). Wenn Antworten von Modell B angegeben werden, sollte dieser Parameter nicht angegeben werden. - MODEL_A_PROMPT_PARAMETERS (Optional): Die Prompt-Vorlagenparameter von Modell A, die Spalten oder Vorlagen zugeordnet sind. Wenn Antworten von Modell A vordefiniert sind, sollte dieser Parameter nicht angegeben werden. Beispiel:
{'prompt': {'column': 'my_prompt'}}verwendet die Spaltemy_promptdes Bewertungs-Datasets für den Promptparameter namensprompt. - MODEL_B_PROMPT_PARAMETERS (Optional): Die Parameter der Prompt-Vorlagen von Modell B, die Spalten oder Vorlagen zugeordnet sind. Wenn Antworten von Modell B vordefiniert sind, sollte dieser Parameter nicht angegeben werden. Beispiel:
{'prompt': {'column': 'my_prompt'}}verwendet die Spaltemy_promptdes Bewertungs-Datasets für den Promptparameter namensprompt. - JUDGMENTS_FORMAT
(optional): Das Format, in dem Beurteilungen geschrieben werden sollen. Kann
jsonl(Standard),jsonoderbigquerysein. - BIGQUERY_DESTINATION_PREFIX: BigQuery-Tabelle, in die Beurteilungen geschrieben werden, wenn das angegebene Format
bigqueryist.
JSON-Text der Anfrage:
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
"judgments_format": "JUDGMENTS_FORMAT",
"bigquery_destination_prefix":BIGQUERY_DESTINATION_PREFIX,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
Verwenden Sie curl, um Ihre Anfrage zu senden.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
Antwort
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@002",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@developer.gserviceaccount.com",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
Vertex AI SDK für Python
Informationen zur Installation des Vertex AI SDK for Python finden Sie unter Vertex AI SDK for Python installieren. Weitere Informationen zur Python API finden Sie in der Vertex AI SDK for Python API.
Weitere Informationen zu Pipelineparametern finden Sie in der Referenzdokumentation zu Google Cloud-Pipeline-Komponenten.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PIPELINEJOB_DISPLAYNAME : Der Anzeigename für
pipelineJob. - PROJECT_ID :Das Google Cloud -Projekt, in dem die Pipelinekomponenten ausgeführt werden.
- LOCATION: Die Region, in der die Pipelinekomponenten ausgeführt werden.
us-central1wird unterstützt. - OUTPUT_DIR : Cloud Storage-URI zum Speichern der Bewertungsausgabe.
- EVALUATION_DATASET : BigQuery-Tabelle oder eine durch Kommas getrennte Liste von Cloud Storage-Pfaden zu einem JSONL-Dataset mit Bewertungsbeispielen.
- TASK: Bewertungsaufgabe, die eine der folgenden sein kann:
[summarization, question_answering]. - ID_COLUMNS : Spalten, die zwischen eindeutigen Bewertungsbeispielen unterscheiden.
- AUTORATER_PROMPT_PARAMETERS : Die Parameter des Autorater-Prompts, die Spalten oder Vorlagen zugeordnet sind. Die erwarteten Parameter sind:
inference_instruction(Details zur Ausführung einer Aufgabe) undinference_context(Inhalte, auf die sich bei der Ausführung der Aufgabe bezogen werden soll). Zum Beispiel verwendet{'inference_context': {'column': 'my_prompt'}}die Spalte „my_prompt“ des Bewertungs-Datasets für den Kontext des Autoraters. - RESPONSE_COLUMN_A : Entweder der Name einer Spalte im Bewertungs-Dataset, das vordefinierte Vorhersagen enthält, oder der Name der Spalte in der Modell-A-Ausgabe, die Vorhersagen enthält. Wenn kein Wert angegeben wird, versucht das System, den richtigen Namen der Modellausgabespalte abzuleiten.
- RESPONSE_COLUMN_B : Entweder der Name einer Spalte im Bewertungs-Dataset, das vordefinierte Vorhersagen enthält, oder der Name der Spalte in der Ausgabe von Modell B mit Vorhersagen. Wenn kein Wert angegeben wird, versucht das System, den richtigen Namen der Modellausgabespalte abzuleiten.
- MODEL_A (optional): Ein voll qualifizierter Name für die Modellressource (
projects/{project}/locations/{location}/models/{model}@{version}) oder der Ressourcenname des Publisher-Modells (publishers/{publisher}/models/{model}). Wenn Antworten von Modell A angegeben werden, sollte dieser Parameter nicht angegeben werden. - MODEL_B (optional): Ein voll qualifizierter Name für die Modellressource (
projects/{project}/locations/{location}/models/{model}@{version}) oder der Ressourcenname des Publisher-Modells (publishers/{publisher}/models/{model}). Wenn Antworten von Modell B angegeben werden, sollte dieser Parameter nicht angegeben werden. - MODEL_A_PROMPT_PARAMETERS (Optional): Die Prompt-Vorlagenparameter von Modell A, die Spalten oder Vorlagen zugeordnet sind. Wenn Antworten von Modell A vordefiniert sind, sollte dieser Parameter nicht angegeben werden. Beispiel:
{'prompt': {'column': 'my_prompt'}}verwendet die Spaltemy_promptdes Bewertungs-Datasets für den Promptparameter namensprompt. - MODEL_B_PROMPT_PARAMETERS (Optional): Die Parameter der Prompt-Vorlagen von Modell B, die Spalten oder Vorlagen zugeordnet sind. Wenn Antworten von Modell B vordefiniert sind, sollte dieser Parameter nicht angegeben werden. Beispiel:
{'prompt': {'column': 'my_prompt'}}verwendet die Spaltemy_promptdes Bewertungs-Datasets für den Promptparameter namensprompt. - JUDGMENTS_FORMAT
(optional): Das Format, in dem Beurteilungen geschrieben werden sollen. Kann
jsonl(Standard),jsonoderbigquerysein. - BIGQUERY_DESTINATION_PREFIX: BigQuery-Tabelle, in die Beurteilungen geschrieben werden, wenn das angegebene Format
bigqueryist.
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'judgments_format': 'JUDGMENTS_FORMAT',
'bigquery_destination_prefix':
BIGQUERY_DESTINATION_PREFIX,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
Konsole
Führen Sie die folgenden Schritte aus, um mithilfe der Google Cloud Console einen paarweisen Modellbewertungsjob zu erstellen:
Beginnen Sie mit einem Google-Foundation Model oder verwenden Sie ein Modell, das bereits in Ihrer Vertex AI Model Registry vorhanden ist:
So bewerten Sie ein Google-Foundation Model:
Rufen Sie den Vertex AI Model Garden auf und wählen Sie ein Modell aus, das die paarweise Bewertung unterstützt, z. B.
text-bison.Klicken Sie auf Bewerten.
Klicken Sie im angezeigten Menü auf Auswählen, um eine Modellversion auszuwählen.
Im Bereich Modell speichern werden Sie möglicherweise aufgefordert, eine Kopie des Modells in Vertex AI Model Registry zu speichern, wenn Sie noch keine Kopie haben. Geben Sie einen Modellnamen ein und klicken Sie auf Speichern.
Die Seite Evaluierung erstellen wird angezeigt. Wählen Sie für den Schritt Evaluate Method (Bewertungsmethode) die Option Evaluate this model against another model (Dieses Modell im Vergleich zu einem anderen Modell bewerten) aus.
Klicken Sie auf Weiter.
So bewerten Sie ein vorhandenes Modell in der Vertex AI Model Registry:
Rufen Sie die Seite Vertex AI Model Registry auf:
Klicken Sie auf den Namen des Modells, das bewertet werden soll. Prüfen Sie, ob der Modelltyp die paarweise Auswertung unterstützt. Beispiel:
text-bison.Klicken Sie auf dem Tab Bewerten auf SxS.
Klicken Sie auf Vergleichende Bewertung erstellen.
Geben Sie für jeden Schritt auf der Seite zum Erstellen der Auswertung die erforderlichen Informationen ein und klicken Sie auf Weiter:
Wählen Sie im Schritt Evaluierungs-Dataset ein Evaluierungsziel und ein Modell aus, das mit dem ausgewählten Modell verglichen werden soll. Wählen Sie ein Bewertungs-Dataset aus und geben Sie die ID-Spalten (Antwortspalten) ein.
Geben Sie im Schritt Modelleinstellungen an, ob Sie die Modellantworten verwenden möchten, die bereits in Ihrem Dataset enthalten sind, oder ob Sie Vertex AI Batch Prediction verwenden möchten, um die Antworten zu generieren. Geben Sie die Antwortspalten für beide Modelle an. Für die Option Vertex AI Batch Prediction können Sie Ihre Inferenzmodell-Prompt-Parameter angeben.
Geben Sie im Schritt Autorater-Einstellungen Ihre Autorater-Prompt-Parameter und einen Ausgabespeicherort für die Bewertungen ein.
Klicken Sie auf Bewertung starten.
Bewertungsergebnisse ansehen
Die Bewertungsergebnisse finden Sie in Vertex AI Pipelines, indem Sie die folgenden Artefakte untersuchen, die von der AutoSxS-Pipeline erstellt wurden:
- Die Tabelle Bewertungen wird vom AutoSxS-Arbiter erstellt.
- Zusammengefasste Messwerte werden von der AutoSxS-Messwertkomponente erstellt.
- Messwerte zur Ausrichtung mit menschlichen Präferenzen werden von der AutoSxS-Messwertkomponente erstellt.
Bewertungen
AutoSxS gibt Bewertungen (Messwerte auf Beispielebene) aus, die Nutzern helfen, die Modellleistung auf Beispielebene zu verstehen. Die Bewertungen umfassen folgende Informationen:
- Inferenz-Prompts
- Modellantworten
- Entscheidungen des Autoraters
- Erläuterungen zur Altersfreigabe
- Konfidenzwerte
Ursprünge können mit den folgenden Spalten im JSONL-Format oder in eine BigQuery-Tabelle geschrieben werden:
| Spalte | Beschreibung |
|---|---|
| ID-Spalten | Spalten, die zwischen eindeutigen Bewertungsbeispielen unterscheiden. |
inference_instruction |
Anweisung, die zum Generieren von Modellantworten verwendet wird. |
inference_context |
Kontext, der zum Generieren von Modellantworten verwendet wird. |
response_a |
Antwort von Modell A unter Berücksichtigung der Inferenzanweisung und des Kontexts. |
response_b |
Antwort von Modell B unter Angabe der Inferenzanweisung und des Kontexts. |
choice |
Das Modell mit der besseren Antwort. Mögliche Werte sind Model A, Model B und Error. Error bedeutet, dass ein Fehler verhindert hat, dass das Autoscaling ermitteln konnte, ob die Antwort von Modell A oder die von Modell B am besten war. |
confidence |
Ein Wert zwischen 0 und 1, der angibt, wie sicher sich der Autorater bei seiner Auswahl war. |
explanation |
Der Grund des Autoraters für seine Wahl. |
Zusammengefasste Messwerte
AutoSxS berechnet zusammengefasste Messwerte (Gewinnrate) anhand der Bewertungstabelle. Wenn keine Daten mit menschlichen Präferenzen bereitgestellt werden, werden die folgenden aggregierten Messwerte generiert:
| Messwert | Beschreibung |
|---|---|
| AutoRater-Modell A – Gewinnrate | Prozentsatz der Zeit, in der der Autorater entschied, dass Modell A die bessere Antwort war. |
| AutoRater-Modell B – Gewinnrate | Prozentsatz der Zeit, in der der Autorater entschied, dass Modell B die bessere Antwort war. |
Um die Gewinnrate besser zu verstehen, sehen Sie sich die zeilenbasierten Ergebnisse und die Erläuterungen des Autoraters an, um festzustellen, ob die Ergebnisse und Erläuterungen mit Ihren Erwartungen übereinstimmen.
Messwerte zur Ausrichtung mit menschlichen Präferenzen
Wenn Daten mit menschlichen Präferenzen bereitgestellt werden, gibt AutoSxS die folgenden Messwerte aus:
| Messwert | Beschreibung | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AutoRater-Modell A – Gewinnrate | Prozentsatz der Zeit, in der der Autorater entschied, dass Modell A die bessere Antwort war. | ||||||||||||||
| AutoRater-Modell B – Gewinnrate | Prozentsatz der Zeit, in der der Autorater entschied, dass Modell B die bessere Antwort war. | ||||||||||||||
| Gewinnrate Modell A mit menschlichen Präferenzen | Prozentsatz der Zeit, in der Menschen entschieden haben, dass Modell A die bessere Antwort hatte. | ||||||||||||||
| Gewinnrate Modell B mit menschlichen Präferenzen | Prozentsatz der Zeit, in der Menschen entschieden haben, dass Modell B die bessere Antwort hatte. | ||||||||||||||
| TP | Anzahl der Beispiele, bei denen sowohl der Autorater als auch die menschlichen Präferenzen Modell A als die bessere Antwort ansahen. | ||||||||||||||
| FP | Anzahl der Beispiele, bei denen der Autorater Modell A als bessere Antwort auswählte, die menschliche Präferenz aber Modell B als bessere Antwort ansah. | ||||||||||||||
| TN | Anzahl der Beispiele, bei denen sowohl der Autorater als auch die menschliche Präferenz das Modell B als die bessere Antwort ansahen. | ||||||||||||||
| FN | Anzahl der Beispiele, bei denen der Autorater Modell B als bessere Antwort gewählt hat, die menschliche Präferenz aber Modell A als bessere Antwort ansah. | ||||||||||||||
| Genauigkeit | Prozentsatz der Zeit, in der der Autoscaler mit menschlichen Beurteilern vereinbart hat. | ||||||||||||||
| Precision | Prozentsatz der Zeit, in der sowohl der Autorater als auch die Menschen fanden, dass Modell A eine bessere Antwort hätte, an allen Fällen, in denen der Autorater fand, dass Modell A eine bessere Antwort hatte. | ||||||||||||||
| Recall | Prozentsatz der Zeit, in der sowohl der Autorater als auch die Menschen dachten, dass Modell A eine bessere Antwort hätte, an allen Fällen, in denen Modell A eine bessere Antwort hatte. | ||||||||||||||
| F1 | Harmonischer Mittelwert von Precision und Recall. | ||||||||||||||
| Cohens Kappa | Messung der Übereinstimmung zwischen dem Autorater und den menschlichen Beurteilern, bei dem die Wahrscheinlichkeit einer zufälligen Vereinbarung berücksichtigt wird. Cohen schlägt die folgende Interpretation vor:
|
AutoSxS-Anwendungsfälle
Anhand von drei Anwendungsfallszenarien können Sie sich ansehen, wie Sie AutoSxS verwenden können.
Modelle vergleichen
Ein abgestimmtes eigenes (1P) Modell mit einem eigenen Referenzmodell vergleichen.
Sie können festlegen, dass die Inferenz gleichzeitig für beide Modelle ausgeführt wird.
In diesem Codebeispiel wird ein optimiertes Modell aus der Vertex Model Registry mit einem Referenzmodell aus derselben Registry verglichen.
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@002',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
Vorhersagen vergleichen
Ein abgestimmtes Drittanbietermodell mit einem Referenzmodell eines Drittanbieters vergleichen
Sie können die Inferenz überspringen, indem Sie direkt Modellantworten angeben.
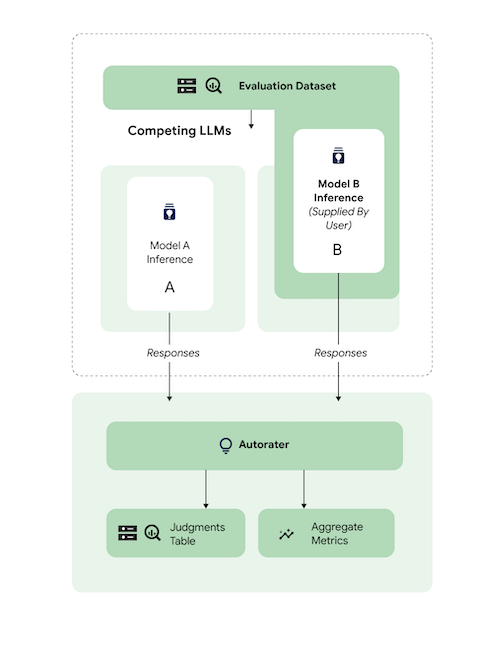
In diesem Codebeispiel wird ein abgestimmtes 3p-Modell mit einem 3p-Referenzmodell verglichen.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
Ausrichtung prüfen
Alle unterstützten Aufgaben wurden mit Daten von menschlichen Beurteilern verglichen, um zu gewährleisten, dass die Antworten der Autorater auf menschliche Präferenzen ausgerichtet sind. Wenn Sie ein Benchmarking von AutoSxS für Ihre Anwendungsfälle durchführen möchten, stellen Sie AutoSxS die Daten mit menschlichen Präferenzen direkt zur Verfügung, sodass AutoSxS aggregierte Ausrichtungsstatistiken ausgibt.
Sie können beide Ausgaben (Vorhersageergebnisse) für den Autorater angeben, um die Ausrichtung anhand eines Datasets für menschliche Präferenzen zu prüfen. Sie können auch Ihre Inferenz-Ergebnisse angeben.
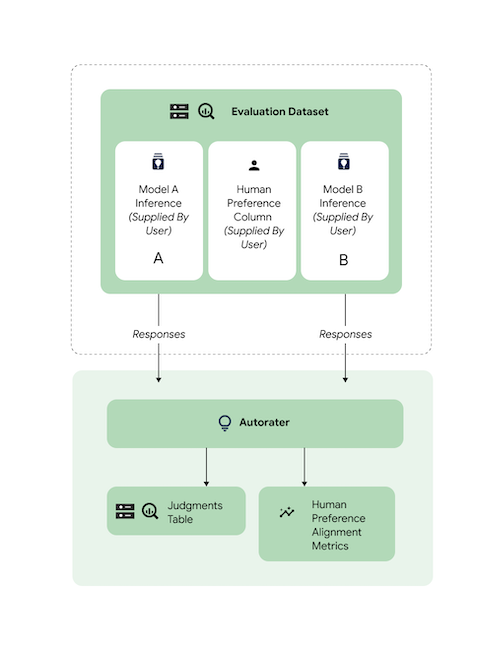
Mit diesem Codebeispiel wird sichergestellt, dass die Ergebnisse und Erläuterungen des Autoraters Ihren Erwartungen entsprechen.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
Nächste Schritte
- Weitere Informationen zur Bewertung mit generativer KI
- Weitere Informationen zur Onlinebewertung mit dem Gen AI Evaluation Service
- Weitere Informationen zum Optimieren von Foundation Models