検索拡張生成(RAG)とは
RAG(検索拡張生成)は、従来の情報検索システム(検索やデータベースなど)の長所と、生成大規模言語モデル(LLM)の機能を組み合わせた AI フレームワークです。独自のデータと世界に関する知識を LLM の言語スキルと組み合わせることで、根拠のある生成はより精度が高く最新の、特定のニーズに関連したものとなります。この電子書籍をご覧になり、企業の実体を明らかにしましょう。
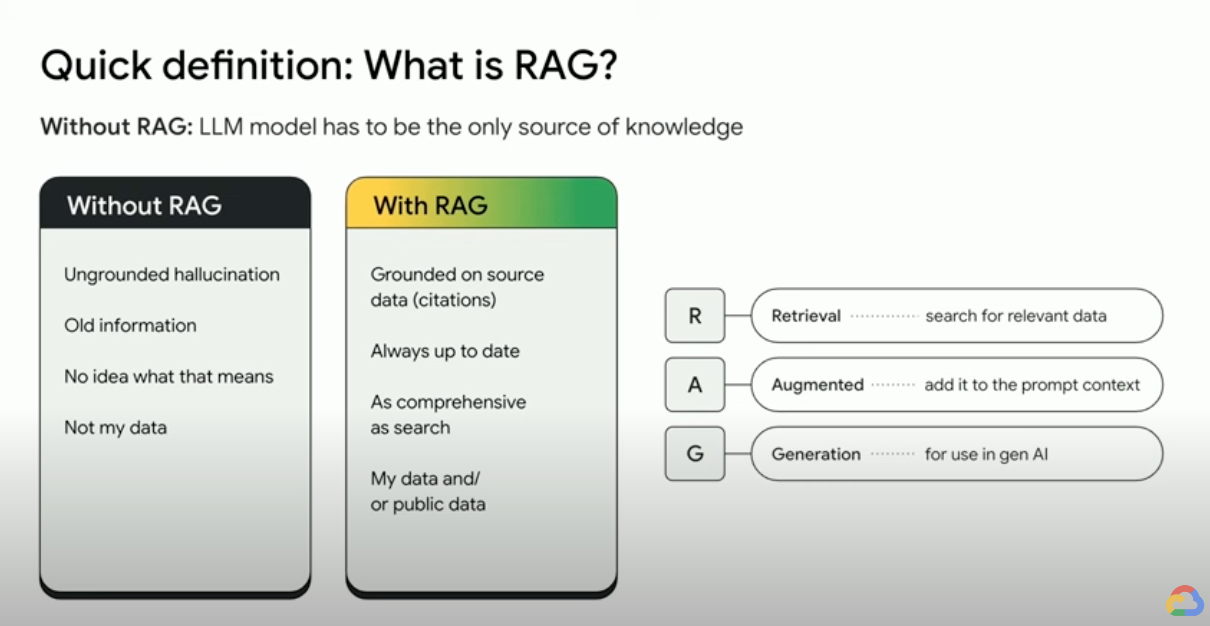
検索拡張生成の仕組み
RAG は、生成 AI の出力を強化するために、いくつかの主要な手順で動作します。
- 取得と前処理: RAG は、強力な検索アルゴリズムを活用して、ウェブページ、ナレッジベース、データベースなどの外部データをクエリします。関連情報が取得されると、トークン化、ステミング、ストップワードの削除などの前処理が行われます。
- 根拠に基づく生成: 取得された情報の前処理が終わると、事前トレーニング済みの LLM にシームレスに組み込まれます。この統合により、LLM のコンテキストが強化され、トピックをより包括的に理解できるようになります。この補強されたコンテキストにより、LLM はより正確で有益な、魅力的な回答を生成できるようになります。
RAG を使用する理由
RAG には、従来のテキスト生成方法を補完するいくつかの利点があります。特に、事実情報やデータドリブンな回答を扱う場合にその利点が生かされます。RAG を使用するとメリットがあることには、次のような主な理由があります。
新しい情報へのアクセス
LLM は、事前トレーニング済みデータに限定されます。そのため、情報が古く、不正確であることが考えられるレスポンスを生成する場合があります。RAG は、LLM に最新の情報を提供することによってこれを克服します。
事実に基づく根拠付け
LLM は、創造的で魅力的なテキストを生成するための優れたツールですが、事実の正確性については苦慮することになる場合があります。これは、LLM が大量のテキストデータでトレーニングされていて、そのテキストデータに不正確さやバイアスが含まれている可能性があるためです。
入力プロンプトの一部として LLM に「事実」を提示することで、「生成 AI のハルシネーション」を軽減できます。このアプローチの要点は、ユーザーの質問に答え、システムの指示と安全上の制約を遵守しつつ、最も関連性の高い事実が LLM に提示され、LLM の出力が完全にそれらの事実に基づいている状態を確保することです。
Gemini の長いコンテキスト ウィンドウ(LCW)を使用すると、LLM にソース マテリアルを提供できます。LCW に収まる量を超える情報を提供する必要がある場合や、パフォーマンスをスケールアップする必要がある場合は、トークンの数を減らし、時間と費用を節約できる RAG アプローチを使用します。
ベクトル データベースと関連性についての re-ranker を使用して検索する
RAG は通常、検索によって事実を取得します。最新の検索エンジンは、ベクトル データベースを活用して関連ドキュメントを効率的に取得するようになりました。ベクトル データベースは、ドキュメントをエンベディングとして高次元空間に保存し、セマンティックな類似性に基づいて高速かつ正確に検索できるようにします。マルチモーダル エンベディングは画像、音声、動画などに使用でき、これらのメディア エンベディングはテキスト エンベディングやマルチランゲージ エンベディングとともに取得できます。
Vertex AI Search などの高度な検索エンジンでは、セマンティック検索とキーワード検索を組み合わせて使用します(ハイブリッド検索と呼ばれます)。また、検索結果にスコアを付け、上位に返される結果が最も関連性が高い状態にする re-ranker も使用します。また、検索結果は、誤字のない明確で的を絞ったクエリで検索した方が向上します。そのため、高度な検索エンジンは、検索前にクエリを変換してスペルミスを修正します。
関連性、精度、品質
RAG の検索メカニズムは非常に重要です。キュレートされたナレッジベースの上に最適なセマンティック検索を構築して、取得された情報が入力クエリまたはコンテキストに関連している状態にする必要があります。取得した情報が無関係である場合、生成された情報は根拠があるものの、話題から外れているか、間違っている可能性があります。
RAG は、LLM をファインチューニングまたはプロンプト エンジニアリングして、すべて取得した知識に基づいてテキストを生成することで、生成されたテキストの矛盾や不整合を最小限に抑えます。これにより、生成されるテキストの品質が大幅に向上し、ユーザー エクスペリエンスが向上します。
Vertex Eval Service は、LLM で生成されたテキストと取得されたチャンクを「coherence」、「fluency」、「groundedness」、「safety」、「instruction_following」、「question_answering_quality」などの指標に基づいてスコア付けするようになりました。これらの指標によって、LLM から得られる根拠のあるテキストを測定できます(一部の指標については、提示したグラウンド トゥルースの回答と比較されます)。これらの評価を実施することで、ベースラインの測定値が得られ、検索エンジンの構成、ソースデータのキュレート、ソースレイアウト解析やチャンキング戦略の改善、検索前のユーザーの質問の精査などによって、RAG の品質を最適化できます。このような RAG の運用、指標重視のアプローチは、高品質な RAG と根拠のある生成を実現するための取り組みに活用できます。
RAG、エージェント、chatbot
RAG とグラウンディングは、最新のデータ、プライベートなデータ、または特殊なデータへのアクセスを必要とする LLM アプリケーションやエージェントに統合できます。外部の情報にアクセスすることで、RAG を利用した chatbot と会話エージェントが外部の知識を活用し、より包括的で情報に富み、コンテキストアウェアな回答を提供できるようにし、全体的なユーザー エクスペリエンスを向上させます。
生成 AI で構築する内容を差別化する要因は、データとユースケースです。RAG とグラウンディングにより、データを LLM に効率的かつスケーラブルに適用できます。
RAG に関連する Google Cloud プロダクトとサービス
検索拡張生成に関連する Google Cloud プロダクトは次のとおりです。
 Vertex AI RAG Engineコンテキスト拡張型 LLM アプリケーションを開発するためのデータ フレームワークで、検索拡張生成(RAG)を容易にします。
Vertex AI RAG Engineコンテキスト拡張型 LLM アプリケーションを開発するためのデータ フレームワークで、検索拡張生成(RAG)を容易にします。- Vertex AI SearchVertex AI Search は、データ向けの Google 検索であり、フルマネージド型の直ちに使用を開始できる検索および RAG ビルダーです。
- Vertex AI Vector SearchVertex AI Search の基盤となる超高性能ベクトル インデックス。大量のエンベディング コレクションから、高クエリレートかつ高再現率でセマンティック検索とハイブリッド検索、取得を可能にします。
 BigQueryVertex AI Vector Search 用のモデルなど、ML モデルのトレーニングに使用できる大規模なデータセット。
BigQueryVertex AI Vector Search 用のモデルなど、ML モデルのトレーニングに使用できる大規模なデータセット。- Grounded Generation APIGemini の高忠実度モードは、Google 検索またはインライン ファクトに基づくか、独自の検索エンジンを使用します。
 AlloyDB AIVertex AI でモデルを実行し、使い慣れた SQL クエリを使用してアプリケーションでアクセスします。Gemini などの Google モデル、または独自のカスタムモデルを使用します。
AlloyDB AIVertex AI でモデルを実行し、使い慣れた SQL クエリを使用してアプリケーションでアクセスします。Gemini などの Google モデル、または独自のカスタムモデルを使用します。
関連情報
以下のリソースで、検索拡張生成の使用について詳細をご確認ください。
- Vertex AI を使用して次世代の検索アプリケーションを構築する
- Google 検索のテクノロジーを活用した RAG
- Google Cloud データベースを使用した RAG
- 独自の検索および検索拡張生成(RAG)システムを構築するための API
- BigQuery で RAG を使用して LLM を強化する方法
- RAG に慣れるためのコードサンプルとクイックスタート
- Vertex AI とベクトル検索を使用した RAG 対応生成 AI アプリケーション用インフラストラクチャ
- Vertex AI と AlloyDB for PostgreSQL を使用した RAG 対応生成 AI アプリケーション用インフラストラクチャ
- GKE を使用した RAG 対応生成 AI アプリケーション用のインフラストラクチャ
開始にあたりサポートが必要な場合
お問い合わせ信頼できるパートナーと連携する
パートナーを探すもっと見る
すべてのプロダクトを見る











