IA multimodal
Genera texto, código, video, imágenes y audio a partir de prácticamente cualquier tipo de contenido
Los modelos multimodales pueden procesar una amplia variedad de entradas (como texto, imágenes y audio) en forma de instrucciones y convertirlas en varias salidas, no solo en el tipo de fuente.
Los clientes nuevos obtienen hasta $300 en créditos gratuitos para probar modelos multimodales en Gemini Enterprise Agent Platform y otros productos de Google Cloud.

Descripción general
¿Cuál es un ejemplo de IA multimodal?
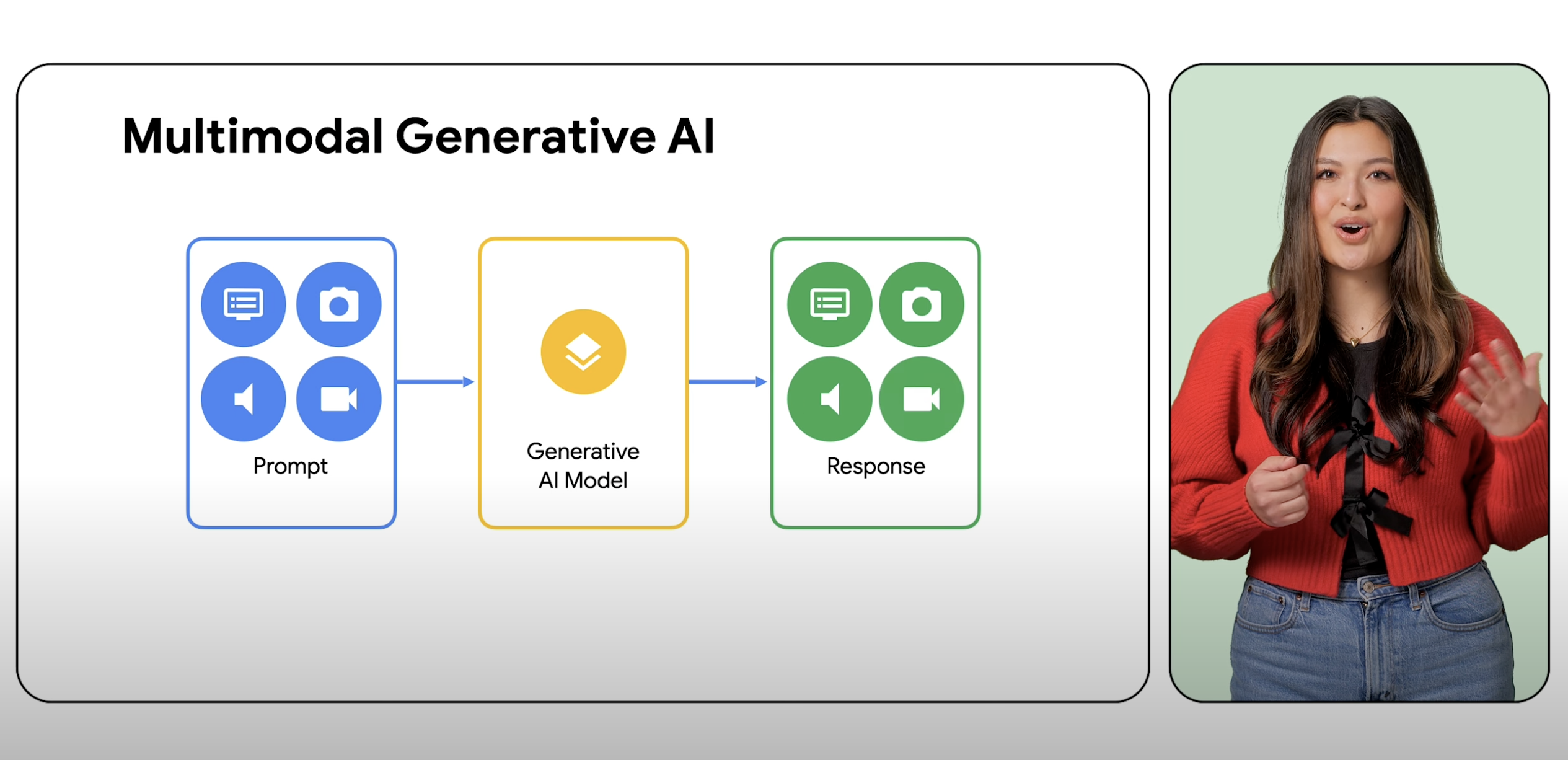
Un modelo multimodal es un modelo de AA (aprendizaje automático) que es capaz de procesar información de diferentes modalidades, lo que incluye imágenes, videos y texto. Por ejemplo, el modelo multimodal de Google, Gemini, puede recibir una foto de un plato de galletas y generar una receta escrita como respuesta, y viceversa.
¿Cuál es la diferencia entre la IA generativa y la IA multimodal?
La IA generativa es un término general para el uso de modelos de AA para crear contenido nuevo, como texto, imágenes, música, audio y videos, por lo general, a partir de una instrucción de un solo tipo. La IA multimodal amplía estas capacidades generativas y procesa información de múltiples modalidades, lo que incluye imágenes, videos y texto. La multimodalidad puede considerarse como la capacidad de la IA para procesar y comprender diferentes modos sensoriales. En la práctica, esto significa que los usuarios no están limitados a un tipo de entrada y un tipo de salida, y pueden escribir instrucciones en un modelo con prácticamente cualquier entrada para generar prácticamente cualquier tipo de contenido.
¿Cuál es una IA que puede usar imágenes como instrucciones?
Gemini es un modelo multimodal del equipo de Google DeepMind que puede recibir instrucciones con imágenes, texto, código y video. Gemini se diseñó desde cero para razonar sin problemas en texto, imágenes, video, audio y código. Gemini Enterprise Agent Platform puede incluso usar instrucciones para extraer texto de imágenes, convertir texto de imágenes a JSON y generar respuestas sobre las imágenes subidas.
¿Cuál es el futuro de la IA multimodal y por qué es importante?
La IA multimodal y los modelos multimodales representan un avance en la forma en que los desarrolladores compilan y expanden la funcionalidad de la IA en la nueva generación de aplicaciones. Por ejemplo, Gemini puede entender, explicar y generar código de alta calidad en los lenguajes de programación más populares del mundo, como Python, Java, C++ y Go, lo que libera a los desarrolladores para que trabajen en la creación de aplicaciones con más funciones. El potencial de la IA multimodal también lleva al mundo a una IA que se parece menos a un software inteligente y más a un asistente o ayudante experto.
¿Cuáles son los beneficios de los modelos multimodales y la IA multimodal?
Los beneficios de la IA multimodal son que ofrece a los desarrolladores y usuarios una IA con capacidades de razonamiento, resolución de problemas y generación más avanzadas. Estos avances brindan posibilidades infinitas sobre cómo las aplicaciones de nueva generación pueden cambiar la forma en que trabajamos y vivimos. Para los desarrolladores que buscan comenzar a crear, la API de Gemini Enterprise Agent Platform ofrece funciones como seguridad empresarial, residencia de datos, rendimiento y asistencia técnica. Los clientes existentes de Google Cloud pueden escribir instrucciones con Gemini en Agent Platform ahora mismo.
Cómo funciona
Un modelo multimodal es capaz de comprender y procesar prácticamente cualquier entrada, combinar diferentes tipos de información y generar casi cualquier resultado. Por ejemplo, con Agent Platform, los usuarios pueden escribir instrucciones con texto, imágenes, videos o código para generar diferentes tipos de contenido que no sean los que se ingresaron originalmente.
Un modelo multimodal es capaz de comprender y procesar prácticamente cualquier entrada, combinar diferentes tipos de información y generar casi cualquier resultado. Por ejemplo, con Agent Platform, los usuarios pueden escribir instrucciones con texto, imágenes, videos o código para generar diferentes tipos de contenido que no sean los que se ingresaron originalmente.

Prueba las instrucciones multimodales
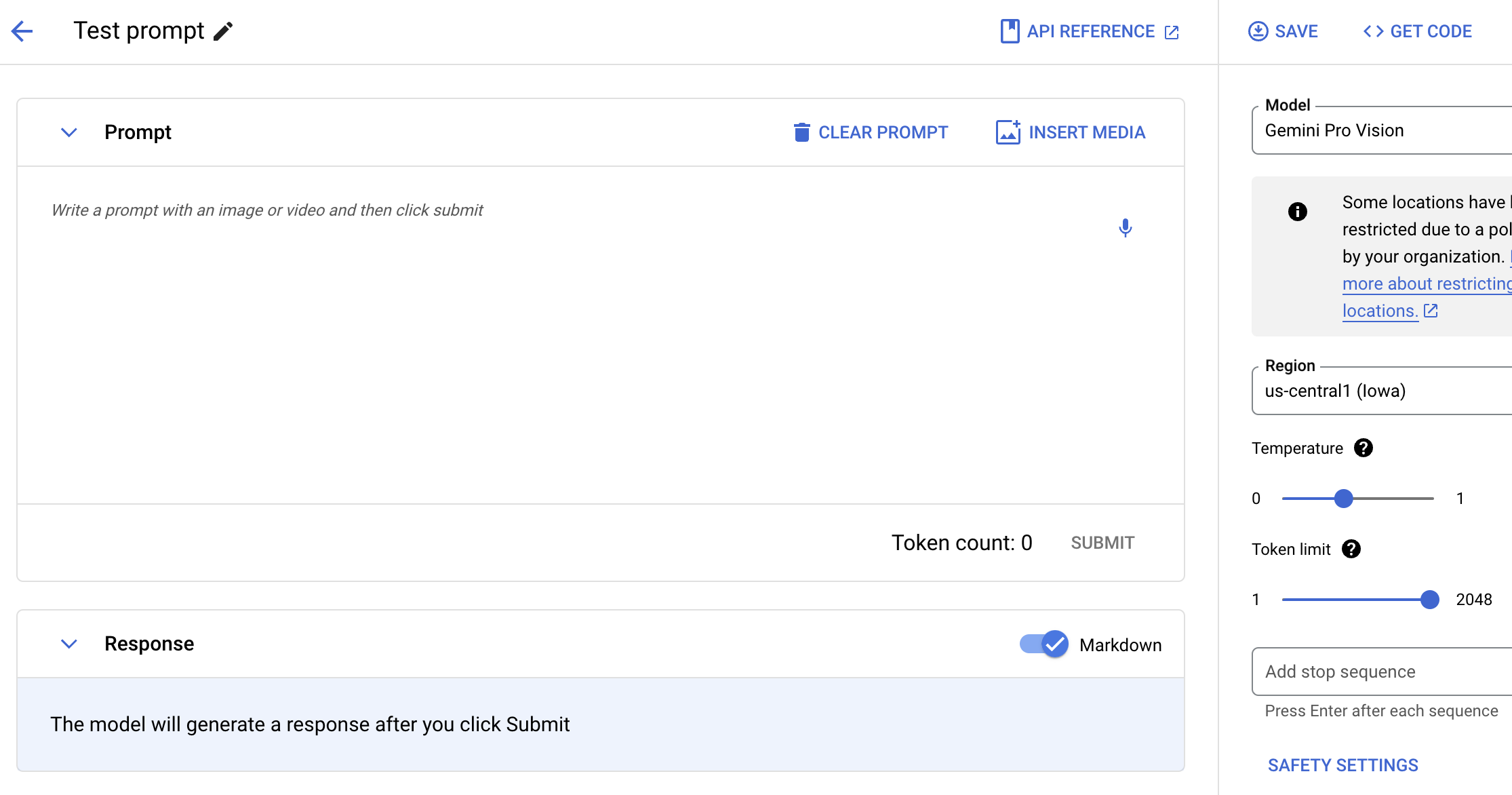
Escribe instrucciones en Gemini con texto, imágenes y video
Prueba el modelo de Gemini con lenguaje natural, código o imágenes. Prueba instrucciones de muestra para extraer texto de imágenes, convertir texto de imágenes en formato JSON y hasta generar respuestas sobre las imágenes subidas para crear aplicaciones de IA de nueva generación.
Instructivos
Escribe instrucciones en Gemini con texto, imágenes y video
Prueba el modelo de Gemini con lenguaje natural, código o imágenes. Prueba instrucciones de muestra para extraer texto de imágenes, convertir texto de imágenes en formato JSON y hasta generar respuestas sobre las imágenes subidas para crear aplicaciones de IA de nueva generación.
Usa modelos multimodales
Comienza a usar Gemini, el modelo multimodal de Google
Obtén una descripción general del uso del modelo multimodal en Google Cloud, las fortalezas y limitaciones de Gemini, la información de instrucciones y solicitudes, y los recuentos de tokens.

Instructivos
Comienza a usar Gemini, el modelo multimodal de Google
Obtén una descripción general del uso del modelo multimodal en Google Cloud, las fortalezas y limitaciones de Gemini, la información de instrucciones y solicitudes, y los recuentos de tokens.











