Ce document explique comment configurer le collecteur OpenTelemetry pour extraire des métriques Prometheus standards et les transmettre à Google Cloud Managed Service pour Prometheus. Le collecteur OpenTelemetry est un agent que vous pouvez déployer vous-même et configurer pour effectuer des exportations vers Managed Service pour Prometheus. La configuration est semblable à l'exécution de Managed Service pour Prometheus avec une collecte auto-déployée.
Vous pouvez privilégier le collecteur OpenTelemetry à la collecte auto-déployée pour les raisons suivantes :
- Le collecteur OpenTelemetry vous permet d'acheminer vos données de télémétrie vers plusieurs backends en configurant différents exportateurs dans votre pipeline.
- Le collecteur accepte également les signaux provenant des métriques, des journaux et des traces. Vous pouvez donc grâce à lui gérer ces trois types de signaux via un seul et même agent.
- Le format de données d'OpenTelemetry, indépendant du fournisseur (le protocole OpenTelemetry ou OTLP) est compatible avec un robuste écosystème de bibliothèques et de composants de collecteurs connectables. Cela autorise toute une plage d'options de personnalisation pour la réception, le traitement et l'exportation de vos données.
En contrepartie, l'exécution d'un collecteur OpenTelemetry nécessite une approche de déploiement et de maintenance autogérée. L'approche retenue dépendra de vos besoins spécifiques. Toutefois, nous proposons dans ce document les consignes recommandées pour configurer le collecteur OpenTelemetry en utilisant Managed Service pour Prometheus en tant que backend.
Avant de commencer
Cette section décrit la configuration nécessaire pour les tâches décrites dans ce document.
Configurer des projets et des outils
Pour utiliser Google Cloud Managed Service pour Prometheus, vous avez besoin des ressources suivantes :
Un projet Google Cloud avec l'API Cloud Monitoring activée.
Si vous n'avez pas de projet Google Cloud , procédez comme suit :
Dans la console Google Cloud , accédez à Nouveau projet :
Dans le champ Nom du projet, saisissez un nom pour votre projet, puis cliquez sur Créer.
Accéder à la page Facturation :
Sélectionnez le projet que vous venez de créer s'il n'est pas déjà sélectionné en haut de la page.
Vous êtes invité à choisir un profil de paiement existant ou à en créer un.
L'API Monitoring est activée par défaut pour les nouveaux projets.
Si vous disposez déjà d'un projet Google Cloud , assurez-vous que l'API Monitoring est activée :
Accédez à la page API et services :
Sélectionnez votre projet.
Cliquez sur Enable APIs and Services (Activer les API et les services).
Recherchez "Monitoring".
Dans les résultats de recherche, cliquez sur "API Cloud Monitoring".
Si l'option "API activée" ne s'affiche pas, cliquez sur le bouton Activer.
Un cluster Kubernetes. Si vous ne disposez pas de cluster Kubernetes, suivez les instructions du guide de démarrage rapide pour GKE.
Vous avez également besoin des outils de ligne de commande suivants :
gcloudkubectl
Les outils gcloud et kubectl font partie de Google Cloud CLI. Pour en savoir plus sur leur installation, consultez la page Gérer les composants de Google Cloud CLI. Pour afficher les composants de la CLI gcloud que vous avez installés, exécutez la commande suivante :
gcloud components list
Configurer votre environnement
Pour éviter de saisir à plusieurs reprises l'ID de votre projet ou le nom de votre cluster, effectuez la configuration suivante :
Configurez les outils de ligne de commande comme suit :
Configurez la gcloud CLI pour faire référence à l'ID de votre projetGoogle Cloud :
gcloud config set project PROJECT_ID
Configurez la CLI
kubectlpour utiliser votre cluster :kubectl config set-cluster CLUSTER_NAME
Pour en savoir plus sur ces outils, consultez les articles suivants :
Configurer un espace de noms
Créez l'espace de noms Kubernetes NAMESPACE_NAME pour les ressources que vous créez dans le cadre de l'exemple d'application :
kubectl create ns NAMESPACE_NAME
Vérifier les identifiants du compte de service
Si Workload Identity Federation for GKE est activé sur votre cluster Kubernetes, vous pouvez ignorer cette section.
Lors de l'exécution sur GKE, Managed Service pour Prometheus récupère automatiquement les identifiants de l'environnement en fonction du compte de service Compute Engine par défaut. Le compte de service par défaut dispose des autorisations nécessaires, monitoring.metricWriter et monitoring.viewer, par défaut. Si vous n'utilisez pas Workload Identity Federation for GKE et que vous avez précédemment supprimé l'un de ces rôles du compte de service de nœud par défaut, vous devrez rajouter ces autorisations manquantes avant de continuer.
Configurer un compte de service pour Workload Identity Federation for GKE
Si Workload Identity Federation for GKE n'est pas activé sur votre cluster Kubernetes, vous pouvez ignorer cette section.
Managed Service pour Prometheus capture les données de métriques à l'aide de l'API Cloud Monitoring. Si votre cluster utilise Workload Identity Federation for GKE, vous devez autoriser votre compte de service Kubernetes à accéder à l'API Monitoring. Cette section décrit les opérations suivantes :
- Créer un compte de serviceGoogle Cloud dédié,
gmp-test-sa. - Associer le compte de service Google Cloud au compte de service Kubernetes par défaut dans un espace de noms de test,
NAMESPACE_NAME. - Accorder l'autorisation nécessaire au compte de service Google Cloud .
Créer et associer le compte de service
Cette étape apparaît à plusieurs endroits de la documentation de Managed Service pour Prometheus. Si vous avez déjà effectué cette étape dans le cadre d'une tâche précédente, vous n'avez pas besoin de la répéter. Passez directement à la section Autoriser le compte de service.
La séquence de commandes suivante crée le compte de service gmp-test-sa et l'associe au compte de service Kubernetes par défaut dans l'espace de noms NAMESPACE_NAME :
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Si vous utilisez un autre espace de noms ou compte de service GKE, ajustez les commandes en conséquence.
Autoriser le compte de service
Les groupes d'autorisations associées sont collectés dans des rôles que vous attribuez à un compte principal, dans cet exemple, le compte de service Google Cloud. Pour en savoir plus sur les rôles Monitoring, consultez Contrôle des accès.
La commande suivante accorde au compte de service Google Cloud , gmp-test-sa, les rôles de l'API Monitoring dont il a besoin pour écrire les données de métriques.
Si vous avez déjà attribué un rôle spécifique au compte de service Google Cloud dans le cadre de la tâche précédente, vous n'avez pas besoin de le faire à nouveau.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Déboguer votre configuration de Workload Identity Federation for GKE
Si vous rencontrez des difficultés pour utiliser Workload Identity Federation for GKE, consultez la documentation sur la vérification de la configuration de Workload Identity Federation for GKE et le guide de dépannage de Workload Identity Federation for GKE.
Les fautes de frappe et les copier-coller partiels sont les sources d'erreurs les plus courantes lors de la configuration de Workload Identity Federation for GKE. Nous vous recommandons vivement d'utiliser les variables modifiables et les icônes de copier-coller cliquables intégrées dans les exemples de code figurant dans ces instructions.
Workload Identity Federation for GKE dans les environnements de production
L'exemple décrit dans ce document associe le compte de service Google Cloud au compte de service Kubernetes par défaut et accorde au compte de service Google Cloudtoutes les autorisations nécessaires pour utiliser l'API Monitoring.
Dans un environnement de production, vous pouvez utiliser une approche plus précise, avec un compte de service pour chaque composant, chacun disposant d'autorisations minimales. Pour en savoir plus sur la configuration des comptes de service pour la gestion des identités de charge de travail, consultez la section Utiliser Workload Identity Federation for GKE.
Configurer le collecteur OpenTelemetry
Cette section vous guide dans la configuration et l'utilisation du collecteur OpenTelemetry pour extraire les métriques à partir d'un exemple d'application, et envoyer les données à Google Cloud Managed Service pour Prometheus. Pour obtenir des informations détaillées sur la configuration, consultez les sections suivantes :
- Extraire les métriques Prometheus
- Ajouter des processeurs
- Configurer l'exportateur
googlemanagedprometheus
Le collecteur OpenTelemetry est semblable au binaire de l'agent Managed Service pour Prometheus. La communauté OpenTelemetry publie régulièrement des versions, comprenant code source, binaires, et images de conteneurs.
Vous pouvez déployer ces artefacts sur des VM ou des clusters Kubernetes en suivant les bonnes pratiques par défaut, ou utiliser le compilateur de collecteur pour créer votre propre collecteur, qui ne va réunir que les composants dont vous avez besoin. Pour créer un collecteur à utiliser avec Managed Service pour Prometheus, vous devez spécifier les composants suivants :
- L'exportateur de Managed Service pour Prometheus, qui écrit vos métriques dans Managed Service pour Prometheus.
- Un récepteur pour extraire vos métriques. Ce document part du principe que vous utilisez le récepteur Prometheus OpenTelemetry, mais l'exportateur de Managed Service pour Prometheus est compatible avec n'importe quel récepteur de métriques OpenTelementry.
- Des processeurs pour assurer le traitement par lot et le balisage de vos métriques, afin d'inclure des identifiants de ressources importants en fonction de votre environnement.
Ces composants sont activés à l'aide d'un fichier de configuration transmis au collecteur à l'aide de l'option --config.
Les sections suivantes expliquent plus en détail comment configurer chacun de ces composants. Ce document explique comment exécuter le collecteur sur GKE, mais aussi dans n'importe quel autre environnement.
Configurer et déployer le collecteur
Que vous exécutiez votre collecte sur Google Cloud ou dans un autre environnement, vous pouvez toujours configurer le collecteur OpenTelemetry pour réaliser des exportations vers Managed Service pour Prometheus. La principale différence réside dans la configuration du collecteur. Dans les environnements autres queGoogle Cloud , une procédure supplémentaire de mise en forme des données des métriques peut être nécessaire pour assurer leur compatibilité avec Managed Service pour Prometheus. Tandis que sur Google Cloud, une grande partie de cette mise en forme peut être détectée automatiquement par le collecteur.
Exécuter le collecteur OpenTelemetry sur GKE
Vous pouvez copier la configuration suivante dans un fichier nommé config.yaml pour configurer le collecteur OpenTelemetry sur GKE :
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
La configuration précédente utilise le récepteur Prometheus et l'exportateur de Managed Service pour Prometheus pour extraire les points de terminaison des métriques sur les pods Kubernetes et exporter ces métriques vers Managed Service pour Prometheus. Les processeurs du pipeline mettent en forme et regroupent les données.
Pour en savoir plus sur le rôle de chacune des parties de cette configuration, ainsi que sur les configurations des différentes plates-formes, consultez les sections détaillées ci-après sur le scraping des métriques et l'ajout de processeurs.
Lorsque vous utilisez une configuration Prometheus existante avec le récepteur prometheus du collecteur OpenTelemetry, remplacez les caractères dollar simples, 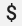 , par des caractères doubles,
, par des caractères doubles, 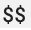 , pour éviter de déclencher une substitution de variables d'environnement. Pour en savoir plus, consultez la section Extraire les métriques Prometheus.
, pour éviter de déclencher une substitution de variables d'environnement. Pour en savoir plus, consultez la section Extraire les métriques Prometheus.
Vous pouvez modifier cette configuration en fonction de votre environnement, de votre fournisseur et des métriques que vous souhaitez extraire. Toutefois, l'exemple de configuration constitue un point de départ recommandé pour l'exécution sur GKE.
Exécuter le collecteur OpenTelemetry en dehors de Google Cloud
L'exécution du collecteur OpenTelemetry en dehors de Google Cloud, sur site ou sur d'autres fournisseurs de services cloud, est semblable à l'exécution du collecteur sur GKE. Cependant, les métriques que vous extrayez sont moins susceptibles d'inclure automatiquement dont la mise en forme se prête idéalement à Managed Service pour Prometheus. Par conséquent, vous devez prendre soin de configurer le collecteur pour qu'il assure la mise en forme des métriques, afin qu'elles soient compatibles avec Managed Service pour Prometheus.
Vous pouvez copier la configuration suivante dans un fichier nommé config.yaml pour configurer le collecteur OpenTelemetry pour un déploiement sur un cluster Kubernetes non GKE :
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
Cette configuration effectue les opérations suivantes :
- Définition d'une configuration de scraping pour la détection de services Kubernetes pour Prometheus. Pour en savoir plus, consultez la section Scraping de métriques dans Prometheus.
- Définition manuelle des attributs de ressource
cluster,namespaceetlocation. Pour en savoir plus sur les attributs de ressource, y compris la détection de ressources pour Amazon EKS et Azure AKS, consultez la section Détecter les attributs de ressource. - Définition de l'option
projectdans l'exportateurgooglemanagedprometheus. Pour en savoir plus sur l'exportateur, consultez la section Configurer l'exportateurgooglemanagedprometheus.
Lorsque vous utilisez une configuration Prometheus existante avec le récepteur prometheus du collecteur OpenTelemetry, remplacez les caractères dollar simples, , par des caractères doubles, , pour éviter de déclencher une substitution de variables d'environnement. Pour en savoir plus, consultez la section Extraire les métriques Prometheus.
Pour en savoir plus sur les bonnes pratiques concernant la configuration du collecteur sur d'autres clouds, consultez la section Amazon EKS ou Azure AKS.
Déployer l'exemple d'application
L'exemple d'application émet la métrique de compteur example_requests_total et la métrique d'histogramme example_random_numbers (entre autres) sur son port metrics.
Le fichier manifeste de cet exemple définit trois instances répliquées.
Pour déployer l'exemple d'application, exécutez la commande suivante :
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Créer votre configuration de collecteur en tant que ConfigMap
Une fois que vous avez créé votre configuration et que vous l'avez placée dans un fichier nommé config.yaml, utilisez ce fichier pour créer un ConfigMap Kubernetes basé sur votre fichier config.yaml.
Une fois le collecteur déployé, il va installer le ConfigMap et charger le fichier.
Pour créer un ConfigMap nommé otel-config avec votre configuration, exécutez la commande suivante :
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
Déployer le collecteur
Créez un fichier nommé collector-deployment.yaml avec le contenu suivant :
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
Créez le déploiement du collecteur dans votre cluster Kubernetes en exécutant la commande suivante :
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
Une fois le pod démarré, il va extraire l'exemple d'application et transmettre les métriques à Managed Service pour Prometheus.
Pour en savoir plus sur l'interrogation des données, consultez les pages Interroger à l'aide de Cloud Monitoring ou Interroger à l'aide de Grafana.
Fournir des identifiants de manière explicite
Lors de l'exécution sur GKE, le collecteur OpenTelemetry récupère automatiquement les identifiants de l'environnement en fonction du compte de service du nœud.
Dans les clusters Kubernetes non GKE, les identifiants doivent être explicitement fournis au collecteur OpenTelemetry à l'aide d'options ou de la variable d'environnement GOOGLE_APPLICATION_CREDENTIALS.
Définissez le contexte de votre projet cible :
gcloud config set project PROJECT_ID
Créez un compte de service :
gcloud iam service-accounts create gmp-test-sa
Cette étape crée le compte de service que vous avez peut-être déjà créé dans les instructions de Workload Identity Federation for GKE.
Accordez les autorisations requises au compte de service :
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Créez et téléchargez une clé pour le compte de service :
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Ajoutez le fichier de clé en tant que secret à votre cluster non-GKE :
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Ouvrez la ressource de déploiement d'OpenTelemetry pour la modifier :
kubectl -n NAMESPACE_NAME edit deployment otel-collector
Ajoutez le texte affiché en gras à la ressource :
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...Enregistrez le fichier et fermez l'éditeur. Une fois la modification appliquée, les pods sont recréés et commencent à s'authentifier auprès du backend de métrique avec le compte de service donné.
Extraire les métriques Prometheus
Cette section et la suivante fournissent des informations de personnalisation supplémentaires sur l'utilisation du collecteur OpenTelemetry. Ces informations peuvent être utiles dans certaines situations, mais aucune n'est nécessaire pour exécuter l'exemple décrit dans la section Configurer le collecteur OpenTelemetry.
Si vos applications exposent déjà des points de terminaison Prometheus, le collecteur OpenTelemetry peut extraire ces points de terminaison à l'aide du même format de configuration de scraping que celui que vous utiliseriez avec n'importe quelle configuration Prometheus standard. Pour ce faire, activez le récepteur Prometheus dans votre configuration de collecteur.
Une configuration de récepteur Prometheus pour les pods Kubernetes peut se présenter comme suit :
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
Il s'agit d'une configuration de scraping basée sur la détection de services que vous pouvez modifier si nécessaire pour extraire vos applications.
Lorsque vous utilisez une configuration Prometheus existante avec le récepteur prometheus du collecteur OpenTelemetry, remplacez les caractères dollar simples, , par des caractères doubles, , pour éviter de déclencher une substitution de variables d'environnement. Cette étape est particulièrement importante pour la valeur replacement dans votre section relabel_configs. Par exemple, en présence de la section relabel_config suivante :
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
Réécrivez-la ensuite comme suit :
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
Pour en savoir plus, consultez la documentation OpenTelemetry.
Ensuite, nous vous recommandons vivement d'utiliser des processeurs pour mettre en forme vos métriques. En effet, dans de nombreux cas, les processeurs sont indispensables pour assurer la mise en forme correcte de vos métriques.
Ajouter des processeurs
Les processeurs OpenTelementry modifient les données de télémétrie avant leur exportation. Vous pouvez utiliser les processeurs suivants pour vous assurer que vos métriques sont écrites dans un format compatible avec Managed Service pour Prometheus.
Détecter les attributs de ressource
L'exportateur de Managed Service pour Prometheus dédié à OpenTelemetry utilise la ressource surveillée prometheus_target pour identifier de manière unique les points de données des séries temporelles. L'exportateur analyse les champs de ressource surveillée requis à partir des attributs de ressource sur les points de données de métriques.
Les champs et les attributs à partir desquels les valeurs sont extraites sont les suivants :
- project_id : détecté automatiquement par lesIdentifiants par défaut de l'application, ou bien correspond à
gcp.project.idouprojectdans la configuration de l'exportateur (voir la section Configurer l'exportateur) - emplacement :
location,cloud.availability_zone,cloud.region - cluster :
cluster,k8s.cluster_name - espace de noms :
namespace,k8s.namespace_name - job :
service.name+service.namespace - instance :
service.instance.id
Le fait de ne pas définir ces libellés sur des valeurs uniques peut entraîner des erreurs de "série temporelle en double" lors de l'exportation vers Managed Service pour Prometheus. Dans de nombreux cas, les valeurs de ces libellés peuvent être détectées automatiquement, mais dans certains cas, vous devrez peut-être les mapper vous-même. Le reste de cette section décrit ces scénarios.
Le récepteur Prometheus définit automatiquement l'attribut service.name en fonction de la valeur job_name définie dans la configuration de scraping, et l'attribut service.instance.id en fonction de la valeur instance de la cible de scraping. Le récepteur définit également l'attribut k8s.namespace.name lorsque role: pod est utilisé dans la configuration de scraping.
Si possible, renseignez automatiquement les autres attributs à l'aide du processeur de détection de ressources. Cependant, selon votre environnement, certains attributs peuvent ne pas être détectables automatiquement. Dans ce cas, vous pouvez utiliser d'autres processeurs pour insérer manuellement ces valeurs, ou bien les analyser à partir des libellés de métriques. Les sections suivantes illustrent les configurations permettant de détecter des ressources sur différentes plates-formes.
GKE
Lorsque vous exécutez OpenTelemetry sur GKE, vous devez activer le processeur de détection de ressources pour remplir les libellés de ressource. Assurez-vous que vos métriques ne contiennent pas déjà des libellés de ressource réservés. Si ces libellés doivent être présents, consultez la section Éviter les conflits d'attributs de ressource en renommant les attributs.
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
Cette section peut être copiée directement dans votre fichier de configuration, en remplaçant la section processors si elle existe déjà.
Amazon EKS
Le détecteur de ressources EKS ne renseigne pas automatiquement les attributs cluster ou namespace. Vous pouvez spécifier ces valeurs manuellement à l'aide du processeur de ressources, comme indiqué dans l'exemple suivant :
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Vous pouvez également convertir ces valeurs à partir des libellés de métriques, à l'aide du processeur groupbyattrs (consultez la section ci-après, Déplacer des libellés de métriques vers des libellés de ressources).
Azure AKS
Le détecteur de ressources AKS ne renseigne pas automatiquement les attributs cluster ou namespace. Vous pouvez spécifier ces valeurs manuellement à l'aide du processeur de ressources, comme indiqué dans l'exemple suivant :
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Vous pouvez également convertir ces valeurs à partir des libellés de métriques, à l'aide du processeur groupbyattrs. Consultez la section Déplacer des libellés de métriques vers des libellés de ressources.
Environnements sur site et non-cloud
Avec des environnements sur site ou non-cloud, vous ne pourrez probablement pas détecter automatiquement les attributs de ressource nécessaires. Dans ce cas, vous pouvez émettre les libellés correspondants dans vos métriques, puis les déplacer vers les attributs de ressource (consultez la section Déplacer des libellés de métriques vers des libellés de ressources), ou bien définir manuellement tous les attributs de ressource, comme décrit dans l'exemple suivant :
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
La section Créer votre configuration de collecteur en tant que ConfigMap décrit comment utiliser la configuration. Dans cette section, nous partons du principe que vous avez placé votre configuration dans un fichier nommé config.yaml.
L'attribut de ressource project_id peut toujours être défini automatiquement lorsque le collecteur est exécuté avec les Identifiants par défaut de l'application.
Si votre collecteur n'a pas accès aux Identifiants par défaut de l'application, consultez la section Définir project_id.
Vous pouvez également définir manuellement les attributs de ressource dont vous avez besoin dans une variable d'environnement, OTEL_RESOURCE_ATTRIBUTES, en spécifiant une liste de paires clé/valeur séparées par une virgule, par exemple :
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
Utilisez ensuite le processeur de détecteur de ressources env pour définir les attributs de ressource :
processors:
resourcedetection:
detectors: [env]
Éviter les conflits d'attributs de ressource en renommant les attributs
Si vos métriques contiennent déjà des libellés qui entrent en conflit avec les attributs de ressource requis (tels que location, cluster ou namespace), renommez-les pour éviter le conflit. La convention Prometheus consiste à ajouter le préfixe exported_ au nom du libellé. Pour ajouter ce préfixe, utilisez le processeur de transformation.
La configuration processors suivante renomme tous les conflits potentiels et résout les clés en conflit de la métrique :
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
Déplacer des libellés de métriques vers des libellés de ressources
Dans certains cas, vos métriques peuvent signaler intentionnellement des libellés tels que namespace, car votre exportateur surveille plusieurs espaces de noms. C'est le cas par exemple lors de l'exécution de l'exportateur kube-state-metrics.
Dans ce scénario, ces libellés peuvent être déplacés vers des attributs de ressource à l'aide du processeur groupbyattrs :
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
Dans l'exemple précédent, une métrique dotée des libellés namespace, cluster ou location est convertie vers les attributs de ressources correspondants.
Limiter les requêtes API et l'utilisation de la mémoire
Deux autres processeurs, le processeur de traitement par lot et le processeur de limitation de mémoire, vous permettent de limiter la consommation de ressources de votre collecteur.
Traitement par lot
Les requêtes de traitement par lot vous permettent de définir le nombre de points de données à envoyer en une seule requête. Notez que Cloud Monitoring applique une limite de 200 séries temporelles par requête. Activez le processeur de traitement par lot à l'aide des paramètres suivants :
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
Limitation de mémoire
Nous vous recommandons d'activer le processeur de limitation de mémoire pour éviter que votre collecteur ne plante en cas de débit élevé. Activez le traitement à l'aide des paramètres suivants :
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
Configurer l'exportateur googlemanagedprometheus
Par défaut, l'utilisation de l'exportateur googlemanagedprometheus sur GKE ne nécessite aucune configuration supplémentaire. Dans de nombreux cas d'utilisation, vous n'avez besoin de l'activer qu'avec un bloc vide dans la section exporters :
exporters: googlemanagedprometheus:
Toutefois, l'exportateur fournit d'autres paramètres de configuration facultatifs. Les sections suivantes décrivent ces autres paramètres de configuration.
Configurer project_id
Pour associer votre série temporelle à un projet Google Cloud , vous devez définir project_id pour la ressource surveillée prometheus_target.
Lors de l'exécution d'OpenTelemetry sur Google Cloud, l'exportateur de Managed Service pour Prometheus définit par défaut cette valeur en fonction des identifiants par défaut de l'application qu'il va détecter. Si aucun identifiant n'est disponible ou si vous souhaitez remplacer le projet par défaut, deux options s'offrent à vous :
- Définir
projectdans la configuration de l'exportateur - Ajouter un attribut de ressource
gcp.project.idà vos métriques
Nous vous recommandons vivement, lorsque cela est possible, d'utiliser la valeur par défaut pour project_id (c'est-à-dire de la laisser non définie) plutôt que de la définir explicitement.
Définir project dans la configuration de l'exportateur
L'extrait de configuration suivant envoie des métriques à Managed Service pour Prometheus dans le projet Google Cloud MY_PROJECT :
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
La seule différence par rapport aux exemples précédents est la nouvelle ligne project: MY_PROJECT.
Ce paramètre est utile si vous savez que chaque métrique provenant de ce collecteur doit être envoyée à MY_PROJECT.
Définir l'attribut de ressource gcp.project.id
Vous pouvez définir l'association à un projet à l'échelle d'une métrique, en ajoutant un attribut de ressource gcp.project.id à vos métriques. Définissez la valeur de l'attribut sur le nom du projet auquel la métrique doit être associée.
Par exemple, si votre métrique comporte déjà le libellé project, ce libellé peut être déplacé vers un attribut de ressource et renommé en gcp.project.id, à l'aide de processeurs dans la configuration du collecteur, comme illustré ci-dessous :
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
Définir les options relatives au client
L'exportateur googlemanagedprometheus utilise des clients gRPC pour Managed Service pour Prometheus. Par conséquent, des paramètres facultatifs sont disponibles pour configurer le client gRPC :
compression: active la compression gzip pour les requêtes gRPC, ce qui est utile pour réduire les frais de transfert de données lors de l'envoi de données depuis d'autres clouds vers Managed Service pour Prometheus (valeurs valides :gzip).user_agent: remplace la chaîne user-agent envoyée sur les requêtes transmises à Cloud Monitoring ; ce paramètre ne s'applique qu'aux métriques. Il s'agit par défaut du numéro de build et de version de votre collecteur OpenTelemetry, par exempleopentelemetry-collector-contrib 0.128.0.endpoint: définit le point de terminaison vers lequel les données de métriques seront envoyées.use_insecure: si ce paramètre est défini sur "true", gRPC sera utilisé comme transport de communication. Ce paramètre ne produit d'effet que lorsque la valeurendpointest différente de "".grpc_pool_size: définit la taille du pool de connexions dans le client gRPC.prefix: configure le préfixe des métriques envoyées à Managed Service pour Prometheus. La valeur par défaut estprometheus.googleapis.com. Ne modifiez pas ce préfixe, sous peine de rendre impossible l'interrogation des métriques via PromQL, dans l'interface utilisateur de Cloud Monitoring.
Dans la plupart des cas, il n'est pas nécessaire de modifier les valeurs par défaut de ces paramètres. Vous pourrez toutefois être amené à les modifier dans certaines circonstances particulières.
Tous ces paramètres sont définis dans un bloc metric dans la section googlemanagedprometheus de l'exportateur, comme illustré dans l'exemple suivant :
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
Étapes suivantes
- Utilisez PromQL dans Cloud Monitoring pour interroger les métriques Prometheus.
- Utilisez Grafana pour interroger les métriques Prometheus.
- Configurez le collecteur OpenTelemetry en tant qu'agent side-car dans Cloud Run.
-
La page Gestion des métriques de Cloud Monitoring fournit des informations qui peuvent vous aider à contrôler les sommes que vous consacrez aux métriques facturables, sans affecter l'observabilité. La page Gestion des métriques fournit les informations suivantes :
- Les volumes d'ingestion pour la facturation à base d'octets et celle à base d'exemples, englobant les différents domaines de métriques et des métriques individuelles
- Les données sur les libellés et la cardinalité des métriques
- Nombre de lectures pour chaque métrique.
- L'utilisation de métriques dans les règles d'alerte et les tableaux de bord personnalisés
- Les taux d'erreurs d'écriture de métriques
Vous pouvez également utiliser la page Gestion des métriques pour exclure les métriques inutiles, ce qui élimine le coût de leur ingestion. Pour en savoir plus sur la Gestion des métriques, consultez la section Afficher et gérer l'utilisation des métriques.