Cette page explique comment utiliser le tableau de bord des insights système de Cloud SQL. Le tableau de bord des insights système affiche les métriques des ressources utilisées par votre instance, et vous aide à détecter et à analyser les problèmes de performances du système.
Vous pouvez bénéficier de l'assistance de Gemini dans les bases de données pour vous aider à observer et à résoudre les problèmes liés à vos ressources Cloud SQL pour PostgreSQL. Pour en savoir plus, consultez Observer et résoudre les problèmes avec l'aide de Gemini.Afficher le tableau de bord des insights système
Pour afficher le tableau de bord des insights système, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page Instances Cloud SQL.
- Cliquez sur le nom d'une instance.
Sélectionnez l'onglet Insights système dans le panneau de navigation SQL de gauche.
Le tableau de bord des insights système s'affiche.
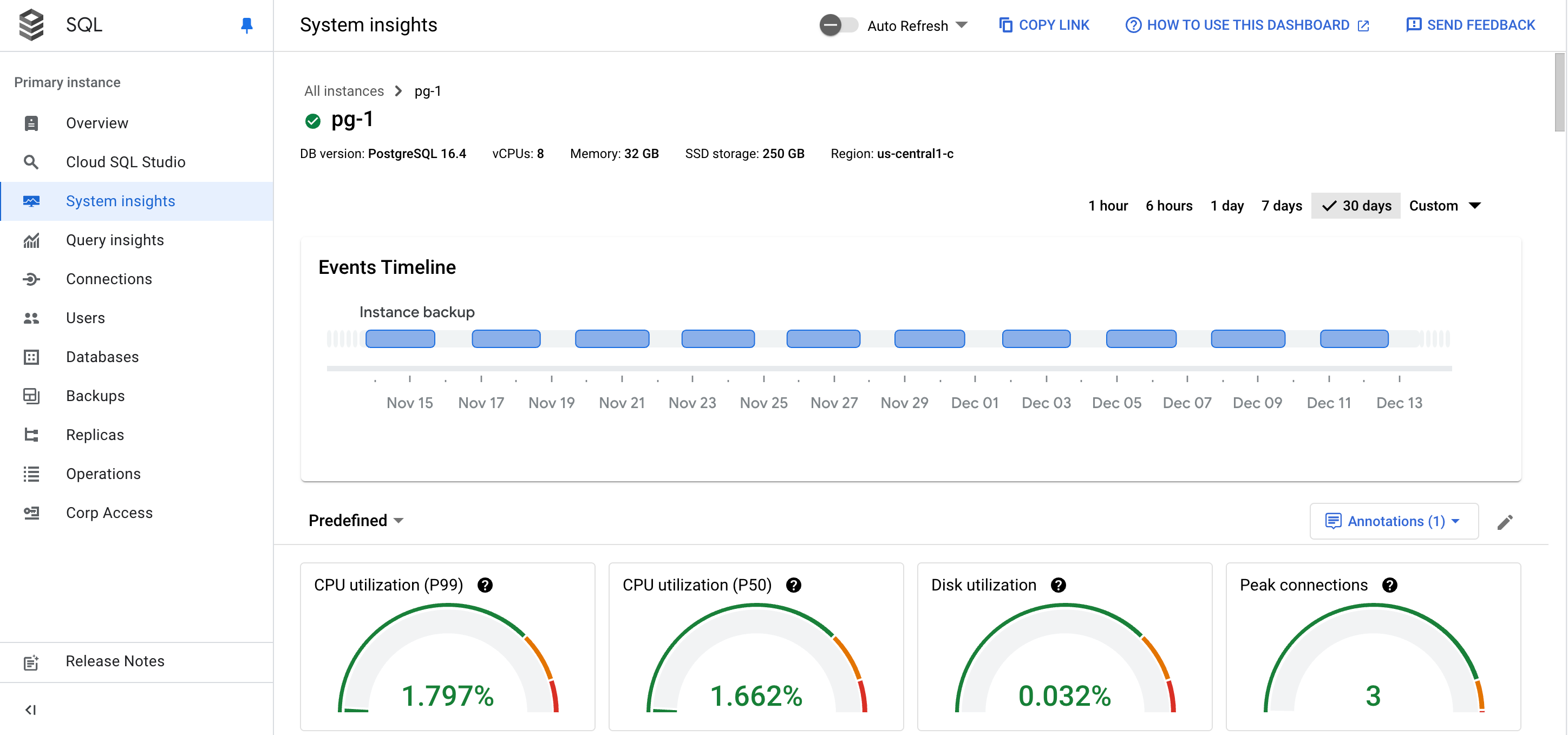
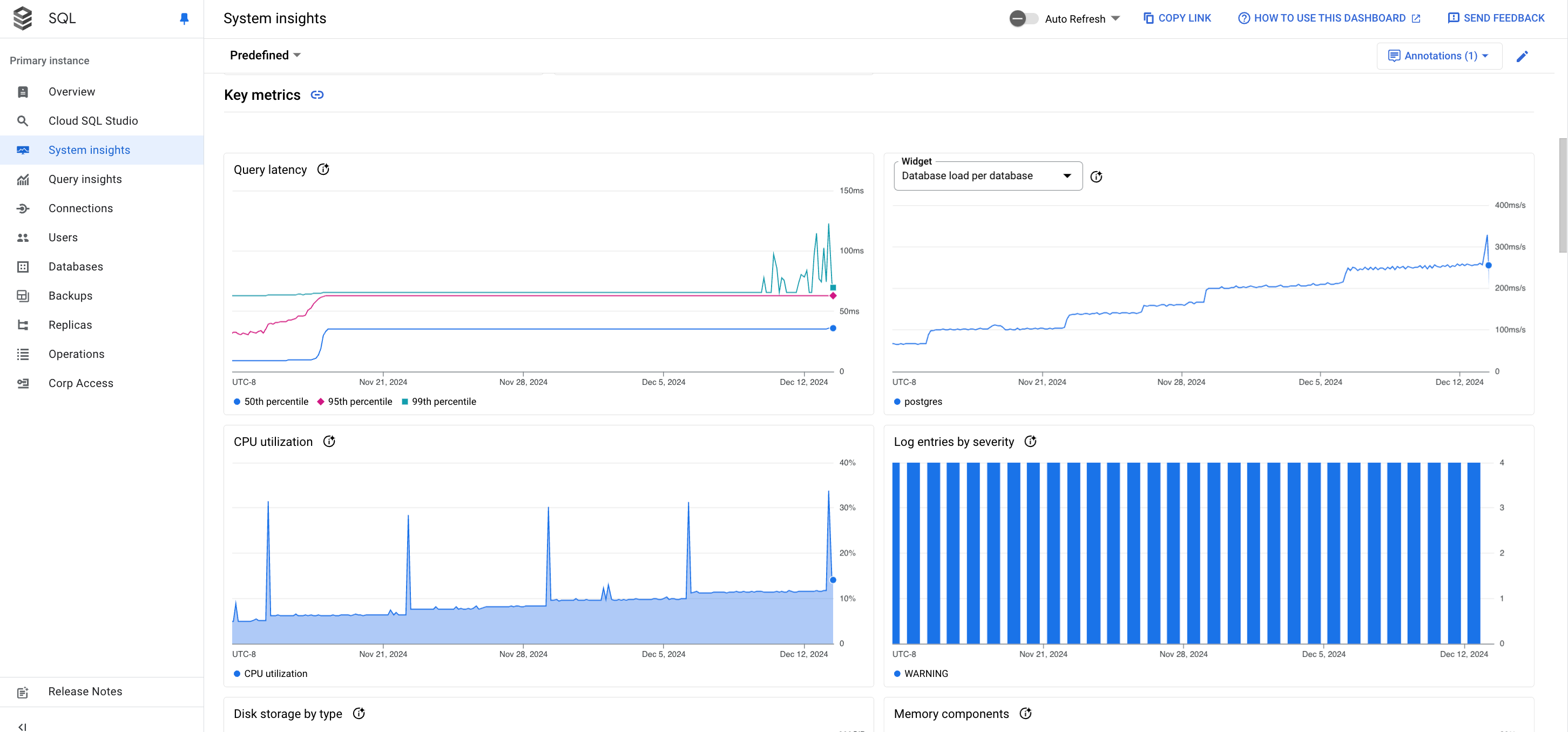
Le tableau de bord des insights système affiche les informations suivantes :
Détails de votre instance
Chronologie des événements : affiche les événements système dans un ordre chronologique. Ces informations vous aident à évaluer l'impact des événements système sur l'état et les performances de l'instance.
Fiches récapitulatives : fournissent un aperçu de l'état et des performances de l'instance en affichant les valeurs agrégées et les plus récentes pour les métriques d'utilisation du processeur, d'utilisation du disque et d'erreurs de journaux.
Graphiques de métriques : affichent les informations sur les métriques de système d'exploitation et de base de données qui vous aident à mieux comprendre les problèmes de débit, de latence et de coûts.
Le tableau de bord propose les options générales suivantes :
- Pour afficher un ou deux graphiques par ligne. Cliquez sur Personnaliser la vue pour choisir comment afficher ces graphiques. Vous pouvez également utiliser cette option pour choisir les métriques à afficher dans le tableau de bord.
Pour maintenir le tableau de bord à jour, activez l'option
 Actualisation automatique. Lorsque vous activez l'actualisation automatique, les données du tableau de bord sont mises à jour toutes les minutes. Cette fonctionnalité n'est pas compatible avec les périodes personnalisées.
Actualisation automatique. Lorsque vous activez l'actualisation automatique, les données du tableau de bord sont mises à jour toutes les minutes. Cette fonctionnalité n'est pas compatible avec les périodes personnalisées.Le sélecteur de temps affiche
1 daysélectionnée par défaut. Pour modifier la période, sélectionnez l'une des autres périodes prédéfinies ou cliquez sur Personnalisée, puis définissez une heure de début et une heure de fin. Les données disponibles portent sur les 30 derniers jours.Pour créer un lien absolu vers le tableau de bord, cliquez sur le bouton Copier le lien. Vous pouvez partager ce lien avec d'autres utilisateurs Cloud SQL disposant des mêmes autorisations.
Pour créer une alerte pour un événement spécifique, cliquez sur Notification.
Pour afficher des alertes spécifiques, cliquez sur Annotations.
Fiches récapitulatives
Le tableau suivant décrit les fiches récapitulatives affichées en haut du tableau de bord des insights système. Ces fiches offrent un aperçu rapide de l'état et des performances de l'instance pendant la période choisie.
| Fiche récapitulative | Description |
|---|---|
| Utilisation du processeur - P99 | P50 | Valeurs d'utilisation du processeur P99 et P50 sur la période sélectionnée. |
| Pic de connexions | Ratio entre le pic de connexions et le nombre maximal de connexions pour la période sélectionnée.
Le nombre maximal de connexions peut être supérieur au nombre maximal si le nombre maximal de modifications a récemment changé, par exemple en raison d'un scaling d'instance ou d'une modification manuelle du paramètre max_connections. |
| Utilisation des ID de transaction | Dernière valeur d'utilisation de l'ID de transaction pour la période sélectionnée. |
| Utilisation du disque | Dernière valeur d'utilisation du disque. |
| Erreurs du journal | Nombre d'erreurs enregistrées par les utilisateurs. |
Graphiques des métriques
Une fiche de graphique pour un exemple de métrique s'affiche comme suit.
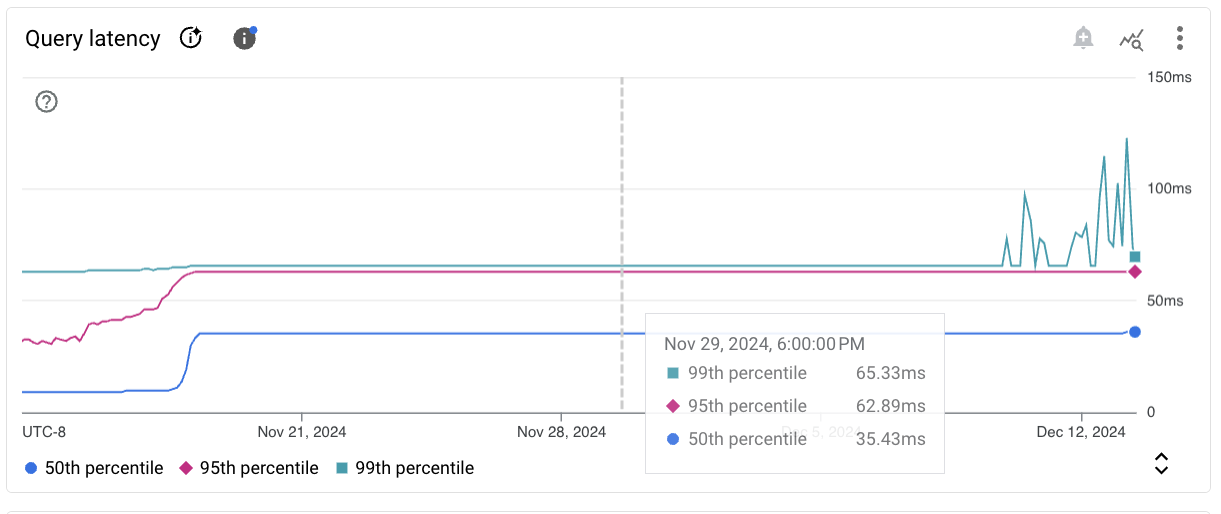
La barre d'outils de chaque fiche de graphique fournit les options standards suivantes :
Pour afficher les valeurs de métrique à un moment spécifique dans la période sélectionnée, déplacez le curseur sur le graphique.
Pour zoomer sur un graphique, cliquez dessus et faites-le glisser horizontalement le long de l'axe des abscisses ou verticalement sur l'axe des ordonnées. Pour annuler l'opération de zoom, cliquez sur Réinitialiser le zoom. Vous pouvez également cliquer sur l'une des périodes prédéfinies en haut du tableau de bord. Les opérations de zoom s'appliquent simultanément à tous les graphiques d'un tableau de bord.
Pour afficher d'autres options, cliquez sur more_vert Autres options des graphiques. La plupart des graphiques offrent les options suivantes :
Pour afficher un graphique en mode plein écran, cliquez sur Afficher en plein écran. Pour quitter le mode plein écran, cliquez sur Annuler.
masquer ou réduire la légende ;
Télécharger une image du graphique au format PNG ou un fichier CSV
Afficher dans l'Explorateur de métriques. Affichez la métrique dans l'Explorateur de métriques. Vous pouvez afficher d'autres métriques Cloud SQL dans l'explorateur de métriques après avoir sélectionné le type de ressource Base de données Cloud SQL.
Pour créer un tableau de bord personnalisé, cliquez sur edit Personnaliser le tableau de bord, puis donnez-lui un nom. Vous pouvez également développer le menu Prédéfini et sélectionner un tableau de bord personnalisé existant.
Pour afficher les données d'un graphique de métriques en détail, cliquez sur query_stats Explorer les données. Vous pouvez y filtrer des métriques spécifiques et choisir le mode d'affichage du graphique :
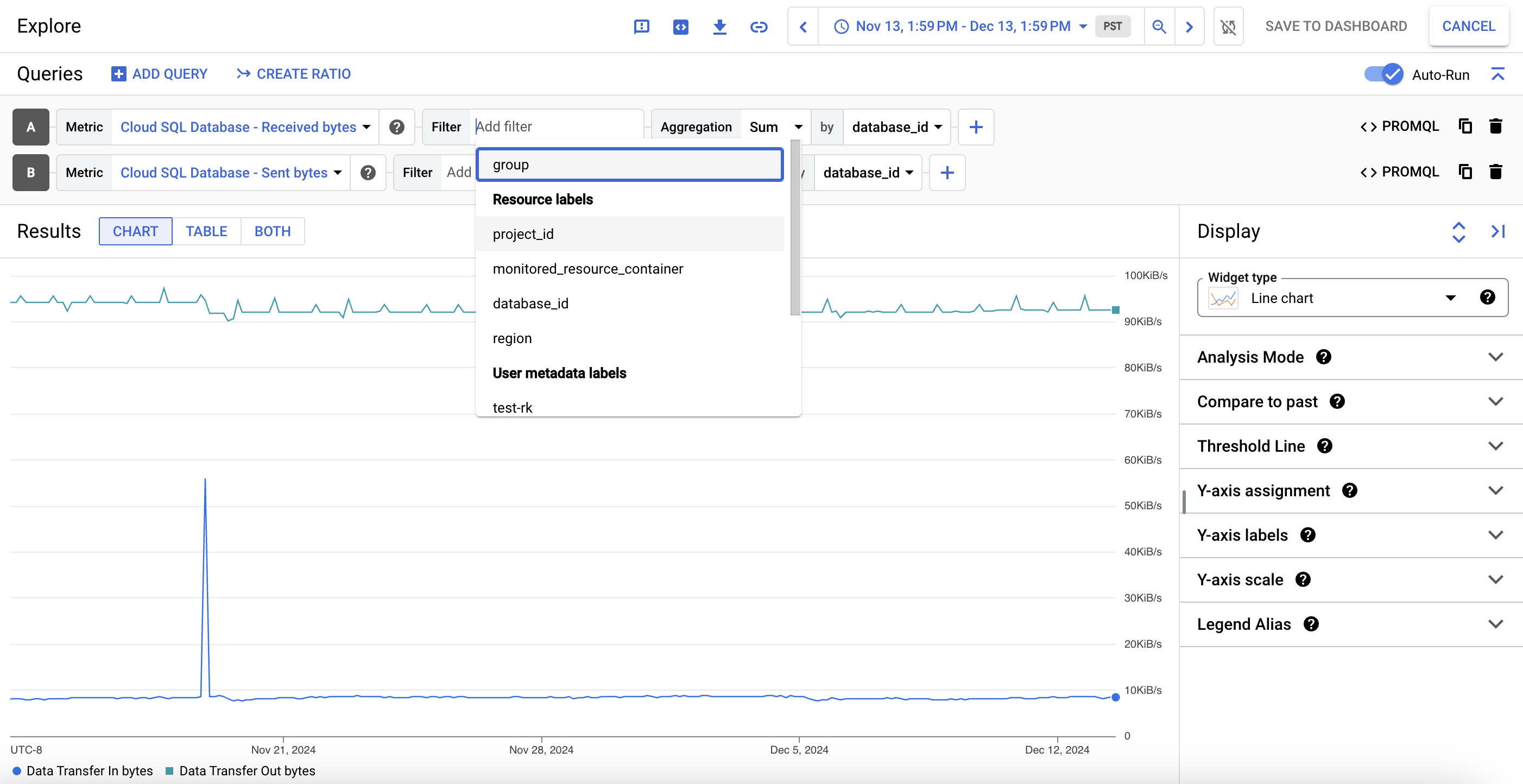
Pour enregistrer cette vue personnalisée en tant que graphique de métriques, cliquez sur Enregistrer dans le tableau de bord.
Métriques par défaut
Le tableau suivant décrit les métriques Cloud SQL qui s'affichent par défaut dans le tableau de bord des insights système de Cloud SQL.
Les chaînes de type de métrique comportent le préfixe suivant : cloudsql.googleapis.com/database/.
Pour connaître la phase de lancement la plus récente des métriques suivantes, consultez les métriquesGoogle Cloud .
| Nom et type de la métrique | Description |
|---|---|
Nouvelles connexions par secondepostgresql/new_connection_count
|
Taux correspondant au nombre de nouvelles connexions que vous créez sur votre instance Cloud SQL pour PostgreSQL par seconde Cloud SQL calcule et affiche cette métrique par base de données. Cette métrique est disponible pour PostgreSQL 14 et versions ultérieures. |
Types d'événements d'attente
postgresql/backends_in_wait
|
Nombre de connexions pour chaque type d'événement d'attente dans une instance Cloud SQL pour PostgreSQL. |
Événements d'attentepostgresql/backends_in_wait
|
Nombre d'événements d'attente dans une instance Cloud SQL pour PostgreSQL. Le tableau de bord affiche cette métrique sous la forme "wait event name:wait event type". |
Nombre de transactionspostgresql/transaction_count
|
Le nombre de transactions aux états |
Composants mémoirememory/components
|
Composants de mémoire disponibles pour la base de données. La valeur de chaque composant de mémoire est calculée en pourcentage de la mémoire totale disponible pour la base de données. |
Délai maximal pour les octets d'instances répliquéespostgresql/external_sync/max_replica_byte_lag
|
Délai maximal de réplication (en octets) entre toutes les bases de données de l'instance dupliquée externe du serveur. |
Latence des requêtespostgresql/insights/aggregate/latencies |
Latence cumulée des requêtes au 50e, 95e et 99e centile par utilisateur et par base de données. Disponible uniquement pour les instances sur lesquelles Query Insights est activé. |
Charge de la base de données par base de données/utilisateur/adresse clientpostgresql/insights/aggregate/execution_time |
Temps d'exécution cumulé de la requête par base de données, utilisateur ou adresse client. Il s'agit de la somme du temps CPU, du temps d'attente E/S, du temps de verrouillage, ainsi que du temps consacré au changement de contexte de traitement et à la planification de tous les processus impliqués dans l'exécution de la requête. Disponible uniquement pour les instances sur lesquelles Query Insights est activé. |
Utilisation du processeurcpu/utilization |
Utilisation actuelle du processeur représentée sous forme de pourcentage du processeur réservé utilisé. |
Stockage sur disque par typedisk/bytes_used_by_data_type |
Répartition de l'utilisation du disque d'instance par type de données, y compris Cette métrique vous aide à comprendre vos coûts de stockage. Pour plus d'informations sur les frais d'utilisation du stockage, consultez la page Tarifs du stockage et de la mise en réseau. La récupération à un moment précis (PITR) utilise l'archivage de journaux préalable (write-ahead log). Ces journaux sont mis à jour régulièrement et utilisent de l'espace de stockage. Les journaux préalables sont automatiquement supprimés, ainsi que la sauvegarde automatique associée, au bout de sept jours environ. Si la taille de vos journaux préalables pose problème pour votre instance, envisagez d'augmenter la taille de votre espace de stockage. Sachez toutefois qu'une augmentation de l'espace disque occupé par vos journaux préalables peut être temporaire. Pour éviter les problèmes de stockage inattendus, nous vous recommandons d'activer l'augmentation automatique de l'espace de stockage lorsque vous utilisez PITR. Pour supprimer les journaux et récupérer de l'espace de stockage, vous pouvez désactiver la récupération à un moment précis. Notez cependant que la réduction de l'espace de stockage utilisé ne réduit pas la taille du stockage provisionné pour l'instance. Les données temporaires sont prises en compte dans la métrique d'utilisation du stockage. Les données temporaires sont supprimées dans le cadre de la maintenance. Elles peuvent excéder les limites de capacité définies par l'utilisateur afin d'éviter un événement "disque saturé", sans frais pour l'utilisateur. Une base de données venant d'être créée utilise environ 100 Mo pour les tables et les fichiers système. |
Stockage sur disque par typedisk/bytes_used_by_data_type |
Répartition de l'utilisation du disque d'instance par type de données, y compris Cette métrique vous aide à comprendre vos coûts de stockage. Pour plus d'informations sur les frais d'utilisation du stockage, consultez la page Tarifs du stockage et de la mise en réseau. La récupération à un moment précis utilise l'archivage des journaux préalables (WAL, Write-Ahead Logging). Pour les nouvelles instances Cloud SQL pour lesquelles la récupération à un moment précis est activée ou pour les instances existantes qui activent la récupération à un moment précis après la mise à disposition de cette fonctionnalité pour le stockage des journaux WAL dans Cloud Storage, les journaux ne seront plus stockés sur le disque, mais dans Cloud Storage, dans la même région que les instances. Pour savoir si les journaux d'une instance sont stockés dans Cloud Storage, consultez la métrique bytes_used_by_data_type de l'instance. Si la valeur du type de données Les journaux des autres instances existantes sur lesquelles la récupération à un moment précis est activée continuent d'être conservés sur le disque. La modification du stockage des journaux dans Cloud Storage sera disponible ultérieurement. Les journaux préalables utilisés pour la récupération à un moment précis sont automatiquement supprimés, ainsi que leur sauvegarde automatique associée, généralement après que la valeur définie pour transactionLogRetentionDays est atteinte. Il s'agit du nombre de jours de journaux de transactions que Cloud SQL conserve à un moment précis, de 1 à 7. Pour les instances disposant de journaux préalables stockés dans Cloud Storage, les journaux sont stockés dans la même région que l'instance principale. Ce stockage de journaux (jusqu'à sept jours, la durée maximale pour la récupération à un moment précis) ne génère aucun coût supplémentaire par instance. Si la récupération à un moment précis est activée sur votre instance, et si la taille de vos journaux préalables sur le disque pose problème pour votre instance, désactivez la récupération à un moment précis puis réactivez-la, pour vous assurer que les nouveaux journaux sont stockés dans Cloud Storage, dans la même région que l'instance. Cette opération supprime les journaux WAL existants. Vous ne pouvez donc pas effectuer de restauration à un moment précis antérieur à la date à laquelle vous avez réactivé la récupération à un moment précis. Toutefois, bien que les journaux existants soient supprimés, la taille du disque reste la même. Pour éviter les problèmes de stockage inattendus, nous vous recommandons d'activer l'augmentation automatique de l'espace de stockage pour toutes les instances lorsque vous utilisez la récupération à un moment précis. Cette recommandation ne s'applique que si la récupération à un moment précis est activée sur votre instance et que vos journaux sont stockés sur le disque. Pour supprimer les journaux et récupérer de l'espace de stockage, vous pouvez désactiver la récupération à un moment précis. Notez cependant que la réduction du nombre de journaux préalables utilisés ne réduit pas la taille du disque provisionné pour l'instance. Les données temporaires sont prises en compte dans la métrique d'utilisation du stockage. Les données temporaires sont supprimées dans le cadre de la maintenance. Elles peuvent excéder les limites de capacité définies par l'utilisateur afin d'éviter un événement "disque saturé", sans frais pour l'utilisateur. Une base de données venant d'être créée utilise environ 100 Mo pour les tables et les fichiers système. |
Opérations de lecture/écriture sur le disquedisk/read_ops_count, disk/write_ops_count |
La métrique "Nombre de lectures" indique le nombre d'opérations de lecture par seconde exécutées depuis le disque et qui ne proviennent pas du cache. Vous pouvez utiliser cette métrique pour savoir si votre instance est correctement dimensionnée par rapport à votre environnement. Si nécessaire, vous pouvez passer à un type de machine plus grand pour traiter davantage de requêtes en cache et réduire le temps de latence. La métrique "Nombre d'écritures" recense le nombre d'opérations d'écriture sur le disque. Des activités en écriture existent même si votre application n'est pas active, car les instances Cloud SQL, à l'exception des instances dupliquées, écrivent dans une table système environ toutes les secondes. |
Connexions par étatpostgresql/num_backends_by_state |
Nombre de connexions regroupées par ces états : Pour en savoir plus sur ces états, consultez la ligne |
Connexions par base de donnéespostgresql/num_backends |
Nombre de connexions détenues par l'instance de base de données. |
Octets d'entrée/de sortienetwork/received_bytes_count, network/sent_bytes_count |
Trafic réseau exprimé en nombre d'octets d'entrée (envoyés vers l'instance) et d'octets de sortie (envoyés depuis l'instance). |
Répartition de l'attente d'E/S par typepostgresql/insights/aggregate/io_time |
Temps d'attente E/S pour les instructions SQL par type de lecture et d'écriture. Disponible uniquement pour les instances sur lesquelles Query Insights est activé. |
Nombre d'interblocages par base de donnéespostgresql/deadlock_count |
Nombre d'interblocages par base de données. |
Nombre de blocs luspostgresql/blocks_read_count |
Nombre de blocs lus par seconde dans le disque et le cache des tampons. |
Lignes traitées par opérationpostgresql/tuples_processed_count |
Nombre de lignes traitées par opération par seconde. |
Lignes dans la base de données par étatpostgresql/tuple_size |
Nombre de lignes pour chaque état de la base de données. Cloud SQL fournit cette métrique si le nombre de bases de données de l'instance est inférieur à 50. |
Plus ancienne transaction par âgepostgresql/vacuum/oldest_transaction_age |
Âge de la transaction la plus ancienne bloquant l'opération VACUUM. |
Archivage WALreplication/log_archive_success_count, replication/log_archive_failure_count |
Nombre de fichiers journaux d'écriture préalable dont l'archivage a abouti ou a échoué par minute. |
Utilisation des ID de transactionpostgresql/transaction_id_utilization |
Pourcentage d'ID de transaction utilisés dans l'instance. |
Nombre de connexions par nom d'applicationpostgresql/num_backends_by_application |
Nombre de connexions à l'instance Cloud SQL, regroupées par application. |
Lignes récupérées, lignes renvoyées et lignes écrites
|
Si la différence entre les lignes renvoyées et les lignes récupérées est si importante que leurs valeurs ne s'affichent pas à la même échelle, la valeur des lignes récupérées est également 0 car elle est négligeable par rapport à la valeur des lignes renvoyées. |
Taille des données temporairespostgresql/temp_bytes_written_count |
Quantité totale de données (en octets) utilisée pour exécuter des requêtes et exécuter des algorithmes de jointure et de tri. |
Fichiers temporairespostgresql/temp_files_written_count |
Nombre de fichiers temporaires utilisés pour l'exécution de la requête et l'exécution d'algorithmes de jointure et de tri. |
En outre, la métrique Cloud Logging, Journaux des entrées par gravité (logging.googleapis.com/log_entry_count), affiche le nombre total d'entrées de journal d'erreurs et d'avertissements.
Celles-ci sont extraites de postgres.log, qui est le journal de la base de données, et de pgaudit.log, qui contient des informations d'accès aux données.
Pour en savoir plus, consultez la section Métriques Cloud SQL.
Chronologie des événements
Le tableau de bord fournit les détails des événements suivants :
| Nom de l'événement | Description | Type d'opération |
|---|---|---|
Instance restart |
Redémarre l'instance Cloud SQL | RESTART |
Instance failover |
Démarre un basculement manuel d'une instance principale à haute disponibilité (HA) vers une instance de secours, qui devient l'instance principale. | FAILOVER |
Instance maintenance |
Indique que l'instance est en cours de maintenance. Les opérations de maintenance entraînent généralement l'indisponibilité de l'instance pendant une à trois minutes. | MAINTENANCE |
Instance backup |
Sauvegarde une instance. | BACKUP_VOLUME |
Instance update |
Met à jour les paramètres d'une instance Cloud SQL. | UPDATE |
Promote replica |
Promeut une instance dupliquée Cloud SQL. | PROMOTE_REPLICA |
Start replica |
Démarre la duplication sur une instance dupliquée avec accès en lecture Cloud SQL. | START_REPLICA |
Stop replica |
Arrête la duplication sur une instance dupliquée avec accès en lecture Cloud SQL. | STOP_REPLICA |
Recreate replica |
Recrée des ressources pour une instance dupliquée Cloud SQL. | RECREATE_REPLICA |
Create replica |
Crée une instance dupliquée Cloud SQL. | CREATE_REPLICA |
Data import |
Importe des données dans une instance Cloud SQL. | IMPORT |
Instance export |
Exporte les données d'une instance Cloud SQL vers un bucket Cloud Storage. | EXPORT |
Restore backup |
Restaure une sauvegarde d'instance Cloud SQL. L'utilisation de cette opération peut entraîner le redémarrage de votre instance. | RESTORE_VOLUME |