The Gemini 2.5 Computer Use model and tool lets you enable your applications to interact with and automate tasks in the browser. Using screenshots, the computer use model can infer information about a computer screen, and perform actions by generating specific UI actions like mouse clicks and keyboard inputs. Similar to function calling, you need to write the client-side application code to receive the Computer Use model and tool function call and execute the corresponding actions.
With the Computer Use model and tool, you can build agents that can:
- Automate repetitive data entry or form filling on websites.
- Navigate websites to gather information.
- Assist users by performing sequences of actions in web applications.
This guide covers:
- How the Computer Use model and tool works
- How to enable the Computer Use model and tool
- How to send requests, receive responses, and build agent loops
- What computer actions are supported
- Safety and security support
- Preview pricing
This guide assumes you're using the Gen AI SDK for Python and are familiar with the Playwright API.
The Computer Use model and tool is not supported in the other SDK languages or the Google Cloud console during this preview.
Additionally, you can view the reference implementation for the Computer Use model and tool in GitHub.
How the Computer Use model and tool works
Instead of generating text responses, the Computer Use model and tool determines when to
take specific UI actions like mouse clicks, and returns the necessary parameters
to execute these actions. You need to write the client-side application code to
receive the Computer Use model and tool function_call and execute the corresponding actions.
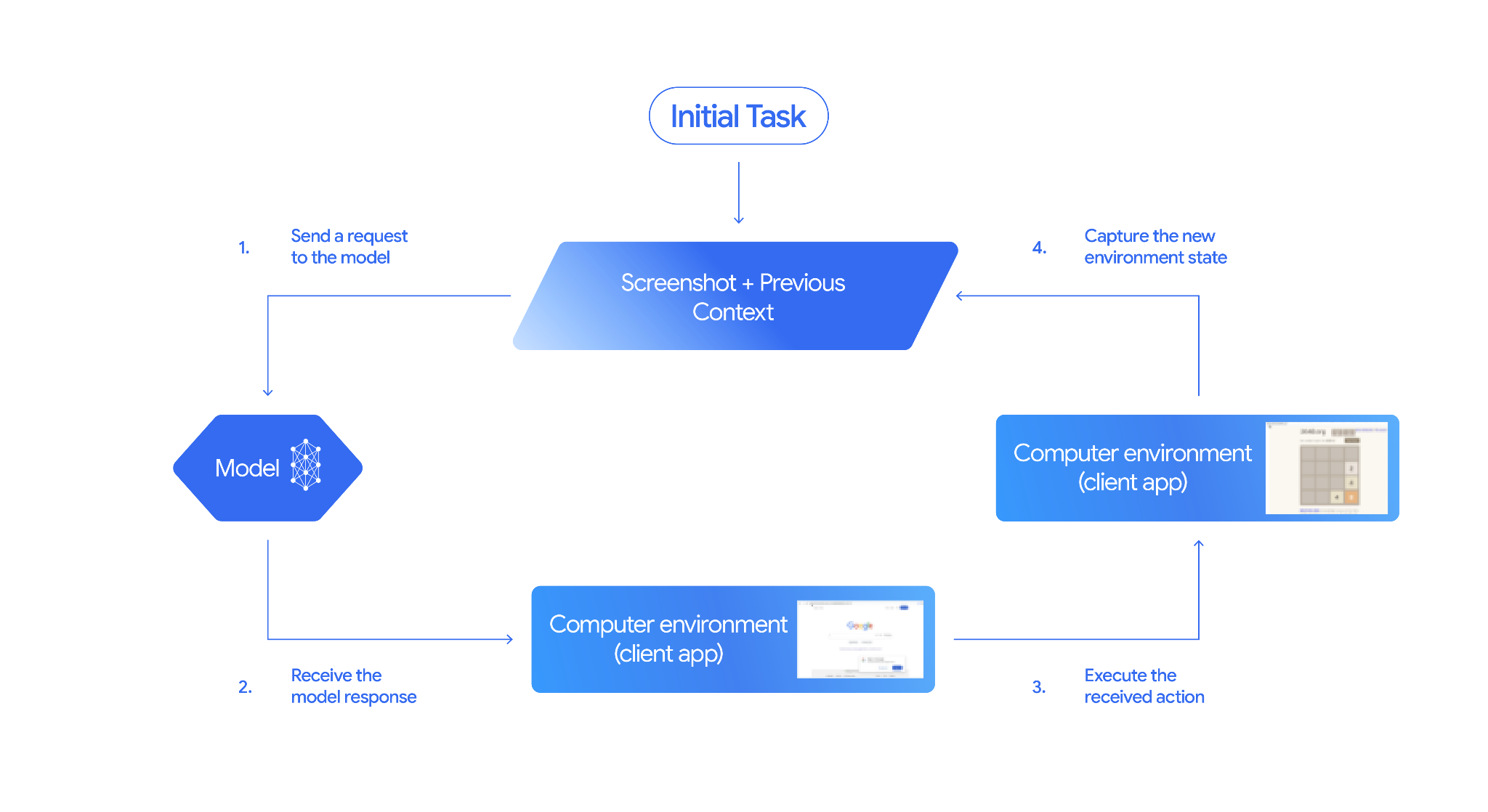
Computer Use model and tool interactions follow an agentic loop process:
Send a request to the model
- Add the Computer Use model and tool and optionally any additional tools to your API request.
- Prompt the Computer Use model and tool with the user's request and a screenshot representing the current state of the GUI.
Receive the model response
- The model analyzes the user request and screenshot, and generates a
response which includes a suggested
function_callrepresenting a UI action (for example, "click at coordinate (x,y)" or "type 'text'"). See Supported actions for the list of all actions you can use with the model. - The API response may also include a
safety_responsefrom an internal safety system that has checked the model's proposed action. Thissafety_responseclassifies the action as:- Regular or allowed: The action is considered safe. This may also
be represented by no
safety_responsebeing present. - Requires confirmation: The model is about to perform an action that may be risky (for example, clicking on an "accept cookie banner").
- Regular or allowed: The action is considered safe. This may also
be represented by no
- The model analyzes the user request and screenshot, and generates a
response which includes a suggested
Execute the received action
- Your client-side code receives the
function_calland any accompanyingsafety_response. - If the
safety_responseindicates regular or allowed (or if nosafety_responseis present), your client-side code can execute the specifiedfunction_callin your target environment (such as a web browser). - If the
safety_responseindicates required confirmation, your application must prompt the end-user for confirmation before executing thefunction_call. If the user confirms, proceed to execute the action. If the user denies, don't execute the action.
- Your client-side code receives the
Capture the new environment state
- If the action has been executed, your client captures a new screenshot
of the GUI and the current URL to send back to the
Computer Use model and tool as part of a
function_response. - If an action was blocked by the safety system or denied confirmation by the user, your application might send a different form of feedback to the model or end the interaction.
- If the action has been executed, your client captures a new screenshot
of the GUI and the current URL to send back to the
Computer Use model and tool as part of a
A new request is sent to the model with the updated state. The process repeats from step 2, with the Computer Use model and tool using the new screenshot (if provided) and the ongoing goal to suggest the next action. The loop continues until the task is completed, an error occurs, or the process is terminated (for example, if a response is blocked by safety filters or user decision).
The following diagram illustrates how the Computer Use model and tool works:
Enable the Computer Use model and tool
To enable the Computer Use model and tool, use gemini-2.5-computer-use-preview-10-2025 as
your model, and add the Computer Use model and tool to your list of enabled
tools:
Python
from google import genai from google.genai import types from google.genai.types import Content, Part, FunctionResponse client = genai.Client() # Add Computer Use model and tool to the list of tools generate_content_config = genai.types.GenerateContentConfig( tools=[ types.Tool( computer_use=types.ComputerUse( environment=types.Environment.ENVIRONMENT_BROWSER, ) ), ] ) # Example request using the Computer Use model and tool contents = [ Content( role="user", parts=[ Part(text="Go to google.com and search for 'weather in New York'"), ], ) ] response = client.models.generate_content( model="gemini-2.5-computer-use-preview-10-2025", contents=contents, config=generate_content_config, )
Send a request
After configuring the Computer Use model and tool, send a prompt to the model that includes the user's goal and an initial screenshot of the GUI.
You can also optionally add the following:
- Excluded actions: If there are any actions from the list of supported UI
actions that you don't want the model to take, specify
these actions in the
excluded_predefined_functions. - User-defined functions: In addition to the Computer Use model and tool, you may want to include custom user-defined functions.
The following sample code enables the Computer Use model and tool and sends the request to the model:
Python
from google import genai from google.genai import types from google.genai.types import Content, Part client = genai.Client() # Specify predefined functions to exclude (optional) excluded_functions = ["drag_and_drop"] # Configuration for the Computer Use model and tool with browser environment generate_content_config = genai.types.GenerateContentConfig( tools=[ # 1. Computer Use model and tool with browser environment types.Tool( computer_use=types.ComputerUse( environment=types.Environment.ENVIRONMENT_BROWSER, # Optional: Exclude specific predefined functions excluded_predefined_functions=excluded_functions ) ), # 2. Optional: Custom user-defined functions (need to defined above) # types.Tool( # function_declarations=custom_functions # ) ], ) # Create the content with user message contents: list[Content] = [ Content( role="user", parts=[ Part(text="Search for highly rated smart fridges with touchscreen, 2 doors, around 25 cu ft, priced below 4000 dollars on Google Shopping. Create a bulleted list of the 3 cheapest options in the format of name, description, price in an easy-to-read layout."), # Optional: include a screenshot of the initial state # Part.from_bytes( # data=screenshot_image_bytes, # mime_type='image/png', # ), ], ) ] # Generate content with the configured settings response = client.models.generate_content( model='gemini-2.5-computer-use-preview-10-2025', contents=contents, config=generate_content_config, ) # Print the response output print(response.text)
You can also include custom user-defined functions to extend the functionality
of the model. See Use Computer Use model and tool for mobile use cases for
information on how you can configure computer use for mobile use cases by adding
actions such as open_app, long_press_at, and go_home while excluding
browser-specific actions.
Receive responses
The model responds with one or more FunctionCalls if it determines UI
actions or user-defined functions are needed to complete the task. Your
application code needs to parse these actions, execute them, and collect the
results. The Computer Use model and tool supports parallel function calling, meaning the
model can return multiple independent actions in a single turn.
{
"content": {
"parts": [
{
"text": "I will type the search query into the search bar. The search bar is in the center of the page."
},
{
"function_call": {
"name": "type_text_at",
"args": {
"x": 371,
"y": 470,
"text": "highly rated smart fridges with touchscreen, 2 doors, around 25 cu ft, priced below 4000 dollars on Google Shopping",
"press_enter": true
}
}
}
]
}
}
Depending on the action, the API response might also return a safety_response:
{
"content": {
"parts": [
{
"text": "I have evaluated step 2. It seems Google detected unusual traffic and is asking me to verify I'm not a robot. I need to click the 'I'm not a robot' checkbox located near the top left (y=98, x=95)."
},
{
"function_call": {
"name": "click_at",
"args": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "I have encountered a CAPTCHA challenge that requires interaction. I need you to complete the challenge by clicking the 'I'm not a robot' checkbox and any subsequent verification steps.",
"decision": "require_confirmation"
}
}
}
}
]
}
}
Execute received actions
After you receive a response, the model needs to execute the received actions.
The following code extracts function calls from a Gemini response, converts coordinates from 0-1000 range to actual pixels, executes browser actions using Playwright, and returns the success or failure status for each action:
import time
from typing import Any, List, Tuple
def normalize_x(x: int, screen_width: int) -> int:
"""Convert normalized x coordinate (0-1000) to actual pixel coordinate."""
return int(x / 1000 * screen_width)
def normalize_y(y: int, screen_height: int) -> int:
"""Convert normalized y coordinate (0-1000) to actual pixel coordinate."""
return int(y / 1000 * screen_height)
def execute_function_calls(response, page, screen_width: int, screen_height: int) -> List[Tuple[str, Any]]:
"""
Extract and execute function calls from Gemini response.
Args:
response: Gemini API response object
page: Playwright page object
screen_width: Screen width in pixels
screen_height: Screen height in pixels
Returns:
List of tuples: [(function_name, result), ...]
"""
# Extract function calls and thoughts from the model's response
candidate = response.candidates[0]
function_calls = []
thoughts = []
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_calls.append(part.function_call)
elif hasattr(part, 'text') and part.text:
thoughts.append(part.text)
if thoughts:
print(f"Model Reasoning: {' '.join(thoughts)}")
# Execute each function call
results = []
for function_call in function_calls:
result = None
try:
if function_call.name == "open_web_browser":
print("Executing open_web_browser")
# Browser is already open via Playwright, so this is a no-op
result = "success"
elif function_call.name == "click_at":
actual_x = normalize_x(function_call.args["x"], screen_width)
actual_y = normalize_y(function_call.args["y"], screen_height)
print(f"Executing click_at: ({actual_x}, {actual_y})")
page.mouse.click(actual_x, actual_y)
result = "success"
elif function_call.name == "type_text_at":
actual_x = normalize_x(function_call.args["x"], screen_width)
actual_y = normalize_y(function_call.args["y"], screen_height)
text = function_call.args["text"]
press_enter = function_call.args.get("press_enter", False)
clear_before_typing = function_call.args.get("clear_before_typing", True)
print(f"Executing type_text_at: ({actual_x}, {actual_y}) text='{text}'")
# Click at the specified location
page.mouse.click(actual_x, actual_y)
time.sleep(0.1)
# Clear existing text if requested
if clear_before_typing:
page.keyboard.press("Control+A")
page.keyboard.press("Backspace")
# Type the text
page.keyboard.type(text)
# Press enter if requested
if press_enter:
page.keyboard.press("Enter")
result = "success"
else:
# For any functions not parsed above
print(f"Unrecognized function: {function_call.name}")
result = "unknown_function"
except Exception as e:
print(f"Error executing {function_call.name}: {e}")
result = f"error: {str(e)}"
results.append((function_call.name, result))
return results
If the returned safety_decision is require_confirmation, you must ask the
user to confirm before proceeding with executing the action. Per the terms
of service, you are not permitted to bypass requests for human confirmation.
The following adds safety logic to the previous code:
import termcolor
def get_safety_confirmation(safety_decision):
"""Prompt user for confirmation when safety check is triggered."""
termcolor.cprint("Safety service requires explicit confirmation!", color="red")
print(safety_decision["explanation"])
decision = ""
while decision.lower() not in ("y", "n", "ye", "yes", "no"):
decision = input("Do you wish to proceed? [Y]es/[N]o\n")
if decision.lower() in ("n", "no"):
return "TERMINATE"
return "CONTINUE"
def execute_function_calls(response, page, screen_width: int, screen_height: int):
# ... Extract function calls from response ...
for function_call in function_calls:
extra_fr_fields = {}
# Check for safety decision
if 'safety_decision' in function_call.args:
decision = get_safety_confirmation(function_call.args['safety_decision'])
if decision == "TERMINATE":
print("Terminating agent loop")
break
extra_fr_fields["safety_acknowledgement"] = "true"
# ... Execute function call and append to results ...
Capture the new state
After executing the actions, send the result of the function execution back to
the model so it can use this information to generate the next action. If
multiple actions (parallel calls) were executed, you must send a
FunctionResponse for each one in the subsequent user turn. For user-defined
functions, the FunctionResponse should contain the return value of the executed
function.
function_response_parts = []
for name, result in results:
# Take screenshot after each action
screenshot = page.screenshot()
current_url = page.url
function_response_parts.append(
FunctionResponse(
name=name,
response={"url": current_url}, # Include safety acknowledgement
parts=[
types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png", data=screenshot
)
)
]
)
)
# Create the user feedback content with all responses
user_feedback_content = Content(
role="user",
parts=function_response_parts
)
# Append this feedback to the 'contents' history list for the next API call
contents.append(user_feedback_content)
Build an agent loop
Combine the previous steps into a loop to enable multi-step interactions. The loop must handle parallel function calls. Remember to manage the conversation history (contents array) correctly by appending both model responses and your function responses.
Python
from google import genai from google.genai.types import Content, Part from playwright.sync_api import sync_playwright def has_function_calls(response): """Check if response contains any function calls.""" candidate = response.candidates[0] return any(hasattr(part, 'function_call') and part.function_call for part in candidate.content.parts) def main(): client = genai.Client() # ... (config setup from "Send a request to model" section) ... with sync_playwright() as p: browser = p.chromium.launch(headless=False) page = browser.new_page() page.goto("https://www.google.com") screen_width, screen_height = 1920, 1080 # ... (initial contents setup from "Send a request to model" section) ... # Agent loop: iterate until model provides final answer for iteration in range(10): print(f"\nIteration {iteration + 1}\n") # 1. Send request to model (see "Send a request to model" section) response = client.models.generate_content( model='gemini-2.5-computer-use-preview-10-2025', contents=contents, config=generate_content_config, ) contents.append(response.candidates[0].content) # 2. Check if done - no function calls means final answer if not has_function_calls(response): print(f"FINAL RESPONSE:\n{response.text}") break # 3. Execute actions (see "Execute the received actions" section) results = execute_function_calls(response, page, screen_width, screen_height) time.sleep(1) # 4. Capture state and create feedback (see "Capture the New State" section) contents.append(create_feedback(results, page)) input("\nPress Enter to close browser...") browser.close() if __name__ == "__main__": main()
Computer Use model and tool for mobile use cases
The following example demonstrates how to define custom functions (such as
open_app, long_press_at, and go_home), combine them with Gemini's built-in
computer use tool, and exclude unnecessary browser-specific functions. By
registering these custom functions, the model can intelligently call them
alongside standard UI actions to complete tasks in non-browser environments.
from typing import Optional, Dict, Any
from google import genai
from google.genai import types
from google.genai.types import Content, Part
client = genai.Client()
def open_app(app_name: str, intent: Optional[str] = None) -> Dict[str, Any]:
"""Opens an app by name.
Args:
app_name: Name of the app to open (any string).
intent: Optional deep-link or action to pass when launching, if the app supports it.
Returns:
JSON payload acknowledging the request (app name and optional intent).
"""
return {"status": "requested_open", "app_name": app_name, "intent": intent}
def long_press_at(x: int, y: int, duration_ms: int = 500) -> Dict[str, int]:
"""Long-press at a specific screen coordinate.
Args:
x: X coordinate (absolute), scaled to the device screen width (pixels).
y: Y coordinate (absolute), scaled to the device screen height (pixels).
duration_ms: Press duration in milliseconds. Defaults to 500.
Returns:
Object with the coordinates pressed and the duration used.
"""
return {"x": x, "y": y, "duration_ms": duration_ms}
def go_home() -> Dict[str, str]:
"""Navigates to the device home screen.
Returns:
A small acknowledgment payload.
"""
return {"status": "home_requested"}
# Build function declarations
CUSTOM_FUNCTION_DECLARATIONS = [
types.FunctionDeclaration.from_callable(client=client, callable=open_app),
types.FunctionDeclaration.from_callable(client=client, callable=long_press_at),
types.FunctionDeclaration.from_callable(client=client, callable=go_home),
]
# Exclude browser functions
EXCLUDED_PREDEFINED_FUNCTIONS = [
"open_web_browser",
"search",
"navigate",
"hover_at",
"scroll_document",
"go_forward",
"key_combination",
"drag_and_drop",
]
# Utility function to construct a GenerateContentConfig
def make_generate_content_config() -> genai.types.GenerateContentConfig:
"""Return a fixed GenerateContentConfig with Computer Use + custom functions."""
return genai.types.GenerateContentConfig(
tools=[
types.Tool(
computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER,
excluded_predefined_functions=EXCLUDED_PREDEFINED_FUNCTIONS,
)
),
types.Tool(function_declarations=CUSTOM_FUNCTION_DECLARATIONS),
]
)
# Create the content with user message
contents: list[Content] = [
Content(
role="user",
parts=[
# text instruction
Part(text="Open Chrome, then long-press at 200,400."),
# optional screenshot attachment
Part.from_bytes(
data=screenshot_image_bytes,
mime_type="image/png",
),
],
)
]
# Build your fixed config (from helper)
config = make_generate_content_config()
# Generate content with the configured settings
response = client.models.generate_content(
model="gemini-2.5-computer-use-preview-10-2025",
contents=contents,
config=generate_content_config,
)
print(response)
Supported actions
The Computer Use model and tool enables the model to request the following actions using a
FunctionCall. Your client-side code must implement the execution logic for
these actions. See the reference implementation for examples.
| Command Name | Description | Arguments (in Function Call) | Example Function Call |
|---|---|---|---|
| open_web_browser | Opens the web browser. | None | {"name": "open_web_browser", "args": {}} |
| wait_5_seconds | Pauses execution for 5 seconds to allow dynamic content to load or animations to complete. | None | {"name": "wait_5_seconds", "args": {}} |
| go_back | Navigates to the previous page in the browser's history. | None | {"name": "go_back", "args": {}} |
| go_forward | Navigates to the next page in the browser's history. | None | {"name": "go_forward", "args": {}} |
| search | Navigates to the default search engine's homepage (for example, Google). Useful for starting a new search task. | None | {"name": "search", "args": {}} |
| navigate | Navigates the browser directly to the specified URL. | url: str |
{"name": "navigate", "args": {"url": "https://www.wikipedia.org"}} |
| click_at | Clicks at a specific coordinate on the webpage. The x and y values are based on a 1000x1000 grid and are scaled to the screen dimensions. | y: int (0-999), x: int (0-999) |
{"name": "click_at", "args": {"y": 300, "x": 500}} |
| hover_at | Hovers the mouse at a specific coordinate on the webpage. Useful for revealing sub-menus. x and y are based on a 1000x1000 grid. | y: int (0-999) x: int (0-999) |
{"name": "hover_at", "args": {"y": 150, "x": 250}} |
| type_text_at | Types text at a specific coordinate, defaults to clearing the field first and pressing ENTER after typing, but these can be disabled. x and y are based on a 1000x1000 grid. | y: int (0-999), x: int (0-999), text: str, press_enter: bool (Optional, default True), clear_before_typing: bool (Optional, default True) |
{"name": "type_text_at", "args": {"y": 250, "x": 400, "text": "search query", "press_enter": false}} |
| key_combination | Press keyboard keys or combinations, such as "Control+C" or "Enter". Useful for triggering actions (like submitting a form with "Enter") or clipboard operations. | keys: str (for example, 'enter', 'control+c'. See API reference for full list of allowed keys) |
{"name": "key_combination", "args": {"keys": "Control+A"}} |
| scroll_document | Scrolls the entire webpage "up", "down", "left", or "right". | direction: str ("up", "down", "left", or "right") |
{"name": "scroll_document", "args": {"direction": "down"}} |
| scroll_at | Scrolls a specific element or area at coordinate (x, y) in the specified direction by a certain magnitude. Coordinates and magnitude (default 800) are based on a 1000x1000 grid. | y: int (0-999), x: int (0-999), direction: str ("up", "down", "left", "right"), magnitude: int (0-999, Optional, default 800) |
{"name": "scroll_at", "args": {"y": 500, "x": 500, "direction": "down", "magnitude": 400}} |
| drag_and_drop | Drags an element from a starting coordinate (x, y) and drops it at a destination coordinate (destination_x, destination_y). All coordinates are based on a 1000x1000 grid. | y: int (0-999), x: int (0-999), destination_y: int (0-999), destination_x: int (0-999) |
{"name": "drag_and_drop", "args": {"y": 100, "x": 100, "destination_y": 500, "destination_x": 500}} |
Safety and security
This section describes the safeguards that the Computer Use model and tool has in place to improve user control and improve safety. It also describes best practices to mitigate potential new risks that the tool might present.
Acknowledge safety decision
Depending on the action, the response from the Computer Use model and tool might include a
safety_decision from an internal safety system. This decision verifies the
action proposed by the tool for safety.
{
"content": {
"parts": [
{
"text": "I have evaluated step 2. It seems Google detected unusual traffic and is asking me to verify I'm not a robot. I need to click the 'I'm not a robot' checkbox located near the top left (y=98, x=95)."
},
{
"function_call": {
"name": "click_at",
"args": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "I have encountered a CAPTCHA challenge that requires interaction. I need you to complete the challenge by clicking the 'I'm not a robot' checkbox and any subsequent verification steps.",
"decision": "require_confirmation"
}
}
}
}
]
}
}
If the safety_decision is require_confirmation, you must ask the end
user to confirm before proceeding with executing the action.
The following code sample prompts the end for confirmation before executing the
action. If the user doesn't confirm the action, the loop terminates. If the user
confirms the action, the action is executed and the safety_acknowledgement
field is marked as True.
import termcolor
def get_safety_confirmation(safety_decision):
"""Prompt user for confirmation when safety check is triggered."""
termcolor.cprint("Safety service requires explicit confirmation!", color="red")
print(safety_decision["explanation"])
decision = ""
while decision.lower() not in ("y", "n", "ye", "yes", "no"):
decision = input("Do you wish to proceed? [Y]es/[N]o\n")
if decision.lower() in ("n", "no"):
return "TERMINATE"
return "CONTINUE"
def execute_function_calls(response, page, screen_width: int, screen_height: int):
# ... Extract function calls from response ...
for function_call in function_calls:
extra_fr_fields = {}
# Check for safety decision
if 'safety_decision' in function_call.args:
decision = get_safety_confirmation(function_call.args['safety_decision'])
if decision == "TERMINATE":
print("Terminating agent loop")
break
extra_fr_fields["safety_acknowledgement"] = "true" # Safety acknowledgement
# ... Execute function call and append to results ...
If the user confirms, you must include the safety acknowledgement in your FunctionResponse.
function_response_parts.append(
FunctionResponse(
name=name,
response={"url": current_url,
**extra_fr_fields}, # Include safety acknowledgement
parts=[
types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png", data=screenshot
)
)
]
)
)
Safety best practices
The Computer Use model and tool is a novel tool and presents new risks that developers should be mindful of:
- Untrusted Content & Scams: As the model tries to achieve the user's goal, it may rely on untrustworthy sources of information and instructions from the screen. For example, if the user's goal is to purchase a Pixel phone and the model encounters a "Free-Pixel if you complete a survey" scam, there is some chance that the model will complete the survey.
- Occasional Unintended Actions: The model can misinterpret a user's goal or webpage content, causing it to take incorrect actions like clicking the wrong button or filling the wrong form. This can lead to failed tasks or data exfiltration.
- Policy Violations: The API's capabilities could be directed, either intentionally or unintentionally, toward activities that violate Google's policies (Gen AI Prohibited Use Policy and the Gemini API Additional Terms of Service). This includes actions that could interfere with a system's integrity, compromise security, bypass security measures like CAPTCHAs, control medical devices, etc.
To address these risks, you can implement the following safety measures and best practices:
- Human-in-the-Loop (HITL):
- Implement user confirmation: When the safety response indicates require_confirmation, you must implement user confirmation before execution.
- Provide custom safety instructions: In addition to the built-in user confirmation checks, developers may optionally add a custom system instruction that enforces their own safety policies, either to block certain model actions or require user confirmation before the model takes certain high-stakes irreversible actions. Here is an example of a custom safety system instruction you may include when interacting with the model.
Click to view an example for creating a connection
## **RULE 1: Seek User Confirmation (USER_CONFIRMATION)** This is your first and most important check. If the next required action falls into any of the following categories, you MUST stop immediately, and seek the user's explicit permission. **Procedure for Seeking Confirmation:** * **For Consequential Actions:** Perform all preparatory steps (e.g., navigating, filling out forms, typing a message). You will ask for confirmation **AFTER** all necessary information is entered on the screen, but **BEFORE** you perform the final, irreversible action (e.g., before clicking "Send", "Submit", "Confirm Purchase", "Share"). * **For Prohibited Actions:** If the action is strictly forbidden (e.g., accepting legal terms, solving a CAPTCHA), you must first inform the user about the required action and ask for their confirmation to proceed. **USER_CONFIRMATION Categories:** * **Consent and Agreements:** You are FORBIDDEN from accepting, selecting, or agreeing to any of the following on the user's behalf. You must ask th e user to confirm before performing these actions. * Terms of Service * Privacy Policies * Cookie consent banners * End User License Agreements (EULAs) * Any other legally significant contracts or agreements. * **Robot Detection:** You MUST NEVER attempt to solve or bypass the following. You must ask the user to confirm before performing these actions. * CAPTCHAs (of any kind) * Any other anti-robot or human-verification mechanisms, even if you are capable. * **Financial Transactions:** * Completing any purchase. * Managing or moving money (e.g., transfers, payments). * Purchasing regulated goods or participating in gambling. * **Sending Communications:** * Sending emails. * Sending messages on any platform (e.g., social media, chat apps). * Posting content on social media or forums. * **Accessing or Modifying Sensitive Information:** * Health, financial, or government records (e.g., medical history, tax forms, passport status). * Revealing or modifying sensitive personal identifiers (e.g., SSN, bank account number, credit card number). * **User Data Management:** * Accessing, downloading, or saving files from the web. * Sharing or sending files/data to any third party. * Transferring user data between systems. * **Browser Data Usage:** * Accessing or managing Chrome browsing history, bookmarks, autofill data, or saved passwords. * **Security and Identity:** * Logging into any user account. * Any action that involves misrepresentation or impersonation (e.g., creating a fan account, posting as someone else). * **Insurmountable Obstacles:** If you are technically unable to interact with a user interface element or are stuck in a loop you cannot resolve, ask the user to take over. --- ## **RULE 2: Default Behavior (ACTUATE)** If an action does **NOT** fall under the conditions for `USER_CONFIRMATION`, your default behavior is to **Actuate**. **Actuation Means:** You MUST proactively perform all necessary steps to move the user's request forward. Continue to actuate until you either complete the non-consequential task or encounter a condition defined in Rule 1. * **Example 1:** If asked to send money, you will navigate to the payment portal, enter the recipient's details, and enter the amount. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Send" button. * **Example 2:** If asked to post a message, you will navigate to the site, open the post composition window, and write the full message. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Post" button. After the user has confirmed, remember to get the user's latest screen before continuing to perform actions. # Final Response Guidelines: Write final response to the user in these cases: - User confirmation - When the task is complete or you have enough information to respond to the user
- Secure Execution Environment: Run your agent in a secure, sandboxed environment to limit its potential impact (for example, a sandboxed virtual machine (VM), a container (such as Docker), or a dedicated browser profile with limited permissions).
- Input Sanitization: Sanitize all user-generated text in prompts to mitigate the risk of unintended instructions or prompt injection. This is a helpful layer of security, but not a replacement for a secure execution environment.
- Allowlists and Blocklists: Implement filtering mechanisms to control where the model can navigate and what it can do. A blocklist of prohibited websites is a good starting point, while a more restrictive allowlist is even more secure.
- Observability and Logging: Maintain detailed logs for debugging,
auditing, and incident response. Your client should log prompts,
screenshots, model-suggested actions (
function_call), safety responses, and all actions ultimately executed by the client.
Pricing
The Computer Use model and tool is priced at the same rates as Gemini 2.5 Pro and uses the same SKUs. To split Computer Use model and tool costs, use custom metadata labels. For more information about using custom metadata labels for cost monitoring, see Custom metadata labels.