text-to-image AI
コードを 1 行も書かずにテキストから画像を作成、編集する
画像生成モデル Gemini 3 Pro Image や Imagen を、Python、Java、Go の各プログラミング言語で利用可能な API で使用して、テキストの説明から画像を数秒で生成、編集しましょう。
Gemini Enterprise Agent Platform で画像の生成などにご利用いただける無料クレジット最大 $300 分を新規のお客様に差し上げます。
概要
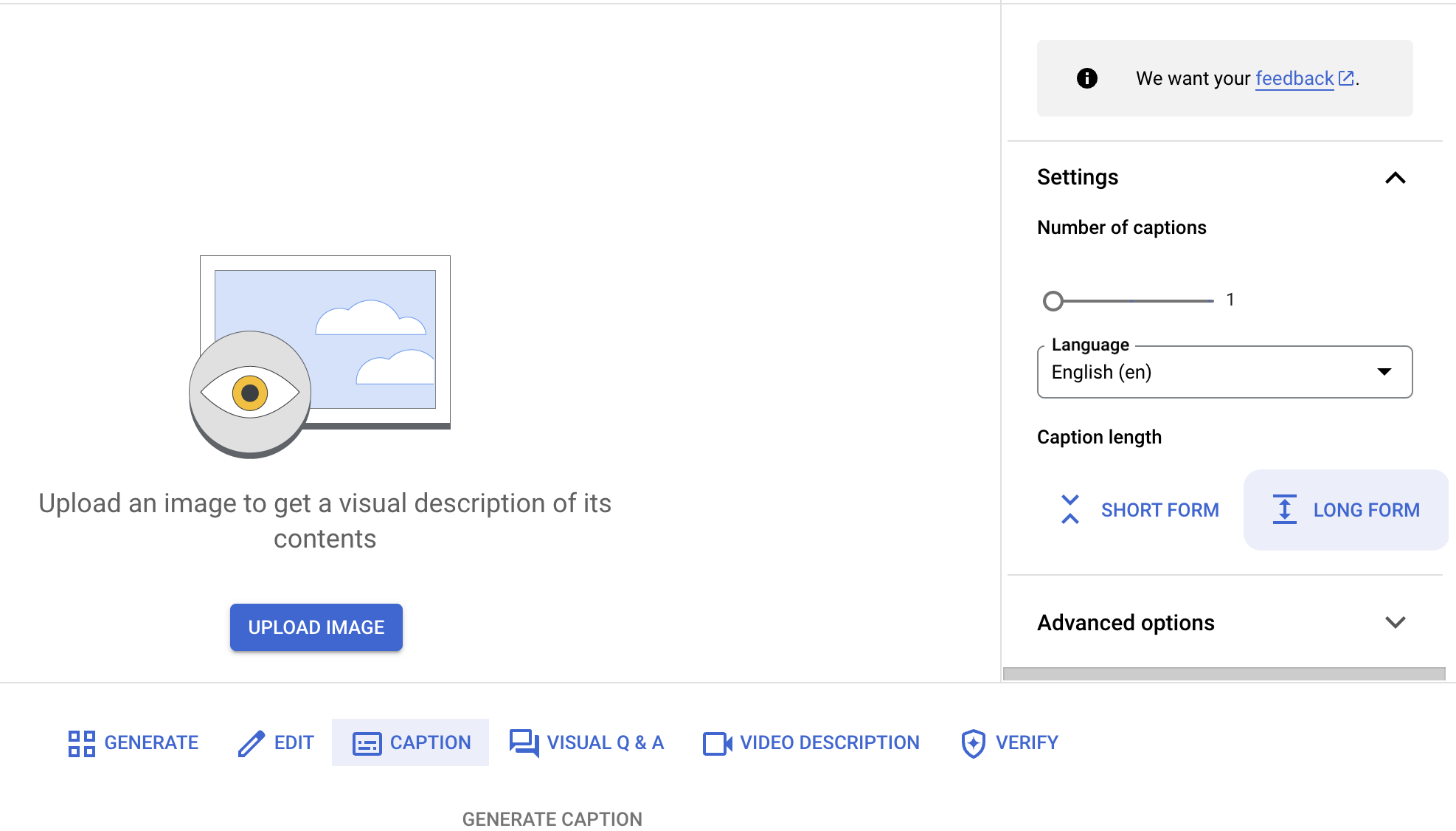
text-to-image AI とは何か?
テキスト画像変換の AI は、テキストの説明から画像を生成して編集できる AI の一種です。このテクノロジーは、ビジュアル コンテンツの操作や作成の方法を変える可能性を秘めています。Google Cloud の Text-to-AI ツールとリソースは、Agent Platform で利用可能な Imagen、Gemini 3 Pro Image、Veo などの事前トレーニング済み AI モデルを含め、デベロッパーがテキストから画像の生成を簡単に実装できるように設計されています。
text-to-image はアプリケーション開発でどのように使用されますか?
アプリケーション開発でテキスト画像変換 AI を使用して、モックアップ、プロトタイプ、イラスト、テストデータ、教育コンテンツ、デバッグ用の可視化を生成できます。開発者は、Google Cloud の Agent Platform と Cloud Vision API を使用して、テキスト検出、オブジェクト検出、画像分類などの一連の画像処理機能にアクセスできます。Document AI を使用してスキャンしたドキュメントからテキストを抽出し、テキストの説明画像を生成できます。
これらの Google モデルを使用する方法は?
これらのテキスト画像変換の AI モデルには、Google Cloud の Agent Platform または Google AI Studio からアクセスできます。このモデルを使用するには、テキスト プロンプトを入力してパラメータを選択し(一部のモデルでは、生成された画像のスタイル、独創性、精度を制御するパラメータを選択できます)、最後に画像を生成します。
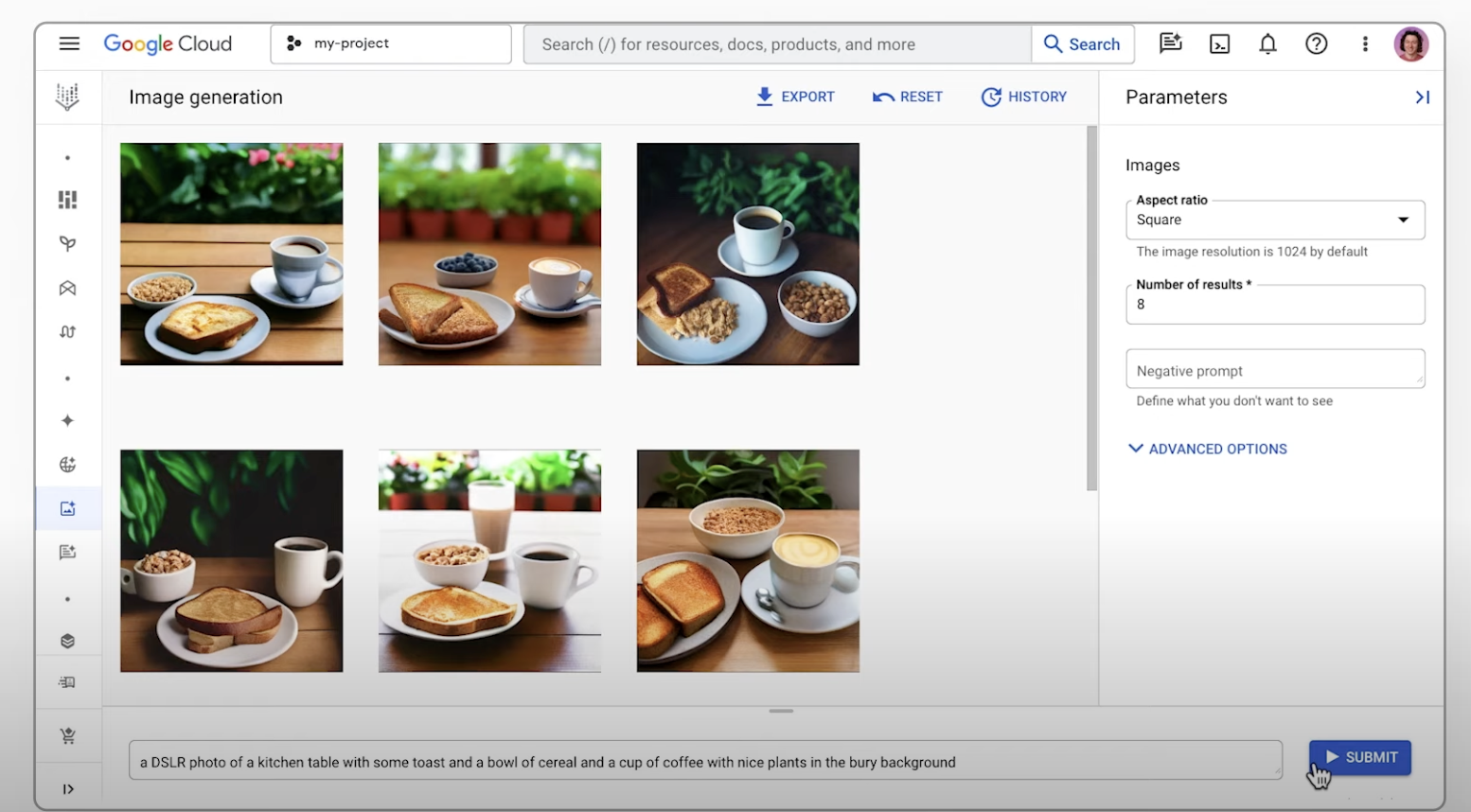
AI を使用して画像を生成する
テキスト プロンプトを使用して画像を生成する
Agent Platform で、Imagen のテキスト画像変換機能を使用し、生成された画像をアップスケールしてエクスポートする方法を学習します。このクイックスタートでは、Google Cloud コンソールで Imagen 画像生成機能を使用する方法について説明します。

入門ガイド
テキスト プロンプトを使用して画像を生成する
Agent Platform で、Imagen のテキスト画像変換機能を使用し、生成された画像をアップスケールしてエクスポートする方法を学習します。このクイックスタートでは、Google Cloud コンソールで Imagen 画像生成機能を使用する方法について説明します。
AI で画像を編集する
マルチ画像融合と会話型編集
Gemini を使用すると、複数の画像を組み合わせて、シームレスな新しいビジュアルを作成できます。複数の参照画像を使用して、単一の統合画像を作成します。簡単な自然言語で指示して画像を編集することもできます。グループ写真から人物を削除したり、汚れなどの小さなディテールを修正したりするなど、簡単な会話で変更できます。
また、Agent Platform の Imagen を使用すると、Imagen で生成された画像や既存の画像を編集できます。更新に関する説明テキストと変更する画像部分を指定することも(マスクベースの編集)できます。
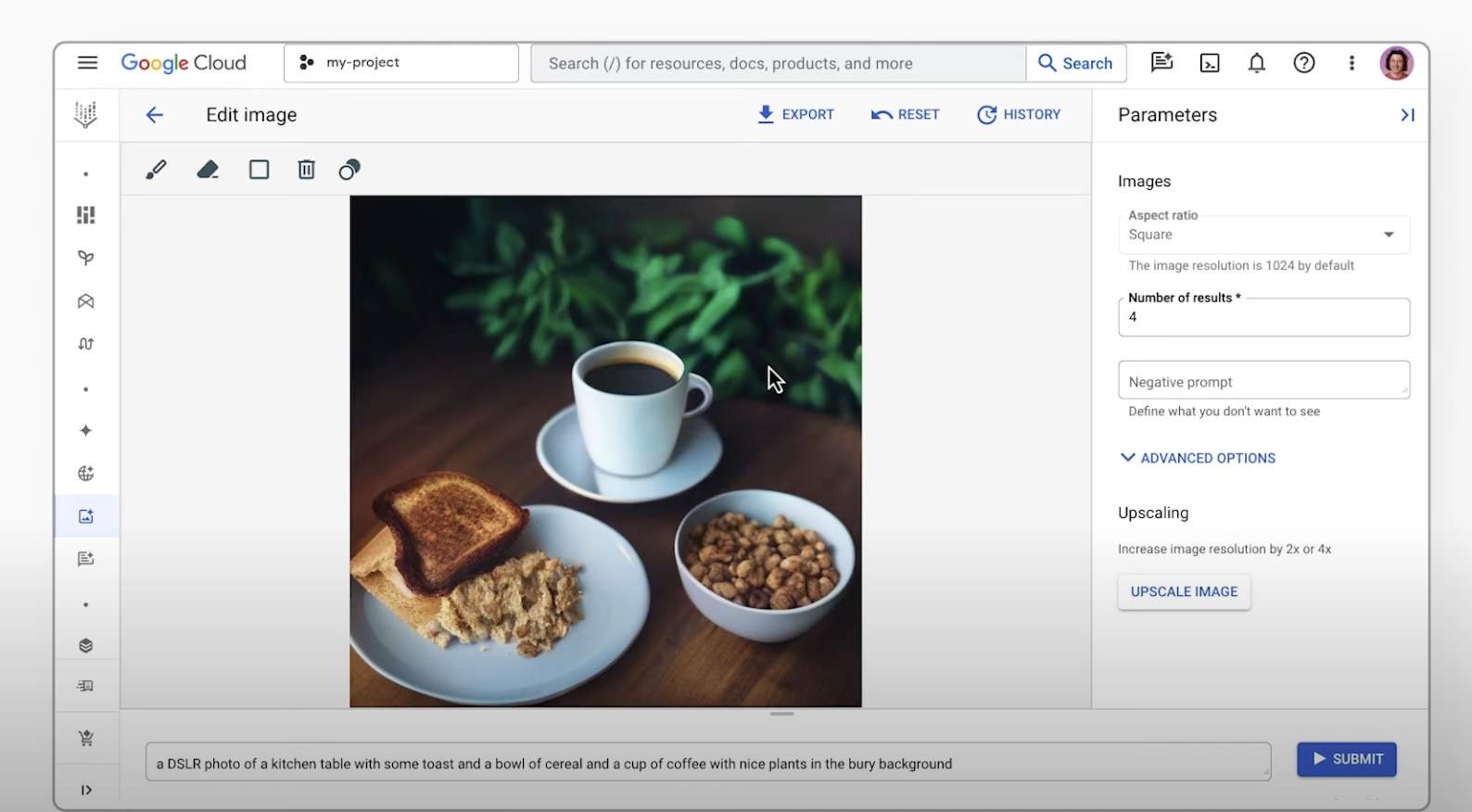
入門ガイド
マルチ画像融合と会話型編集
Gemini を使用すると、複数の画像を組み合わせて、シームレスな新しいビジュアルを作成できます。複数の参照画像を使用して、単一の統合画像を作成します。簡単な自然言語で指示して画像を編集することもできます。グループ写真から人物を削除したり、汚れなどの小さなディテールを修正したりするなど、簡単な会話で変更できます。
また、Agent Platform の Imagen を使用すると、Imagen で生成された画像や既存の画像を編集できます。更新に関する説明テキストと変更する画像部分を指定することも(マスクベースの編集)できます。