Este documento descreve uma configuração de avaliação de regras e alertas em uma implantação do Managed Service para Prometheus que usa coleta autoimplantada.
O diagrama a seguir ilustra uma implantação que usa vários clusters em dois projetos Google Cloud e utiliza a avaliação de regras e alertas:
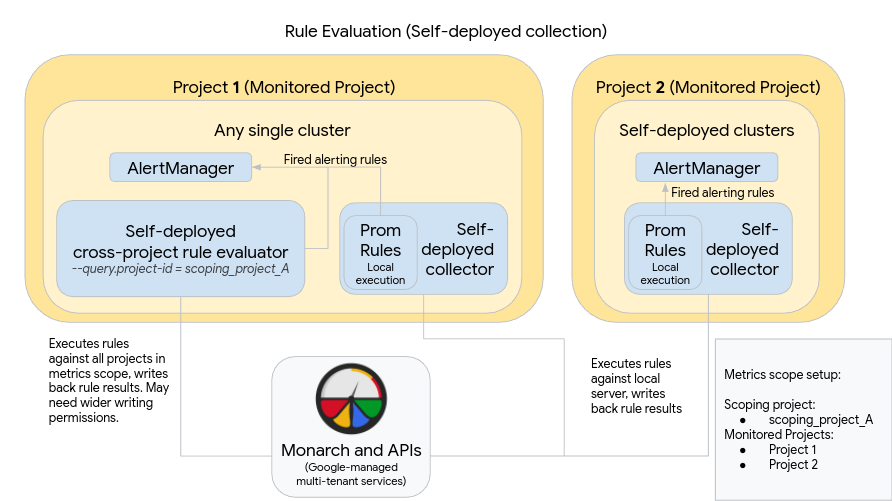
Para configurar e usar uma implantação como a do diagrama, lembre-se de que:
As regras são instaladas em cada servidor de coleta do Managed Service para Prometheus, assim como no Prometheus padrão. A avaliação das regras é executada com base nos dados armazenados localmente em cada servidor. Os servidores são configurados para reter dados por tempo suficiente para abranger o período de lookback de todas as regras, o que geralmente não é mais de uma hora. Os resultados da regra são gravados no Monarch após a avaliação.
Uma instância AlertManager do Prometheus é implantada manualmente em cada cluster. Os servidores do Prometheus são configurados com a edição do campo
alertmanager_configdo arquivo de configuração para enviar regras de alerta disparadas para a instância local AlertManager. Silenciamentos, confirmações e fluxos de trabalho de gerenciamento de incidentes em geral são processados em uma ferramenta de terceiros, como o PagerDuty.É possível centralizar o gerenciamento de alertas em vários clusters em um único AlertManager com um recurso do Endpoints do Kubernetes.
Um único cluster em execução no Google Cloud é designado como o cluster de avaliação de regra global para um escopo de métricas. O avaliador de regras independente é implantado nesse cluster, e as regras são instaladas no formato de arquivo de regra padrão do Prometheus.
O avaliador de regras independente é configurado para usar scoping_project_A, que contém os projetos 1 e 2. As regras executadas em scoping_project_A distribuem dados automaticamente para os projetos 1 e 2. A conta de serviço subjacente precisa receber as permissões de Leitor do Monitoring para scoping_project_A.
O avaliador de regras está configurado para enviar alertas ao Alertmanager do Prometheus local usando o campo
alertmanager_configdo arquivo de configuração.
O uso de um avaliador de regras global autoimplantado pode ter efeitos inesperados,
dependendo se você preserva ou agrega os identificadores project_id,
location, cluster e namespace nas regras:
Se as regras preservarem o identificador
project_id(usando uma cláusulaby(project_id)), os resultados da regra serão gravados no Monarch com o valorproject_idoriginal da série temporal subjacente.Nesse cenário, você precisa garantir que a conta de serviço subjacente tenha as permissões de Gravador de métricas do Monitoring para cada projeto monitorado em scoping_project_A. Se você adicionar um novo projeto monitorado a scoping_project_A, também precisará adicionar manualmente uma nova permissão à conta de serviço.
Se as regras não preservarem o identificador
project_id(sem o uso de uma cláusulaby(project_id)), os resultados da regra serão gravados no Monarch usando o valorproject_iddo cluster em que o avaliador de regra global está em execução.Nesse cenário, não é preciso modificar a conta de serviço.
Se as regras preservarem o identificador
locationcom uma cláusulaby(location), os resultados da regra serão gravados no Monarch usando cada região original Google Cloud de onde a série temporal subjacente se originou.Se as regras não preservarem o identificador
location, os dados serão gravados no local do cluster em que o avaliador de regras global está em execução.
É altamente recomendável preservar os identificadores cluster e namespace nos resultados de avaliação de regras sempre que possível. Caso contrário, o desempenho da consulta
poderá diminuir e você poderá encontrar limites de cardinalidade. Não é indicado remover os dois identificadores.