En este documento se describe cómo configurar un entorno que combine colectores autodesplegados con colectores gestionados en diferentesGoogle Cloud proyectos y clústeres.
Te recomendamos que uses la recogida gestionada en todos los entornos de Kubernetes, ya que así se elimina prácticamente la sobrecarga de ejecutar colectores de Prometheus en tu clúster. Puedes ejecutar recopiladores gestionados y con despliegue automático en el mismo clúster. Te recomendamos que uses un enfoque coherente para la monitorización, pero puedes combinar métodos de implementación en algunos casos de uso específicos, como alojar una pasarela push, tal como se ilustra en este documento.
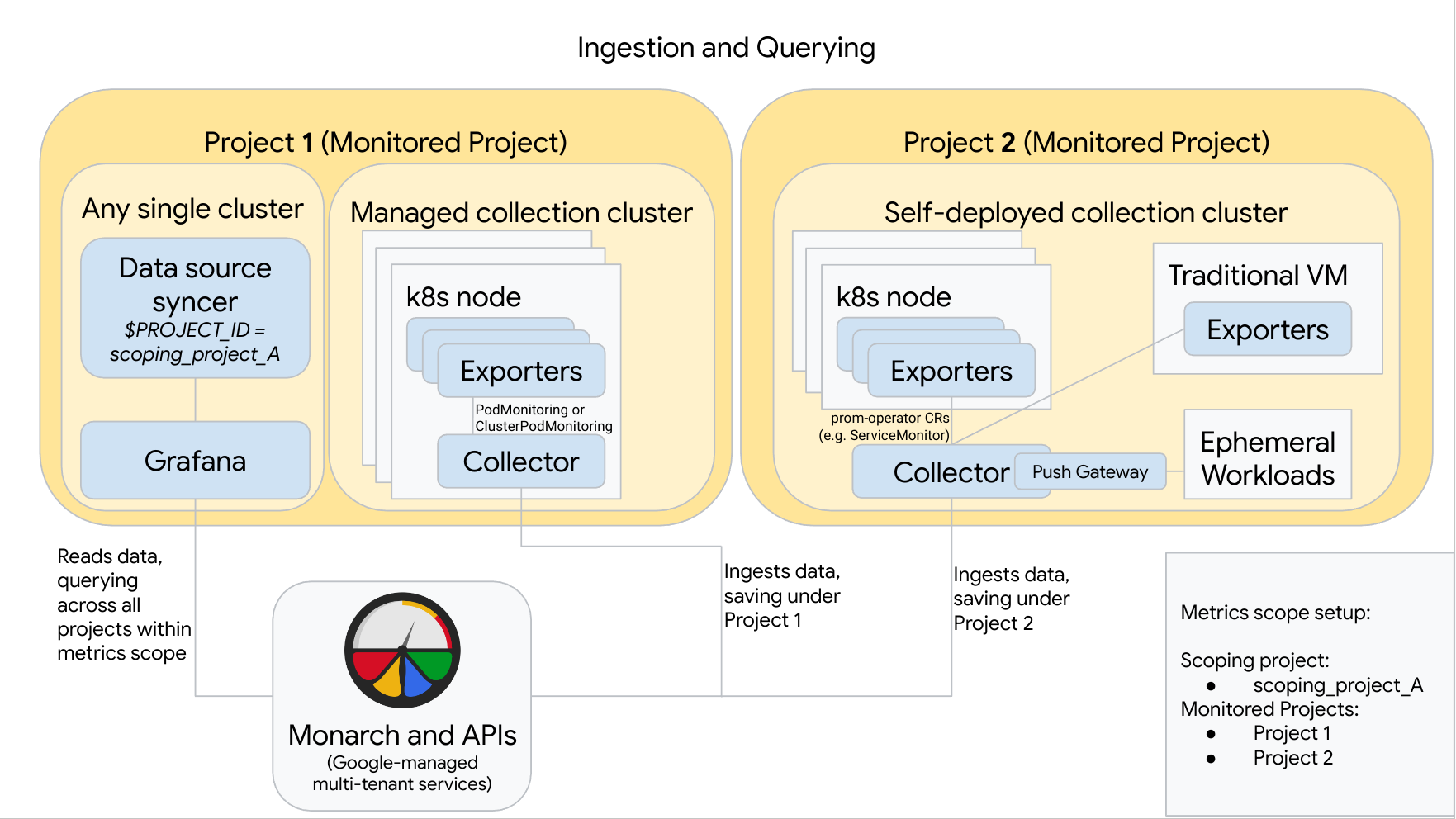
En el siguiente diagrama se muestra una configuración que usa dos proyectos deGoogle Cloud , tres clústeres y una combinación de recogida gestionada y autodesplegada. Si solo usa la recogida gestionada o autodesplegada, el diagrama sigue siendo válido. Solo tiene que ignorar el estilo de recogida que no utilice:
Para configurar y usar una configuración como la del diagrama, ten en cuenta lo siguiente:
Debe instalar los exportadores necesarios en sus clústeres. Google Cloud Managed Service para Prometheus no instala ningún exportador en tu nombre.
El proyecto 1 tiene un clúster que ejecuta una colección gestionada, que se ejecuta como un agente de nodo. Los colectores se configuran con recursos de PodMonitoring para monitorizar los destinos de un espacio de nombres y con recursos de ClusterPodMonitoring para monitorizar los destinos de un clúster. Los PodMonitorings deben aplicarse en todos los espacios de nombres en los que quieras recoger métricas. Los ClusterPodMonitorings se aplican una vez por clúster.
Todos los datos recogidos en el proyecto 1 se guardan en Monarch en el proyecto 1. Estos datos se almacenan de forma predeterminada en la Google Cloud región desde la que se emitieron.
El proyecto 2 tiene un clúster que ejecuta una colección autodesplegada con prometheus-operator y que funciona como un servicio independiente. Este clúster está configurado para usar PodMonitors o ServiceMonitors de prometheus-operator para recoger datos de los exportadores de pods o máquinas virtuales.
El proyecto 2 también aloja un sidecar de pasarela push para recoger métricas de cargas de trabajo efímeras.
Todos los datos recogidos en el proyecto 2 se guardan en Monarch en el proyecto 2. Estos datos se almacenan de forma predeterminada en la Google Cloud región desde la que se emitieron.
El proyecto 1 también tiene un clúster que ejecuta Grafana y el sincronizador de fuentes de datos. En este ejemplo, estos componentes están alojados en un clúster independiente, pero se pueden alojar en cualquier clúster.
El sincronizador de fuentes de datos está configurado para usar scoping_project_A y su cuenta de servicio subyacente tiene permisos de lector de Monitoring para scoping_project_A.
Cuando un usuario envía consultas desde Grafana, Monarch amplía scoping_project_A a sus proyectos monitorizados constituyentes y devuelve resultados de Project 1 y Project 2 en todas las regiones de Google Cloud . Todas las métricas conservan sus etiquetas originales
project_idylocation(Google Cloud región) para agrupar y filtrar.
Si tu clúster no se ejecuta en Google Cloud, debes configurar manualmente las etiquetas project_id y location. Para obtener información sobre cómo definir estos valores, consulta Ejecutar Managed Service para Prometheus fuera deGoogle Cloud.
No federes cuando uses Managed Service para Prometheus. Para reducir la cardinalidad y los costes agregando los datos localmente antes de enviarlos a Monarch, usa la agregación local. Para obtener más información, consulta Configurar la agregación local.