Dokumen ini menjelaskan cara menyiapkan OpenTelemetry Collector untuk menyalin metrik Prometheus standar dan melaporkan metrik tersebut ke Google Cloud Managed Service for Prometheus. OpenTelemetry Collector adalah agen yang dapat Anda deploy sendiri dan dikonfigurasi untuk diekspor ke Managed Service for Prometheus. Penyiapannya mirip dengan menjalankan Managed Service for Prometheus dengan pengumpulan yang di-deploy sendiri.
Anda dapat memilih OpenTelemetry Collector daripada pengumpulan yang di-deploy sendiri karena alasan berikut:
- OpenTelemetry Collector memungkinkan Anda merutekan data telemetri ke beberapa backend dengan mengonfigurasi berbagai eksportir di pipeline.
- Pengumpul juga mendukung sinyal dari metrik, log, dan rekaman aktivitas, sehingga dengan menggunakannya, Anda dapat menangani ketiga jenis sinyal dalam satu agen.
- Format data independen vendor OpenTelemetry (OpenTelemetry Protocol, atau OTLP) mendukung ekosistem library dan komponen Collector yang dapat di-plug in yang kuat. Hal ini memungkinkan berbagai opsi penyesuaian untuk menerima, memproses, dan mengekspor data Anda.
Sebagai imbalan atas manfaat ini, menjalankan OpenTelemetry Collector memerlukan pendekatan deployment dan pemeliharaan yang dikelola sendiri. Pendekatan yang Anda pilih akan bergantung pada kebutuhan spesifik Anda, tetapi dalam dokumen ini kami menawarkan panduan yang direkomendasikan untuk mengonfigurasi OpenTelemetry Collector menggunakan Managed Service for Prometheus sebagai backend.
Sebelum memulai
Bagian ini menjelaskan konfigurasi yang diperlukan untuk tugas yang dijelaskan dalam dokumen ini.
Menyiapkan project dan alat
Untuk menggunakan Google Cloud Managed Service for Prometheus, Anda memerlukan resource berikut:
Project Google Cloud dengan Cloud Monitoring API diaktifkan.
Jika Anda tidak memiliki Google Cloud project, lakukan hal berikut:
Di Google Cloud console, buka New Project:
Di kolom Project Name, masukkan nama project Anda, lalu klik Create.
Buka Penagihan:
Pilih project yang baru saja Anda buat jika belum dipilih di bagian atas halaman.
Anda akan diminta untuk memilih profil pembayaran yang sudah ada atau membuat profil pembayaran baru.
Monitoring API diaktifkan secara default untuk project baru.
Jika Anda sudah memiliki Google Cloud project, pastikan Monitoring API diaktifkan:
Buka APIs & services:
Pilih project Anda.
Klik Aktifkan API dan Layanan.
Telusuri "Monitoring".
Di hasil penelusuran, klik "Cloud Monitoring API".
Jika "API enabled" tidak ditampilkan, klik tombol Enable.
Cluster Kubernetes. Jika Anda tidak memiliki cluster Kubernetes, ikuti petunjuk di Mulai Cepat untuk GKE.
Anda juga memerlukan alat command line berikut:
gcloudkubectl
Alat gcloud dan kubectl adalah bagian dari
Google Cloud CLI. Untuk mengetahui informasi tentang cara menginstalnya, lihat Mengelola komponen Google Cloud CLI. Untuk melihat komponen gcloud CLI yang telah Anda instal, jalankan perintah berikut:
gcloud components list
Mengonfigurasi lingkungan Anda
Agar tidak perlu memasukkan project ID atau nama cluster berulang kali, lakukan konfigurasi berikut:
Konfigurasi alat command line sebagai berikut:
Konfigurasi gcloud CLI untuk merujuk ke ID projectGoogle Cloud Anda:
gcloud config set project PROJECT_ID
Konfigurasi CLI
kubectluntuk menggunakan cluster Anda:kubectl config set-cluster CLUSTER_NAME
Untuk mengetahui informasi selengkapnya tentang alat ini, lihat artikel berikut:
Menyiapkan namespace
Buat namespace Kubernetes NAMESPACE_NAME untuk resource yang Anda buat
sebagai bagian dari aplikasi contoh:
kubectl create ns NAMESPACE_NAME
Memverifikasi kredensial akun layanan
Jika cluster Kubernetes Anda telah mengaktifkan Workload Identity Federation untuk GKE, Anda dapat melewati bagian ini.
Saat berjalan di GKE, Managed Service for Prometheus
akan otomatis mengambil kredensial dari lingkungan berdasarkan
akun layanan default Compute Engine. Akun layanan default memiliki izin yang diperlukan, monitoring.metricWriter dan monitoring.viewer, secara default. Jika Anda tidak menggunakan Workload Identity Federation untuk GKE, dan sebelumnya telah
menghapus salah satu peran tersebut dari akun layanan node default, Anda harus
menambahkan kembali izin yang hilang tersebut sebelum melanjutkan.
Mengonfigurasi akun layanan untuk Workload Identity Federation for GKE
Jika cluster Kubernetes Anda tidak mengaktifkan Workload Identity Federation untuk GKE, Anda dapat melewati bagian ini.
Managed Service for Prometheus merekam data metrik menggunakan Cloud Monitoring API. Jika cluster Anda menggunakan Workload Identity Federation for GKE, Anda harus memberikan izin akun layanan Kubernetes Anda ke Monitoring API. Bagian ini menjelaskan hal berikut:
- Membuat Google Cloud akun layanan khusus,
gmp-test-sa. - Mengikat Google Cloud akun layanan ke akun layanan
Kubernetes default di namespace pengujian,
NAMESPACE_NAME. - Memberikan izin yang diperlukan ke akun layanan Google Cloud .
Buat dan ikat akun layanan
Langkah ini muncul di beberapa tempat dalam dokumentasi Managed Service for Prometheus. Jika Anda telah melakukan langkah ini sebagai bagian dari tugas sebelumnya, Anda tidak perlu mengulanginya. Lanjutkan ke Melakukan otorisasi akun layanan.
Urutan perintah berikut membuat akun layanan gmp-test-sa
dan mengikatnya ke akun layanan Kubernetes default di namespace
NAMESPACE_NAME:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Jika Anda menggunakan namespace atau akun layanan GKE yang berbeda, sesuaikan perintah dengan tepat.
Memberikan otorisasi akun layanan
Grup izin terkait dikumpulkan ke dalam peran, dan Anda memberikan peran tersebut kepada akun utama, dalam contoh ini, akun layanan Google Cloud. Untuk mengetahui informasi selengkapnya tentang peran Monitoring, lihat Kontrol akses.
Perintah berikut memberikan peran Monitoring API yang diperlukan akun layanan Google Cloud ,gmp-test-sa, untuk menulis data metrik.
Jika Anda telah memberikan peran tertentu kepada Google Cloud akun layanan sebagai bagian dari tugas sebelumnya, Anda tidak perlu melakukannya lagi.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Men-debug konfigurasi Workload Identity Federation for GKE
Jika Anda mengalami masalah saat mengaktifkan Workload Identity Federation for GKE, lihat dokumentasi untuk memverifikasi penyiapan Workload Identity Federation for GKE dan panduan pemecahan masalah Workload Identity Federation for GKE.
Karena kesalahan ketik dan penyalinan sebagian adalah sumber kesalahan paling umum saat mengonfigurasi Workload Identity Federation untuk GKE, kami sangat merekomendasikan penggunaan variabel yang dapat diedit dan ikon salin tempel yang dapat diklik yang disematkan dalam contoh kode dalam petunjuk ini.
Workload Identity Federation for GKE di lingkungan produksi
Contoh yang dijelaskan dalam dokumen ini mengikat akun layanan Google Cloud ke akun layanan Kubernetes default dan memberikan semua izin yang diperlukan kepada akun layanan Google Clouduntuk menggunakan Monitoring API.
Dalam lingkungan produksi, Anda mungkin ingin menggunakan pendekatan yang lebih terperinci, dengan akun layanan untuk setiap komponen, masing-masing dengan izin minimal. Untuk mengetahui informasi selengkapnya tentang cara mengonfigurasi akun layanan untuk pengelolaan workload identity, lihat Menggunakan Workload Identity Federation untuk GKE.
Menyiapkan OpenTelemetry Collector
Bagian ini memandu Anda menyiapkan dan menggunakan OpenTelemetry Collector untuk menyalin metrik dari aplikasi contoh dan mengirim data ke Google Cloud Managed Service for Prometheus. Untuk informasi konfigurasi mendetail, lihat bagian berikut:
OpenTelemetry Collector serupa dengan biner agen Managed Service for Prometheus. Komunitas OpenTelemetry secara rutin memublikasikan rilis, termasuk kode sumber, biner, dan image container.
Anda dapat men-deploy artefak ini di VM atau cluster Kubernetes menggunakan default praktik terbaik, atau Anda dapat menggunakan pembuat pengumpul untuk membuat pengumpul Anda sendiri yang hanya terdiri dari komponen yang Anda butuhkan. Untuk membuat kolektor yang akan digunakan dengan Managed Service for Prometheus, Anda memerlukan komponen berikut:
- Managed Service for Prometheus exporter, yang menulis metrik Anda ke Managed Service for Prometheus.
- Penerima untuk meng-scrape metrik Anda. Dokumen ini mengasumsikan bahwa Anda menggunakan penerima OpenTelemetry Prometheus, tetapi eksportir Managed Service for Prometheus kompatibel dengan penerima metrik OpenTelemetry apa pun.
- Prosesor untuk mengelompokkan dan menandai metrik Anda guna menyertakan ID resource penting, bergantung pada lingkungan Anda.
Komponen ini diaktifkan menggunakan file
konfigurasi
yang diteruskan ke Pengumpul dengan tanda --config.
Bagian berikut membahas cara mengonfigurasi setiap komponen ini secara lebih mendetail. Dokumen ini menjelaskan cara menjalankan pengumpul di GKE dan di tempat lain.
Mengonfigurasi dan men-deploy Pengumpul
Baik Anda menjalankan pengumpulan di Google Cloud atau di lingkungan lain, Anda tetap dapat mengonfigurasi OpenTelemetry Collector untuk mengekspor ke Managed Service for Prometheus. Perbedaan terbesar akan terletak pada cara Anda mengonfigurasi Pengumpul. Di lingkungan non-Google Cloud , mungkin ada pemformatan tambahan data metrik yang diperlukan agar kompatibel dengan Managed Service for Prometheus. Namun, di Google Cloud, sebagian besar pemformatan ini dapat dideteksi secara otomatis oleh Pengumpul.
Menjalankan OpenTelemetry Collector di GKE
Anda dapat menyalin konfigurasi berikut ke dalam file bernama config.yaml untuk menyiapkan
OpenTelemetry Collector di GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
Konfigurasi sebelumnya menggunakan penerima Prometheus dan pengekspor Managed Service for Prometheus untuk menyalin endpoint metrik di Pod Kubernetes dan mengekspor metrik tersebut ke Managed Service for Prometheus. Prosesor pipeline memformat dan mengelompokkan data.
Untuk mengetahui detail selengkapnya tentang fungsi setiap bagian konfigurasi ini, beserta konfigurasi untuk platform yang berbeda, lihat bagian berikut yang menjelaskan secara mendetail tentang meng-scraping metrik dan menambahkan pemroses.
Saat menggunakan konfigurasi Prometheus yang ada dengan penerima prometheus OpenTelemetry Collector, ganti karakter tanda dolar tunggal, 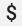 , dengan karakter ganda,
, dengan karakter ganda, 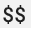 , untuk menghindari pemicuan penggantian variabel lingkungan. Untuk mengetahui informasi selengkapnya, lihat
Mengambil metrik Prometheus.
, untuk menghindari pemicuan penggantian variabel lingkungan. Untuk mengetahui informasi selengkapnya, lihat
Mengambil metrik Prometheus.
Anda dapat mengubah konfigurasi ini berdasarkan lingkungan, penyedia, dan metrik yang ingin Anda ambil, tetapi contoh konfigurasi adalah titik awal yang direkomendasikan untuk dijalankan di GKE.
Menjalankan OpenTelemetry Collector di luar Google Cloud
Menjalankan OpenTelemetry Collector di luar Google Cloud, seperti di lokal atau di penyedia cloud lain, serupa dengan menjalankan Collector di GKE. Namun, metrik yang Anda scraping cenderung tidak secara otomatis menyertakan data yang paling sesuai formatnya untuk Managed Service for Prometheus. Oleh karena itu, Anda harus berhati-hati saat mengonfigurasi pengumpul untuk memformat metrik agar kompatibel dengan Managed Service for Prometheus.
Anda dapat menyalin konfigurasi berikut ke dalam file bernama config.yaml untuk menyiapkan
OpenTelemetry Collector untuk deployment di cluster Kubernetes non-GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
Konfigurasi ini melakukan hal berikut:
- Menyiapkan konfigurasi scraping penemuan layanan Kubernetes untuk Prometheus. Untuk mengetahui informasi selengkapnya, lihat mengambil metrik Prometheus.
- Menetapkan atribut resource
cluster,namespace, danlocationsecara manual. Untuk mengetahui informasi selengkapnya tentang atribut resource, termasuk deteksi resource untuk Amazon EKS dan Azure AKS, lihat Mendeteksi atribut resource. - Menetapkan opsi
projectdi eksportirgooglemanagedprometheus. Untuk mengetahui informasi selengkapnya tentang eksportir, lihat Mengonfigurasi eksportirgooglemanagedprometheus.
Saat menggunakan konfigurasi Prometheus yang ada dengan penerima prometheus OpenTelemetry Collector, ganti karakter tanda dolar tunggal, , dengan karakter ganda, , untuk menghindari pemicuan penggantian variabel lingkungan. Untuk mengetahui informasi selengkapnya, lihat
Mengambil metrik Prometheus.
Untuk mengetahui informasi tentang praktik terbaik dalam mengonfigurasi Pengumpul di cloud lain, lihat Amazon EKS atau Azure AKS.
Men-deploy aplikasi contoh
Aplikasi contoh memancarkan
metrik penghitung example_requests_total dan metrik histogram example_random_numbers (di antara metrik lainnya) di port metrics.
Manifes untuk contoh ini menentukan tiga replika.
Untuk men-deploy aplikasi contoh, jalankan perintah berikut:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Buat konfigurasi pengumpul Anda sebagai ConfigMap
Setelah membuat konfigurasi dan menempatkannya dalam file bernama config.yaml,
gunakan file tersebut untuk membuat ConfigMap Kubernetes berdasarkan file config.yaml Anda.
Saat di-deploy, pengumpul akan memasang ConfigMap dan memuat file.
Untuk membuat ConfigMap bernama otel-config dengan konfigurasi Anda, gunakan perintah
berikut:
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
Men-deploy pengumpul
Buat file bernama collector-deployment.yaml dengan konten berikut:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
Buat deployment Pengumpul di cluster Kubernetes Anda dengan menjalankan perintah berikut:
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
Setelah pod dimulai, pod akan meng-scrape aplikasi contoh dan melaporkan metrik ke Managed Service for Prometheus.
Untuk mengetahui informasi tentang cara membuat kueri data Anda, lihat Membuat kueri menggunakan Cloud Monitoring atau Membuat kueri menggunakan Grafana.
Memberikan kredensial secara eksplisit
Saat berjalan di GKE, OpenTelemetry Collector
akan otomatis mengambil kredensial dari lingkungan berdasarkan
akun layanan node.
Di cluster Kubernetes non-GKE, kredensial harus diberikan secara eksplisit ke OpenTelemetry Collector menggunakan flag atau variabel lingkungan GOOGLE_APPLICATION_CREDENTIALS.
Tetapkan konteks ke project target Anda:
gcloud config set project PROJECT_ID
Membuat akun layanan:
gcloud iam service-accounts create gmp-test-sa
Langkah ini membuat akun layanan yang mungkin telah Anda buat di petunjuk Workload Identity Federation untuk GKE.
Berikan izin yang diperlukan ke akun layanan:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Buat dan download kunci untuk akun layanan:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Tambahkan file kunci sebagai secret ke cluster non-GKE Anda:
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Buka resource OpenTelemetry Deployment untuk mengedit:
kubectl -n NAMESPACE_NAME edit deployment otel-collector
Tambahkan teks yang ditampilkan dalam huruf tebal ke resource:
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...Simpan file dan tutup editor. Setelah perubahan diterapkan, pod akan dibuat ulang dan mulai mengautentikasi ke backend metrik dengan akun layanan yang diberikan.
Melakukan scraping metrik Prometheus
Bagian ini dan bagian berikutnya memberikan informasi penyesuaian tambahan untuk menggunakan OpenTelemetry Collector. Informasi ini mungkin berguna dalam situasi tertentu, tetapi tidak ada yang diperlukan untuk menjalankan contoh yang dijelaskan dalam Menyiapkan OpenTelemetry Collector.
Jika aplikasi Anda sudah mengekspos endpoint Prometheus, OpenTelemetry Collector dapat meng-scrape endpoint tersebut menggunakan format config scrape yang sama dengan yang akan Anda gunakan dengan konfigurasi Prometheus standar. Untuk melakukannya, aktifkan Prometheus receiver di konfigurasi pengumpul Anda.
Konfigurasi penerima Prometheus untuk pod Kubernetes mungkin terlihat seperti berikut:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
Ini adalah konfigurasi pengambilan berbasis penemuan layanan yang dapat Anda ubah sesuai kebutuhan untuk mengambil aplikasi Anda.
Saat menggunakan konfigurasi Prometheus yang ada dengan penerima prometheus OpenTelemetry Collector, ganti karakter tanda dolar tunggal, , dengan karakter ganda, , untuk menghindari pemicuan penggantian variabel lingkungan. Hal ini terutama penting untuk dilakukan pada nilai replacement dalam bagian relabel_configs. Misalnya, jika Anda memiliki bagian relabel_config berikut:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
Kemudian, tulis ulang menjadi:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
Untuk mengetahui informasi selengkapnya, lihat dokumentasi OpenTelemetry.
Selanjutnya, sebaiknya gunakan pemroses untuk memformat metrik Anda. Dalam banyak kasus, pemroses harus digunakan untuk memformat metrik Anda dengan benar.
Menambahkan pemroses
Prosesor OpenTelemetry mengubah data telemetri sebelum diekspor. Anda dapat menggunakan pemroses berikut untuk memastikan metrik Anda ditulis dalam format yang kompatibel dengan Managed Service for Prometheus.
Mendeteksi atribut resource
Pengekspor Managed Service for Prometheus untuk OpenTelemetry menggunakan
prometheus_target resource yang dipantau
untuk mengidentifikasi titik data deret waktu secara unik. Exporter mengurai kolom monitored-resource yang diperlukan dari atribut resource pada titik data metrik.
Kolom dan atribut yang nilainya di-scrap adalah:
- project_id: terdeteksi otomatis oleh Kredensial Default
Aplikasi,
gcp.project.id, atauprojectdalam konfigurasi pengekspor (lihat mengonfigurasi pengekspor) - lokasi:
location,cloud.availability_zone,cloud.region - cluster:
cluster,k8s.cluster_name - namespace:
namespace,k8s.namespace_name - job:
service.name+service.namespace - instance:
service.instance.id
Jika label ini tidak ditetapkan ke nilai unik, error "duplicate timeseries" dapat terjadi saat mengekspor ke Managed Service for Prometheus. Dalam banyak kasus, nilai dapat terdeteksi secara otomatis untuk label ini, tetapi dalam beberapa kasus, Anda mungkin harus memetakannya sendiri. Bagian selanjutnya menjelaskan skenario ini.
Penerima Prometheus otomatis menetapkan atribut service.name berdasarkan job_name dalam konfigurasi pengambilan data, dan atribut service.instance.id berdasarkan instance target pengambilan data. Penerima juga menetapkan
k8s.namespace.name saat menggunakan role: pod dalam konfigurasi pengambilan data.
Jika memungkinkan, isi atribut lainnya secara otomatis menggunakan prosesor deteksi resource. Namun, bergantung pada lingkungan Anda, beberapa atribut mungkin tidak dapat dideteksi secara otomatis. Dalam hal ini, Anda dapat menggunakan pemroses lain untuk memasukkan nilai ini secara manual atau menguraikannya dari label metrik. Bagian berikut mengilustrasikan konfigurasi untuk mendeteksi resource di berbagai platform.
GKE
Saat menjalankan OpenTelemetry di GKE, Anda harus mengaktifkan pemroses deteksi resource untuk mengisi label resource. Pastikan metrik Anda belum berisi label resource yang dikhususkan. Jika hal ini tidak dapat dihindari, lihat Menghindari konflik atribut resource dengan mengganti nama atribut.
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
Bagian ini dapat disalin langsung ke file konfigurasi Anda, menggantikan bagian
processors jika sudah ada.
Amazon EKS
Detektor resource EKS tidak otomatis mengisi atribut cluster atau namespace. Anda dapat memberikan nilai ini secara manual menggunakan
pemroses
resource,
seperti yang ditunjukkan dalam contoh berikut:
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Anda juga dapat mengonversi nilai ini dari label metrik menggunakan groupbyattrs
prosesor (lihat memindahkan label metrik ke label resource di bawah).
Azure AKS
Detektor resource AKS tidak otomatis mengisi atribut cluster atau namespace. Anda dapat memberikan nilai ini secara manual menggunakan
pemroses
resource,
seperti yang ditunjukkan dalam contoh berikut:
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Anda juga dapat mengonversi nilai ini dari label metrik menggunakan prosesor groupbyattrs; lihat Memindahkan label metrik ke label resource.
Lingkungan lokal dan non-cloud
Dengan lingkungan lokal atau non-cloud, Anda mungkin tidak dapat mendeteksi atribut resource yang diperlukan secara otomatis. Dalam hal ini, Anda dapat memancarkan label ini dalam metrik dan memindahkannya ke atribut resource (lihat Memindahkan label metrik ke label resource), atau menetapkan semua atribut resource secara manual seperti yang ditunjukkan dalam contoh berikut:
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
Membuat konfigurasi pengumpul sebagai ConfigMap menjelaskan cara
menggunakan konfigurasi. Bagian tersebut mengasumsikan bahwa Anda telah menempatkan konfigurasi dalam file
yang disebut config.yaml.
Atribut resource project_id masih dapat disetel secara otomatis saat menjalankan Pengumpul dengan Kredensial Default Aplikasi.
Jika Pengumpul Anda tidak memiliki akses ke Kredensial Default Aplikasi, lihat
Menyiapkan project_id.
Atau, Anda dapat menetapkan atribut resource yang diperlukan secara manual dalam
variabel lingkungan, OTEL_RESOURCE_ATTRIBUTES, dengan daftar pasangan nilai kunci yang dipisahkan koma, misalnya:
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
Kemudian, gunakan prosesor detektor resource env
untuk menetapkan atribut resource:
processors:
resourcedetection:
detectors: [env]
Menghindari konflik atribut resource dengan mengganti nama atribut
Jika metrik Anda sudah berisi label yang bertentangan dengan atribut resource yang diperlukan (seperti location, cluster, atau namespace), ganti namanya untuk menghindari konflik. Konvensi Prometheus adalah menambahkan awalan exported_ ke nama label. Untuk menambahkan awalan ini, gunakan transform
processor.
Konfigurasi processors berikut mengganti nama potensi bentrokan dan
menyelesaikan konflik kunci dari metrik:
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
Memindahkan label metrik ke label resource
Dalam beberapa kasus, metrik Anda mungkin sengaja melaporkan label seperti
namespace karena eksportir Anda memantau beberapa namespace. Misalnya, saat menjalankan pengekspor kube-state-metrics.
Dalam skenario ini, label ini dapat dipindahkan ke atribut resource menggunakan groupbyattrs processor:
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
Pada contoh sebelumnya, jika diberi metrik dengan label namespace, cluster,
atau location, label tersebut akan dikonversi menjadi atribut
resource yang cocok.
Membatasi permintaan API dan penggunaan memori
Dua pemroses lainnya, pemroses batch dan pemroses pembatas memori memungkinkan Anda membatasi konsumsi resource pengumpul.
Batch processing
Dengan mengelompokkan permintaan, Anda dapat menentukan jumlah titik data yang akan dikirim dalam satu permintaan. Perhatikan bahwa Cloud Monitoring memiliki batas 200 deret waktu per permintaan. Aktifkan pemroses batch menggunakan setelan berikut:
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
Pembatasan memori
Sebaiknya aktifkan prosesor pembatas memori untuk mencegah pengumpul data Anda mengalami error saat throughput tinggi. Aktifkan pemrosesan menggunakan setelan berikut:
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
Mengonfigurasi eksportir googlemanagedprometheus
Secara default, penggunaan eksportir googlemanagedprometheus di GKE
tidak memerlukan konfigurasi tambahan. Untuk banyak kasus penggunaan, Anda hanya perlu mengaktifkannya dengan blok kosong di bagian exporters:
exporters: googlemanagedprometheus:
Namun, pengekspor menyediakan beberapa setelan konfigurasi opsional. Bagian berikut menjelaskan setelan konfigurasi lainnya.
Setelan project_id
Untuk mengaitkan deret waktu dengan project Google Cloud , resource yang dipantauprometheus_target harus memiliki project_id yang ditetapkan.
Saat menjalankan OpenTelemetry di Google Cloud, pengekspor Managed Service for Prometheus secara default menetapkan nilai ini berdasarkan Kredensial Default Aplikasi yang ditemukannya. Jika tidak ada kredensial yang tersedia, atau Anda ingin mengganti project default, Anda memiliki dua opsi:
- Tetapkan
projectdalam konfigurasi eksportir - Tambahkan atribut resource
gcp.project.idke metrik Anda.
Sebaiknya gunakan nilai default (tidak disetel) untuk project_id daripada
menyetelnya secara eksplisit, jika memungkinkan.
Tetapkan project dalam konfigurasi eksportir
Cuplikan konfigurasi berikut mengirimkan metrik ke
Managed Service for Prometheus di Google Cloud project MY_PROJECT:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
Satu-satunya perubahan dari contoh sebelumnya adalah baris baru project: MY_PROJECT.
Setelan ini berguna jika Anda tahu bahwa setiap metrik yang masuk melalui
Collector ini harus dikirim ke MY_PROJECT.
Menetapkan atribut resource gcp.project.id
Anda dapat menetapkan asosiasi project per metrik dengan menambahkan atribut resource
gcp.project.id ke metrik Anda. Tetapkan nilai atribut
ke nama project yang harus dikaitkan dengan metrik.
Misalnya, jika metrik Anda sudah memiliki label project, label ini dapat
dipindahkan ke atribut resource dan diganti namanya menjadi gcp.project.id menggunakan
pemroses dalam konfigurasi Pengumpul, seperti yang ditunjukkan dalam contoh berikut:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
Menetapkan opsi klien
Pengekspor googlemanagedprometheus menggunakan klien gRPC untuk
Managed Service for Prometheus. Oleh karena itu, setelan opsional
tersedia untuk mengonfigurasi klien gRPC:
compression: Mengaktifkan kompresi gzip untuk permintaan gRPC, yang berguna untuk meminimalkan biaya transfer data saat mengirim data dari cloud lain ke Managed Service for Prometheus (nilai yang valid:gzip).user_agent: Mengganti string agen pengguna yang dikirim pada permintaan ke Cloud Monitoring; hanya berlaku untuk metrik. Secara default, nilai ini adalah nomor build dan versi OpenTelemetry Collector Anda, misalnya,opentelemetry-collector-contrib 0.128.0.endpoint: Menetapkan endpoint tempat data metrik akan dikirim.use_insecure: Jika benar (true), menggunakan gRPC sebagai transport komunikasi. Hanya berpengaruh jika nilaiendpointbukan "".grpc_pool_size: Menetapkan ukuran pool koneksi di klien gRPC.prefix: Mengonfigurasi awalan metrik yang dikirim ke Managed Service for Prometheus. Nilai defaultnya adalahprometheus.googleapis.com. Jangan mengubah awalan ini; jika Anda melakukannya, metrik tidak dapat dikueri dengan PromQL di UI Cloud Monitoring.
Dalam sebagian besar kasus, Anda tidak perlu mengubah nilai ini dari defaultnya. Namun, Anda dapat mengubahnya untuk mengakomodasi keadaan khusus.
Semua setelan ini ditetapkan dalam blok metric di bagian
pengekspor googlemanagedprometheus, seperti yang ditunjukkan dalam contoh berikut:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
Langkah berikutnya
- Gunakan PromQL di Cloud Monitoring untuk membuat kueri metrik Prometheus.
- Gunakan Grafana untuk membuat kueri metrik Prometheus.
- Siapkan OpenTelemetry Collector sebagai agen file bantuan di Cloud Run.
-
Halaman Pengelolaan Metrik Cloud Monitoring memberikan informasi yang dapat membantu Anda mengontrol jumlah yang Anda belanjakan untuk metrik yang dapat ditagih tanpa memengaruhi kemampuan pengamatan. Halaman Pengelolaan Metrik melaporkan informasi berikut:
- Volume penyerapan untuk penagihan berbasis byte dan sampel, di seluruh domain metrik dan untuk setiap metrik.
- Data tentang label dan kardinalitas metrik.
- Jumlah pembacaan untuk setiap metrik.
- Penggunaan metrik dalam kebijakan pemberitahuan dan dasbor kustom.
- Rasio error penulisan metrik.
Anda juga dapat menggunakan halaman Pengelolaan Metrik untuk mengecualikan metrik yang tidak diperlukan, sehingga menghilangkan biaya penyerapan metrik tersebut. Untuk mengetahui informasi selengkapnya tentang halaman Pengelolaan Metrik, lihat Melihat dan mengelola penggunaan metrik.