多模态 AI
几乎能根据任何类型的内容生成文本、代码、视频、音频和图片
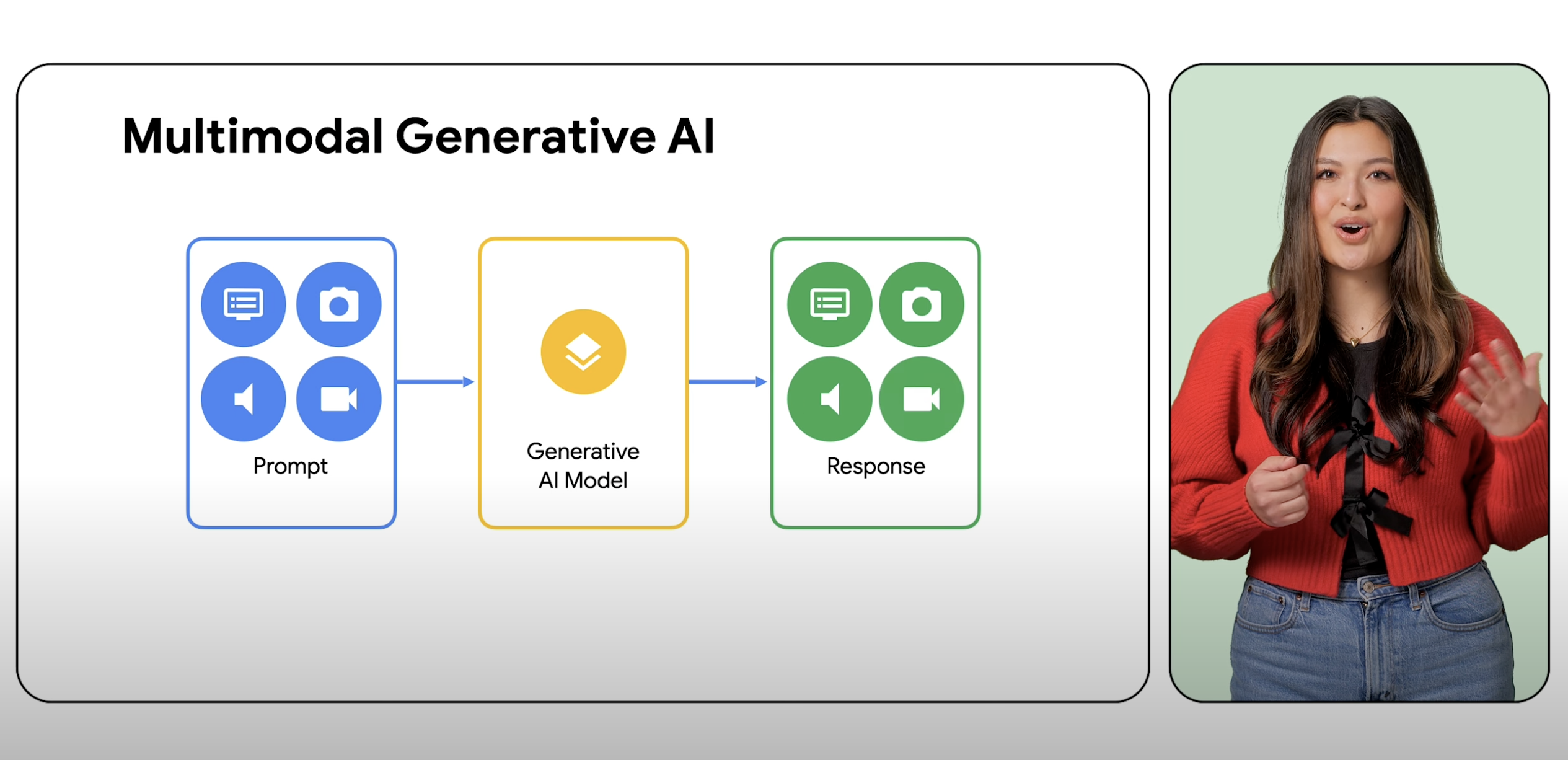
多模态模型可以将各种输入(包括文本、图片和音频)作为提示进行处理,并将这些提示转换为各种输出,而不仅仅是源类型。
新客户可获享最高 $300 赠金,用于在 Vertex AI 和其他 Google Cloud 产品中试用多模态模型。
概览
多模态 AI 的示例是哪些?
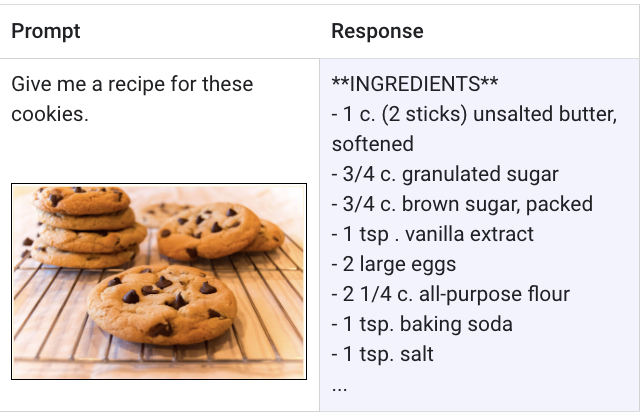
多模态模型是一种机器学习模型,能够处理来自不同模态的信息,包括图片、视频和文本。例如,Google 的多模态模型 Gemini 可以通过收到的饼干照片生成文字食谱作为回复,反之亦然。
生成式 AI 和多模态 AI 有什么不同?
生成式 AI 是一个概括性术语,是指使用机器学习模型来创建新内容,例如通常通过某种类型的提示生成文本、图片、音乐、音频和视频。多模态 AI 在这些生成功能的基础上进行扩展,能够处理来自图片、视频和文本等多种模态的信息。多模态可以视为赋予 AI 处理和理解不同感官模式的能力。实际上,这意味着用户可使用的输入和输出类型不限于一种,而且可以使用几乎任何输入来提示模型生成几乎任何类型的内容。
什么是可以使用图片作为提示的 AI?
Gemini 是 Google DeepMind 团队开发的多模态模型,不仅支持图片提示,还支持文本、代码和视频提示。Gemini 从设计之初就经过精心设计,能够跨文本、图片、视频、音频和代码无缝推理。Vertex AI 上的 Gemini 甚至可以根据提示从图片中提取文本、将图片文本转换为 JSON,以及针对上传的图片生成答案。
多模态 AI 的前景如何?为何它如此重要?
多模态 AI 和多模态模型代表开发者在新一代应用中构建和扩展 AI 功能方面的飞跃。例如,Gemini 可以理解、解释和生成采用全球热门编程语言(如 Python、Java、C++ 和 Go)的高质量代码,让开发者不必再专注于构建功能更丰富的应用。多模态 AI 的潜力也让全世界更接近一种新型 AI:它不再只是智能软件,而是更像一位专家型助手或助理。
多模态模型和多模态 AI 有哪些优势?
多模态 AI 的优势在于,它可以为开发者和用户提供更先进的推理、问题解决和生成能力。这些进步为新一代应用带来了无限可能,改变了我们的工作方式和生活方式。对于想要开始构建的开发者,Vertex AI Gemini API 提供了企业安全、数据驻留、性能和技术支持等功能。现有 Google Cloud 客户现可以在 Vertex AI 中开始使用 Gemini 发送提示。
工作方式
多模态模型能够理解和处理几乎任何输入,结合不同类型的信息,并生成几乎任何输出。例如,借助采用 Gemini 的 Vertex AI,用户可以通过文本、图片、视频或代码来生成提示,从而生成与最初输入内容不同的类型。
多模态模型能够理解和处理几乎任何输入,结合不同类型的信息,并生成几乎任何输出。例如,借助采用 Gemini 的 Vertex AI,用户可以通过文本、图片、视频或代码来生成提示,从而生成与最初输入内容不同的类型。
常见用途
尝试多模态提示
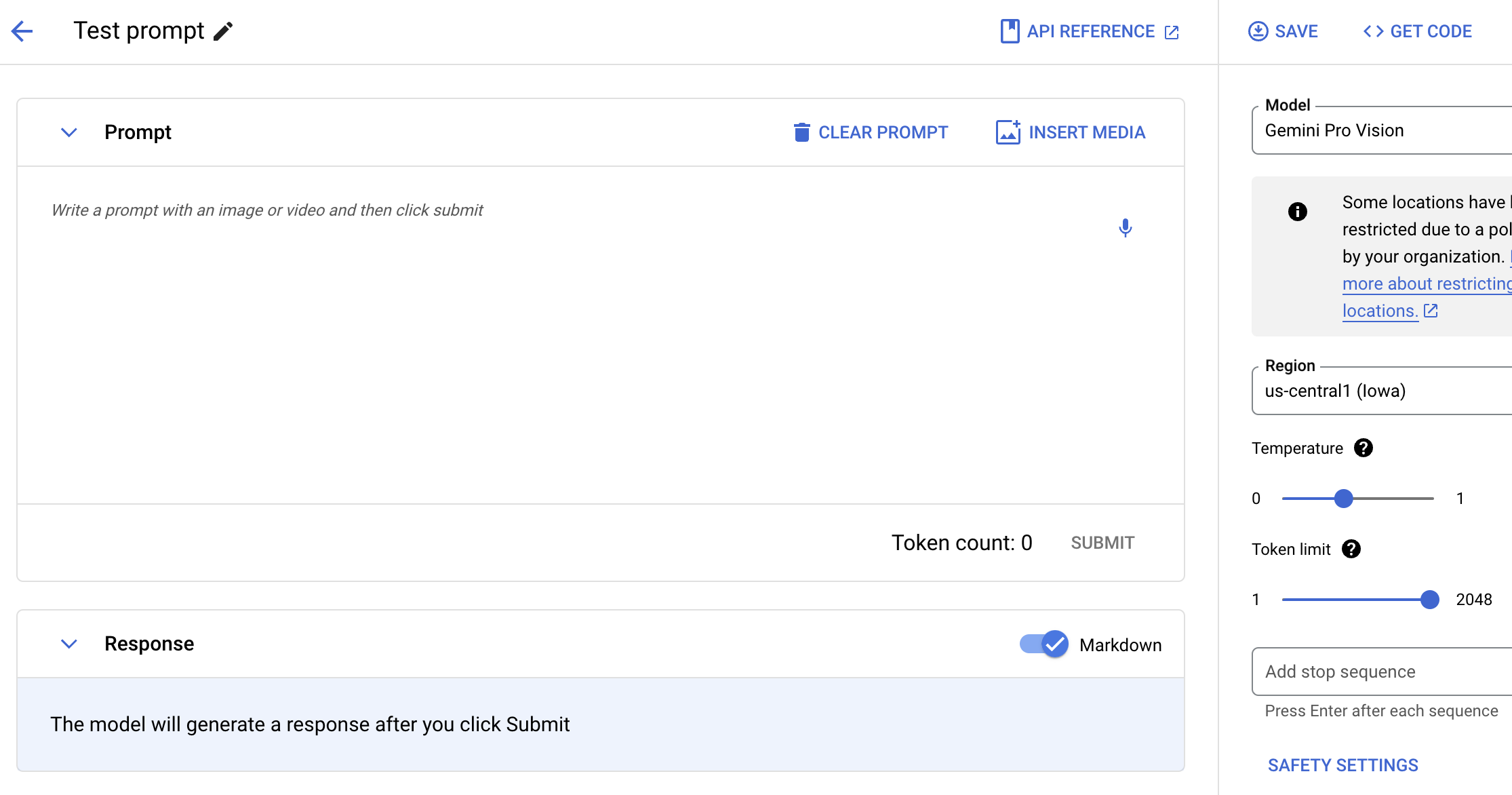
通过文字、图片和视频向 Gemini 发出提示
使用自然语言、代码或图片测试 Gemini 模型。您可以尝试使用示例提示从图片中提取文本、将图片文本转换为 JSON,甚至可以针对上传的图片生成答案,从而构建新一代 AI 应用。
方法指南
通过文字、图片和视频向 Gemini 发出提示
使用自然语言、代码或图片测试 Gemini 模型。您可以尝试使用示例提示从图片中提取文本、将图片文本转换为 JSON,甚至可以针对上传的图片生成答案,从而构建新一代 AI 应用。












