Dokumen ini menjelaskan konfigurasi untuk evaluasi aturan dan pemberitahuan dalam deployment Managed Service for Prometheus yang menggunakan koleksi yang di-deploy sendiri.
Diagram berikut mengilustrasikan deployment yang menggunakan beberapa cluster dalam dua Google Cloud project dan menggunakan evaluasi aturan dan pemberitahuan:
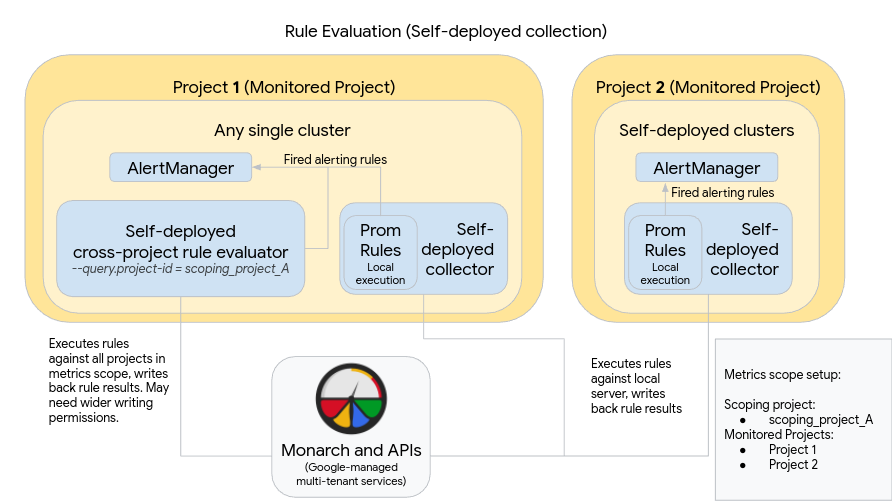
Untuk menyiapkan dan menggunakan deployment seperti yang ada dalam diagram, perhatikan hal berikut:
Aturan diinstal dalam setiap server koleksi Managed Service for Prometheus, seperti saat menggunakan Prometheus standar. Evaluasi aturan dijalankan terhadap data yang disimpan secara lokal di setiap server. Server dikonfigurasi untuk menyimpan data cukup lama untuk mencakup periode lihat balik semua aturan, yang biasanya tidak lebih dari 1 jam. Hasil aturan ditulis ke Monarch setelah evaluasi.
Instance Prometheus AlertManager di-deploy secara manual di setiap cluster. Server Prometheus dikonfigurasi dengan mengedit kolom
alertmanager_configdari file konfigurasi untuk mengirim aturan pemberitahuan yang diaktifkan ke instance AlertManager lokal. Diam, respons, dan alur kerja pengelolaan insiden biasanya ditangani di alat pihak ketiga seperti PagerDuty.Anda dapat memusatkan pengelolaan pemberitahuan di beberapa cluster ke dalam satu AlertManager menggunakan resource Endpoint Kubernetes.
Satu cluster yang berjalan di dalam Google Cloud ditetapkan sebagai cluster evaluasi aturan global untuk cakupan metrik. Evaluator aturan mandiri di-deploy di cluster tersebut dan aturan diinstal menggunakan format file aturan Prometheus standar.
Evaluator aturan mandiri dikonfigurasi untuk menggunakan scoping_project_A, yang berisi Project 1 dan 2. Aturan yang dieksekusi terhadap scoping_project_A otomatis diperluas ke Project 1 dan 2. Akun layanan pokok harus diberi izin Monitoring Viewer untuk scoping_project_A.
Evaluator aturan dikonfigurasi untuk mengirim pemberitahuan ke Prometheus Alertmanager lokal menggunakan kolom
alertmanager_configdari file konfigurasi.
Menggunakan evaluator aturan global yang di-deploy sendiri dapat memiliki efek yang tidak terduga, bergantung pada apakah Anda mempertahankan atau menggabungkan label project_id, location, cluster, dan namespace dalam aturan:
Jika aturan Anda mempertahankan label
project_id(dengan menggunakan klausaby(project_id)), hasil aturan akan ditulis kembali ke Monarch menggunakan nilaiproject_idasli dari deret waktu yang mendasarinya.Dalam skenario ini, Anda harus memastikan akun layanan yang mendasarinya memiliki izin Monitoring Metric Writer untuk setiap project yang dipantau di scoping_project_A. Jika menambahkan project baru yang dipantau ke scoping_project_A, Anda juga harus menambahkan izin baru ke akun layanan secara manual.
Jika aturan Anda tidak mempertahankan label
project_id(dengan tidak menggunakan klausaby(project_id)), hasil aturan akan ditulis kembali ke Monarch menggunakan nilaiproject_idcluster tempat evaluator aturan global berjalan.Dalam skenario ini, Anda tidak perlu mengubah akun layanan yang mendasarinya lebih lanjut.
Jika aturan Anda mempertahankan label
location(dengan menggunakan klausaby(location)), hasil aturan akan ditulis kembali ke Monarch menggunakan setiap region Google Cloud asli tempat deret waktu yang mendasarinya berasal.Jika aturan Anda tidak mempertahankan label
location, data akan ditulis kembali ke lokasi cluster tempat evaluator aturan global berjalan.
Sebaiknya pertahankan label cluster dan namespace
dalam hasil evaluasi aturan jika memungkinkan. Jika tidak, performa kueri
mungkin menurun dan Anda mungkin mengalami batas kardinalitas. Sebaiknya jangan menghapus kedua label tersebut.