Dokumen ini menjelaskan cara menyiapkan lingkungan yang menggabungkan kolektor yang di-deploy sendiri dengan kolektor terkelola, di berbagai project dan clusterGoogle Cloud .
Sebaiknya gunakan pengumpulan terkelola untuk semua lingkungan Kubernetes. Dengan begitu, overhead untuk menjalankan kolektor Prometheus dalam cluster Anda akan praktis dihilangkan. Anda dapat menjalankan kolektor terkelola dan yang di-deploy sendiri dalam cluster yang sama. Sebaiknya gunakan pendekatan yang konsisten untuk pemantauan, tetapi Anda dapat memilih untuk menggabungkan metode deployment untuk beberapa kasus penggunaan tertentu, seperti menghosting gateway push, seperti yang diilustrasikan dalam dokumen ini.
Diagram berikut mengilustrasikan konfigurasi yang menggunakan dua projectGoogle Cloud , tiga cluster, dan menggabungkan koleksi yang dikelola dan di-deploy sendiri. Jika Anda hanya menggunakan koleksi terkelola atau yang di-deploy sendiri, diagram ini masih berlaku; cukup abaikan gaya koleksi yang tidak Anda gunakan:
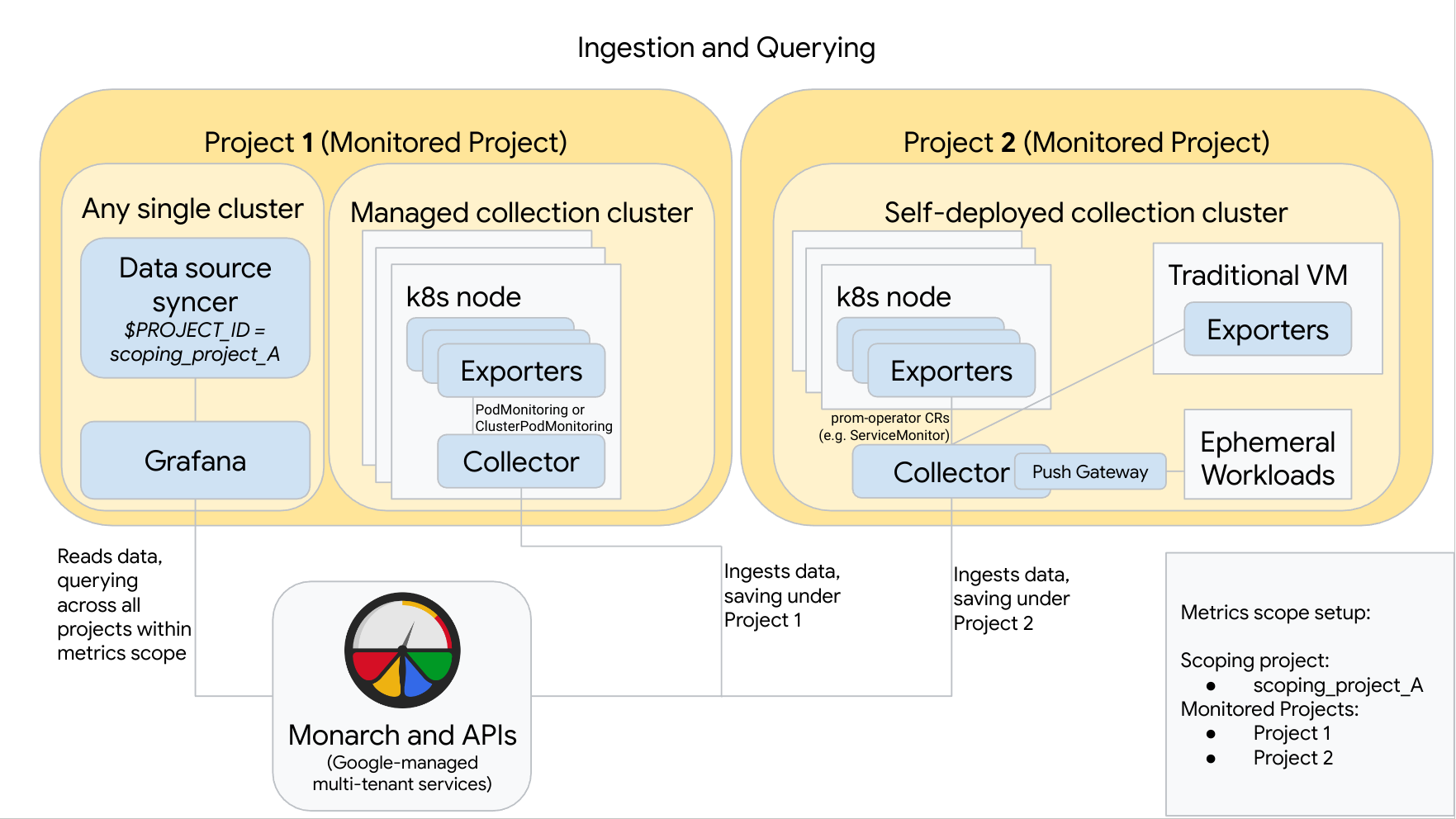
Untuk menyiapkan dan menggunakan konfigurasi seperti yang ada dalam diagram, perhatikan hal berikut:
Anda harus menginstal eksportir yang diperlukan di cluster. Google Cloud Managed Service for Prometheus tidak menginstal eksportir apa pun atas nama Anda.
Project 1 memiliki cluster yang menjalankan koleksi terkelola, yang berjalan sebagai agen node. Pengumpul dikonfigurasi dengan resource PodMonitoring untuk meng-scrape target dalam namespace dan dengan resource ClusterPodMonitoring untuk meng-scrape target di seluruh cluster. PodMonitorings harus diterapkan di setiap namespace tempat Anda ingin mengumpulkan metrik. ClusterPodMonitorings diterapkan satu kali per cluster.
Semua data yang dikumpulkan di Project 1 disimpan di Monarch di bagian Project 1. Data ini disimpan secara default di region Google Cloud tempat data tersebut dimunculkan.
Project 2 memiliki cluster yang menjalankan pengumpulan yang di-deploy sendiri menggunakan prometheus-operator dan berjalan sebagai layanan mandiri. Cluster ini dikonfigurasi untuk menggunakan PodMonitors atau ServiceMonitors prometheus-operator untuk menyalin eksportir di pod atau VM.
Project 2 juga menghosting sidecar gateway push untuk mengumpulkan metrik dari workload sementara.
Semua data yang dikumpulkan di Project 2 disimpan di Monarch di bagian Project 2. Data ini disimpan secara default di region Google Cloud tempat data tersebut dimunculkan.
Project 1 juga memiliki cluster yang menjalankan Grafana dan penyinkron sumber data. Dalam contoh ini, komponen ini dihosting di cluster mandiri, tetapi dapat dihosting di satu cluster.
Pengsinkron sumber data dikonfigurasi untuk menggunakan scoping_project_A, dan akun layanan pokoknya memiliki izin Pelihat Pemantauan untuk scoping_project_A.
Saat pengguna mengeluarkan kueri dari Grafana, Monarch akan memperluas scoping_project_A ke dalam project yang dipantau penyusunnya dan menampilkan hasil untuk Project 1 dan Project 2 di semua Google Cloud region. Semua metrik mempertahankan label
project_iddanlocation(regionGoogle Cloud ) aslinya untuk tujuan pengelompokan dan pemfilteran.
Jika cluster tidak berjalan di dalam Google Cloud, Anda harus mengonfigurasi label project_id dan location secara manual. Untuk informasi tentang cara menetapkan nilai ini, lihat Menjalankan Managed Service for Prometheus di luarGoogle Cloud.
Jangan melakukan federasi saat menggunakan Managed Service for Prometheus. Untuk mengurangi kardinalitas dan biaya dengan "menggabungkan" data sebelum mengirimkannya ke Monarch, gunakan agregasi lokal. Untuk informasi selengkapnya, lihat Mengonfigurasi agregasi lokal.