本文說明如何設定 OpenTelemetry Collector,以擷取標準 Prometheus 指標,並將這些指標回報給 Google Cloud Managed Service for Prometheus。OpenTelemetry Collector 是一種代理程式,您可以自行部署並設定,將資料匯出至 Managed Service for Prometheus。設定方式與使用自行部署的收集作業執行 Managed Service for Prometheus 類似。
您可能會基於下列原因,選擇 OpenTelemetry Collector 而非自行部署的收集器:
- 您可以在管道中設定不同的匯出工具,藉此透過 OpenTelemetry Collector 將遙測資料傳送至多個後端。
- 收集器也支援指標、記錄和追蹤記錄的信號,因此您可以使用單一代理程式處理這三種信號類型。
- OpenTelemetry 的廠商中立資料格式 (OpenTelemetry Protocol,簡稱 OTLP) 支援強大的程式庫生態系統和可外掛的 Collector 元件。因此您可以選擇多種自訂選項,接收、處理及匯出資料。
不過,執行 OpenTelemetry Collector 時,您必須自行部署及維護,這是享受上述優點的代價。您選擇的方法取決於具體需求,但本文會提供建議的指引,說明如何使用 Managed Service for Prometheus 做為後端,設定 OpenTelemetry Collector。
事前準備
本節說明執行本文所述工作所需的設定。
設定專案和工具
如要使用 Google Cloud Managed Service for Prometheus,您需要下列資源:
已啟用 Cloud Monitoring API 的 Google Cloud 專案。
如果您沒有 Google Cloud 專案,請執行下列步驟:
前往 Google Cloud 控制台的「New Project」(新增專案):
在「Project Name」(專案名稱) 欄位中輸入專案名稱,然後按一下「Create」(建立)。
前往「帳單」:
如果尚未在頁面頂端選取您剛建立的專案,請立即選取。
系統會提示您選擇現有的付款資料或是建立新的付款資料。
新專案預設會啟用 Monitoring API。
如果您已有 Google Cloud 專案,請確認已啟用 Monitoring API:
前往「API 和服務」:
選取專案。
點選「啟用 API 和服務」。
搜尋「監控」。
在搜尋結果中,按一下「Cloud Monitoring API」。
如果畫面未顯示「API enabled」(API 已啟用),請按一下「Enable」(啟用) 按鈕。
Kubernetes 叢集。如果您沒有 Kubernetes 叢集,請按照 GKE 快速入門導覽課程中的操作說明進行。
您還需要下列指令列工具:
gcloudkubectl
gcloud 和 kubectl 工具是 Google Cloud CLI 的一部分。如要瞭解如何安裝這些元件,請參閱「管理 Google Cloud CLI 元件」。如要查看已安裝的 gcloud CLI 元件,請執行下列指令:
gcloud components list
設定環境
為避免重複輸入專案 ID 或叢集名稱,請執行下列設定:
請依下列方式設定指令列工具:
設定 gcloud CLI,以參照Google Cloud 專案的 ID:
gcloud config set project PROJECT_ID
將
kubectlCLI 設為使用叢集:kubectl config set-cluster CLUSTER_NAME
如要進一步瞭解這些工具,請參閱下列說明:
設定命名空間
為您建立的資源建立 NAMESPACE_NAME Kubernetes 命名空間,做為範例應用程式的一部分:
kubectl create ns NAMESPACE_NAME
驗證服務帳戶憑證
如果 Kubernetes 叢集已啟用 Workload Identity Federation for GKE,則可以略過本節。
在 GKE 上執行時,Managed Service for Prometheus 會根據 Compute Engine 預設服務帳戶,自動從環境中擷取憑證。根據預設,預設服務帳戶具備必要權限 monitoring.metricWriter 和 monitoring.viewer。如果您未使用 GKE 的 Workload Identity Federation,且先前已從預設節點服務帳戶移除任一角色,請先重新新增缺少的權限,再繼續操作。
設定 Workload Identity Federation for GKE 的服務帳戶
如果 Kubernetes 叢集未啟用 GKE 適用的工作負載身分聯盟,則可跳過本節。
Managed Service for Prometheus 會使用 Cloud Monitoring API 擷取指標資料。如果叢集使用 GKE 適用的工作負載身分聯盟,您必須授予 Kubernetes 服務帳戶 Monitoring API 的權限。本節說明下列事項:
- 建立專屬Google Cloud 服務帳戶。
gmp-test-sa. - 將 Google Cloud 服務帳戶繫結至測試命名空間中的預設 Kubernetes 服務帳戶,
NAMESPACE_NAME。 - 將必要權限授予 Google Cloud 服務帳戶。
建立及繫結服務帳戶
這個步驟會出現在 Managed Service for Prometheus 說明文件的多個位置。如果您已在先前的作業中執行這個步驟,則無須重複執行。直接跳到「授權服務帳戶」。
下列指令序列會建立 gmp-test-sa 服務帳戶,並將其繫結至 NAMESPACE_NAME 命名空間中的預設 Kubernetes 服務帳戶:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
如果您使用其他 GKE 命名空間或服務帳戶,請適當調整指令。
授權給服務帳戶
相關權限會歸類為角色,您可將角色授予主體,在本例中即為 Google Cloud服務帳戶。如要進一步瞭解 Monitoring 角色,請參閱存取權控管。
下列指令會授予 Google Cloud 服務帳戶 (gmp-test-sa) 寫入指標資料所需的 Monitoring API 角色。
如果您已在先前的作業中授予 Google Cloud 服務帳戶特定角色,則不必再次執行這項操作。
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
對 GKE 適用的 Workload Identity 聯盟設定進行偵錯
如果無法順利使用 Workload Identity Federation for GKE,請參閱驗證 Workload Identity Federation for GKE 設定的說明文件,以及 Workload Identity Federation for GKE 疑難排解指南。
設定 Workload Identity Federation for GKE 時,最常見的錯誤來源是錯別字和部分複製貼上,因此我們強烈建議使用這些操作說明中程式碼範例內建的可編輯變數和可點選的複製貼上圖示。
實際工作環境中的 GKE 工作負載身分聯盟
本文所述範例會將 Google Cloud 服務帳戶繫結至預設 Kubernetes 服務帳戶,並授予 Google Cloud服務帳戶使用 Monitoring API 的所有必要權限。
在正式環境中,您可能想採用更精細的方法,為每個元件建立服務帳戶,並授予最基本的權限。如要進一步瞭解如何設定服務帳戶來管理工作負載身分,請參閱「使用 Workload Identity Federation for GKE」。
設定 OpenTelemetry 收集器
本節將逐步說明如何設定及使用 OpenTelemetry Collector,從範例應用程式擷取指標,並將資料傳送至 Google Cloud Managed Service for Prometheus。如需詳細設定資訊,請參閱下列章節:
OpenTelemetry Collector 類似於 Managed Service for Prometheus 代理程式二進位檔。OpenTelemetry 社群會定期發布版本,包括原始碼、二進位檔和容器映像檔。
您可以透過最佳做法預設值,在 VM 或 Kubernetes 叢集上部署這些構件,也可以使用收集器建構工具,只建構包含所需元件的收集器。如要建構收集器,以便搭配 Managed Service for Prometheus 使用,您需要下列元件:
- Managed Service for Prometheus 匯出工具,可將指標寫入 Managed Service for Prometheus。
- 用於擷取指標的接收器。本文假設您使用 OpenTelemetry Prometheus 接收器,但 Managed Service for Prometheus 匯出工具與任何 OpenTelemetry 指標接收器都相容。
- 處理器會批次處理及標記指標,以便根據您的環境加入重要資源 ID。
如要啟用這些元件,請使用設定檔,並透過 --config 標記傳遞至 Collector。
以下各節將詳細說明如何設定這些元件。本文說明如何在 GKE 上和其他位置執行收集器。
設定及部署收集器
無論您是在 Google Cloud 還是其他環境中執行收集作業,都可以設定 OpenTelemetry Collector,將資料匯出至 Managed Service for Prometheus。最大的差異在於設定收集器的方式。在非Google Cloud 環境中,可能需要額外格式化指標資料,才能與 Managed Service for Prometheus 相容。不過,在 Google Cloud上,收集器可以自動偵測大部分的格式。
在 GKE 上執行 OpenTelemetry 收集器
您可以將下列設定複製到名為 config.yaml 的檔案中,在 GKE 上設定 OpenTelemetry Collector:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
上述設定會使用 Prometheus 接收器和 Managed Service for Prometheus 匯出工具,抓取 Kubernetes Pod 的指標端點,並將這些指標匯出至 Managed Service for Prometheus。管道處理器會格式化資料並進行批次處理。
如要進一步瞭解這項設定的各個部分,以及不同平台的設定,請參閱以下有關擷取指標和新增處理器的詳細章節。
使用現有的 Prometheus 設定搭配 OpenTelemetry Collector 的 prometheus 接收器時,請將所有單一錢幣符號字元 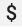 替換為雙字元
替換為雙字元 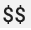 ,以免觸發環境變數替代。詳情請參閱擷取 Prometheus 指標。
,以免觸發環境變數替代。詳情請參閱擷取 Prometheus 指標。
您可以根據環境、供應商和要擷取的指標修改這項設定,但建議您以範例設定為起點,在 GKE 上執行。
在外部執行 OpenTelemetry Collector Google Cloud
在外部 (例如內部部署或在其他雲端服務供應商上) 執行 OpenTelemetry Collector,與在 GKE 上執行 Collector 類似。 Google Cloud不過,您擷取的指標不太可能自動納入最適合 Managed Service for Prometheus 的資料格式。因此,您必須格外小心地設定收集器,確保指標格式與 Managed Service for Prometheus 相容。
您可以將下列設定複製到名為 config.yaml 的檔案中,為部署在非 GKE Kubernetes 叢集上的 OpenTelemetry Collector 進行設定:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
這項設定會執行下列操作:
- 為 Prometheus 設定 Kubernetes 服務探索抓取設定。詳情請參閱擷取 Prometheus 指標。
- 手動設定
cluster、namespace和location資源屬性。如要進一步瞭解資源屬性,包括 Amazon EKS 和 Azure AKS 的資源偵測,請參閱「偵測資源屬性」。 - 在
googlemanagedprometheus匯出工具中設定project選項。 如要進一步瞭解匯出工具,請參閱「設定googlemanagedprometheus匯出工具」。
使用現有的 Prometheus 設定搭配 OpenTelemetry Collector 的 prometheus 接收器時,請將所有單一錢幣符號字元 替換為雙字元 ,以免觸發環境變數替代。詳情請參閱擷取 Prometheus 指標。
如要瞭解在其他雲端服務上設定 Collector 的最佳做法,請參閱 Amazon EKS 或 Azure AKS。
部署範例應用程式
範例應用程式會在 metrics 連接埠上發出 example_requests_total 計數器指標和 example_random_numbers 直方圖指標 (以及其他指標)。這個範例的資訊清單定義了三個備用資源。
如要部署範例應用程式,請執行下列指令:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
以 ConfigMap 形式建立收集器設定
建立設定並將其放在名為 config.yaml 的檔案中後,請使用該檔案,根據 config.yaml 檔案建立 Kubernetes ConfigMap。部署收集器時,系統會掛接 ConfigMap 並載入檔案。
如要使用設定建立名為 otel-config 的 ConfigMap,請使用下列指令:
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
部署收集器
建立名為 collector-deployment.yaml 的檔案,並在其中加入下列內容:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
在 Kubernetes 叢集中建立 Collector 部署作業,請執行下列指令:
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
Pod 啟動後,會抓取範例應用程式,並將指標回報給 Managed Service for Prometheus。
如要瞭解如何查詢資料,請參閱「使用 Cloud Monitoring 查詢」或「使用 Grafana 查詢」。
明確提供憑證
在 GKE 上執行時,OpenTelemetry Collector 會根據節點的服務帳戶,自動從環境中擷取憑證。在非 GKE 的 Kubernetes 叢集中,必須使用旗標或 GOOGLE_APPLICATION_CREDENTIALS 環境變數,明確向 OpenTelemetry Collector 提供憑證。
將環境設為目標專案:
gcloud config set project PROJECT_ID
建立服務帳戶:
gcloud iam service-accounts create gmp-test-sa
這個步驟會建立服務帳戶,您可能已在「適用於 GKE 的工作負載身分聯盟」說明中建立該帳戶。
將必要權限授予服務帳戶:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
建立並下載服務帳戶的金鑰:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
將金鑰檔案新增為非 GKE 叢集的密鑰:
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
開啟 OpenTelemetry Deployment 資源進行編輯:
kubectl -n NAMESPACE_NAME edit deployment otel-collector
將以粗體顯示的文字新增至資源:
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...儲存檔案並關閉編輯器。套用變更後,系統會重新建立 Pod,並開始使用指定的服務帳戶向指標後端進行驗證。
抓取 Prometheus 指標
本節和後續章節提供使用 OpenTelemetry Collector 的其他自訂資訊。在某些情況下,這些資訊可能很有幫助,但執行「設定 OpenTelemetry 收集器」一文所述範例時,不需要任何資訊。
如果應用程式已公開 Prometheus 端點,OpenTelemetry Collector 可以使用與任何標準 Prometheus 設定相同的擷取設定格式,擷取這些端點。如要這麼做,請在收集器設定中啟用 Prometheus 接收器。
Kubernetes Pod 的 Prometheus 接收器設定可能如下所示:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
這是以服務探索為基礎的擷取設定,您可以視需要修改,以擷取應用程式。
使用現有的 Prometheus 設定搭配 OpenTelemetry Collector 的 prometheus 接收器時,請將所有單一錢幣符號字元 替換為雙字元 ,以免觸發環境變數替代。請務必為「replacement」relabel_configs 部分中的值執行這項操作。舉例來說,如果您有下列 relabel_config 區段:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
然後改寫成:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
詳情請參閱 OpenTelemetry 說明文件。
接著,我們強烈建議您使用處理器來格式化指標。在許多情況下,必須使用處理器才能正確格式化指標。
新增處理器
OpenTelemetry 處理器會在遙測資料匯出前修改資料。您可以使用下列處理器,確保指標是以與 Managed Service for Prometheus 相容的格式寫入。
偵測資源屬性
OpenTelemetry 適用的 Managed Service for Prometheus 匯出工具會使用prometheus_target受監控的資源,匯出工具會從指標資料點的資源屬性中,剖析必要的受監控資源欄位。系統會從下列欄位和屬性擷取值:
- project_id:由應用程式預設憑證、
gcp.project.id或匯出工具設定中的project自動偵測 (請參閱設定匯出工具) - 位置:
location、cloud.availability_zone、cloud.region - 叢集:
cluster、k8s.cluster_name - 命名空間:
namespace、k8s.namespace_name - job:
service.name+service.namespace - instance:
service.instance.id
如果未將這些標籤設為不重複的值,匯出至 Managed Service for Prometheus 時可能會發生「duplicate timeseries」(重複時間序列) 錯誤。在許多情況下,系統會自動偵測這些標籤的值,但有時您可能必須自行對應。本節的其餘部分將說明這些情境。
Prometheus 接收器會根據擷取設定中的 job_name 自動設定 service.name 屬性,並根據擷取目標的 instance 設定 service.instance.id 屬性。接收器也會在擷取設定中使用 role: pod 時,設定 k8s.namespace.name。
盡可能使用資源偵測處理器,自動填入其他屬性。不過,視環境而定,系統可能無法自動偵測某些屬性。在這種情況下,您可以使用其他處理器手動插入這些值,或從指標標籤剖析這些值。以下各節說明如何在不同平台上偵測資源。
GKE
在 GKE 上執行 OpenTelemetry 時,您需要啟用資源偵測處理器,才能填寫資源標籤。請確認指標尚未包含任何預留資源標籤。如果無法避免,請參閱「避免資源屬性衝突 (重新命名屬性)」。
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
您可以直接將這個區段複製到設定檔中,並取代現有的 processors 區段。
Amazon EKS
EKS 資源偵測器不會自動填入 cluster 或 namespace 屬性。您可以手動提供這些值,方法是使用資源處理器,如下列範例所示:
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
您也可以使用groupbyattrs處理器從指標標籤轉換這些值 (請參閱下方的「將指標標籤移至資源標籤」)。
Azure AKS
AKS 資源偵測器不會自動填入 cluster 或 namespace 屬性。您可以使用資源處理器手動提供這些值,如下列範例所示:
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
您也可以使用 groupbyattrs
處理器,將這些值從指標標籤轉換為資源標籤;詳情請參閱「將指標標籤移至資源標籤」。
內部部署和非雲端環境
如果是地端或非雲端環境,您可能無法自動偵測任何必要的資源屬性。在這種情況下,您可以在指標中發出這些標籤,並將其移至資源屬性 (請參閱「將指標標籤移至資源標籤」),或手動設定所有資源屬性,如下列範例所示:
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
將收集器設定建立為 ConfigMap 一文說明如何使用設定。該節假設您已將設定放在名為 config.yaml 的檔案中。
使用應用程式預設憑證執行 Collector 時,project_id 資源屬性仍可自動設定。如果 Collector 無法存取應用程式預設憑證,請參閱「設定 project_id」。
或者,您也可以在環境變數 OTEL_RESOURCE_ATTRIBUTES 中手動設定所需的資源屬性,並以半形逗號分隔鍵值組,例如:
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
然後使用env資源偵測器處理器設定資源屬性:
processors:
resourcedetection:
detectors: [env]
重新命名屬性,避免資源屬性發生衝突
如果指標已包含與必要資源屬性 (例如 location、cluster 或 namespace) 衝突的標籤,請重新命名這些標籤,以免發生衝突。Prometheus 慣例是在標籤名稱中加入 exported_ 前置字串。如要新增這個前置字串,請使用 transform 處理器。
下列 processors 設定會重新命名任何可能發生衝突的項目,並解決指標中任何衝突的鍵:
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
將指標標籤移至資源標籤
在某些情況下,由於匯出工具監控多個命名空間,指標可能會刻意回報 namespace 等標籤。舉例來說,執行 kube-state-metrics 匯出工具時。
在此情境中,可以使用 groupbyattrs 處理器,將這些標籤移至資源屬性:
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
以前例來說,如果指標含有 namespace、cluster 或 location 標籤,這些標籤就會轉換為相應的資源屬性。
限制 API 要求和記憶體用量
另外兩個處理器 (批次處理器和記憶體限制處理器) 可讓您限制收集器的資源消耗量。
批次處理
批次處理要求可讓您定義單一要求中要傳送的資料點數量。請注意,Cloud Monitoring 限制為每個要求 200 個時間序列。使用下列設定啟用批次處理器:
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
記憶體限制
建議您啟用記憶體限制處理器,以免收集器在高輸送量時當機。使用下列設定啟用處理程序:
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
設定 googlemanagedprometheus 匯出工具
在 GKE 上使用 googlemanagedprometheus 匯出工具時,預設不需要額外設定。在許多用途中,您只需要在 exporters 區段中啟用空白區塊即可:
exporters: googlemanagedprometheus:
不過,匯出工具確實提供一些選用設定。下列各節說明其他設定。
設定 project_id
如要將時間序列與 Google Cloud 專案建立關聯,受監控的prometheus_target資源必須設有 project_id。
在 Google Cloud上執行 OpenTelemetry 時,Managed Service for Prometheus 匯出工具會根據找到的應用程式預設憑證,預設設定這個值。如果沒有可用憑證,或想覆寫預設專案,有兩種做法:
- 在匯出工具設定中設定
project - 在指標中新增
gcp.project.id資源屬性。
強烈建議您盡可能使用 project_id 的預設 (未設定) 值,而非明確設定。
在匯出工具設定中設定 project
下列設定摘錄會將指標傳送至 Google Cloud 專案 MY_PROJECT中的 Managed Service for Prometheus:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
與先前範例的唯一差異是新行 project: MY_PROJECT。如果您知道透過這個 Collector 傳送的每個指標都應傳送至 MY_PROJECT,這項設定就很有用。
設定 gcp.project.id 資源屬性
您可以為指標新增 gcp.project.id 資源屬性,逐一設定指標的專案關聯。將屬性的值設為指標應與之建立關聯的專案名稱。
舉例來說,如果指標已有 project 標籤,可以使用 Collector 設定中的處理器,將這個標籤移至資源屬性,並重新命名為 gcp.project.id,如下例所示:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
設定用戶端選項
googlemanagedprometheus 匯出工具會使用 gRPC 用戶端,因此,您可以透過選用設定來設定 gRPC 用戶端:
compression:為 gRPC 要求啟用 gzip 壓縮功能,從其他雲端將資料傳送至 Managed Service for Prometheus 時,這項功能有助於盡量減少資料傳輸費用 (有效值:gzip)。user_agent:覆寫傳送至 Cloud Monitoring 的要求中的使用者代理程式字串;僅適用於指標。預設為 OpenTelemetry Collector 的建構版本和版本號碼,例如opentelemetry-collector-contrib 0.128.0。endpoint:設定要將指標資料傳送至哪個端點。use_insecure:如為 true,則使用 gRPC 做為通訊傳輸方式。只有在endpoint值不是「」時,才會生效。grpc_pool_size:在 gRPC 用戶端中設定連線集區的大小。prefix:設定傳送至 Managed Service for Prometheus 的指標前置字元。預設值為prometheus.googleapis.com。請勿變更這個前置字元,否則您將無法在 Cloud Monitoring 使用者介面中,透過 PromQL 查詢指標。
在大多數情況下,您不需要變更這些預設值。不過,您可以視特殊情況變更這些設定。
所有這些設定都會在 googlemanagedprometheus 匯出器區段的 metric 區塊下設定,如下列範例所示:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
後續步驟
- 在 Cloud Monitoring 中使用 PromQL 查詢 Prometheus 指標。
- 使用 Grafana 查詢 Prometheus 指標。
- 在 Cloud Run 中,將 OpenTelemetry Collector 設定為補充代理程式。
-
Cloud Monitoring 的「指標管理」頁面提供相關資訊,可協助您控管可計費指標的支出金額,同時不影響可觀測性。「指標管理」頁面會回報下列資訊:
- 以位元組和樣本為準的帳單,以及指標網域和個別指標的擷取量。
- 指標的標籤和基數相關資料。
- 每個指標的讀取次數。
- 在警告政策和自訂資訊主頁中使用指標。
- 指標寫入錯誤率。
您也可以使用「指標管理」頁面排除不必要的指標,藉此省下擷取這些指標的費用。如要進一步瞭解「指標管理」頁面,請參閱「查看及管理指標用量」。