IA multimodal
Gere texto, código, vídeo, áudio e imagens de praticamente qualquer tipo de conteúdo
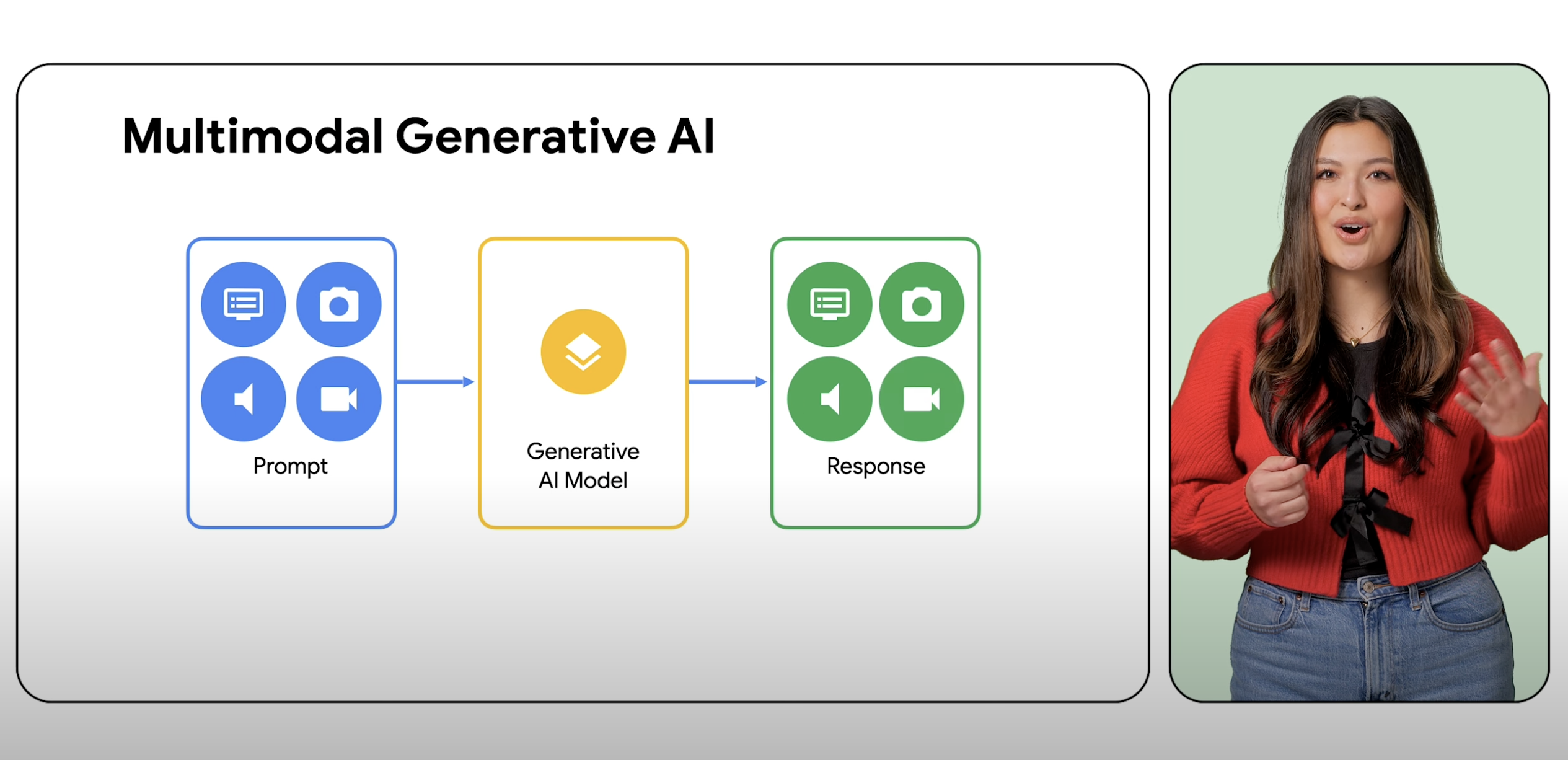
Os modelos multimodais podem processar uma ampla variedade de entradas, incluindo texto, imagens e áudio, como comandos e convertê-los em várias saídas, não apenas no tipo de origem.
Novos clientes ganham até US $300 em créditos para testar modelos multimodais na Vertex AI e em outros produtos do Google Cloud.
Visão geral
Qual é um exemplo de IA multimodal?
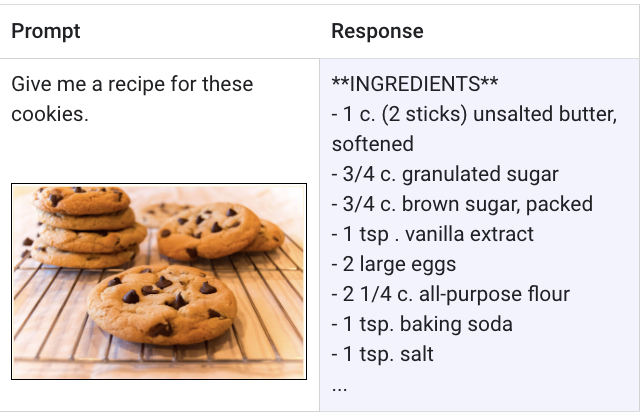
Um modelo multimodal é um modelo de ML (machine learning) capaz de processar informações de diferentes modalidades, incluindo imagens, vídeos e texto. Por exemplo, o Gemini, o modelo multimodal do Google, pode receber uma foto de um prato de biscoitos e gerar uma receita escrita como resposta e vice-versa.
Quais são as diferenças entre a IA generativa e a IA multimodal?
IA generativa é um termo abrangente para o uso de modelos de ML para criar novos conteúdos, como textos, imagens, músicas, áudios e vídeos, normalmente com um comando de um único tipo. A IA multimodal expande esses recursos generativos, processando informações de várias modalidades, incluindo imagens, vídeos e texto. A multimodalidade pode ser considerada uma atividade que dá à IA a capacidade de processar e entender diferentes modos sensoriais. Na prática, isso significa que os usuários não estão limitados a uma entrada e um tipo de saída e podem solicitar que um modelo com praticamente qualquer entrada gere praticamente qualquer tipo de conteúdo.
O que é uma IA que pode usar imagens como comando?
O Gemini é um modelo multimodal da equipe do Google DeepMind que pode receber comandos não apenas de imagens, mas também de texto, código e vídeo. O Gemini foi desenvolvido do zero para lidar perfeitamente com texto, imagens, vídeo, áudio e código. O Gemini na Vertex AI pode até usar comandos para extrair texto de imagens, converter o texto da imagem em JSON e gerar respostas sobre imagens enviadas.
Qual é o futuro da IA multimodal e por que ela é importante?
A IA multimodal e os modelos multimodais representam um salto na forma como os desenvolvedores criam e expandem a funcionalidade da IA na próxima geração de aplicativos. Por exemplo, o Gemini é capaz de entender, explicar e gerar código de alta qualidade nas linguagens de programação mais conhecidas do mundo, como Python, Java, C++ e Go. Assim, os desenvolvedores ficam livres para trabalhar na criação de aplicativos com muitos recursos. O potencial da IA multimodal também aproxima o mundo da IA, que é menos semelhante a um software inteligente e mais a um assistente especializado.
Quais são os benefícios dos modelos multimodais e da IA multimodal?
O benefício da IA multimodal é que ela oferece aos desenvolvedores e usuários uma IA com recursos mais avançados de raciocínio, solução de problemas e geração. Esses avanços oferecem infinitas possibilidades de como os aplicativos de última geração podem mudar a forma como trabalhamos e vivemos. Para desenvolvedores que querem começar a criar, a API Vertex AI Gemini oferece recursos como segurança empresarial, residência de dados, desempenho e suporte técnico. Os clientes atuais do Google Cloud podem começar a criar comandos com o Gemini na Vertex AI agora mesmo.
Como funciona
Um modelo multimodal é capaz de entender e processar praticamente qualquer entrada, combinando diferentes tipos de informações e gerando quase qualquer saída. Por exemplo, usando a Vertex AI com o Gemini, os usuários podem usar comando de texto, imagens, vídeo ou código para gerar tipos diferentes de conteúdo do que foi inserido originalmente.
Um modelo multimodal é capaz de entender e processar praticamente qualquer entrada, combinando diferentes tipos de informações e gerando quase qualquer saída. Por exemplo, usando a Vertex AI com o Gemini, os usuários podem usar comando de texto, imagens, vídeo ou código para gerar tipos diferentes de conteúdo do que foi inserido originalmente.
Usos comuns
Testar comandos multimodais
Comande o Gemini com texto, imagens e vídeo
Teste o modelo do Gemini usando linguagem natural, código ou imagens. Teste comandos de exemplo para extrair texto de imagens, converter texto de imagem em JSON e até gerar respostas sobre imagens enviadas para criar aplicativos de IA de última geração.
Tutoriais
Comande o Gemini com texto, imagens e vídeo
Teste o modelo do Gemini usando linguagem natural, código ou imagens. Teste comandos de exemplo para extrair texto de imagens, converter texto de imagem em JSON e até gerar respostas sobre imagens enviadas para criar aplicativos de IA de última geração.
Usar modelos multimodais
Comece a usar o Gemini, o modelo multimodal do Google
Tenha uma visão geral do uso do modelo multimodal no Google Cloud, pontos fortes e limitações do Gemini, informações de solicitações e solicitações e contagens de tokens.

Tutoriais
Comece a usar o Gemini, o modelo multimodal do Google
Tenha uma visão geral do uso do modelo multimodal no Google Cloud, pontos fortes e limitações do Gemini, informações de solicitações e solicitações e contagens de tokens.











