Multimodale KI
Text, Code, Video, Audio und Bilder aus praktisch jedem Inhaltstyp generieren
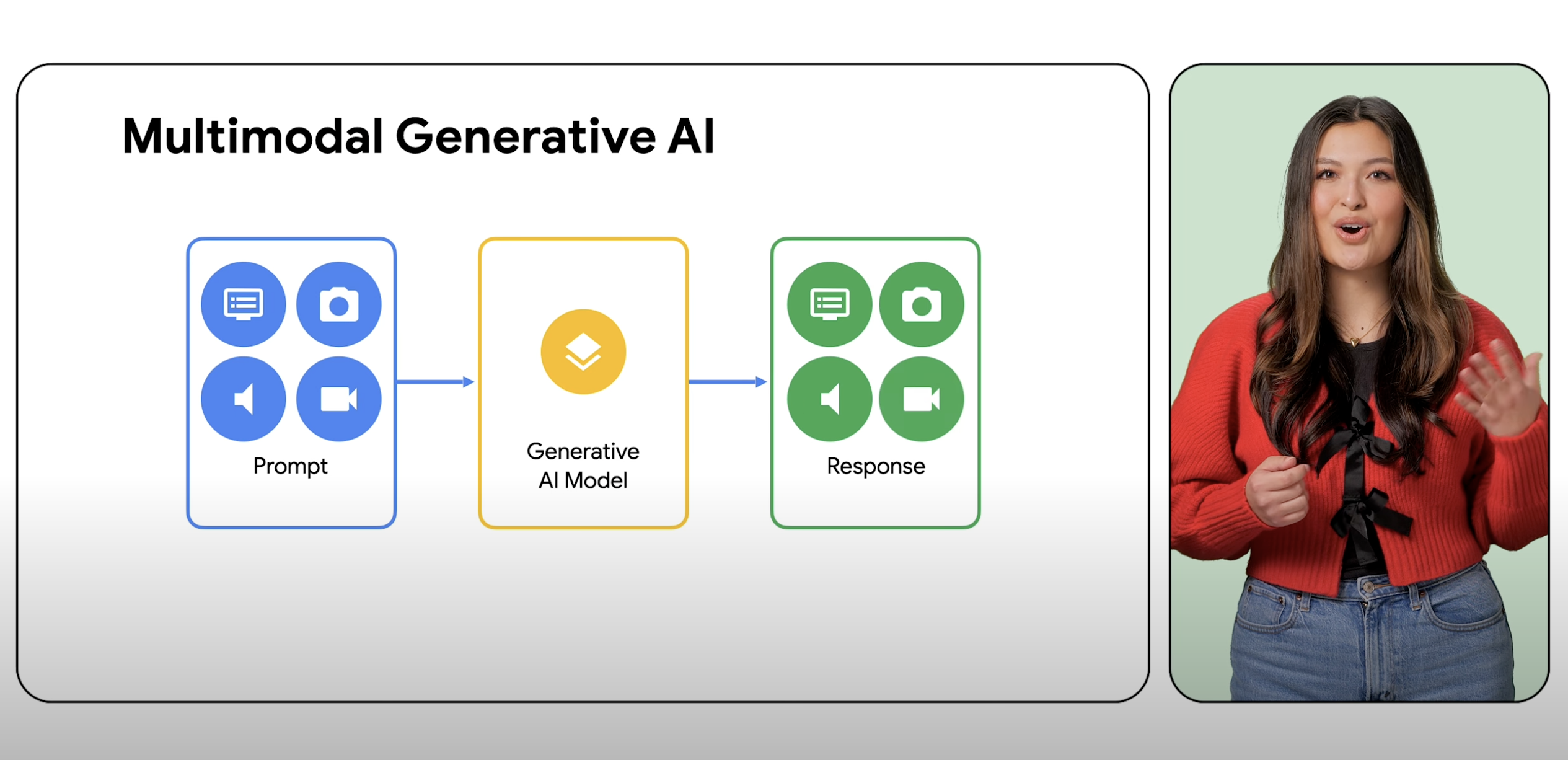
Multimodale Modelle können eine Vielzahl von Eingaben, einschließlich Text, Bilder und Audio, als Prompts verarbeiten und diese Prompts in verschiedene Ausgaben konvertieren, nicht nur in den Quelltyp.
Neukunden erhalten ein Guthaben von bis zu 300 $, um multimodale Modelle in der Gemini Enterprise Agent Platform und andere Google Cloud-Produkte auszuprobieren.

Überblick
Was ist ein Beispiel für multimodale KI?
Ein multimodales Modell ist ein ML-Modell (maschinelles Lernen), das Informationen aus verschiedenen Modalitäten verarbeiten kann, darunter Bilder, Videos und Text. So kann beispielsweise das multimodale Modell von Google, Gemini, ein Foto von einem Teller mit Keksen empfangen und als Antwort ein Rezept generieren, und umgekehrt.
Was ist der Unterschied zwischen generativer KI und multimodaler KI?
Generative KI ist ein Überbegriff für den Einsatz von ML-Modellen zum Erstellen neuer Inhalte wie Text, Bilder, Musik, Audio und Videos, die in der Regel mit einem Prompt eines einzigen Typs erstellt werden. Multimodale KI erweitert diese generativen Funktionen und verarbeitet Informationen aus mehreren Modalitäten, darunter Bilder, Videos und Text. Mit Multimodalität kann KI verschiedene Sinnesmodi verarbeiten und verstehen. In der Praxis bedeutet dies, dass Nutzer nicht auf einen Eingabe- und einen Ausgabetyp beschränkt sind und ein Modell mit praktisch jeder Eingabe auffordern können, praktisch jeden Inhaltstyp zu generieren.
Was ist eine KI, die Bilder als Prompt verwenden kann?
Gemini ist ein multimodales Modell des Teams bei Google DeepMind, dem nicht nur Bilder, sondern auch Text, Code und Videos angezeigt werden können. Gemini wurde von Grund auf für die nahtlose Nutzung von Text, Bildern, Video, Audio und Code entwickelt. Gemini Enterprise Agent Platform kann sogar Prompts verwenden, um Text aus Bildern zu extrahieren, Bildtext in JSON zu konvertieren und Antworten zu hochgeladenen Bildern zu generieren.
Wie sieht die Zukunft der multimodalen KI aus und warum ist sie wichtig?
Multimodale KI und multimodale Modelle stellen einen Fortschritt bei der Entwicklung und Erweiterung von KI-Funktionen in der nächsten Generation von Anwendungen dar. Gemini beispielsweise kann in den beliebtesten Programmiersprachen der Welt hochwertigen Code wie Python, Java, C++ und Go verstehen, erklären und generieren. So können Entwickler mehr Anwendungen mit mehr Funktionen erstellen. Das Potenzial multimodaler KI bringt die Welt auch näher an KI heran, die weniger wie intelligente Software, sondern eher wie fachkundige Hilfskräfte oder Assistenten aussieht.
Welche Vorteile bieten multimodale Modelle und multimodale KI?
Die Vorteile der multimodalen KI besteht darin, dass sie Entwicklern und Nutzern eine KI mit erweiterten Funktionen für Logik, Problemlösung und Generierung bietet. Diese Fortschritte bieten endlose Möglichkeiten, wie Anwendungen der nächsten Generation unsere Arbeitsweise und Lebensweise verändern können. Für Entwickler, die mit der Entwicklung beginnen möchten, bietet die Gemini Enterprise Agent Platform API Features wie Unternehmenssicherheit, Datenstandort, Leistung und technischen Support. Bestehende Google Cloud-Kunden können jetzt Prompts mit Gemini in der Agent Platform starten.
Funktionsweise
Ein multimodales Modell ist in der Lage, praktisch jede Eingabe zu verstehen und zu verarbeiten, verschiedene Arten von Informationen zu kombinieren und fast jede Ausgabe zu generieren. Mithilfe der Agent Platform können Nutzer beispielsweise Text, Bilder, Videos oder Code eingeben, um andere Arten von Inhalten zu generieren, als ursprünglich eingegeben wurden.
Ein multimodales Modell ist in der Lage, praktisch jede Eingabe zu verstehen und zu verarbeiten, verschiedene Arten von Informationen zu kombinieren und fast jede Ausgabe zu generieren. Mithilfe der Agent Platform können Nutzer beispielsweise Text, Bilder, Videos oder Code eingeben, um andere Arten von Inhalten zu generieren, als ursprünglich eingegeben wurden.

Multimodale Prompts ausprobieren
Gemini mit Text, Bildern und Video auffordern
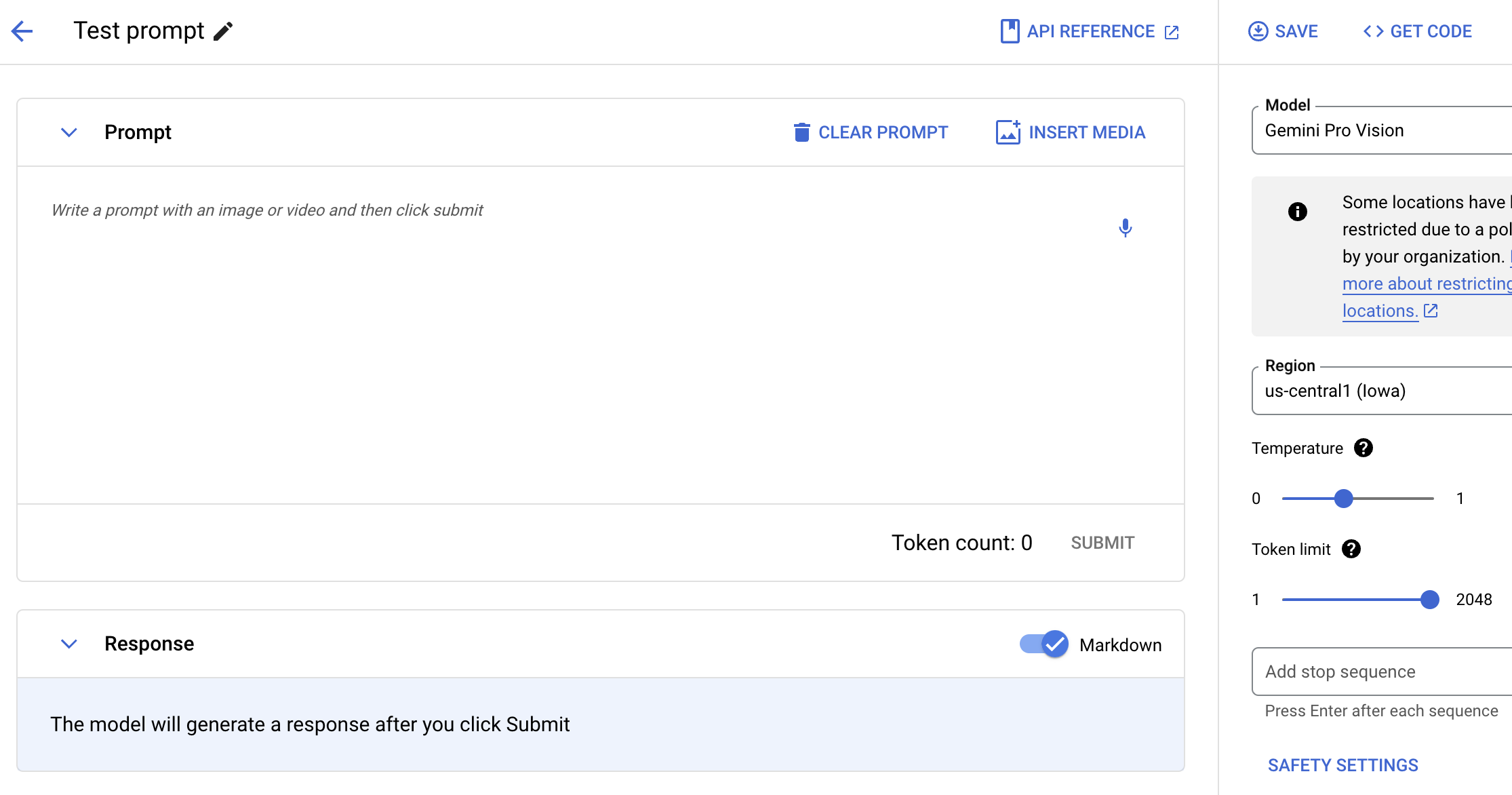
Testen Sie das Gemini-Modell mit natürlicher Sprache, Code oder Bildern. Probieren Sie Beispiel-Prompts aus, um Text aus Bildern zu extrahieren, Bildtext in JSON zu konvertieren und sogar Antworten zu hochgeladenen Bildern zu generieren, um KI-Anwendungen der nächsten Generation zu entwickeln.
Anleitungen
Gemini mit Text, Bildern und Video auffordern
Testen Sie das Gemini-Modell mit natürlicher Sprache, Code oder Bildern. Probieren Sie Beispiel-Prompts aus, um Text aus Bildern zu extrahieren, Bildtext in JSON zu konvertieren und sogar Antworten zu hochgeladenen Bildern zu generieren, um KI-Anwendungen der nächsten Generation zu entwickeln.
Multimodale Modelle verwenden
Erste Schritte mit Gemini, dem multimodalen Modell von Google
Verschaffen Sie sich einen Überblick über die Nutzung multimodaler Modelle in Google Cloud, über die Stärken und Einschränkungen von Gemini, über Prompt- und Anfrageinformationen sowie über die Anzahl der Tokens.

Anleitungen
Erste Schritte mit Gemini, dem multimodalen Modell von Google
Verschaffen Sie sich einen Überblick über die Nutzung multimodaler Modelle in Google Cloud, über die Stärken und Einschränkungen von Gemini, über Prompt- und Anfrageinformationen sowie über die Anzahl der Tokens.


















