Auf dieser Seite wird die Notfallwiederherstellung in Cloud SQL vorgestellt.
Übersicht
In Google Cloudist die Datenbank-Notfallwiederherstellung darauf ausgelegt, die Aufrechterhaltung der Verarbeitung zu gewährleisten, insbesondere wenn eine Region ausfällt oder nicht verfügbar ist. Cloud SQL ist ein regionaler Dienst (wenn Cloud SQL für Hochverfügbarkeit konfiguriert ist). Wenn die Google Cloud Region, in der eine Cloud SQL-Datenbank gehostet wird, nicht mehr verfügbar ist, ist die Cloud SQL-Datenbank ebenfalls nicht mehr verfügbar.
Für die weitere Verarbeitung müssen Sie die Datenbank so schnell wie möglich in einer sekundären Region verfügbar machen. Der Notfallwiederherstellungs-Plan erfordert, dass Sie ein regionenübergreifendes Lesereplikat in Cloud SQL konfigurieren. Ein Failover, der auf dem Export/Import oder der Sicherung/Wiederherstellung basiert, ist ebenfalls möglich, benötigt jedoch mehr Zeit, insbesondere bei großen Datenbanken.
Die folgenden geschäftlichen Szenarien sind Beispiele, die eine regionsübergreifende Failover-Konfiguration garantieren:
- Das Service Level Agreement für die Geschäftsanwendung ist größer als das regionale Cloud SQL-Service Level Agreement (99,99% Verfügbarkeit, je nach Cloud SQL-Version). Durch ein Failover in eine andere Region können Sie einen Ausfall minimieren.
- Alle Ebenen der Geschäftsanwendung sind bereits multiregional und können bei einem Ausfall der Region weiter verarbeitet werden. Die regionenübergreifende Failover-Konfiguration sorgt für die kontinuierliche Verfügbarkeit einer Datenbank.
- Das erforderliche Recovery Time Objective (RTO) und das Recovery Point Objective (RPO) sind in Minuten statt in Stunden angegeben. Ein Failover in eine andere Region ist schneller als das Neuerstellen einer Datenbank.
Im Allgemeinen gibt es zwei Varianten für den DR-Prozess:
- Eine Datenbank kann nicht auf eine sekundäre Region übertragen werden. Sobald die Datenbank bereit ist und von einer Anwendung verwendet wird, wird sie zur neuen primären Datenbank und behält die primäre Datenbank.
- Eine Datenbank führt kein Failover auf eine sekundäre Region durch, greift aber nach dem Ausfall der primären Region wieder auf die primäre Region zurück.
In dieser Übersicht zur Notfallwiederherstellung für Google Cloud SQL-Datenbanken wird die zweite Variante beschrieben. Hierbei wird eine ausgefallene Datenbank wiederhergestellt und greift auf die primäre Region zurück. Dieser Notfallwiederherstellungs-Prozess ist insbesondere für Datenbanken relevant, die aufgrund der Netzwerklatenz in der primären Region laufen müssen oder weil einige Ressourcen nur in der primären Region verfügbar sind. Bei dieser Variante wird die Datenbank in der sekundären Region nur für die Dauer des Ausfalls in der primären Region ausgeführt.
Notfallwiederherstellungsarchitektur
Das folgende Diagramm zeigt die minimale Architektur, die die Datenbank-DR für eine Cloud SQL-Instanz für hohe Verfügbarkeit unterstützt:
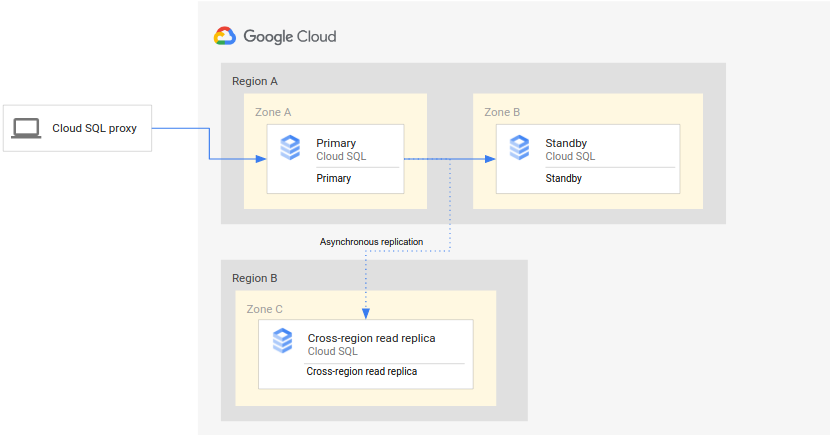
Die Architektur funktioniert so:
- Zwei Instanzen von Cloud SQL (eine primäre Instanz und eine Standby-Instanz) befinden sich in zwei separaten Zonen innerhalb einer einzelnen Region (der primären Region). Die Instanzen werden mithilfe von regionalen nichtflüchtigen Speichern synchronisiert.
- Eine Instanz von Cloud SQL (das regionenübergreifende Lesereplikat) befindet sich in einer zweiten Region (sekundäre Region). Bei DR wird das regionenübergreifende Lesereplikat mithilfe der asynchronen Replikation mit der primären Instanz synchronisiert (mithilfe der Lesereplikation).
Die primäre Instanz und die Standby-Instanz teilen sich das gleiche regionale Laufwerk, sodass ihre Status identisch sind.
Da diese Konfiguration eine asynchrone Replikation verwendet, kann es vorkommen, dass das regionenübergreifende Lesereplikat hinter der primären Instanz zurückliegt. Wenn ein Failover auftritt, ist der RPO-Wert des regionenübergreifenden Lesereplikats wahrscheinlich ungleich null.
Notfallwiederherstellungsprozess
Der Notfallwiederherstellungsprozess beginnt, wenn die primäre Region nicht mehr verfügbar ist. Wenn Sie die Verarbeitung in einer sekundären Region fortsetzen möchten, lösen Sie ein Failover der primären Instanz aus, indem Sie ein regionenübergreifendes Lesereplikat hochstufen. Der DR-Prozess umfasst eine manuelle oder automatische Ausführung der operativen Schritte, um den regionalen Ausfall zu minimieren und eine laufende primäre Instanz in einer sekundären Region einzurichten.
Das folgende Diagramm zeigt den DR-Prozess:
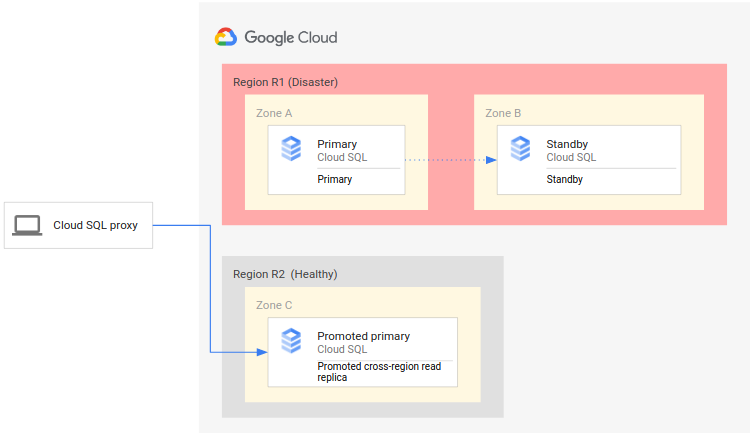
Der Prozess besteht aus den folgenden Schritten:
- Die primäre Region (R1), die die primäre Instanz ausführt, ist nicht mehr verfügbar.
- Das operative Team erkennt und bestätigt offiziell den Notfall und entscheidet, ob ein Failover erforderlich ist.
- Wenn ein Failover erforderlich ist, können Sie das regionenübergreifende Lesereplikat in der sekundären Region (R2) zur neuen primären Instanz hochstufen.
- Clientverbindungen werden neu konfiguriert, um die Verarbeitung auf der neuen primären Instanz fortzusetzen und in R2 auf die primäre Instanz zuzugreifen.
Im Rahmen dieses grundlegenden Prozesses wird wieder eine funktionierende primäre Datenbank eingerichtet. Es wird jedoch keine vollständige DR-Architektur eingerichtet, bei der die neue primäre Instanz selbst eine Standby-Instanz und ein regionenübergreifendes Lesereplikat hat.
Ein vollständiger DR-Prozess stellt sicher, dass die einzelne Instanz, die neue primäre Instanz, für HA aktiviert ist und über ein regionenübergreifendes Lesereplikat verfügt. Ein vollständiger DR-Prozess bietet auch ein Fallback auf die ursprüngliche Bereitstellung in der ursprünglichen primären Region.
Failover auf sekundäre Region ausführen
Ein vollständiger DR-Prozess ergänzt den grundlegenden DR-Prozess durch Schritte, mit denen eine vollständige DR-Architektur nach einem Failover eingerichtet wird. Das folgende Diagramm zeigt eine vollständige Datenbank-DR-Architektur nach dem Failover:
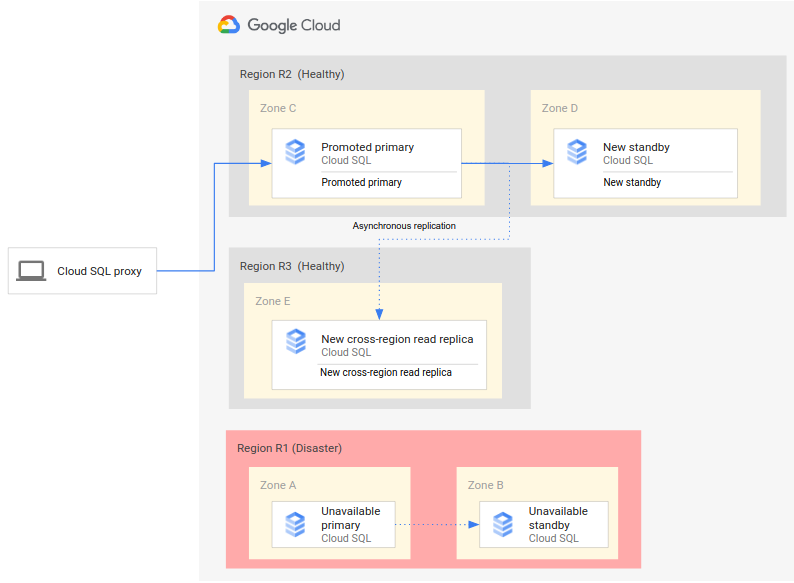
Der vollständige Datenbank-DR-Prozess umfasst die folgenden Schritte:
- Die primäre Region (R1), die die primäre Datenbank ausführt, ist dann nicht mehr verfügbar.
- Das operative Team erkennt und bestätigt offiziell den Notfall und entscheidet, ob ein Failover erforderlich ist.
- Wenn ein Failover erforderlich ist, können Sie das regionenübergreifende Lesereplikat in der sekundären Region (R2) zur neuen primären Instanz hochstufen.
- Clientverbindungen werden neu konfiguriert, um auf die neue primäre Instanz (R2) zuzugreifen und sie zu verarbeiten.
- Eine neue Standby-Instanz wird in R2 erstellt und gestartet und der primären Instanz hinzugefügt. Die Standby-Instanz befindet sich in einer anderen Zone als die primäre Instanz. Die primäre Instanz ist jetzt hochverfügbar, weil für sie eine Standby-Instanz erstellt wurde.
- In einer dritten Region (R3) wird ein neues regionenübergreifendes Lesereplikat erstellt und der primären Instanz hinzugefügt. An diesem Punkt wird eine vollständige Architektur zur Notfallwiederherstellung neu erstellt und betrieben.
Wenn die ursprüngliche primäre Region (R1) verfügbar ist, bevor Schritt 6 implementiert wurde, kann das regionenübergreifende Lesereplikat in Region R1 und nicht in Region R3 platziert werden. In diesem Fall ist das Fallback auf die ursprüngliche primäre Region (R1) weniger komplex und erfordert weniger Schritte.
Split-Brain-Status vermeiden
Ein Ausfall der primären Region (R1) bedeutet nicht, dass die ursprüngliche primäre Instanz und ihre Standby-Instanz automatisch heruntergefahren, entfernt oder anderweitig zugänglich gemacht werden, wenn R1 wieder verfügbar ist. Wenn R1 verfügbar ist, können Clients Daten (auch nach Unfall) auf der ursprünglichen primären Instanz lesen und schreiben. In diesem Fall kann eine Split-Brain-Situation entwickelt werden, bei der einige Clients auf veraltete Daten in der alten primären Datenbank zugreifen. Andere Clients greifen auf neue Daten in der neuen primären Datenbank zu, was zu Problemen in Ihrem Unternehmen führt.
Achten Sie darauf, dass Clients nicht mehr auf die ursprüngliche primäre Instanz zugreifen können, sobald R1 verfügbar ist. So vermeiden Sie eine Teilungszeit für Daten. Idealerweise sollten Sie die ursprüngliche primäre Instanz nicht mehr zugänglich machen, bevor Clients die neue primäre Instanz verwenden. Löschen Sie dann die ursprüngliche primäre Instanz, sobald Sie nicht mehr darauf zugreifen können.
Erste Sicherung nach einem Failover erstellen
Wenn Sie das regionenübergreifende Lesereplikat in einem Failover zur neuen primären Datenbank hochstufen, werden die Transaktionen in der neuen primären Datenbank möglicherweise nicht vollständig mit Transaktionen aus der ursprünglichen primären Datenbank synchronisiert. Daher sind diese Transaktionen in der neuen Instanz nicht verfügbar.
Als Best Practice empfehlen wir, dass Sie sofort die neue primäre Instanz zu Beginn des Failovers sichern und dann wieder auf die Datenbank zugreifen. Diese Sicherung stellt einen konsistenten, bekannten Status zum Zeitpunkt des Failovers dar. Solche Sicherungen können für rechtliche Zwecke oder für die Wiederherstellung eines bekannten Zustands wichtig sein, wenn Clients Probleme beim Zugriff auf die neue primäre Datenbank haben.
Zurück zur ursprünglichen primären Region
Wie bereits beschrieben, umfasst dieses Dokument die Schritte, die auf die ursprüngliche Region (R1) zurückgehen. Der Fallback-Prozess umfasst zwei verschiedene Versionen.
- Wenn Sie das neue regionenübergreifende Lesereplikat in einer tertiären Region (R3) erstellt haben, müssen Sie ein weiteres (sekundäres) regionenübergreifendes Lesereplikat in der primären Region (R1) erstellen.
- Wenn Sie das neue regionenübergreifende Lesereplikat in der primären Region (R1) erstellt haben, müssen Sie kein weiteres regionenübergreifendes Lesereplikat in R1 erstellen.
Nachdem das regionenübergreifende Lesereplikat in R1 vorhanden ist, kann die Cloud SQL-Instanz auf R1 zurückgreifen. Da dieses Fallback manuell ausgelöst wird und nicht aufgrund eines Ausfalls besteht, können Sie für diese Wartungsaktivität einen geeigneten Tag und eine geeignete Uhrzeit auswählen.
Um eine vollständige DR mit einem primären, Standby- und regionenübergreifenden Lesereplikat zu erreichen, benötigen Sie daher zwei Failovers. Das erste Failover wird durch den Ausfall ausgelöst (ein wirkliches Failover) und das zweite Failover stellt die Startbereitstellung wieder her (ein Fallback).
Ein Fallback auf die ursprüngliche primäre Region (R1) besteht aus den folgenden Schritten:
- Hochstufen des neu erstellten regionenübergreifenden Replikats in der ursprünglichen primären Region (R1).
- Wenn die hochgestufte Instanz nicht ursprünglich als HA-Replikat erstellt wurde, aktivieren Sie HA auf der Instanz zum Schutz vor zonalen Fehlern.
- Konfigurieren Sie Ihre Anwendungen neu, sodass eine Verbindung zur neuen primären Instanz hergestellt werden kann.
- Erstellen Sie ein regionenübergreifendes Replikat für die neue primäre Instanz in der DR-Region (R2).
- (Optional) Bereinigen Sie die primäre Instanz in der DR-Region (R2), um die Ausführung mehrerer unabhängiger primäre Instanzen zu vermeiden.
Erweiterte Notfallwiederherstellung
Wenn Sie Cloud SQL Enterprise Plus verwenden, können Sie die erweiterte Notfallwiederherstellung nutzen. Die erweiterte Notfallwiederherstellung vereinfacht die Wiederherstellung und den Fallback nach einem regionenübergreifenden Failover. Wie unter Notfallwiederherstellungsprozess beschrieben, entfernen Sie bei der Notfallwiederherstellung die Verbindung zwischen der ausgefallenen Region der alten primären Instanz und der Betriebsregion der neuen primären Instanz. ausgeführt werden. Mit der Notfallwiederherstellung müssen Sie eine Reihe manueller Fallback-Schritte ausführen, um Verbindungen zur ursprünglichen Bereitstellungsregion und zur alten primären Instanz wiederherzustellen.
Bei der erweiterten Notfallwiederherstellung können Sie bei einem regionalen Ausfall ein Replikat-Failover aufrufen. Beim Replikat-Failover stufen Sie ein regionenübergreifendes Lesereplikat ähnlich wie bei der regulären DR hoch, mit der Ausnahme, dass Sie das festgelegte Replikat der Notfallwiederherstellung (Disaster Recovery, DR) hochstufen. Das Hochstufen des DR-Replikats erfolgt sofort.
Anstatt die alte primäre Instanz zu entfernen, bleibt die Instanz Teil der asynchronen Replikationstopologie von Cloud SQL. Die alte primäre Instanz (Instanz A) wird schließlich zu einem Replikat des DR-Replikats (Instanz B), nachdem das DR-Replikat zur neuen primären Instanz hochgestuft wurde.
Nachdem die alte primäre Instanz (A) in ein Replikat umgewandelt wurde, können Sie den letzten Schritt der erweiterten DR ausführen. Sie können Ihre Cloud SQL-Bereitstellung in den ursprünglichen Zustand zurücksetzen und die alte primäre Instanz (A) auf ihre vorherige Rolle als primäre Instanz ohne Datenverlust wiederherstellen. Für diese Wiederherstellung ohne Datenverlust der alten primären Instanz (A) können Sie den Switchover-Vorgang verwenden. Wenn Sie ein Switchover ausführen, tritt kein Datenverlust auf, da die primäre Instanz (B) im Lesemodus verbleibt, bis das festgelegte DR-Replikat (A) die primäre Instanz (B) aufholt. Nachdem das DR-Replikat (A) alle Replikationsupdates erhalten hat, übernimmt das DR-Replikat (A) die Rolle der primären Instanz, während die vorherige primäre Instanz (B) automatisch als DR-Replikat der aktuellen primären Instanz (A) neu konfiguriert wird. Die Instanzen werden in ihre ursprünglichen Rollen zurückversetzt. Dadurch wird die Topologie in den ursprünglichen Zustand vor der Notfallwiederherstellung und dem Replikat-Failover zurückgesetzt.
Während der erweiterten Notfallwiederherstellung behalten alle Instanzen, die sowohl am Replikat-Failover als auch an Switchover-Vorgängen beteiligt sind, ihre IP-Adressen bei.
Sie können den Switchover-Vorgang der erweiterten Notfallwiederherstellung auch verwenden, um routinemäßige DR-Aufschlüsselungen durchzuführen, um Ihre Cloud SQL-Topologie für den regionenübergreifenden Failover zu testen und vorzubereiten, bevor ein Notfall eintritt. Wenn tatsächlich ein Notfall eintritt, können Sie das bereits getestete regionenübergreifende Replikat-Failover ausführen.
Replikat für die Notfallwiederherstellung
Als erforderliche Komponente der erweiterten Notfallwiederherstellung hat das DR-Replikat die folgenden Eigenschaften:
- Ein DR-Replikat ist ein direkt verbundenes regionenübergreifendes Lesereplikat.
- Sie können die Kennzeichnung des DR-Replikats mehrmals ändern.
- Sie können die Kennzeichnung des DR-Replikats jederzeit ändern, außer während eines Switchover- oder Replikat-Failover-Vorgangs.
Außerdem empfehlen wir Folgendes, um den RTO nach der Verwendung der erweiterten Notfallwiederherstellung zu reduzieren:
- Konfigurieren Sie das DR-Replikat mit derselben Größe wie die primäre Instanz.
- Wenn für die primäre Instanz Hochverfügbarkeit aktiviert ist, empfehlen wir, Hochverfügbarkeit auch für das DR-Replikat zu aktivieren. Prüfen Sie dazu zuerst, ob Hochverfügbarkeit für die primäre Instanz aktiviert ist. Führen Sie dann den Switchover zum DR-Replikat aus. Nach Abschluss des Switchovers aktivieren Sie die Hochverfügbarkeit für die neue primäre Instanz. Anschließend können Sie wieder zur alten primären Instanz wechseln. Das DR-Replikat behält seine HA-Konfiguration auch dann bei, wenn es wieder zu einem Replikat wird.
Replikat-Failover
Zusammenfassend lässt sich sagen, dass ein Replikat-Failover aus den folgenden Ereignissen besteht:
- Sie erstellen ein DR-Replikat und weisen es zu.
- Die primäre Region ist nicht mehr verfügbar.
- Sie führen das Replikat-Failover auf das DR-Replikat aus.
- Der Schreibendpunkt wird aktualisiert und verweist auf die neue primäre Instanz.
- Wenn die ursprüngliche primäre Instanz wieder online ist, wird sie zu einem Lesereplikat der neuen primären Instanz.
- Mit dem Switchover-Vorgang können Sie die ursprüngliche Topologie Ihrer Bereitstellung wiederherstellen.
Klicken Sie auf die folgenden Tabs, um die Details und Diagramme eines Replikat-Failover-Vorgangs aufzurufen.
DR-Replikat zuweisen
Bevor Sie ein Replikat-Failover ausführen, haben Sie der primären Instanz ein DR-Replikat zugewiesen und den Prozess möglicherweise über einen Switchover getestet.

Ausfall tritt auf
Die primäre Region, die die primäre Datenbank ausführt, ist dann nicht mehr verfügbar.

Replikat-Failover
Nachdem Sie festgestellt haben, dass eine Notfallwiederherstellung erforderlich ist, führen Sie ein Replikat-Failover auf das regionenübergreifende DR-Replikat aus.
Das regionenübergreifende DR-Replikat wird sofort zur primären Instanz und beginnt, eingehende Lese- und Schreibvorgänge zu akzeptieren. Der Schreibendpunkt wird aktualisiert und verweist auf die neue primäre Instanz.

Ursprüngliche primäre Instanz wird zum Replikat
Nachdem das Replikat hochgestuft wurde, prüft Cloud SQL regelmäßig, ob die ursprüngliche primäre Instanz wieder online ist. Wenn die ursprüngliche primäre Instanz online ist, erstellt Cloud SQL die alte primäre Instanz als Replikat der hochgestuften Instanz neu. Die alte primäre Instanz behält ihre IP-Adresse bei.

Failback zum Original
Nachdem Sie ein Replikat-Failover durchgeführt haben, können Sie die primäre Instanz in Ihrer ursprünglichen Region wiederherstellen. Führen Sie dazu den Switchover-Vorgang aus und kehren Sie dasselbe DR-Replikat und dasselbe primäre Instanzpaar um.

Wechseln
Zusammenfassend lässt sich sagen, dass ein Switchover-Vorgang aus den folgenden Ereignissen besteht:
- Sie erstellen ein DR-Replikat und weisen es zu.
- Sie initiieren eine Umstellung.
- Wenn die Replikationsverzögerung auf null sinkt, beginnt die neue primäre Instanz, eingehende Verbindungen zu akzeptieren.
- Die alte primäre Instanz wird zu einem Lesereplikat.
- Wenn ein DNS-Schreibendpunkt verwendet wird, wird er aktualisiert, sodass er auf die neue primäre Instanz verweist.
Klicken Sie auf die folgenden Tabs, um die Details und Diagramme eines Switchover-Vorgangs aufzurufen.
DR-Replikat zuweisen
Bevor Sie den *Switchover*-Vorgang starten, müssen Sie der primären Instanz ein DR-Replikat zuweisen.
Prüfen Sie, ob die primäre Instanz fehlerfrei ist. Sie können eine Umstellung nur ausführen, wenn sowohl die primäre Instanz als auch das DR-Replikat online sind.
Umstellung initiieren
Sie initiieren die Umstellung. Wenn Sie einen Switchover initiieren, akzeptiert die primäre Instanz keine Schreibvorgänge mehr und wird schreibgeschützt. Cloud SQL wartet, bis die Transaktionslogs in Cloud Storage kopiert wurden. Das festgelegte DR-Replikat holt die primäre Instanz auf.
Wenn die Replikationsverzögerung auf null sinkt, wird das DR-Replikat zur neuen primären Instanz hochgestuft. Die neue primäre Instanz beginnt, eingehende Verbindungen zu akzeptieren, einschließlich Lese- und Schreibvorgängen der Anwendung.
Endpunkt aktualisiert
Nachdem das DR-Replikat zur neuen primären Instanz hochgestuft wurde, wird der DNS-Schreibendpunkt aktualisiert und verweist auf die neue primäre Instanz. Wenn Sie keinen DNS-Schreibendpunkt verwenden, müssen Sie Ihre Anwendungen so konfigurieren, dass sie auf die IP-Adresse der neuen primären Instanz verweisen.
Die alte primäre Instanz wird als Lesereplikat neu konfiguriert.
PITR wird für die neue primäre Instanz automatisch aktiviert. PITR ist erst nach der ersten automatischen Sicherung möglich.
Schreibendpunkt
Ein Schreibendpunkt ist ein globaler DNS-Name (Domain Name Service), der automatisch in die IP-Adresse der aktuellen primären Instanz aufgelöst wird. Dieser Endpunkt leitet eingehende Verbindungen im Falle eines Replikat-Failovers oder ‑Switchovers automatisch an die neue primäre Instanz weiter. Sie können den Schreibendpunkt in einem SQL-Verbindungsstring anstelle einer IP-Adresse verwenden. Wenn Sie einen Schreibendpunkt verwenden, müssen Sie bei einem regionalen Ausfall keine Änderungen an der Anwendungsverbindung vornehmen.
Für einen Schreibendpunkt muss die Cloud DNS API in dem Projekt aktiviert sein, in dem Sie Ihre primäre Instanz der Cloud SQL Enterprise Plus-Edition erstellen oder in dem sich Ihre vorhandene primäre Instanz befindet. Wenn Sie eine Cloud SQL Enterprise Plus-Instanz mit einer privaten IP-Adresse und autorisierten Netzwerken erstellen, generiert Cloud SQL automatisch einen Schreibendpunkt für die Instanz. Wenn Sie bereits eine primäre Instanz von Cloud SQL Enterprise Plus haben, generiert Cloud SQL den Schreibendpunkt, wenn Sie das DR-Replikat erstellen (ein regionenübergreifendes Replikat, das Sie für die primäre Instanz festlegen). Wenn sich die primäre Instanz aufgrund eines Switchover- oder Replikat-Failover-Vorgangs ändert, weist Cloud SQL den Schreibendpunkt dem DR-Replikat zu, wenn das DR-Replikat zur neuen primären Instanz wird.
Weitere Informationen zum Herstellen einer Verbindung zu einer Instanz über einen Schreibendpunkt finden Sie unter Verbindung zu einer Instanz über einen Schreibendpunkt herstellen.
Nächste Schritte
- Erweiterte Notfallwiederherstellung (Disaster Recovery, DR) verwenden
- Referenzarchitekturen, Diagramme, Anleitungen und Best Practices zu Google Cloudkennenlernen. Weitere Informationen zu Cloud Architecture Center