In diesem Dokument wird beschrieben, wie Sie eine Umgebung einrichten können, die selbst bereitgestellte Collectors mit verwalteten Collectors in verschiedenenGoogle Cloud -Projekten und Clustern mischt.
Wir empfehlen dringend, für alle Kubernetes-Umgebungen die verwaltete Erfassung zu verwenden. Dadurch entfällt der Aufwand für die Ausführung von Prometheus-Collectors in Ihrem Cluster. Sie können verwaltete und selbst bereitgestellte Collectors im selben Cluster ausführen. Wir empfehlen die Verwendung eines konsistenten Monitoring-Ansatzes. Sie können jedoch auch für einige bestimmte Anwendungsfälle, wie das Hosten eines Push-Gateways, Bereitstellungsmethoden mischen, wie in diesem Dokument dargestellt.
Das folgende Diagramm zeigt eine Konfiguration, die zweiGoogle Cloud -Projekte und drei Cluster verwendet und die verwaltete und die selbst bereitgestellte Erfassung kombiniert. Wenn Sie nur die verwaltete oder die selbst bereitgestellte Erfassung verwenden, ist das Diagramm weiterhin anwendbar. Ignorieren Sie einfach den nicht verwendeten Erfassungsstil:
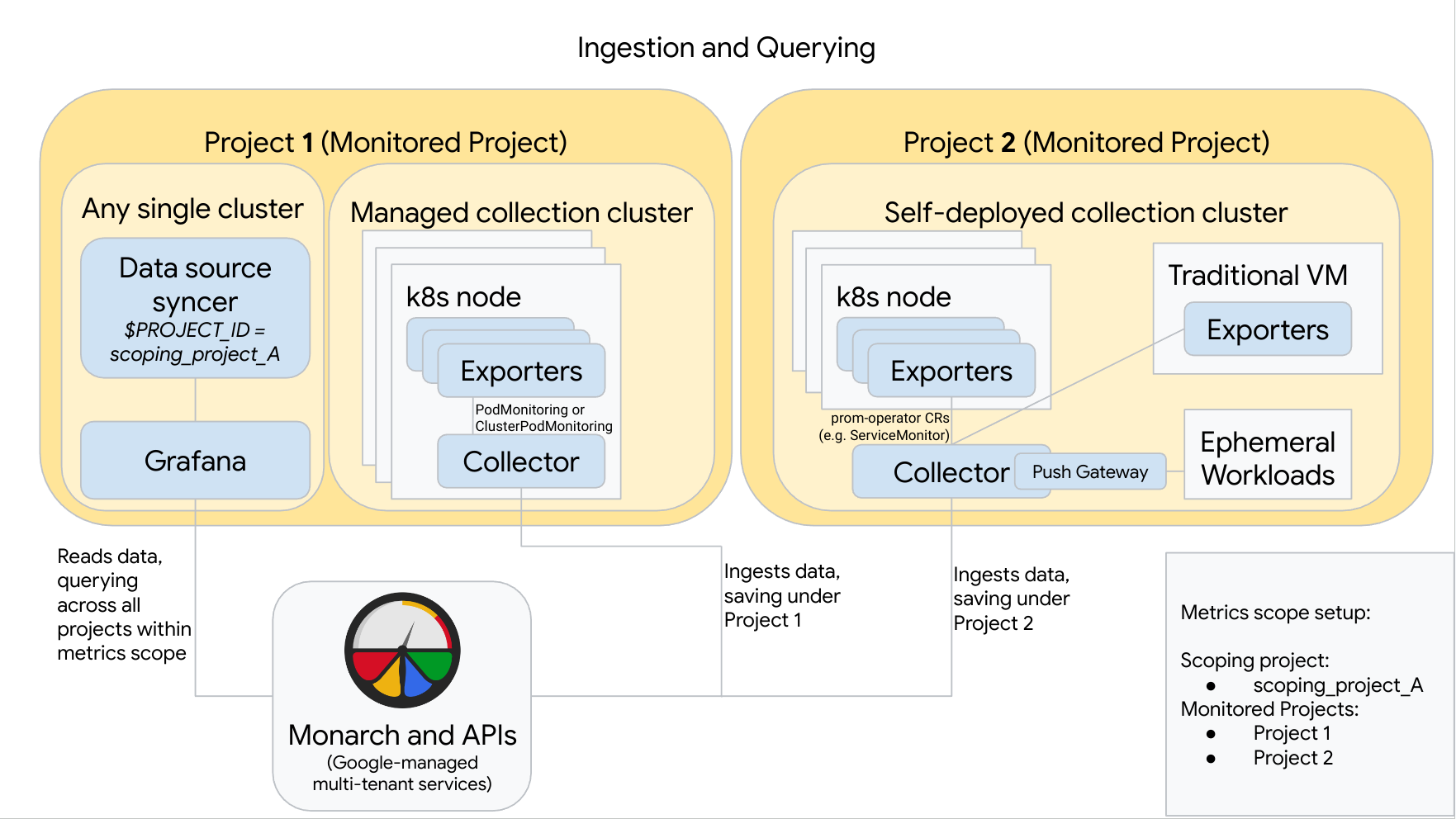
Beachten Sie Folgendes, um eine Konfiguration wie im Diagramm einzurichten und zu verwenden:
Sie müssen alle erforderlichen Exporter in Ihren Clustern installieren. Google Cloud Managed Service for Prometheus installiert in Ihrem Namen keine Exporter.
Projekt 1 hat einen Cluster, der die verwaltete Erfassung ausführt und der als Knoten-Agent ausgeführt wird. Collectors werden mit PodMonitoring-Ressourcen konfiguriert, um Ziele innerhalb eines Namespace zu extrahieren, und mit ClusterPodMonitoring-Ressourcen, um Ziele in einem Cluster zu extrahieren. PodMonitorings müssen auf jeden Namespace angewendet werden, in dem Sie Messwerte erfassen möchten. ClusterPodMonitorings werden pro Cluster einmal angewendet.
Alle in Projekt 1 erfassten Daten werden in Monarch unter Projekt 1 gespeichert. Diese Daten werden standardmäßig in der Google Cloud Region gespeichert, von der sie ausgegeben wurden.
Projekt 2 hat einen Cluster, der die selbst bereitgestellte Erfassung mit dem Prometheus-Operator ausführt und der als eigenständiger Dienst ausgeführt wird. Dieser Cluster ist so konfiguriert, dass er mit PodMonitors oder ServiceMonitors des Prometheus-Operators Daten aus Pods oder VMs extrahiert.
Projekt 2 hostet auch ein Push-Gateway-Sidecar, um Messwerte aus sitzungsspezifischen Arbeitslasten zu erfassen.
Alle in Projekt 2 erfassten Daten werden in Monarch unter Projekt 2 gespeichert. Diese Daten werden standardmäßig in der Google Cloud Region gespeichert, von der sie ausgegeben wurden.
Projekt 1 hat auch einen Cluster, in dem Grafana und der Datenquellen-Synchronizer ausgeführt werden. In diesem Beispiel werden diese Komponenten in einem eigenständigen Cluster gehostet, können aber in einem beliebigen einzelnen Cluster gehostet werden.
Der Datenquellen-Synchronizer ist für die Verwendung von Bereichsprojekt_A konfiguriert und das zugrunde liegende Dienstkonto hat Berechtigungen des Typs Monitoring-Betrachter für Bereichsprojekt_A.
Wenn ein Nutzer Abfragen von Grafana sendet, erweitert Monarch Bereichsprojekt_A in die überwachten Projekte, aus denen es besteht, und gibt Ergebnisse für Projekt 1 und Projekt 2 in allen Google Cloud -Regionen zurück. Alle Messwerte behalten ihre ursprünglichen Labels
project_idundlocation(Google Cloud -Region) für Gruppierungs- und Filterzwecke bei.
Wenn Ihr Cluster nicht in Google Cloudausgeführt wird, müssen Sie die Labels project_id und location manuell konfigurieren. Informationen zum Festlegen dieser Werte finden Sie unter Managed Service for Prometheus außerhalb vonGoogle Cloudausführen.
Führen Sie bei Verwendung von Managed Service for Prometheus keine Föderation durch. Verwenden Sie stattdessen die lokale Aggregation, um die Kardinalität und Kosten durch das "Sammeln" von Daten vor dem Senden an Monarch zu reduzieren. Weitere Informationen finden Sie unter Lokale Aggregation konfigurieren.