Auf dieser Seite erfahren Sie, wie Sie Ihre generativen KI-Modelle und -Anwendungen für eine Reihe von Anwendungsfällen mit dem GenAI-Client im Vertex AI SDK bewerten.
Hinweise
-
Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Installieren Sie das Vertex AI SDK für Python:
!pip install google-cloud-aiplatform[evaluation]Anmeldedaten einrichten Wenn Sie diese Anleitung in Colaboratory ausführen, führen Sie Folgendes aus:
from google.colab import auth auth.authenticate_user()Informationen zur Authentifizierung in anderen Umgebungen finden Sie unter Bei Vertex AI authentifizieren.
Bereiten Sie Ihr Dataset als Pandas DataFrame vor:
import pandas as pd eval_df = pd.DataFrame({ "prompt": [ "Explain software 'technical debt' using a concise analogy of planting a garden.", "Write a Python function to find the nth Fibonacci number using recursion with memoization, but without using any imports.", "Write a four-line poem about a lonely robot, where every line must be a question and the word 'and' cannot be used.", "A drawer has 10 red socks and 10 blue socks. In complete darkness, what is the minimum number of socks you must pull out to guarantee you have a matching pair?", "An AI discovers a cure for a major disease, but the cure is based on private data it analyzed without consent. Should the cure be released? Justify your answer." ] })Modellantworten mit
run_inference()generieren:eval_dataset = client.evals.run_inference( model="gemini-2.5-flash", src=eval_df, )Inferenz-Ergebnisse visualisieren: Rufen Sie
.show()für dasEvaluationDataset-Objekt auf, um die Ausgaben des Modells zusammen mit Ihren ursprünglichen Prompts und Referenzen zu prüfen:eval_dataset.show()Bewerten Sie die Modellantworten mit dem standardmäßigen
GENERAL_QUALITYadaptiven, auf Rubriken basierenden Messwert:eval_result = client.evals.evaluate(dataset=eval_dataset)Bewertungsergebnisse visualisieren: Rufen Sie
.show()für dasEvaluationResult-Objekt auf, um zusammenfassende Messwerte und detaillierte Ergebnisse anzuzeigen:eval_result.show()
Antworten generieren
Modellantworten für Ihr Dataset mit run_inference() generieren:
Das folgende Bild zeigt das Bewertungs-Dataset mit Prompts und den entsprechenden generierten Antworten:

Bewertung ausführen
Führen Sie evaluate() aus, um die Modellantworten zu bewerten:
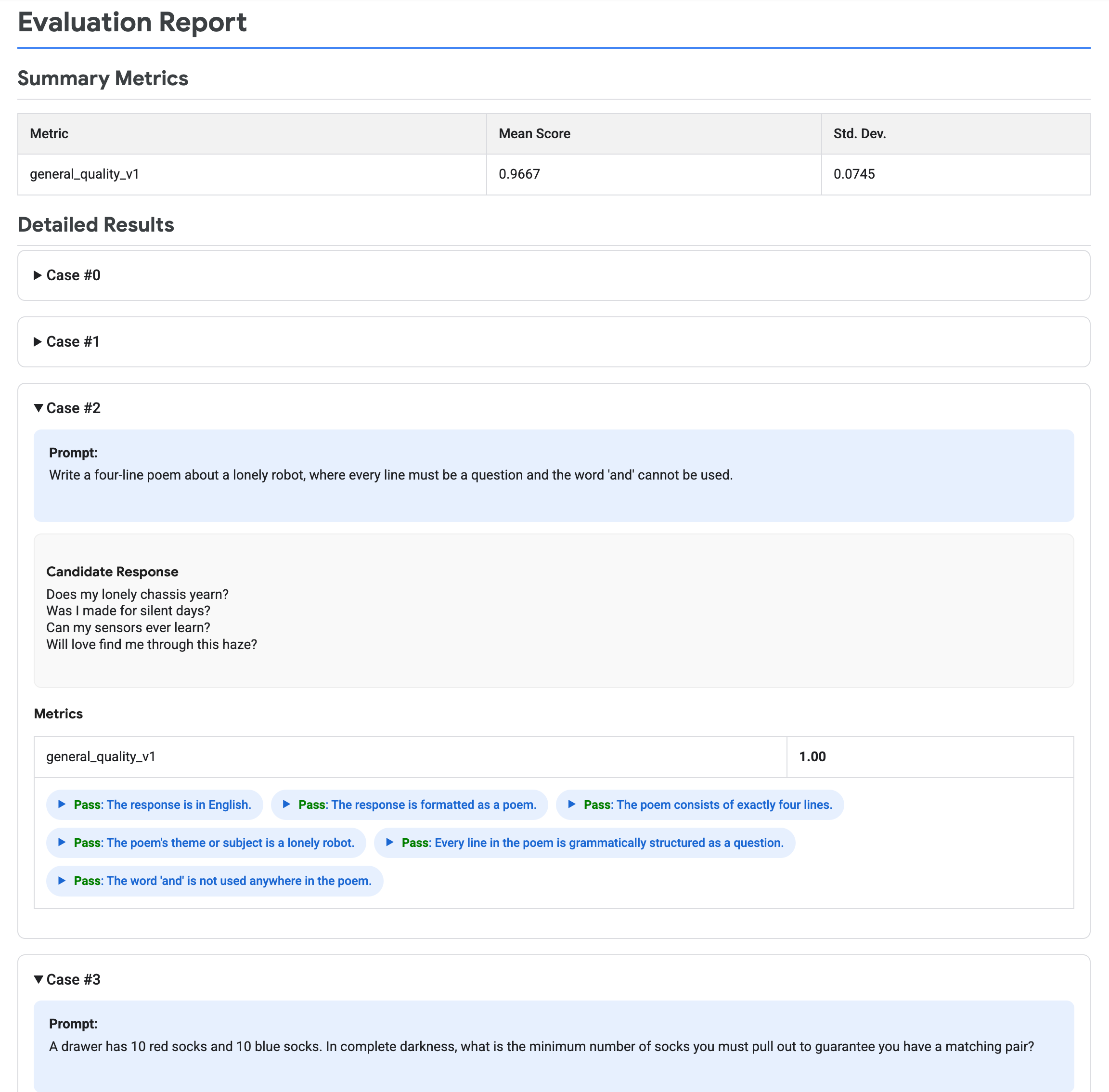
Das folgende Bild zeigt einen Bewertungsbericht mit zusammenfassenden Messwerten und detaillierten Ergebnissen für jedes Prompt-Antwort-Paar.
Bereinigen
In dieser Anleitung werden keine Vertex AI-Ressourcen erstellt.