이 문서에서는 표준 Prometheus 측정항목을 스크래핑하고 이러한 측정항목을 Google Cloud Managed Service for Prometheus로 보고하도록 OpenTelemetry Collector를 설정하는 방법을 설명합니다. OpenTelemetry Collector는 Managed Service for Prometheus로 내보내도록 직접 배포 및 구성할 수 있는 에이전트입니다. 설정은 자체 배포된 컬렉션으로 Managed Service for Prometheus를 실행하는 것과 비슷합니다.
다음과 같은 이유로 자체 배포된 컬렉션에 대해 OpenTelemetry Collector를 선택할 수 있습니다.
- OpenTelemetry Collector를 사용하면 파이프라인에 서로 다른 내보내기 도구를 구성하여 원격 분석 데이터를 여러 백엔드로 라우팅할 수 있습니다.
- Collector는 또한 측정항목, 로그, trace 신호를 지원하므로, 이를 사용해서 하나의 에이전트에서 3개의 신호 유형을 모두 처리할 수 있습니다.
- 공급업체에 영향을 받지 않는 OpenTelemetry 데이터 형식(OpenTelemetry 프로토콜 또는 OTLP)은 라이브러리 및 플러그인할 수 있는 Collector 구성요소의 강력한 에코시스템을 지원합니다. 이를 통해 데이터 수신, 처리, 내보내기에 대해 다양한 맞춤설정 옵션이 허용됩니다.
이러한 이점의 단점은 OpenTelemetry Collector를 실행하기 위해 자체 관리형 배포 및 유지보수 접근 방법이 필요하다는 것입니다. 사용할 접근 방법은 특정 요구에 따라 달라지지만, 이 문서에서는 Managed Service for Prometheus를 백엔드로 사용하여 OpenTelemetry Collector를 구성하는 권장 지침을 제공합니다.
시작하기 전에
이 섹션에서는 이 문서에 설명된 태스크에 필요한 구성에 대해 설명합니다.
프로젝트 및 도구 설정
Google Cloud Managed Service for Prometheus를 사용하려면 다음 리소스가 필요합니다.
Cloud Monitoring API가 사용 설정된 Google Cloud 프로젝트.
Google Cloud 프로젝트가 없으면 다음을 수행합니다.
Google Cloud 콘솔에서 새 프로젝트로 이동합니다.
프로젝트 이름 필드에서 프로젝트 이름을 입력한 후 만들기를 클릭합니다.
결제로 이동:
페이지 상단에서 아직 선택하지 않았으면 바로 전에 만든 프로젝트를 선택합니다.
기존 결제 프로필을 선택하거나 새 결제 프로필을 만들라는 메시지가 표시됩니다.
Monitoring API는 새 프로젝트에 대해 기본적으로 사용 설정됩니다.
Google Cloud 프로젝트가 이미 있으면 Monitoring API가 사용 설정되었는지 확인합니다.
API 및 서비스로 이동합니다.
프로젝트를 선택합니다.
API 및 서비스 사용 설정을 클릭합니다.
'Monitoring'을 검색합니다.
검색 결과에서 'Cloud Monitoring API'를 클릭합니다.
'API 사용 설정'이 표시되지 않으면 사용 설정 버튼을 클릭합니다.
Kubernetes 클러스터가 필요합니다. Kubernetes 클러스터가 없으면 GKE 빠른 시작 안내를 따르세요.
또한 다음 명령줄 도구가 필요합니다.
gcloudkubectl
gcloud 및 kubectl 도구는 Google Cloud CLI의 일부입니다. 설치에 대한 자세한 내용은 Google Cloud CLI 구성요소 관리를 참조하세요. 설치한 gcloud CLI 구성요소를 보려면 다음 명령어를 실행하세요.
gcloud components list
환경 구성
프로젝트 ID 또는 클러스터 이름을 반복해서 입력하지 않으려면 다음 구성을 수행합니다.
다음과 같이 명령줄 도구를 구성합니다.
Google Cloud 프로젝트의 ID를 참조하도록 gcloud CLI를 구성합니다.
gcloud config set project PROJECT_ID
클러스터를 사용하도록
kubectlCLI를 구성합니다.kubectl config set-cluster CLUSTER_NAME
이러한 도구에 대한 자세한 내용은 다음을 참조하세요.
네임스페이스 설정
예시 애플리케이션의 일부로 만드는 리소스에 대해 NAMESPACE_NAME Kubernetes 네임스페이스를 만듭니다.
kubectl create ns NAMESPACE_NAME
서비스 계정 사용자 인증 정보 확인
Kubernetes 클러스터에 GKE용 워크로드 아이덴티티 제휴가 사용 설정되어 있으면 이 섹션을 건너뛸 수 있습니다.
GKE에서 실행될 때 Managed Service for Prometheus는 Compute Engine 기본 서비스 계정을 기반으로 환경에서 사용자 인증 정보를 자동으로 검색합니다. 기본적으로 기본 서비스 계정에는 필요한 권한 monitoring.metricWriter 및 monitoring.viewer가 있습니다. GKE용 워크로드 아이덴티티 제휴를 사용하지 않고 이전에 기본 노드 서비스 계정에서 이러한 역할 중 하나를 삭제한 경우 계속하기 전에 누락된 권한을 다시 추가해야 합니다.
GKE용 워크로드 아이덴티티 제휴 서비스 계정 구성
Kubernetes 클러스터에 GKE용 워크로드 아이덴티티 제휴가 사용 설정되어 있지 않으면 이 섹션을 건너뛸 수 있습니다.
Managed Service for Prometheus는 Cloud Monitoring API를 사용하여 측정항목 데이터를 캡처합니다. 클러스터에서 GKE용 워크로드 아이덴티티 제휴를 사용하는 경우 Kubernetes 서비스 계정에 Monitoring API에 대한 권한을 부여해야 합니다. 이 섹션에서는 다음을 설명합니다.
- 전용 Google Cloud 서비스 계정,
gmp-test-sa를 만듭니다. - 테스트 네임스페이스
NAMESPACE_NAME에서 Google Cloud 서비스 계정을 기본 Kubernetes 서비스 계정에 바인딩합니다. - Google Cloud 서비스 계정에 필요한 권한을 부여합니다.
서비스 계정 만들기 및 바인딩
이 단계는 Managed Service for Prometheus 문서의 여러 위치에 표시됩니다. 이미 이전 태스크를 수행하는 동안 이 단계를 수행했으면 이를 반복할 필요가 없습니다. 서비스 계정 승인으로 건너뛰세요.
다음 명령어 시퀀스는 gmp-test-sa 서비스 계정을 만들고 NAMESPACE_NAME 네임스페이스의 기본 Kubernetes 서비스 계정에 바인딩합니다.
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
다른 GKE 네임스페이스 또는 서비스 계정을 사용하는 경우 적절하게 명령어를 조정합니다.
서비스 계정 승인
관련 권한 그룹이 역할에 수집되고 주 구성원(이 예시에서는 Google Cloud서비스 계정)에 역할을 부여합니다. Monitoring 역할에 대한 자세한 내용은 액세스 제어를 참조하세요.
다음 명령어는 Google Cloud 서비스 계정 gmp-test-sa에 측정항목 데이터 쓰기에 필요한 Monitoring API 역할을 부여합니다.
이미 이전 태스크를 수행하는 동안 Google Cloud 서비스 계정에 특정 역할을 부여한 경우 이를 다시 수행할 필요가 없습니다.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
GKE용 워크로드 아이덴티티 제휴 구성 디버그
GKE용 워크로드 아이덴티티 제휴가 작동하지 않는 경우 GKE용 워크로드 아이덴티티 제휴 설정 확인 문서와 GKE용 워크로드 아이덴티티 제휴 문제 해결 가이드를 참조하세요.
GKE용 워크로드 아이덴티티 제휴를 구성할 때 오타 및 부분 복사-붙여넣기가 가장 일반적인 오류 소스이므로 이 안내의 코드 샘플에 삽입된 수정 가능한 변수 및 클릭 가능한 복사-붙여넣기 아이콘을 사용하는 것이 좋습니다.
프로덕션 환경의 GKE용 워크로드 아이덴티티 제휴
이 문서에 설명된 예시에서는 Google Cloud 서비스 계정을 기본 Kubernetes 서비스 계정에 바인딩하고 Google Cloud서비스 계정에 Monitoring API를 사용하기 위해 필요한 모든 권한을 부여합니다.
프로덕션 환경에서는 각 구성요소에 대해 서비스 계정이 있고, 각각 최소 권한이 포함된 세분화된 방법을 사용해야 할 수 있습니다. 워크로드 아이덴티티 관리를 위한 서비스 계정 구성에 대한 자세한 내용은 GKE용 워크로드 아이덴티티 제휴 사용을 참조하세요.
OpenTelemetry Collector 설정
이 섹션에서는 예시 애플리케이션에서 측정항목을 스크래핑하고 데이터를 Google Cloud Managed Service for Prometheus로 전송하도록 OpenTelemetry Collector를 설정하고 사용하는 과정을 안내합니다. 자세한 구성 정보는 다음 섹션을 참조하세요.
OpenTelemetry Collector는 Managed Service for Prometheus 에이전트 바이너리와 동일합니다. OpenTelemetry 커뮤니티는 소스 코드, 바이너리, 컨테이너 이미지가 포함된 버전을 정기적으로 게시합니다.
권장사항 기본값을 사용하여 VM 또는 Kubernetes 클러스터에 이러한 아티팩트를 배포하거나 Collector 빌더를 사용하여 필요한 구성요소로만 구성된 자체 Collector를 빌드할 수 있습니다. Managed Service for Prometheus에 사용할 Collector를 빌드하려면 다음 구성요소가 필요합니다.
- Managed Service for Prometheus에 측정항목을 기록하는 Managed Service for Prometheus 내보내기 도구
- 측정항목을 스크래핑하는 수신자. 이 문서에서는 OpenTelemetry Prometheus 수신자를 사용한다고 가정하지만 Managed Service for Prometheus 내보내기 도구는 모든 OpenTelemetry 측정항목 수신자와 호환됩니다.
- 환경에 따라 중요한 리소스 식별자를 포함하도록 측정항목을 일괄 처리하고 표시하는 프로세서
이러한 구성요소는 --config 플래그로 Collector에 전달되는 구성 파일을 사용하여 사용 설정됩니다.
다음 섹션에서는 이러한 각 구성요소를 구성하는 방법을 더 자세히 설명합니다. 이 문서에서는 GKE 및 기타 위치에서 Collector를 실행하는 방법을 설명합니다.
Collector 구성 및 배포
Google Cloud 또는 다른 환경에서 컬렉션을 실행하는지에 관계없이 Managed Service for Prometheus로 내보내도록 OpenTelemetry Collector를 구성할 수 있습니다. 가장 큰 차이점은 Collector를 구성하는 방법입니다.Google Cloud 이외의 환경에서는 Managed Service for Prometheus와 호환되기 위해 필요한 측정항목 데이터의 추가 형식이 있을 수 있습니다. 그러나 Google Cloud에서는 이러한 형식의 대부분을 Collector에서 자동으로 감지할 수 있습니다.
GKE에서 OpenTelemetry Collector 실행
다음 구성을 config.yaml이라는 파일에 복사하여 GKE에서 OpenTelemetry Collector를 설정할 수 있습니다.
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
위 구성은 Prometheus 수신자 및 Managed Service for Prometheus 내보내기 도구를 사용하여 Kubernetes 포드에서 측정항목 엔드포인트를 스크래핑하고 이러한 측정항목을 Managed Service for Prometheus로 내보냅니다. 파이프라인 프로세서는 데이터를 형식 지정하고 일괄 처리합니다.
서로 다른 플랫폼의 구성과 함께 이 구성의 각 부분이 수행하는 작업에 대한 자세한 내용은 아래에서 측정항목 스크래핑 및 프로세서 추가에 대한 세부 섹션을 참조하세요.
OpenTelemetry Collector의 prometheus 수신기에서 기존 Prometheus 구성을 사용하는 경우 환경 변수 대체가 발생하지 않도록 단일 달러 기호 문자 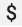 를 이중 문자
를 이중 문자 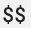 로 바꿉니다. 자세한 내용은 Prometheus 측정항목 스크래핑을 참조하세요.
로 바꿉니다. 자세한 내용은 Prometheus 측정항목 스크래핑을 참조하세요.
환경, 공급자, 스크래핑할 측정항목에 따라 이 구성을 수정할 수 있지만 예시 구성은 GKE에서 실행하기 위한 권장 시작 지점입니다.
Google Cloud외부에서 OpenTelemetry Collector 실행
온프레미스 또는 다른 클라우드 공급자와 같이 Google Cloud외부에서 OpenTelemetry Collector를 실행하는 것은 GKE에서 Collector를 실행하는 것과 비슷합니다. 그러나 스크래핑하는 측정항목은 Managed Service for Prometheus에 대해 형식 지정이 가장 뛰어난 데이터가 자동으로 포함될 가능성이 낮습니다. 따라서 Managed Service for Prometheus와 호환되도록 측정항목을 형식 지정하기 위해 추가적으로 Collector를 구성해야 합니다.
다음 구성을 config.yaml이라는 파일에 복사하여 GKE 이외의 Kubernetes 클러스터에서 배포를 위해 OpenTelemetry Collector를 설정할 수 있습니다.
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
이 구성은 다음을 수행합니다.
- Prometheus에 대해 Kubernetes 서비스 검색 스크래핑 구성을 설정합니다. 자세한 내용은 Prometheus 측정항목 스크래핑을 참조하세요.
cluster,namespace,location리소스 속성을 수동으로 설정합니다. Amazon EKS 및 Azure AKS에 대한 리소스 감지를 포함하여 리소스 속성에 대한 자세한 내용은 리소스 속성 감지를 참조하세요.googlemanagedprometheus내보내기 도구에서project옵션을 설정합니다. 내보내기 도구에 대한 자세한 내용은googlemanagedprometheus내보내기 도구 구성을 참조하세요.
OpenTelemetry Collector의 prometheus 수신기에서 기존 Prometheus 구성을 사용하는 경우 환경 변수 대체가 발생하지 않도록 단일 달러 기호 문자 를 이중 문자 로 바꿉니다. 자세한 내용은 Prometheus 측정항목 스크래핑을 참조하세요.
다른 클라우드에서 Collector 구성에 대한 권장사항은 Amazon EKS 또는 Azure AKS를 참조하세요.
예시 애플리케이션 배포
예시 애플리케이션은 metrics 포트에서 example_requests_total 카운터 측정항목 및 example_random_numbers 히스토그램 측정항목을 내보냅니다.
이 예시의 매니페스트는 3개 복제본을 정의합니다.
예시 애플리케이션을 배포하려면 다음 명령어를 실행합니다.
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Collector 구성을 ConfigMap으로 만들기
구성을 만들고 이를 config.yaml이라는 파일에 배치한 후에는 이 파일을 사용하여 config.yaml 파일을 기반으로 Kubernetes ConfigMap을 만듭니다.
Collector가 배포되었으면 ConfigMap을 마운트하고 파일을 로드합니다.
해당 구성으로 otel-config라는 ConfigMap을 만들려면 다음 명령어를 사용합니다.
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
Collector 배포
다음 콘텐츠로 collector-deployment.yaml이라는 파일을 만듭니다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
다음 명령어를 실행하여 Kubernetes 클러스터에 Collector 배포를 만듭니다.
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
포드가 시작된 다음 샘플 애플리케이션을 스크래핑하고 측정항목을 Managed Service for Prometheus에 보고합니다.
데이터 쿼리 방법에 대한 자세한 내용은 Cloud Monitoring을 사용하여 쿼리 또는 Grafana를 사용하여 쿼리를 참조하세요.
명시적으로 사용자 인증 정보 제공
GKE에서 실행할 때 OpenTelemetry Collector는 노드의 서비스 계정을 기반으로 환경에서 사용자 인증 정보를 자동으로 검색합니다.
GKE 이외의 Kubernetes 클러스터에서는 플래그 또는 GOOGLE_APPLICATION_CREDENTIALS 환경 변수를 사용하여 OpenTelemetry Collector에 사용자 인증 정보를 명시적으로 제공해야 합니다.
컨텍스트를 대상 프로젝트로 설정합니다.
gcloud config set project PROJECT_ID
서비스 계정을 만듭니다.
gcloud iam service-accounts create gmp-test-sa
이 단계에서는 GKE용 워크로드 아이덴티티 제휴 안내에 따라 이미 생성되었을 수 있는 서비스 계정을 만듭니다.
서비스 계정에 필요한 권한을 부여합니다.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
서비스 계정에 대해 키를 만들고 다운로드합니다.
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
키 파일을 GKE 클러스터 외의 클러스터에 보안 비밀로 추가합니다.
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
수정할 OpenTelemetry 배포 리소스를 엽니다.
kubectl -n NAMESPACE_NAME edit deployment otel-collector
굵게 표시된 텍스트를 리소스에 추가합니다.
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...파일을 저장하고 편집기를 닫습니다. 변경사항이 적용되고 포드가 다시 생성된 후 제공된 서비스 계정을 사용하여 측정항목 백엔드에 대해 인증을 시작합니다.
Prometheus 측정항목 스크래핑
이 섹션 및 이후 섹션에서는 OpenTelemetry Collector 사용에 대한 추가 맞춤설정 정보를 제공합니다. 이 정보는 특정 상황에서 유용할 수 있지만 OpenTelemetry Collector 설정에 설명된 예시를 실행하는 데 필수가 아닙니다.
애플리케이션이 이미 Prometheus 엔드포인트를 노출하는 경우 OpenTelemetry Collector는 표준 Prometheus 구성에 사용되는 동일한 스크래핑 구성 형식을 사용하여 이러한 엔드포인트를 스크래핑할 수 있습니다. 이렇게 하려면 Collector 구성에서 Prometheus 수신자를 사용 설정합니다.
Kubernetes 포드에 대한 Prometheus 수신자 구성은 다음과 같을 수 있습니다.
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
이것은 애플리케이션을 스크래핑하기 위해 필요에 따라 수정할 수 있는 서비스 검색 기반 스크래핑 구성입니다.
OpenTelemetry Collector의 prometheus 수신기에서 기존 Prometheus 구성을 사용하는 경우 환경 변수 대체가 발생하지 않도록 단일 달러 기호 문자 를 이중 문자 로 바꿉니다. 이 작업은 특히 relabel_configs 섹션 내에서 replacement 값에 대해 수행하는 것이 중요합니다. 예를 들어 다음 relabel_config 섹션이 있다고 가정해보세요.
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
그런 후 이를 다음과 같이 다시 작성합니다.
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
자세한 내용은 OpenTelemetry 문서를 참조하세요.
그런 다음 프로세서를 사용하여 측정항목을 형식 지정하는 것이 좋습니다. 많은 경우에 측정항목을 올바르게 형식 지정하기 위해 프로세서를 사용해야 합니다.
프로세서 추가
OpenTelemetry 프로세서는 내보내기 전에 원격 분석 데이터를 수정합니다. 다음 프로세서를 사용하여 측정항목이 Managed Service for Prometheus와 호환되는 형식으로 기록되는지 확인할 수 있습니다.
리소스 속성 감지
OpenTelemetry에 대한 Managed Service for Prometheus 내보내기 도구는 prometheus_target 모니터링 리소스를 사용하여 시계열 데이터 포인트를 고유하게 식별합니다. 내보내기 도구는 측정항목 데이터 포인트의 리소스 속성에서 필요한 모니터링 리소스 필드를 파싱합니다.
값이 스크래핑되는 필드 및 속성은 다음과 같습니다.
- project_id: 애플리케이션 기본 사용자 인증 정보,
gcp.project.id, 내보내기 도구 구성의project에서 자동 감지됩니다(내보내기 도구 구성 참조). - 위치:
location,cloud.availability_zone,cloud.region - 클러스터:
cluster,k8s.cluster_name - 네임스페이스:
namespace,k8s.namespace_name - 작업:
service.name+service.namespace - 인스턴스:
service.instance.id
이러한 라벨을 고유 값으로 설정하지 못하면 Managed Service for Prometheus로 내보낼 때 '중복 시계열' 오류가 발생할 수 있습니다. 대부분의 경우 이러한 라벨의 값을 자동으로 감지할 수 있지만 경우에 따라 직접 매핑해야 할 수도 있습니다. 이 섹션의 나머지 부분에서는 이러한 시나리오를 설명합니다.
Prometheus 수신자는 스크래핑 구성의 job_name 기반의 service.name 속성과 스크래핑 대상의 instance 기반의 service.instance.id 속성을 자동으로 설정합니다. 수신자는 또한 스크래핑 구성에서 role: pod를 사용할 때 k8s.namespace.name을 설정합니다.
가능하면 리소스 감지 프로세서를 사용하여 다른 속성을 자동으로 채웁니다. 그러나 환경에 따라 일부 속성은 자동으로 감지되지 않을 수 있습니다. 이 경우 다른 프로세서를 사용하여 이러한 값을 수동으로 삽입하거나 측정항목 라벨에서 파싱할 수 있습니다. 다음 섹션에서는 다양한 플랫폼에서 리소스를 감지하기 위한 구성을 보여줍니다.
GKE
GKE에서 OpenTelemetry를 실행할 때는 리소스 라벨을 채우려면 리소스 감지 프로세서를 사용으로 설정하면 됩니다. 측정항목에 이미 예약된 리소스 라벨이 포함되지 않는지 확인하세요. 이를 방지할 수 없으면 속성 이름 바꾸기로 리소스 속성 충돌 방지를 참조하세요.
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
이 섹션을 구성 파일에 직접 복사하여 processors 섹션(이미 있는 경우)을 대체할 수 있습니다.
Amazon EKS
EKS 리소스 감지기는 cluster 또는 namespace 속성을 자동으로 채우지 않습니다. 다음 예시에 표시된 것처럼 리소스 프로세서를 사용하여 수동으로 이러한 값을 제공할 수 있습니다.
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
또한 groupbyattrs 프로세서를 사용하여 측정항목 라벨에서 이러한 값을 변환할 수도 있습니다(아래의 리소스 라벨로 측정항목 라벨 이동 참조).
Azure AKS
AKS 리소스 감지기는 cluster 또는 namespace 속성을 자동으로 채우지 않습니다. 다음 예시에 표시된 것처럼 리소스 프로세서를 사용하여 수동으로 이러한 값을 제공할 수 있습니다.
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
groupbyattrs 프로세서를 사용하여 측정항목 라벨에서 이러한 값을 변환할 수도 있습니다(리소스 라벨로 측정항목 라벨 이동 참조).
온프레미스 및 비클라우드 환경
온프레미스 또는 비클라우드 환경에서는 필요한 리소스 속성을 자동으로 감지하지 못할 수 있습니다. 이 경우 측정항목에서 이러한 라벨을 내보내고 이를 리소스 속성으로 이동(리소스 라벨로 측정항목 라벨 이동 참조)하거나 다음 예시에 표시된 것처럼 모든 리소스 속성을 수동으로 설정할 수 있습니다.
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
Collector 구성을 ConfigMap으로 만들기에서는 구성을 사용하는 방법을 설명합니다. 이 섹션에서는 config.yaml이라는 파일에 구성을 배치했다고 가정합니다.
project_id 리소스 속성은 여전히 애플리케이션 기본 사용자 인증 정보로 Collector를 실행할 때 자동으로 설정할 수 있습니다.
Collector에 애플리케이션 기본 사용자 인증 정보 액세스 권한이 없으면 project_id 설정을 참조하세요.
또는 쉼표로 구분된 키-값 쌍 목록을 사용하여 환경 변수 OTEL_RESOURCE_ATTRIBUTES에 필요한 리소스 속성을 수동으로 설정할 수 있습니다. 예를 들면 다음과 같습니다.
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
그런 후 env 리소스 감지기 프로세서를 사용하여 리소스 속성을 설정합니다.
processors:
resourcedetection:
detectors: [env]
속성 이름을 바꿔서 리소스 속성 충돌 방지
측정항목에 이미 필요한 리소스 속성(예: location, cluster, namespace)과 충돌하는 라벨이 포함되어 있으면 충돌 방지를 위해 이름을 바꿉니다. Prometheus 규칙은 exported_ 프리픽스를 라벨 이름에 추가하는 것입니다. 이 프리픽스를 추가하려면 변환 프로세서
를 사용합니다.
다음 processors 구성은 잠재적 충돌의 이름을 바꾸고 측정항목에서 충돌하는 키를 해결합니다.
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
측정항목 라벨을 리소스 라벨로 이동
일부 경우에는 내보내기 도구가 여러 네임스페이스를 모니터링하기 때문에 측정항목이 의도적으로 namespace와 같은 라벨을 보고할 수 있습니다. 예를 들어 kube-state-metrics 내보내기 도구를 실행할 경우가 있습니다.
이 시나리오에서는 groupbyattrs 프로세서를 사용하여 이러한 라벨을 리소스 속성으로 이동할 수 있습니다.
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
앞의 예시에서 namespace, cluster, location 라벨이 포함된 측정항목에서 이러한 라벨은 일치하는 리소스 속성으로 변환됩니다.
API 요청 및 메모리 사용 제한
다른 두 프로세서인 일괄 처리 프로세서와 메모리 리미터 프로세서는 Collector의 리소스 소비를 제한할 수 있게 해줍니다.
일괄 처리
요청을 일괄 처리하면 단일 요청으로 전송할 데이터 포인트 수를 정의할 수 있습니다. Cloud Monitoring에서 요청당 시계열 수는 200개로 제한됩니다. 다음 설정을 사용하여 일괄 처리 프로세서를 사용 설정합니다.
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
메모리 제한
처리량이 높을 때 Collector가 충돌하지 않도록 방지하려면 메모리 리미터 프로세서를 사용 설정하는 것이 좋습니다. 다음 설정을 사용하여 처리를 사용 설정합니다.
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
googlemanagedprometheus 내보내기 도구 구성
기본적으로 GKE에서 googlemanagedprometheus 내보내기 도구를 사용하는 데에는 추가 구성이 필요하지 않습니다. 대부분의 경우 exporters 섹션에서 빈 블록으로 사용 설정하면 됩니다.
exporters: googlemanagedprometheus:
그러나 내보내기 도구는 몇 가지 선택적인 구성 설정을 제공합니다. 다음 섹션에서는 다른 구성 설정에 대해 설명합니다.
project_id 설정
시계열을 Google Cloud 프로젝트와 연결하려면 prometheus_target 모니터링 리소스에 설정된 project_id가 있어야 합니다.
Google Cloud에서 OpenTelemetry를 실행할 때 Managed Service for Prometheus 내보내기 도구는 발견된 애플리케이션 기본 사용자 인증 정보에 따라 기본적으로 이 값을 설정하게 되어 있습니다. 사용 가능한 인증 정보가 없거나 기본 프로젝트를 재정의하려면 두 가지 옵션이 있습니다.
- 내보내기 구성에서
project설정 - 측정항목에
gcp.project.id리소스 속성 추가
가능하면 명시적으로 설정하는 대신 project_id에 대해 기본(설정되지 않음) 값을 사용하는 것이 좋습니다.
내보내기 구성에서 project 설정
다음 구성 발췌문은 Google Cloud 프로젝트 MY_PROJECT에서 Managed Service for Prometheus에 측정항목을 전송합니다.
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
이전 예시에서 유일하게 변경된 부분은 새 행 project: MY_PROJECT입니다.
이 설정은 이 Collector를 통과하는 모든 측정항목이 MY_PROJECT로 전송된다는 것을 알고 있는 경우에 유용합니다.
gcp.project.id 리소스 속성 설정
측정항목에 gcp.project.id 리소스 속성을 추가하여 측정항목당 기준에 프로젝트 연결을 설정할 수 있습니다. 속성 값을 측정항목을 연결할 프로젝트 이름으로 설정합니다.
예를 들어 측정항목에 이미 project 라벨이 있으면 다음 예시에 표시된 것처럼 Collector 구성의 프로세서를 사용하여 이 라벨을 리소스 속성으로 이동하고 gcp.project.id로 이름을 바꿀 수 있습니다.
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
클라이언트 옵션 설정
googlemanagedprometheus 내보내기 도구는 Managed Service for Prometheus에 gRPC 클라이언트를 사용합니다. 따라서 선택적인 설정을 gRPC 클라이언트 구성에 사용할 수 있습니다.
compression: 다른 클라우드의 데이터를 Managed Service for Prometheus로 전송할 때 데이터 전송 수수료를 최소화하는 데 도움이 되도록 gRPC 요청에 대해 gzip 압축을 사용 설정합니다(유효한 값:gzip).user_agent: 요청에 따라 Cloud Monitoring에 전송되는 사용자 에이전트 문자열을 재정의합니다. 측정항목에만 적용됩니다. 기본적으로 OpenTelemetry Collector의 빌드 및 버전 번호로 지정됩니다. 예를 들면opentelemetry-collector-contrib 0.128.0입니다.endpoint: 측정항목 데이터를 전송할 엔드포인트를 설정합니다.use_insecure: true이면 gRPC를 통신 전송으로 사용합니다.endpoint값이 ""이 아닌 경우에만 효과가 있습니다.grpc_pool_size: gRPC 클라이언트에서 연결 풀의 크기를 설정합니다.prefix: Managed Service for Prometheus로 전송되는 측정항목의 프리픽스를 구성합니다. 기본값은prometheus.googleapis.com입니다. 이 프리픽스를 변경하지 마세요. 변경하면 Cloud Monitoring UI에서 PromQL로 측정항목을 쿼리하지 못할 수 있습니다.
대부분의 경우 해당 기본값에서 이러한 값을 변경할 필요가 없습니다. 그러나 특별한 상황에 맞게 변경할 수 있습니다.
이러한 모든 설정은 다음 예시에 표시된 것처럼 googlemanagedprometheus 내보내기 도구 섹션의 metric 블록에 설정됩니다.
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
다음 단계
- Cloud Monitoring에서 PromQL을 사용하여 Prometheus 측정항목 쿼리
- Grafana를 사용하여 Prometheus 측정항목 쿼리
- Cloud Run에서 OpenTelemetry Collector를 사이드카 에이전트로 설정
-
Cloud Monitoring 측정항목 관리 페이지에서는 모니터링 가능성에 영향을 주지 않고 청구 가능 측정항목에 지출하는 금액을 제어할 수 있는 정보를 제공합니다. 측정항목 관리 페이지에서는 다음 정보를 보고합니다.
- 측정항목 도메인 및 개별 측정항목의 바이트 기반 및 샘플 기반 청구에 대한 수집량
- 측정항목의 라벨 및 카디널리티에 대한 데이터
- 각 측정항목의 읽기 수
- 알림 정책 및 커스텀 대시보드의 측정항목 사용
- 측정항목 쓰기 오류의 비율
또한 측정항목 관리 페이지를 사용하면 불필요한 측정항목을 제외하여 수집 비용을 절감할 수 있습니다. 측정항목 관리 페이지에 대한 자세한 내용은 측정항목 사용량 보기 및 관리를 참조하세요.