Este documento descreve como configurar o OpenTelemetry Collector para extrair métricas padrão do Prometheus e comunicar essas métricas ao Google Cloud Managed Service for Prometheus. O OpenTelemetry Collector é um agente que pode implementar e configurar para exportar para o Managed Service for Prometheus. A configuração é semelhante à execução do Managed Service for Prometheus com a recolha implementada automaticamente.
Pode escolher o OpenTelemetry Collector em vez da recolha implementada automaticamente pelos seguintes motivos:
- O OpenTelemetry Collector permite-lhe encaminhar os seus dados de telemetria para vários backends configurando diferentes exportadores no seu pipeline.
- O coletor também suporta sinais de métricas, registos e rastreios, pelo que, ao usá-lo, pode processar todos os três tipos de sinais num único agente.
- O formato de dados independente do fornecedor do OpenTelemetry (o protocolo OpenTelemetry ou OTLP) suporta um ecossistema robusto de bibliotecas e componentes do coletor conectáveis. Isto permite uma variedade de opções de personalização para receber, processar e exportar os seus dados.
A contrapartida destas vantagens é que a execução de um OpenTelemetry Collector requer uma abordagem de implementação e manutenção autogerida. A abordagem que escolher vai depender das suas necessidades específicas, mas neste documento oferecemos diretrizes recomendadas para configurar o OpenTelemetry Collector através do Managed Service for Prometheus como back-end.
Antes de começar
Esta secção descreve a configuração necessária para as tarefas descritas neste documento.
Configure projetos e ferramentas
Para usar o serviço gerido do Google Cloud para Prometheus, precisa dos seguintes recursos:
Um Google Cloud projeto com a API Cloud Monitoring ativada.
Se não tiver um Google Cloud projeto, faça o seguinte:
Na Google Cloud consola, aceda a Novo projeto:
No campo Nome do projeto, introduza um nome para o projeto e, de seguida, clique em Criar.
Aceda a Faturação:
Selecione o projeto que acabou de criar, se ainda não estiver selecionado na parte superior da página.
É-lhe pedido que escolha um perfil de pagamentos existente ou que crie um novo.
A API Monitoring está ativada por predefinição para novos projetos.
Se já tiver um Google Cloud projeto, certifique-se de que a API Monitoring está ativada:
Aceda a APIs e serviços:
Selecione o seu projeto.
Clique em Ativar APIs e serviços.
Pesquise "Monitorização".
Nos resultados da pesquisa, clique em "API Cloud Monitoring".
Se não for apresentado "API ativada", clique no botão Ativar.
Um cluster do Kubernetes. Se não tiver um cluster do Kubernetes, siga as instruções no guia de início rápido do GKE.
Também precisa das seguintes ferramentas de linha de comandos:
gcloudkubectl
As ferramentas gcloud e kubectl fazem parte da
CLI gcloud do Google Cloud. Para obter informações sobre a instalação
destes componentes, consulte o artigo Faça a gestão dos componentes da CLI gcloud. Para ver os componentes da CLI gcloud que instalou, execute o seguinte comando:
gcloud components list
Configure o seu ambiente
Para evitar introduzir repetidamente o ID do projeto ou o nome do cluster, faça a seguinte configuração:
Configure as ferramentas de linha de comandos da seguinte forma:
Configure a CLI gcloud para fazer referência ao ID do seu Google Cloud projeto:
gcloud config set project PROJECT_ID
Configure a CLI
kubectlpara usar o seu cluster:kubectl config set-cluster CLUSTER_NAME
Para mais informações sobre estas ferramentas, consulte o seguinte:
Configure um espaço de nomes
Crie o espaço de nomes do Kubernetes NAMESPACE_NAME para os recursos que criar
como parte da aplicação de exemplo:
kubectl create ns NAMESPACE_NAME
Valide as credenciais da conta de serviço
Se o seu cluster do Kubernetes tiver a federação de identidade da carga de trabalho para o GKE ativada, pode ignorar esta secção.
Quando executado no GKE, o Managed Service for Prometheus
obtém automaticamente as credenciais do ambiente com base na
conta de serviço predefinida do Compute Engine. A conta de serviço predefinida tem as autorizações necessárias, monitoring.metricWriter e monitoring.viewer, por predefinição. Se não usar a Workload Identity Federation para o GKE e tiver removido anteriormente uma dessas funções da conta de serviço do nó predefinida, tem de readicionar essas autorizações em falta antes de continuar.
Configure uma conta de serviço para a federação de identidades da carga de trabalho para o GKE
Se o seu cluster do Kubernetes não tiver a Workload Identity Federation para o GKE ativada, pode ignorar esta secção.
O Managed Service for Prometheus captura dados de métricas através da API Cloud Monitoring. Se o seu cluster estiver a usar a Workload Identity Federation para o GKE, tem de conceder autorização à sua conta de serviço do Kubernetes para a API Monitoring. Esta secção descreve o seguinte:
- Criar uma Google Cloud conta de serviço> dedicada,
gmp-test-sa. - Associar a conta de serviço à conta de serviço do Kubernetes predefinida num espaço de nomes de teste,
NAMESPACE_NAME. Google Cloud - Conceder a autorização necessária à Google Cloud conta de serviço.
Crie e associe a conta de serviço
Este passo aparece em vários locais na documentação do Managed Service for Prometheus. Se já realizou este passo como parte de uma tarefa anterior, não precisa de o repetir. Avance para a secção Autorize a conta de serviço.
A seguinte sequência de comandos cria a conta de serviço gmp-test-sa e associa-a à conta de serviço Kubernetes predefinida no espaço de nomes NAMESPACE_NAME:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Se estiver a usar um espaço de nomes ou uma conta de serviço do GKE diferente, ajuste os comandos adequadamente.
Autorize a conta de serviço
Os grupos de autorizações relacionadas são recolhidos em funções e concede as funções a um principal, neste exemplo, a Google Cloud conta de serviço. Para mais informações sobre as funções de monitorização, consulte o artigo Controlo de acesso.
O comando seguinte concede à Google Cloud conta de serviçogmp-test-sa as funções da API Monitoring de que precisa para
escrever
dados de métricas.
Se já tiver concedido à Google Cloud conta de serviço uma função específica como parte de uma tarefa anterior, não tem de o fazer novamente.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Depure a configuração da federação de identidades de cargas de trabalho para o GKE
Se estiver a ter problemas com o funcionamento da federação de identidade da carga de trabalho para o GKE, consulte a documentação para validar a configuração da federação de identidade da carga de trabalho para o GKE e o guia de resolução de problemas da federação de identidade da carga de trabalho para o GKE.
Uma vez que os erros ortográficos e as operações de copiar e colar parciais são as origens mais comuns de erros ao configurar a Workload Identity Federation para o GKE, recomendamos vivamente que use as variáveis editáveis e os ícones de copiar e colar clicáveis incorporados nos exemplos de código nestas instruções.
Workload Identity Federation para o GKE em ambientes de produção
O exemplo descrito neste documento associa a conta de serviço à conta de serviço predefinida do Kubernetes e concede à conta de serviço todas as autorizações necessárias para usar a API Monitoring. Google Cloud Google Cloud
Num ambiente de produção, pode querer usar uma abordagem mais detalhada, com uma conta de serviço para cada componente, cada uma com autorizações mínimas. Para mais informações sobre a configuração de contas de serviço para a gestão de identidades da carga de trabalho, consulte o artigo Usar a federação de identidades da carga de trabalho para o GKE.
Configure o OpenTelemetry Collector
Esta secção explica como configurar e usar o OpenTelemetry Collector para extrair métricas de uma aplicação de exemplo e enviar os dados para o Google Cloud Managed Service for Prometheus. Para informações de configuração detalhadas, consulte as secções seguintes:
- Extraia métricas do Prometheus
- Adicione processadores
- Configure o exportador
googlemanagedprometheus
O OpenTelemetry Collector é análogo ao ficheiro binário do agente do Managed Service for Prometheus. A comunidade OpenTelemetry publica regularmente versões que incluem código-fonte, ficheiros binários e imagens de contentores.
Pode implementar estes artefactos em VMs ou clusters do Kubernetes através das predefinições de práticas recomendadas ou usar o criador de coletores para criar o seu próprio coletor composto apenas pelos componentes de que precisa. Para criar um coletor para utilização com o Managed Service for Prometheus, precisa dos seguintes componentes:
- O exportador do Managed Service for Prometheus, que escreve as suas métricas no Managed Service for Prometheus.
- Um recetor para extrair as suas métricas. Este documento pressupõe que está a usar o recetor OpenTelemetry Prometheus, mas o exportador do Managed Service for Prometheus é compatível com qualquer recetor de métricas OpenTelemetry.
- Processadores para agrupar e marcar as suas métricas de modo a incluir identificadores de recursos importantes, consoante o seu ambiente.
Estes componentes são ativados através de um ficheiro de configuração que é transmitido ao coletor com a flag --config.
As secções seguintes abordam a configuração de cada um destes componentes com mais detalhe. Este documento descreve como executar o coletor no GKE e noutros locais.
Configure e implemente o coletor
Quer esteja a executar a sua recolha no Google Cloud ou noutro ambiente, pode continuar a configurar o OpenTelemetry Collector para exportar para o Managed Service for Prometheus. A maior diferença reside na forma como configura o coletor. Em ambientes nãoGoogle Cloud , pode ser necessária formatação adicional dos dados de métricas para que sejam compatíveis com o Managed Service for Prometheus. No entanto, no Google Cloud, o coletor pode detetar automaticamente grande parte desta formatação.
Execute o coletor OpenTelemetry no GKE
Pode copiar a seguinte configuração para um ficheiro denominado config.yaml para configurar o
OpenTelemetry Collector no GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
A configuração anterior usa o Prometheus receiver e o Managed Service for Prometheus exporter para extrair os pontos finais de métricas nos pods do Kubernetes e exportar essas métricas para o Managed Service for Prometheus. Os processadores do pipeline formatam e agrupam os dados.
Para mais detalhes sobre o que cada parte desta configuração faz, juntamente com as configurações para diferentes plataformas, consulte as seguintes secções detalhadas sobre métricas de extração e adição de processadores.
Quando usar uma configuração do Prometheus existente com o recetor do OpenTelemetry Collector, substitua todos os carateres de cifrão único, 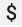 , por carateres duplos,
, por carateres duplos, 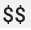 , para evitar acionar a substituição de variáveis de ambiente.
, para evitar acionar a substituição de variáveis de ambiente.prometheus Para mais informações, consulte o artigo
Extraia métricas do Prometheus.
Pode modificar esta configuração com base no seu ambiente, fornecedor e nas métricas que quer extrair, mas a configuração de exemplo é um ponto de partida recomendado para execução no GKE.
Execute o OpenTelemetry Collector fora do Google Cloud
A execução do OpenTelemetry Collector fora Google Cloud, como no local ou noutros fornecedores de nuvem, é semelhante à execução do Collector no GKE. No entanto, é menos provável que as métricas que extrai incluam automaticamente dados que os formatem da melhor forma para o Managed Service for Prometheus. Por conseguinte, tem de ter especial cuidado ao configurar o coletor para formatar as métricas de modo a serem compatíveis com o Managed Service for Prometheus.
Pode copiar a seguinte configuração para um ficheiro denominado config.yaml para configurar o coletor OpenTelemetry para implementação num cluster Kubernetes não pertencente ao GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
Esta configuração faz o seguinte:
- Configura uma configuração de extração de descoberta de serviços do Kubernetes para o Prometheus. Para mais informações, consulte o artigo sobre a obtenção de métricas do Prometheus.
- Define manualmente os atributos de recursos
cluster,namespaceelocation. Para mais informações sobre os atributos de recursos, incluindo a deteção de recursos para o Amazon EKS e o Azure AKS, consulte o artigo Detetar atributos de recursos. - Define a opção
projectno exportadorgooglemanagedprometheus. Para mais informações sobre o exportador, consulte o artigo Configure o exportadorgooglemanagedprometheus.
Quando usar uma configuração do Prometheus existente com o recetor do OpenTelemetry Collector, substitua todos os carateres de cifrão único, , por carateres duplos, , para evitar acionar a substituição de variáveis de ambiente.prometheus Para mais informações, consulte o artigo
Extraia métricas do Prometheus.
Para informações sobre as práticas recomendadas para configurar o coletor noutras nuvens, consulte os artigos Amazon EKS ou Azure AKS.
Implemente a aplicação de exemplo
A aplicação de exemplo emite a métrica de contador example_requests_total e a métrica de histograma example_random_numbers (entre outras) na porta metrics.
O manifesto deste exemplo define três réplicas.
Para implementar a aplicação de exemplo, execute o seguinte comando:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Crie a configuração do coletor como um ConfigMap
Depois de criar a configuração e colocá-la num ficheiro denominado config.yaml, use esse ficheiro para criar um ConfigMap do Kubernetes com base no seu ficheiro config.yaml.
Quando o coletor é implementado, monta o ConfigMap e carrega o ficheiro.
Para criar um ConfigMap denominado otel-config com a sua configuração, use o seguinte comando:
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
Implemente o coletor
Crie um ficheiro denominado collector-deployment.yaml com o seguinte conteúdo:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
Crie a implementação do coletor no cluster do Kubernetes executando o seguinte comando:
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
Depois de o pod ser iniciado, extrai a aplicação de exemplo e comunica as métricas ao serviço gerido para Prometheus.
Para obter informações sobre formas de consultar os seus dados, consulte Consultar através do Cloud Monitoring ou Consultar através do Grafana.
Forneça credenciais explicitamente
Quando executado no GKE, o OpenTelemetry Collector obtém automaticamente as credenciais do ambiente com base na conta de serviço do nó.
Em clusters Kubernetes não GKE, as credenciais têm de ser fornecidas explicitamente ao OpenTelemetry Collector através de flags ou da variável de ambiente GOOGLE_APPLICATION_CREDENTIALS.
Defina o contexto para o projeto de destino:
gcloud config set project PROJECT_ID
Crie uma conta de serviço:
gcloud iam service-accounts create gmp-test-sa
Este passo cria a conta de serviço que pode já ter criado nas instruções da federação de identidades da carga de trabalho para o GKE.
Conceda as autorizações necessárias à conta de serviço:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Crie e transfira uma chave para a conta de serviço:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Adicione o ficheiro de chave como um segredo ao seu cluster não GKE:
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Abra o recurso de implementação do OpenTelemetry para edição:
kubectl -n NAMESPACE_NAME edit deployment otel-collector
Adicione o texto apresentado em negrito ao recurso:
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...Guarde o ficheiro e feche o editor. Após a aplicação da alteração, os pods são recriados e começam a autenticar-se no back-end de métricas com a conta de serviço fornecida.
Extraia métricas do Prometheus
Esta secção e a secção seguinte fornecem informações de personalização adicionais para usar o OpenTelemetry Collector. Estas informações podem ser úteis em determinadas situações, mas nenhuma delas é necessária para executar o exemplo descrito em Configure o coletor do OpenTelemetry.
Se as suas aplicações já estiverem a expor pontos finais do Prometheus, o OpenTelemetry Collector pode extrair esses pontos finais usando o mesmo formato de configuração de extração que usaria com qualquer configuração padrão do Prometheus. Para o fazer, ative o recetor Prometheus na configuração do coletor.
Uma configuração do recetor do Prometheus para pods do Kubernetes pode ter o seguinte aspeto:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
Esta é uma configuração de extração baseada na deteção de serviços que pode modificar conforme necessário para extrair as suas aplicações.
Quando usar uma configuração do Prometheus existente com o recetor do OpenTelemetry Collector, substitua todos os carateres de cifrão único, , por carateres duplos, , para evitar acionar a substituição de variáveis de ambiente.prometheus Isto é especialmente importante para o
replacement
valor na secção relabel_configs. Por exemplo, se tiver a secção relabel_config seguinte:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
Em seguida, reescreva-o da seguinte forma:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
Para mais informações, consulte a documentação do OpenTelemetry.
Em seguida, recomendamos vivamente que use processadores para formatar as suas métricas. Em muitos casos, têm de ser usados processadores para formatar corretamente as suas métricas.
Adicione processadores
Os processadores do OpenTelemetry modificam os dados de telemetria antes de serem exportados. Pode usar os seguintes processadores para se certificar de que as suas métricas são escritas num formato compatível com o Managed Service for Prometheus.
Detete atributos de recursos
O exportador do Managed Service for Prometheus para o OpenTelemetry usa o recurso monitorizado para identificar de forma exclusiva os pontos de dados de séries cronológicas.prometheus_target O exportador analisa os campos de recursos monitorizados necessários a partir dos atributos de recursos nos pontos de dados de métricas.
Os campos e os atributos a partir dos quais os valores são extraídos são:
- project_id: detetado automaticamente pelas credenciais predefinidas da aplicação,
gcp.project.idouprojectna configuração do exportador (consulte configurar o exportador) - location:
location,cloud.availability_zone,cloud.region - cluster:
cluster,k8s.cluster_name - namespace:
namespace,k8s.namespace_name - job:
service.name+service.namespace - instance:
service.instance.id
Se não definir estas etiquetas para valores únicos, podem ocorrer erros de "duplicate timeseries" ao exportar para o Managed Service for Prometheus. Em muitos casos, os valores podem ser detetados automaticamente para estas etiquetas, mas, nalguns casos, pode ter de os mapear manualmente. O resto desta secção descreve estes cenários.
O recetor do Prometheus define automaticamente o atributo service.name com base no job_name na configuração de extração e o atributo service.instance.id com base no instance do destino de extração. O recetor também define k8s.namespace.name quando usa role: pod na configuração de extração.
Quando possível, preencha os outros atributos automaticamente através do processador de deteção de recursos. No entanto, consoante o seu ambiente, alguns atributos podem não ser detetáveis automaticamente. Neste caso, pode usar outros processadores para inserir manualmente estes valores ou analisá-los a partir de etiquetas de métricas. As secções seguintes ilustram as configurações para detetar recursos em várias plataformas.
GKE
Quando executa o OpenTelemetry no GKE, tem de ativar o processador de deteção de recursos para preencher as etiquetas de recursos. Certifique-se de que as suas métricas não contêm nenhuma das etiquetas de recursos reservadas. Se isto for inevitável, consulte o artigo Evite colisões de atributos de recursos mudando o nome dos atributos.
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
Esta secção pode ser copiada diretamente para o ficheiro de configuração, substituindo a secção processors, se já existir.
Amazon EKS
O detetor de recursos do EKS não preenche automaticamente os atributos cluster ou namespace. Pode fornecer estes valores manualmente através do processador de recursos, conforme mostrado no exemplo seguinte:
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Também pode converter estes valores de etiquetas de métricas usando o groupbyattrsprocessador (consulte a secção Mover etiquetas de métricas para etiquetas de recursos abaixo).
Azure AKS
O detetor de recursos do AKS não preenche automaticamente os atributos cluster ou namespace. Pode fornecer estes valores manualmente através do
recurso
processor,
como mostrado no exemplo seguinte:
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Também pode converter estes valores de etiquetas de métricas usando o groupbyattrsprocessador; consulte o artigo Mova as etiquetas de métricas para etiquetas de recursos.
Ambientes nas instalações e não na nuvem
Com ambientes no local ou não na nuvem, provavelmente, não consegue detetar automaticamente nenhum dos atributos de recursos necessários. Neste caso, pode emitir estas etiquetas nas suas métricas e movê-las para atributos de recursos (consulte o artigo Mova etiquetas de métricas para etiquetas de recursos) ou definir manualmente todos os atributos de recursos, conforme mostrado no exemplo seguinte:
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
O artigo Crie a configuração do coletor como um ConfigMap descreve como usar a configuração. Essa secção pressupõe que colocou a configuração num ficheiro denominado config.yaml.
O atributo do recurso project_id ainda pode ser definido automaticamente quando executar o coletor com as credenciais predefinidas da aplicação.
Se o seu coletor não tiver acesso às Credenciais padrão da aplicação, consulte o artigo
Definição de project_id.
Em alternativa, pode definir manualmente os atributos de recursos de que precisa numa variável de ambiente, OTEL_RESOURCE_ATTRIBUTES, com uma lista separada por vírgulas de pares chave-valor, por exemplo:
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
Em seguida, use o env resource detector
processor
para definir os atributos dos recursos:
processors:
resourcedetection:
detectors: [env]
Evite colisões de atributos de recursos ao mudar o nome dos atributos
Se as suas métricas já contiverem etiquetas que entrem em conflito com os atributos de recursos obrigatórios (como location, cluster ou namespace), mude-lhes o nome para evitar o conflito. A convenção do Prometheus é adicionar o prefixo exported_
ao nome da etiqueta. Para adicionar este prefixo, use o processador de
transformação.
A configuração processors muda o nome de potenciais colisões e resolve chaves em conflito da métrica:
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
Mova as etiquetas de métricas para etiquetas de recursos
Em alguns casos, as suas métricas podem estar a comunicar intencionalmente etiquetas como
namespace porque o seu exportador está a monitorizar vários espaços de nomes. Por exemplo, quando executa o exportador kube-state-metrics.
Neste cenário, estas etiquetas podem ser movidas para atributos de recursos através do processador groupbyattrs:
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
No exemplo anterior, dada uma métrica com as etiquetas namespace, cluster,
ou location, essas etiquetas são convertidas nos atributos de recursos correspondentes.
Limite os pedidos de API e a utilização de memória
Outros dois processadores, o processador de lotes e o processador de limite de memória, permitem-lhe limitar o consumo de recursos do seu coletor.
Processamento em lote
Os pedidos em lote permitem-lhe definir quantos pontos de dados enviar num único pedido. Tenha em atenção que o Cloud Monitoring tem um limite de 200 séries cronológicas por pedido. Ative o processador de lotes através das seguintes definições:
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
Limitação de memória
Recomendamos que ative o processador de limite de memória para evitar falhas do coletor em momentos de elevado débito. Ative o processamento através das seguintes definições:
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
Configure o exportador googlemanagedprometheus
Por predefinição, a utilização do exportador googlemanagedprometheus no GKE não requer configuração adicional. Em muitos exemplos de utilização, só precisa de o ativar com um bloco vazio na secção exporters:
exporters: googlemanagedprometheus:
No entanto, o exportador oferece algumas definições de configuração opcionais. As secções seguintes descrevem as outras definições de configuração.
A definir project_id
Para associar a série cronológica a um Google Cloud projeto, o recurso monitorizadoprometheus_target tem de ter o valor project_id definido.
Quando executa o OpenTelemetry no Google Cloud, o exportador do Managed Service for Prometheus define este valor por predefinição com base nas credenciais predefinidas da aplicação que encontra. Se não estiverem disponíveis credenciais ou quiser substituir o projeto predefinido, tem duas opções:
- Defina
projectna configuração do exportador - Adicione um atributo de recurso
gcp.project.idàs suas métricas.
Recomendamos vivamente que use o valor predefinido (não definido) para project_id em vez de o definir explicitamente, quando possível.
Defina project na configuração do exportador
O seguinte excerto de configuração envia métricas para o
Managed Service for Prometheus no projeto Google Cloud MY_PROJECT:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
A única alteração em relação aos exemplos anteriores é a nova linha project: MY_PROJECT.
Esta definição é útil se souber que todas as métricas provenientes deste coletor devem ser enviadas para MY_PROJECT.
Defina o atributo do recurso gcp.project.id
Pode definir a associação de projetos métrica a métrica adicionando um atributo de recurso gcp.project.id às suas métricas. Defina o valor do atributo como o nome do projeto ao qual a métrica deve ser associada.
Por exemplo, se a sua métrica já tiver uma etiqueta project, esta etiqueta pode ser movida para um atributo de recurso e mudada para gcp.project.id usando processadores na configuração do coletor, conforme mostrado no exemplo seguinte:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
Definir opções do cliente
O exportador googlemanagedprometheus usa clientes gRPC para o
Managed Service for Prometheus. Por conseguinte, as definições opcionais estão disponíveis para configurar o cliente gRPC:
compression: ativa a compressão gzip para pedidos gRPC, o que é útil para minimizar as taxas de transferência de dados quando envia dados de outras nuvens para o Managed Service for Prometheus (valores válidos:gzip).user_agent: Substitui a string do agente do utilizador enviada em pedidos para o Cloud Monitoring; aplica-se apenas a métricas. A predefinição é o número de compilação e versão do seu OpenTelemetry Collector, por exemplo,opentelemetry-collector-contrib 0.128.0.endpoint: define o ponto final para o qual os dados de métricas vão ser enviados.use_insecure: se for verdadeiro, usa o gRPC como transporte de comunicação. Tem um efeito apenas quando o valor deendpointnão é "".grpc_pool_size: define o tamanho do conjunto de ligações no cliente gRPC.prefix: configura o prefixo das métricas enviadas para o Managed Service for Prometheus. A predefinição éprometheus.googleapis.com. Não altere este prefixo. Se o fizer, as métricas não podem ser consultadas com o PromQL na IU do Cloud Monitoring.
Na maioria dos casos, não precisa de alterar os valores predefinidos. No entanto, pode alterá-las para ter em conta circunstâncias especiais.
Todas estas definições são definidas num bloco metric na secção do exportador googlemanagedprometheus, conforme mostrado no exemplo seguinte:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
O que se segue?
- Use o PromQL no Cloud Monitoring para consultar métricas do Prometheus.
- Use o Grafana para consultar as métricas do Prometheus.
- Configure o OpenTelemetry Collector como um agente sidecar no Cloud Run.
-
A página Gestão de métricas do Cloud Monitoring fornece informações que podem ajudar a controlar o valor gasto em métricas faturáveis sem afetar a observabilidade. A página Gestão de métricas apresenta as seguintes informações:
- Volumes de carregamento para a faturação baseada em bytes e em amostras, em todos os domínios de métricas e para métricas individuais.
- Dados sobre as etiquetas e a cardinalidade das métricas.
- Número de leituras para cada métrica.
- Utilização de métricas em políticas de alerta e painéis de controlo personalizados.
- Taxa de erros de escrita de métricas.
Também pode usar a página Gestão de métricas para excluir métricas desnecessárias, eliminando o custo da respetiva ingestão. Para mais informações sobre a página Gestão de métricas, consulte o artigo Veja e faça a gestão da utilização de métricas.