Este documento descreve como pode configurar um ambiente que misture coletores implementados automaticamente com coletores geridos em diferentesGoogle Cloud projetos e clusters.
Recomendamos vivamente que use a recolha gerida para todos os ambientes do Kubernetes. Deste modo, elimina praticamente a sobrecarga da execução de coletores do Prometheus no cluster. Pode executar coletores geridos e implementados automaticamente no mesmo cluster. Recomendamos que use uma abordagem consistente para a monitorização, mas pode optar por combinar métodos de implementação para alguns exemplos de utilização específicos, como alojar um gateway de envio, conforme ilustrado neste documento.
O diagrama seguinte ilustra uma configuração que usa dois Google Cloud projetos, três clusters e mistura a recolha gerida e autónoma. Se usar apenas a recolha gerida ou implementada por si, o diagrama continua a ser aplicável. Basta ignorar o estilo de recolha que não está a usar:
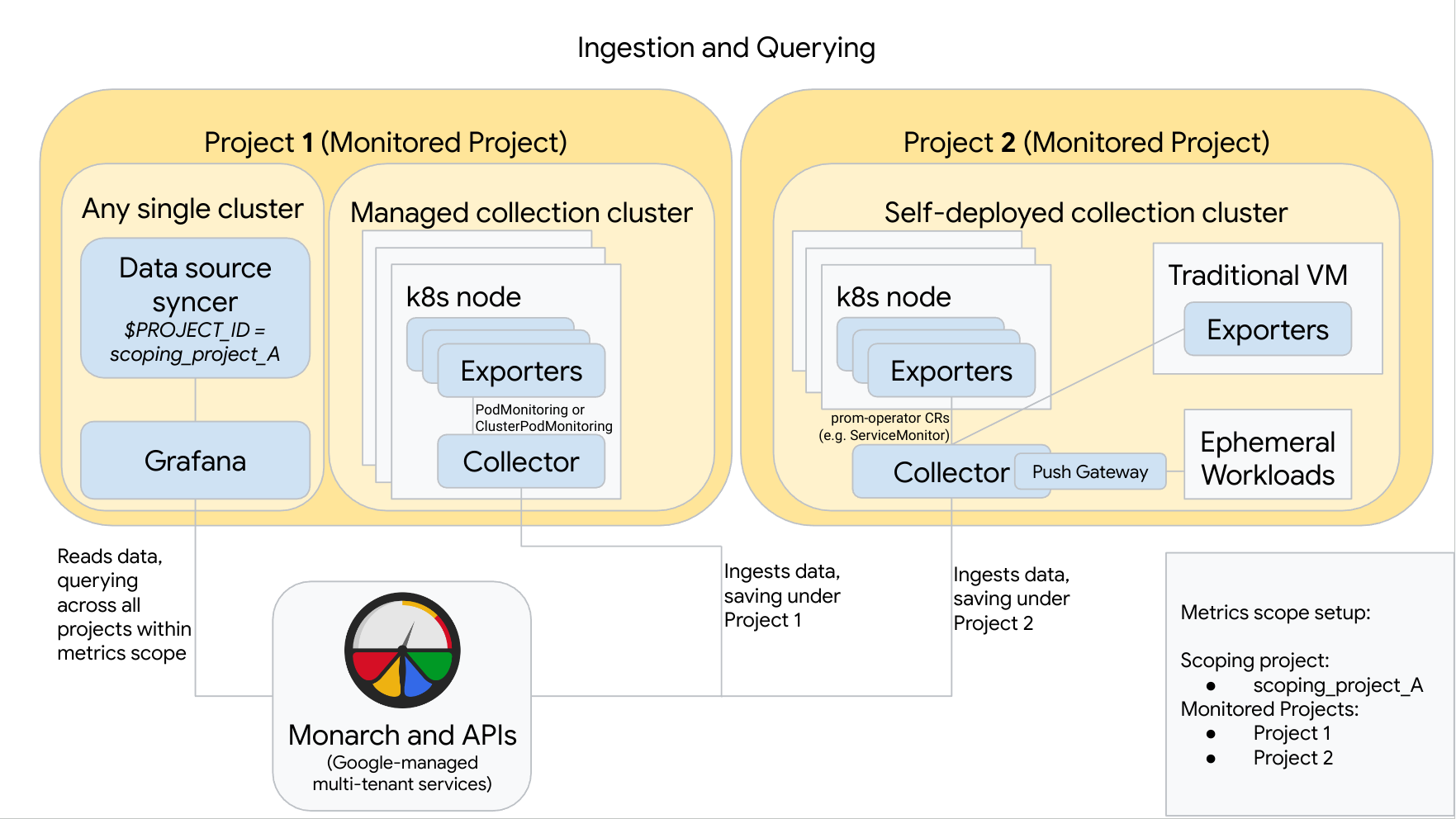
Para configurar e usar uma configuração como a do diagrama, tenha em atenção o seguinte:
Tem de instalar todos os exportadores necessários nos seus clusters. O Google Cloud Managed Service for Prometheus não instala exportadores em seu nome.
O projeto 1 tem um cluster a executar a recolha gerida, que é executada como um agente de nó. Os coletores são configurados com recursos PodMonitoring para extrair alvos num espaço de nomes e com recursos ClusterPodMonitoring para extrair alvos num cluster. Os PodMonitorings têm de ser aplicados em todos os espaços de nomes nos quais quer recolher métricas. Os ClusterPodMonitorings são aplicados uma vez por cluster.
Todos os dados recolhidos no Projeto 1 são guardados no Monarch em Projeto 1. Estes dados são armazenados por predefinição na Google Cloud região a partir da qual foram emitidos.
O projeto 2 tem um cluster a executar a recolha implementada automaticamente através do prometheus-operator e em execução como um serviço autónomo. Este cluster está configurado para usar PodMonitors ou ServiceMonitors do prometheus-operator para extrair dados de exportadores em pods ou VMs.
O projeto 2 também aloja um sidecar do gateway push para recolher métricas de cargas de trabalho efémeras.
Todos os dados recolhidos no Projeto 2 são guardados no Monarch em Projeto 2. Estes dados são armazenados por predefinição na Google Cloud região a partir da qual foram emitidos.
O projeto 1 também tem um cluster a executar o Grafana e o sincronizador de origens de dados. Neste exemplo, estes componentes estão alojados num cluster autónomo, mas podem ser alojados em qualquer cluster único.
O sincronizador da origem de dados está configurado para usar scoping_project_A e a respetiva conta de serviço subjacente tem autorizações de leitor de monitorização para scoping_project_A.
Quando um utilizador envia consultas a partir do Grafana, o Monarch expande scoping_project_A nos respetivos projetos monitorizados constituintes e devolve resultados para o Project 1 e o Project 2 em todas as Google Cloud regiões. Todas as métricas mantêm as etiquetas originais
project_idelocation(Google Cloud região) para fins de agrupamento e filtragem.
Se o cluster não estiver a ser executado no Google Cloud, tem de configurar manualmente as etiquetas project_id e location. Para obter informações sobre como definir estes valores, consulte o artigo Execute o Managed Service for Prometheus fora do
Google Cloud.
Não federar quando usar o Managed Service for Prometheus. Para reduzir a cardinalidade e o custo "agrupando" os dados antes de os enviar para o Monarch, use a agregação local. Para mais informações, consulte o artigo Configure a agregação local.