Auf dieser Seite wird beschrieben, wie Sie die Ergebnisse der Modellbewertung nach der Ausführung der Modellbewertung mit dem Gen AI Evaluation Service ansehen und interpretieren.
Bewertungsergebnisse ansehen
Mit dem Gen AI Evaluation Service können Sie Ihre Bewertungsergebnisse direkt in Ihrer Entwicklungsumgebung visualisieren, z. B. in einem Colab- oder Jupyter-Notebook. Die .show()-Methode, die sowohl für EvaluationDataset- als auch für EvaluationResult-Objekte verfügbar ist, rendert einen interaktiven HTML-Bericht zur Analyse.
Generierte Rubriken in Ihrem Dataset visualisieren
Wenn Sie client.evals.generate_rubrics() ausführen, enthält das resultierende EvaluationDataset-Objekt eine rubric_groups-Spalte. Sie können dieses Dataset visualisieren, um die für jeden Prompt generierten Rubriken zu prüfen, bevor Sie die Bewertung ausführen.
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
Eine interaktive Tabelle wird mit jedem Prompt und den zugehörigen Rubriken angezeigt, die dafür generiert wurden. Sie sind in der Spalte rubric_groups verschachtelt:

Inferenz-Ergebnisse visualisieren
Nachdem Sie mit run_inference() Antworten generiert haben, können Sie .show() für das resultierende EvaluationDataset-Objekt aufrufen, um die Ausgaben des Modells zusammen mit Ihren ursprünglichen Prompts und Referenzen zu prüfen. Das ist nützlich für eine schnelle Qualitätsprüfung, bevor Sie eine vollständige Auswertung durchführen:
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
In einer Tabelle werden die einzelnen Prompts, die entsprechenden Referenzen (falls angegeben) und die neu generierten Antworten angezeigt:
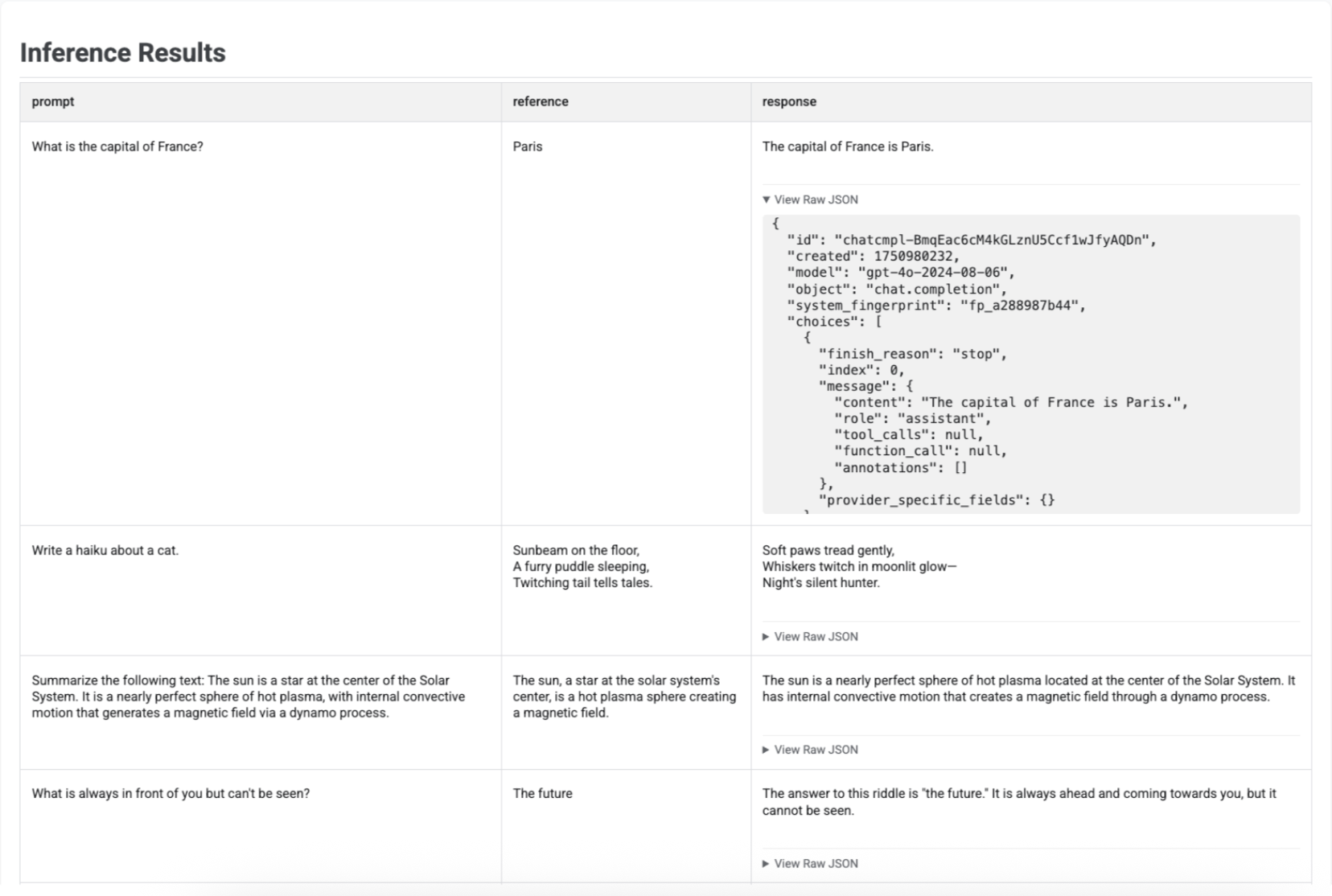
Bewertungsberichte visualisieren
Wenn Sie .show() für ein EvaluationResult-Objekt aufrufen, wird ein Bericht mit zwei Hauptabschnitten angezeigt:
Zusammenfassende Messwerte: Eine aggregierte Ansicht aller Messwerte mit dem mittleren Wert und der Standardabweichung für den gesamten Datensatz.
Detaillierte Ergebnisse: Eine Aufschlüsselung nach Fall, mit der Sie den Prompt, die Referenz, die Antwort des Kandidaten sowie die spezifische Punktzahl und Erklärung für jeden Messwert prüfen können.
Bericht zur Bewertung eines einzelnen Kandidaten
Bei einer einzelnen Modellbewertung enthält der Bericht die Werte für jeden Messwert:
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()
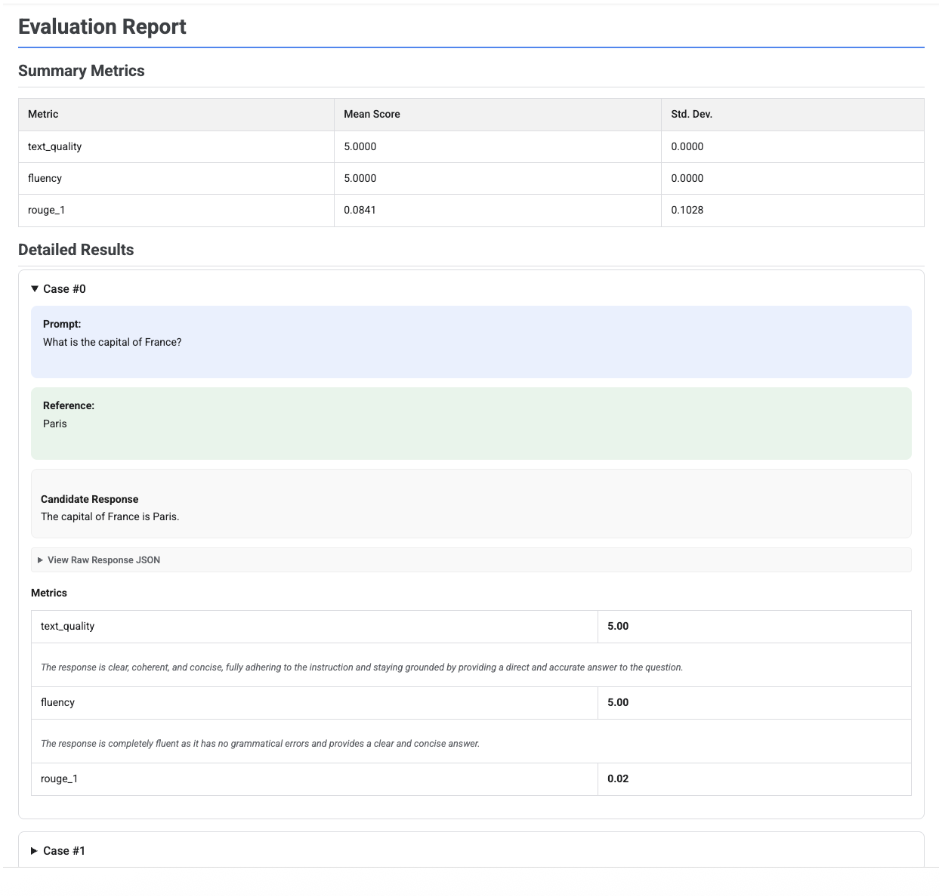
Bei allen Berichten können Sie den Bereich Roh-JSON ansehen maximieren, um die Daten in einem strukturierten Format wie dem Gemini- oder OpenAI Chat Completion API-Format zu prüfen.
Adaptiver rubrikbasierter Bewertungsbericht mit Ergebnissen
Bei der Verwendung von adaptiven rubrikbasierten Messwerten enthalten die Ergebnisse die Bestanden- oder Nicht bestanden-Bewertungen und die Begründung für jede auf die Antwort angewendete Rubrik.
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
Die Visualisierung zeigt für jeden Fall die einzelnen Rubriken, ihr Ergebnis („Bestanden“ oder „Nicht bestanden“) und die Begründung, die in den Messwertergebnissen verschachtelt ist. Für jedes spezifische Rubrikurteil können Sie eine Karte erweitern, um die unverarbeitete JSON-Nutzlast aufzurufen. Diese JSON-Nutzlast enthält zusätzliche Details wie die vollständige Rubrikbeschreibung, den Rubriktyp, die Wichtigkeit und die detaillierte Begründung für das Urteil.

Bericht zum Vergleich mehrerer Kandidaten
Das Format des Berichts wird angepasst, je nachdem, ob Sie einen einzelnen Kandidaten bewerten oder mehrere Kandidaten vergleichen. Bei einer Bewertung mit mehreren Kandidaten enthält der Bericht eine nebeneinanderliegende Ansicht und in der Übersichtstabelle werden die Gewinn- oder Gleichstandraten berechnet.
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()
