マルチモーダル AI
ほとんどのコンテンツ タイプからテキスト、コード、動画、音声、画像を生成する
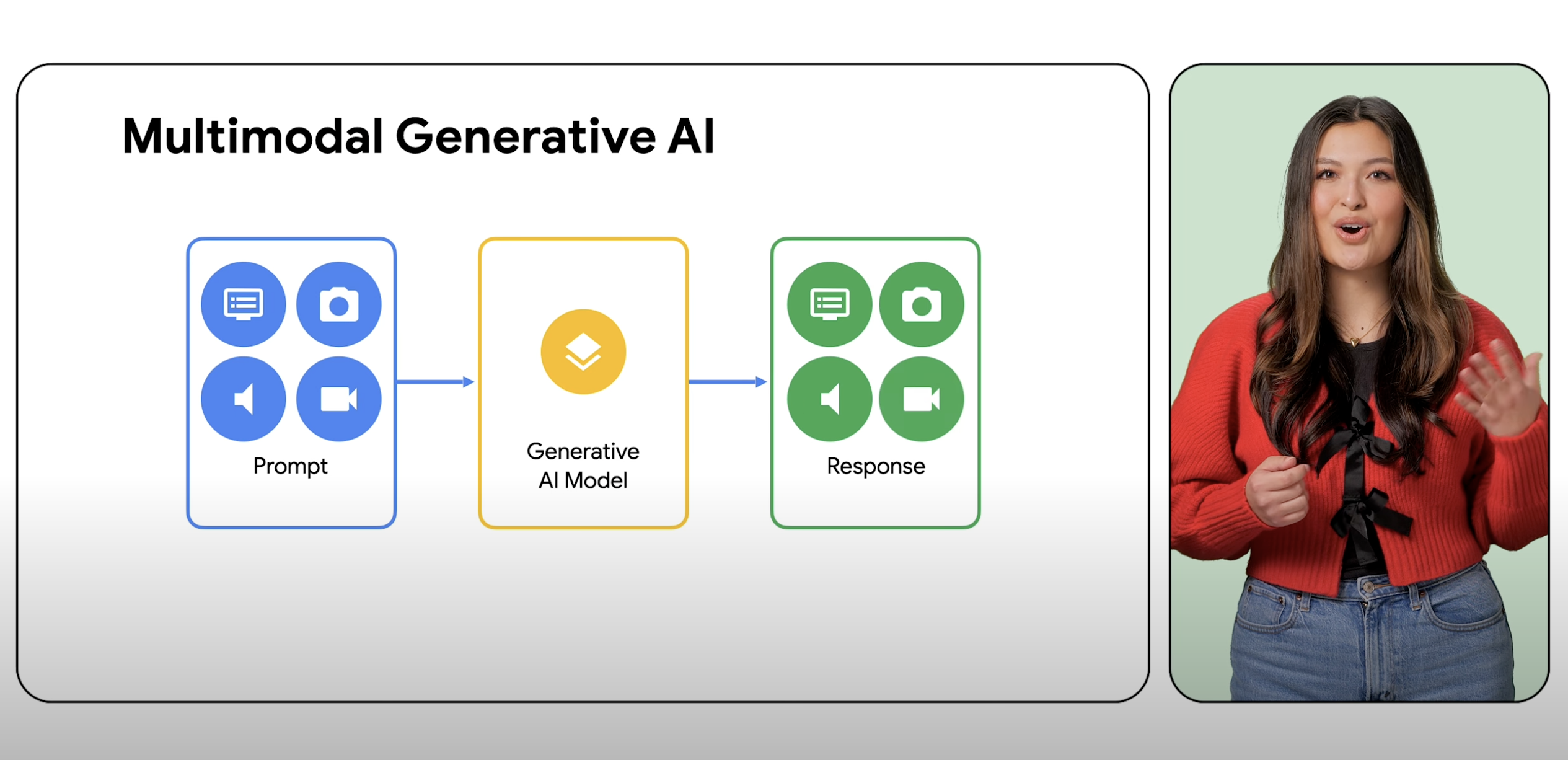
マルチモーダル モデルは、テキスト、画像、音声などの幅広い入力をプロンプトとして処理し、それらのプロンプトをソースタイプだけでなくさまざまな出力に変換できます。
新規のお客様には、Gemini Enterprise Agent Platform のマルチモーダル モデルやその他の Google Cloud プロダクトをお試しいただける無料クレジット最大 $300 分を差し上げます。

概要
マルチモーダル AI の例にはどのようなものがありますか?
マルチモーダル モデルは、画像、動画、テキストなど、異なるモダリティからの情報を処理できる ML(機械学習)モデルです。たとえば、Google のマルチモーダル モデルである Gemini は、クッキーの置かれた皿の写真を受け取って、記述されたレシピをレスポンスとして生成します。その逆も同様です。
生成 AI とマルチモーダル AI の違いは何ですか?
生成 AI とは、ML モデルを使用して、テキスト、画像、音楽、音声、動画などの新しいコンテンツを通常は単一の種類のプロンプトから作成することの総称です。マルチモーダル AI は、画像、動画、テキストなどの複数のモダリティからの情報を処理することで、こうした生成機能を拡張します。マルチモダリティは、AI に異なる感覚的モードを処理して理解する能力を与えるものと考えることができます。これは実質的に、ユーザーが 1 つの入力と 1 つの出力のタイプに制限されることなく、ほとんどの入力を備えるモデルに、ほとんどのコンテンツ タイプの生成をプロンプトできることを意味します。
画像をプロンプトとして使用できる AI はどれですか?
Gemini は、Google DeepMind のチームのマルチモーダル モデルで、画像だけでなく、テキスト、コード、動画でもプロンプトできます。Gemini は最初から設計されており、テキスト、画像、動画、音声、コードにわたってシームレスに推論できます。Gemini Enterprise エージェント プラットフォームでは、プロンプトを使用して画像からのテキスト抽出、画像テキストの JSON への変換、アップロードされた画像に関する回答の生成も行うことができます。
マルチモーダル AI の未来はどのようなもので、なぜ重要なのですか?
マルチモーダル AI とマルチモーダル モデルは、デベロッパーが次世代のアプリケーションで AI の機能を構築して拡張する方法の前進を示しています。たとえば、Gemini は Python、Java、C++、Go などの世界で最も普及しているプログラミング言語で高品質のコードを理解、説明、生成できるため、デベロッパーはより多くの機能を備えたアプリケーションの構築に取り組みたくなります。マルチモーダル AI の可能性は、スマート ソフトウェアというよりも、専門家のヘルパーやアシスタントのような AI に世界を近づけます。
マルチモーダル モデルとマルチモーダル AI の利点は何ですか?
マルチモーダル AI の利点は、より高度な推論、問題解決、生成の機能を備えた AI をデベロッパーとユーザーに提供することです。これらの進歩は、次世代のアプリケーションが私たちの働き方と生活様式を変える可能性に無限の可能性をもたらします。構築を開始しようとしているデベロッパーに、Gemini Enterprise Agent Platform API は、エンタープライズ セキュリティ、データ所在地、パフォーマンス、テクニカル サポートなどの機能を提供します。Google Cloud の既存のお客様は、今すぐエージェント プラットフォームで Gemini を使ってプロンプトを開始できます。
仕組み
マルチモーダル モデルは、ほとんどの入力を理解して処理し、異なる種類の情報を組み合わせ、ほとんどの出力を生成できます。たとえば、Agent Platform を使用すると、ユーザーは、テキスト、画像、動画、コードなどをプロンプトとして使用して、最初に入力したものとは異なるタイプのコンテンツを生成できます。
マルチモーダル モデルは、ほとんどの入力を理解して処理し、異なる種類の情報を組み合わせ、ほとんどの出力を生成できます。たとえば、Agent Platform を使用すると、ユーザーは、テキスト、画像、動画、コードなどをプロンプトとして使用して、最初に入力したものとは異なるタイプのコンテンツを生成できます。

マルチモーダル プロンプトを試す
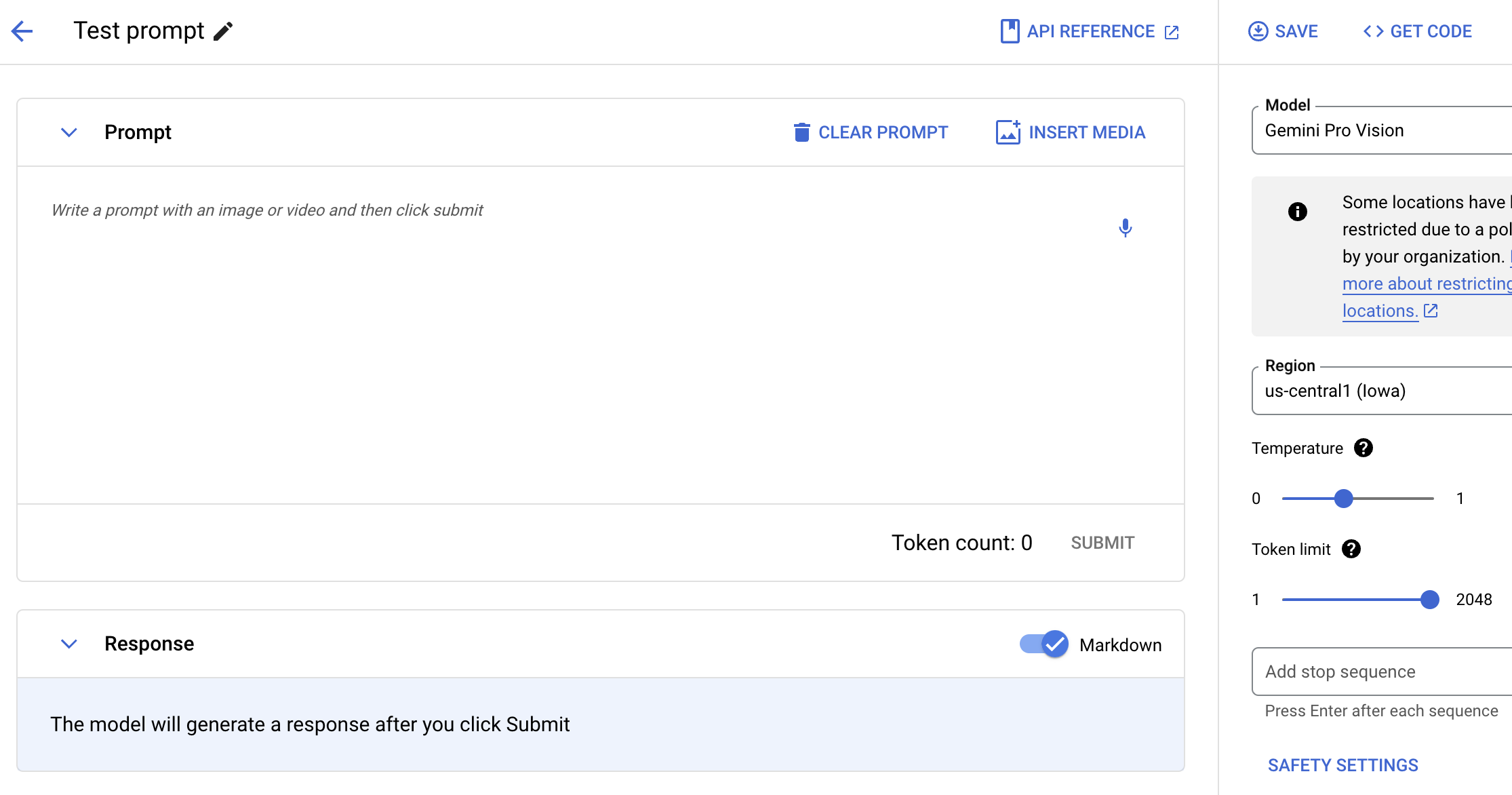
テキスト、画像、動画で Gemini にプロンプトする
自然言語、コード、画像を使用して Gemini モデルをテストします。画像からのテキスト抽出、画像テキストの JSON への変換、アップロードされた画像に関する回答の生成のためのサンプル プロンプトを、次世代の AI アプリケーションの構築にお試しください。
入門ガイド
テキスト、画像、動画で Gemini にプロンプトする
自然言語、コード、画像を使用して Gemini モデルをテストします。画像からのテキスト抽出、画像テキストの JSON への変換、アップロードされた画像に関する回答の生成のためのサンプル プロンプトを、次世代の AI アプリケーションの構築にお試しください。
マルチモーダル モデルを使用する
Google のマルチモーダル モデルである Gemini を使ってみる
Google Cloud でのマルチモーダル モデルの使用、Gemini の長所と制限、プロンプトとリクエストに関する情報、トークン数の概要を確認します。

入門ガイド
Google のマルチモーダル モデルである Gemini を使ってみる
Google Cloud でのマルチモーダル モデルの使用、Gemini の長所と制限、プロンプトとリクエストに関する情報、トークン数の概要を確認します。


















