Multimodal AI
Generate text, code, video, audio, and images from virtually any content type
Multimodal models can process a wide variety of inputs, including text, images, and audio, as prompts and convert those prompts into various outputs, not just the source type.
New customers get up to $300 in free credits to try multimodal models in Gemini Enterprise Agent Platform and other Google Cloud products.

Overview
What is an example of multimodal AI?
A multimodal model is a ML (machine learning) model that is capable of processing information from different modalities, including images, videos, and text. For example, Google's multimodal model, Gemini, can receive a photo of a plate of cookies and generate a written recipe as a response and vice versa.
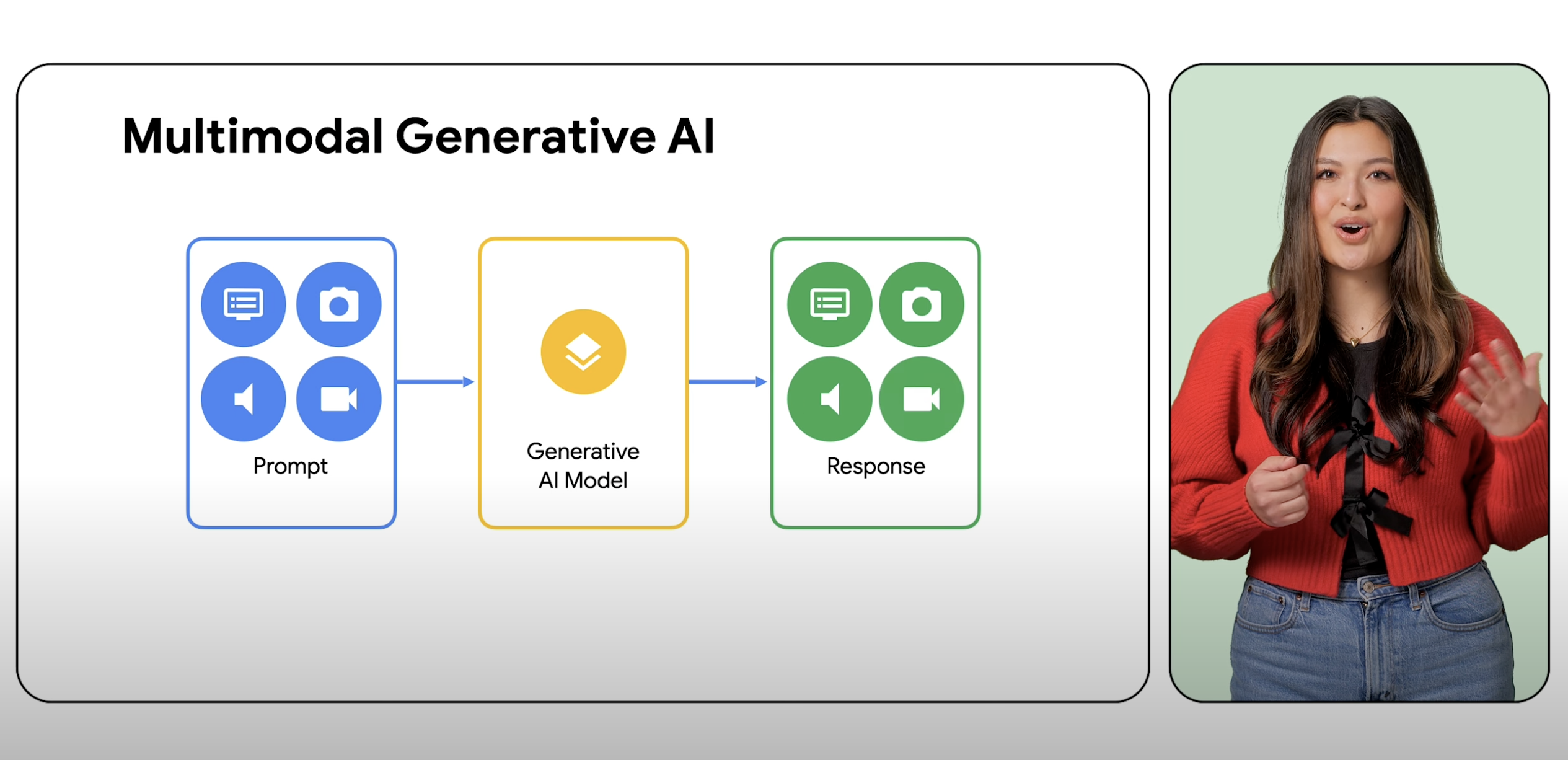
What is the difference between generative AI and multimodal AI?
Generative AI is an umbrella term for the use of ML models to create new content, like text, images, music, audio, and videos typically from a prompt of a single type. Multimodal AI expands on these generative capabilities, processing information from multiple modalities, including images, videos, and text. Multimodality can be thought of as giving AI the ability to process and understand different sensory modes. Practically this means users are not limited to one input and one output type and can prompt a model with virtually any input to generate virtually any content type.
What is an AI that can use images as a prompt?
Gemini is a multimodal model from the team at Google DeepMind that can be prompted with not only images, but also text, code, and video. Gemini was designed from the ground up to reason seamlessly across text, images, video, audio, and code. Gemini Enterprise Agent Platform can even use prompts to extract text from images, convert image text to JSON, and generate answers about uploaded images.
What is the future of multimodal AI and why is it important?
Multimodal AI and multimodal models represent a leap forward in how developers build and expand the functionality of AI in the next generation of applications. For example, Gemini can understand, explain and generate high-quality code in the world’s most popular programming languages, like Python, Java, C++, and Go—freeing developers to work on building more feature filled applications. Multimodal AI's potential also brings the world closer to AI that's less like smart software and more like an expert helper or assistant.
What are the benefits of multimodal models and multimodal AI?
The benefits of multimodal AI is that it offers developers and users an AI with more advanced reasoning, problem-solving, and generation capabilities. These advancements offer endless possibilities for how next generation applications can change the way we work and live. For developers looking to start building, Gemini Enterprise Agent Platform API offers features such as enterprise security, data residency, performance, and technical support. Existing Google Cloud customers can start prompting with Gemini in Agent Platform right now.
How It Works
A multimodal model is capable of understanding and processing virtually any input, combining different types of information, and generating almost any output. For instance, using Agent Platform, users can prompt with text, images, video, or code to generate different types of content than originally inputted.
A multimodal model is capable of understanding and processing virtually any input, combining different types of information, and generating almost any output. For instance, using Agent Platform, users can prompt with text, images, video, or code to generate different types of content than originally inputted.

Try multimodal prompts
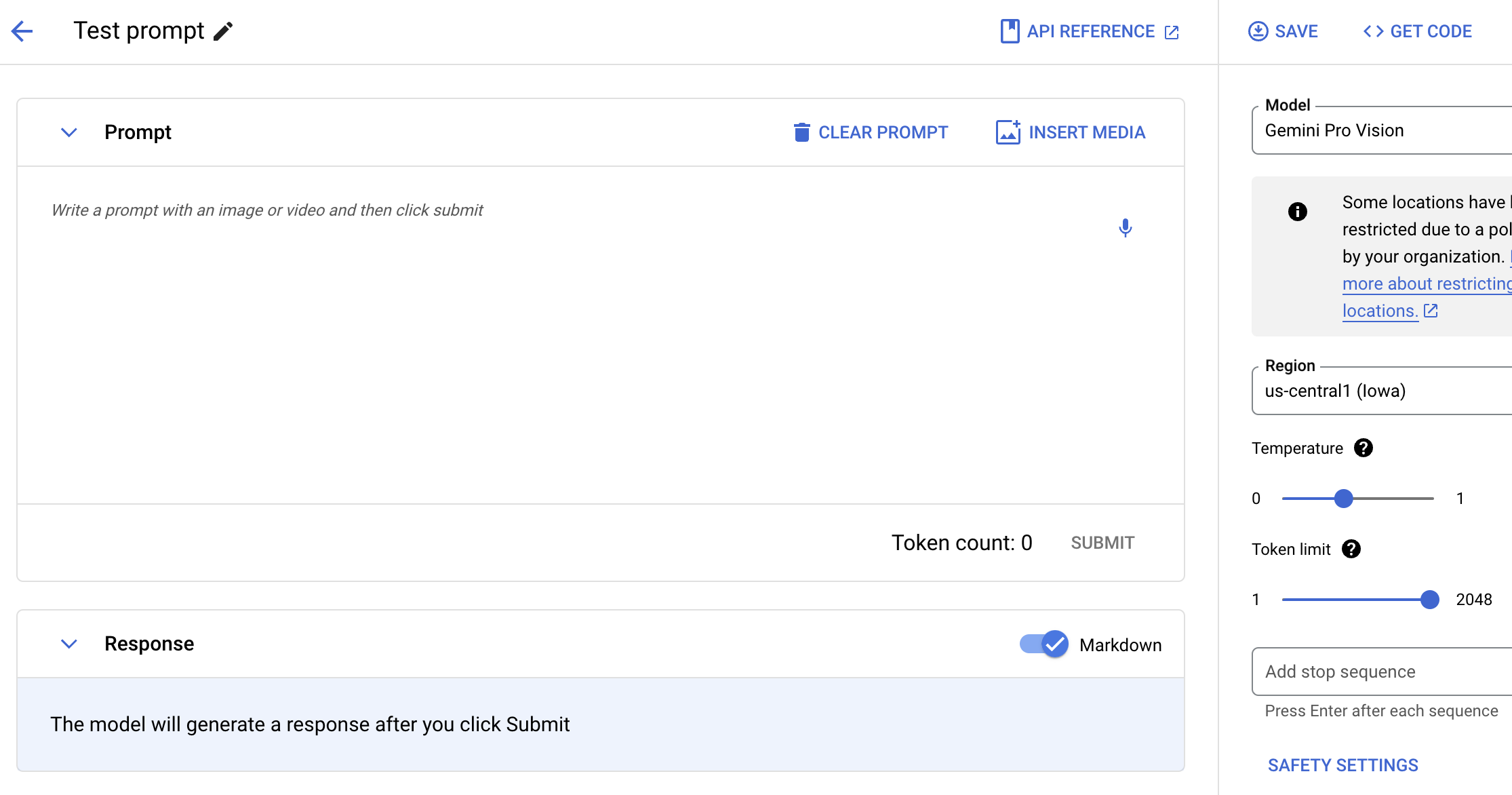
Prompt Gemini with text, images, and video
Test the Gemini model using natural language, code, or images. Try sample prompts for extracting text from images, converting image text to JSON, and even generate answers about uploaded images to build next-gen AI applications.
How-tos
Prompt Gemini with text, images, and video
Test the Gemini model using natural language, code, or images. Try sample prompts for extracting text from images, converting image text to JSON, and even generate answers about uploaded images to build next-gen AI applications.
Use multimodal models
Get started with Gemini, Google's multimodal model
Get an overview of multimodal model usage in Google Cloud, Gemini strengths and limitations, prompt and request info, and token counts.

How-tos
Get started with Gemini, Google's multimodal model
Get an overview of multimodal model usage in Google Cloud, Gemini strengths and limitations, prompt and request info, and token counts.


















