
Spanner
Base de données permanente à évolutivité pratiquement illimitée
Créez des applications intelligentes à l'aide d'une base de données unique qui regroupe les charges de travail relationnelles, de graphes, de clé-valeur et de recherche. Aucune intervalle de maintenance n'est synonyme d'interruption des applications critiques.
De plus, les nouveaux clients Google Cloud bénéficient de 300 $ de crédits.

Fonctionnalités
Multimodèle : une base de données, de nombreuses possibilités
Les fonctionnalités multimodèles de Spanner vous permettent de créer des applications intelligentes basées sur l'IA sur vos données opérationnelles relationnelles et NoSQL en exploitant l'intégration native de Vertex AI, Spanner Graph pour interroger des relations complexes, la recherche vectorielle pour la recherche sémantique, la recherche plein texte intégrée, le tout avec une interopérabilité "vraiment zéro ETL". Cette approche unifiée élimine les silos de données, réduit les coûts, diminue les points de contact opérationnels et de sécurité, et garantit la cohérence des données dans tous les modèles.

Une évolutivité facilitée
Rêvez en grand, commencez petit et évoluez sans effort au rythme de vos besoins. Spanner gère facilement les ensembles de données en croissance et les charges de travail exigeantes grâce à son évolutivité horizontale en termes de lecture et d'écriture. Le fractionnement automatique des bases de données assure une distribution optimale des données, tandis que le partitionnement géographique les rapproche de vos utilisateurs pour réduire la latence. Profitez de performances élevées et constantes avec le traitement des requêtes isolé des charges de travail grâce à Spanner Data Boost, même en période de pic de demande.

Disponibilité permanente
Assurez-vous que vos applications sont toujours disponibles et prêtes à servir vos utilisateurs. Spanner offre une disponibilité pouvant atteindre 99,999 % grâce à une maintenance automatisée et à des options de déploiement flexibles. Choisissez une configuration régionale, birégionale ou multirégionale en fonction de vos besoins spécifiques en termes de disponibilité et de tolérance aux pannes.

Transactions cohérentes garanties
Dites adieu aux incohérences de données et à la complexité de leur gestion. Spanner garantit une cohérence transactionnelle forte, ce qui signifie que chaque lecture reflète les mises à jour les plus récentes, quelle que soit la taille ou la distribution de vos données. Développez en toute confiance, en sachant que vos applications disposent toujours d'une vue cohérente de vos données.
Sécurité et conformité fiables
Confiez vos données à une plate-forme sécurisée et conforme avec Spanner. Bénéficiez d'une administration et d'un contrôle centralisés avec Database Center, ce qui simplifie la gestion de vos bases de données cloud. Spanner offre des fonctionnalités de sécurité et de contrôle de niveau professionnel, y compris le chiffrement des données au repos et en transit, la gestion précise des accès via Identity and Access Management (IAM), et la conformité aux normes du secteur. Protégez davantage vos données grâce à des fonctionnalités de sauvegarde et de restauration robustes, y compris la restauration à un instant donné, pour une tranquillité d'esprit opérationnelle.
Comparaison des bases de données
| Attribut de base de données | Autre BDD relationnelle | Autre BDD non-relationnelle | Spanner |
|---|---|---|---|
Schéma | Statique | Dynamique | Dynamique |
SQL | Oui | Non | Oui (PostgreSQL, Google SQL) |
Transactions | ACID (atomicité, cohérence, isolation, durabilité) | À terme | Strong-ACID avec tri TrueTime |
Évolutivité | Vertical (utilisez une machine de plus grande taille) | Fonctionnement horizontal (ajoutez des machines) | Horizontale |
Disponibilité | Basculement (temps d'arrêt) | Élevée | SLA à taux de disponibilité élevé de 99,999 % |
Duplication | Configurable | Configurable | Automatique |
Gartner® a classé Spanner au premier rang pour le cas d'utilisation des transactions légères. Télécharger le rapport complet
Schéma
Statique
Dynamique
Dynamique
Transactions
ACID
(atomicité, cohérence, isolation, durabilité)
À terme
Strong-ACID
avec tri TrueTime
Évolutivité
Vertical
(utilisez une machine de plus grande taille)
Fonctionnement horizontal
(ajoutez des machines)
Horizontale
Disponibilité
Basculement (temps d'arrêt)
Élevée
SLA à taux de disponibilité élevé de 99,999 %
Duplication
Configurable
Configurable
Automatique
Gartner® a classé Spanner au premier rang pour le cas d'utilisation des transactions légères. Télécharger le rapport complet
Fonctionnement
Les instances Spanner fournissent des capacités de calcul et de stockage dans une ou plusieurs régions. Une horloge distribuée appelée TrueTime garantit que les transactions sont fortement cohérentes, même dans plusieurs régions. Les données sont automatiquement "divisées" pour l'évolutivité, puis répliquées via un schéma synchrone basé sur Paxos pour la disponibilité.
Les instances Spanner fournissent des capacités de calcul et de stockage dans une ou plusieurs régions. Une horloge distribuée appelée TrueTime garantit que les transactions sont fortement cohérentes, même dans plusieurs régions. Les données sont automatiquement "divisées" pour l'évolutivité, puis répliquées via un schéma synchrone basé sur Paxos pour la disponibilité.

Utilisations courantes
Migration et modernisation
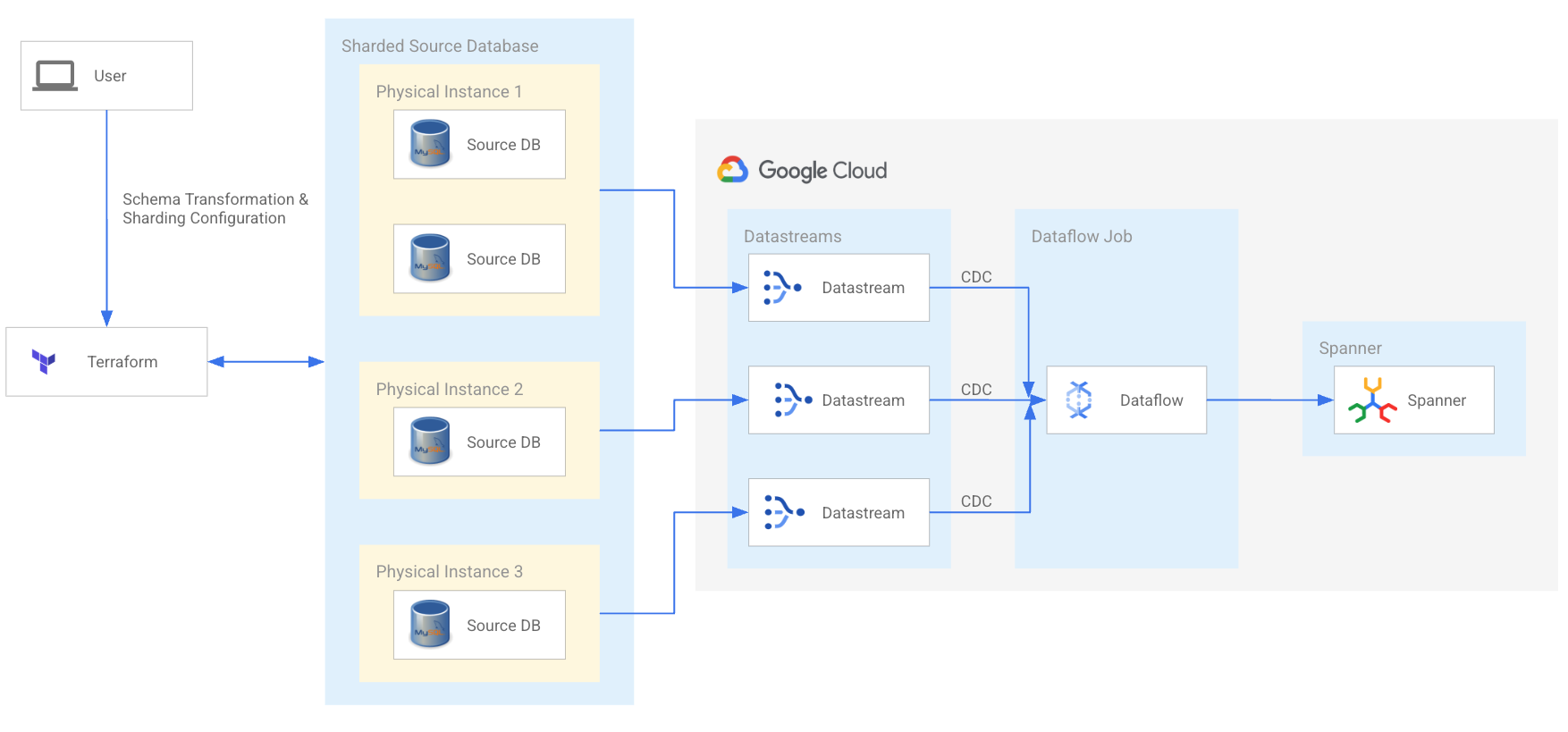
Simplifiez la modernisation de MySQL et de Cassandra
Simplifiez la modernisation de MySQL et de Cassandra
Modernisez vos charges de travail MySQL et Cassandra partitionnées pour booster vos équipes de développement et vous préparer à la prochaine phase de croissance. Profitez de l'outil de migration Spanner Open Source et d'un réseau de partenaires technologiques et de services qualifiés qui peuvent simplifier votre migration.
Tutoriels, guides de démarrage rapide et ateliers
Simplifiez la modernisation de MySQL et de Cassandra
Simplifiez la modernisation de MySQL et de Cassandra
Modernisez vos charges de travail MySQL et Cassandra partitionnées pour booster vos équipes de développement et vous préparer à la prochaine phase de croissance. Profitez de l'outil de migration Spanner Open Source et d'un réseau de partenaires technologiques et de services qualifiés qui peuvent simplifier votre migration.
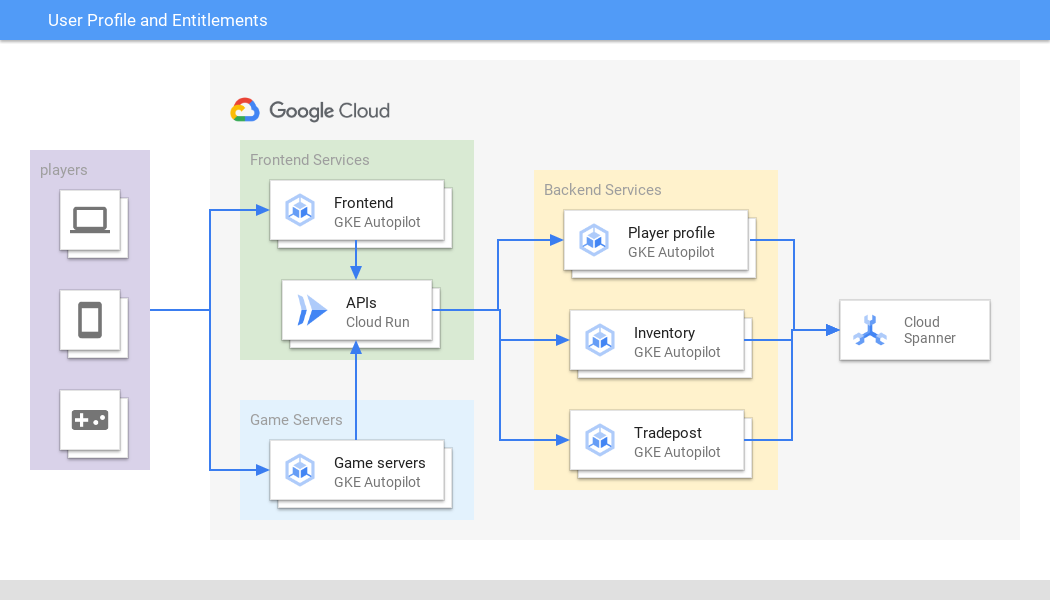
Profil utilisateur et droits d'accès
Gérez les données utilisateur critiques en toute sécurité à n'importe quelle échelle
Tutoriels, guides de démarrage rapide et ateliers
Gérez les données utilisateur critiques en toute sécurité à n'importe quelle échelle
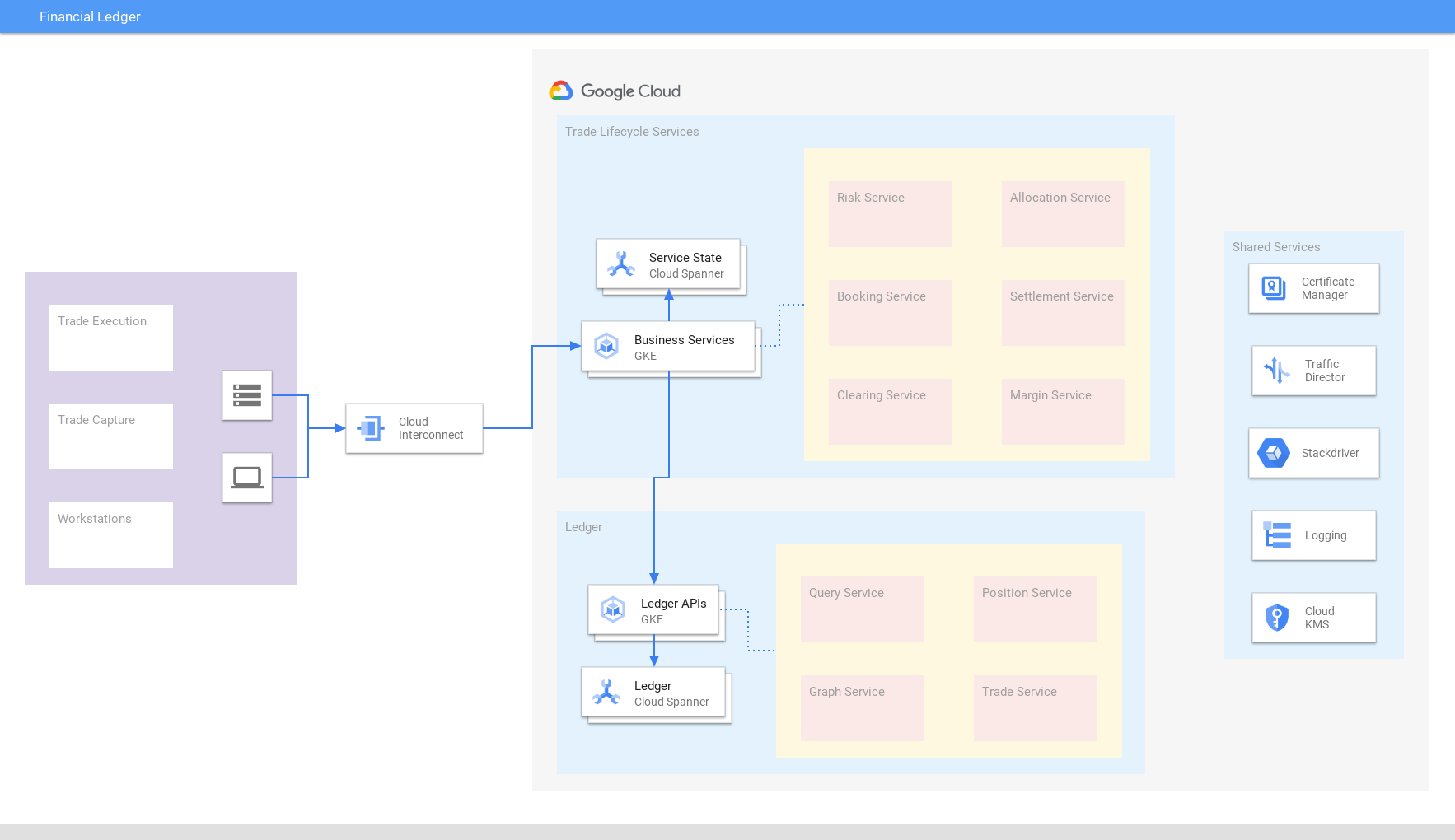
Registre financier
Profitez d'une vue à jour et cohérente des transactions mondiales
Unifiez les transactions, les échanges, les règlements et les positions dans le monde entier au sein d'un registre consolidé basé sur Spanner, qui garantit la cohérence externe et l'évolutivité. La consolidation des données permet de s'adapter rapidement à l'évolution des conditions du marché et aux exigences réglementaires. De manière similaire, des entreprises de vente au détail/d'e-commerce utilisent Spanner pour le registre d'inventaire.
Tutoriels, guides de démarrage rapide et ateliers
Profitez d'une vue à jour et cohérente des transactions mondiales
Unifiez les transactions, les échanges, les règlements et les positions dans le monde entier au sein d'un registre consolidé basé sur Spanner, qui garantit la cohérence externe et l'évolutivité. La consolidation des données permet de s'adapter rapidement à l'évolution des conditions du marché et aux exigences réglementaires. De manière similaire, des entreprises de vente au détail/d'e-commerce utilisent Spanner pour le registre d'inventaire.
Effectuer des opérations bancaires en ligne
Proposez une expérience interactive disponible en permanence pour les expériences numériques
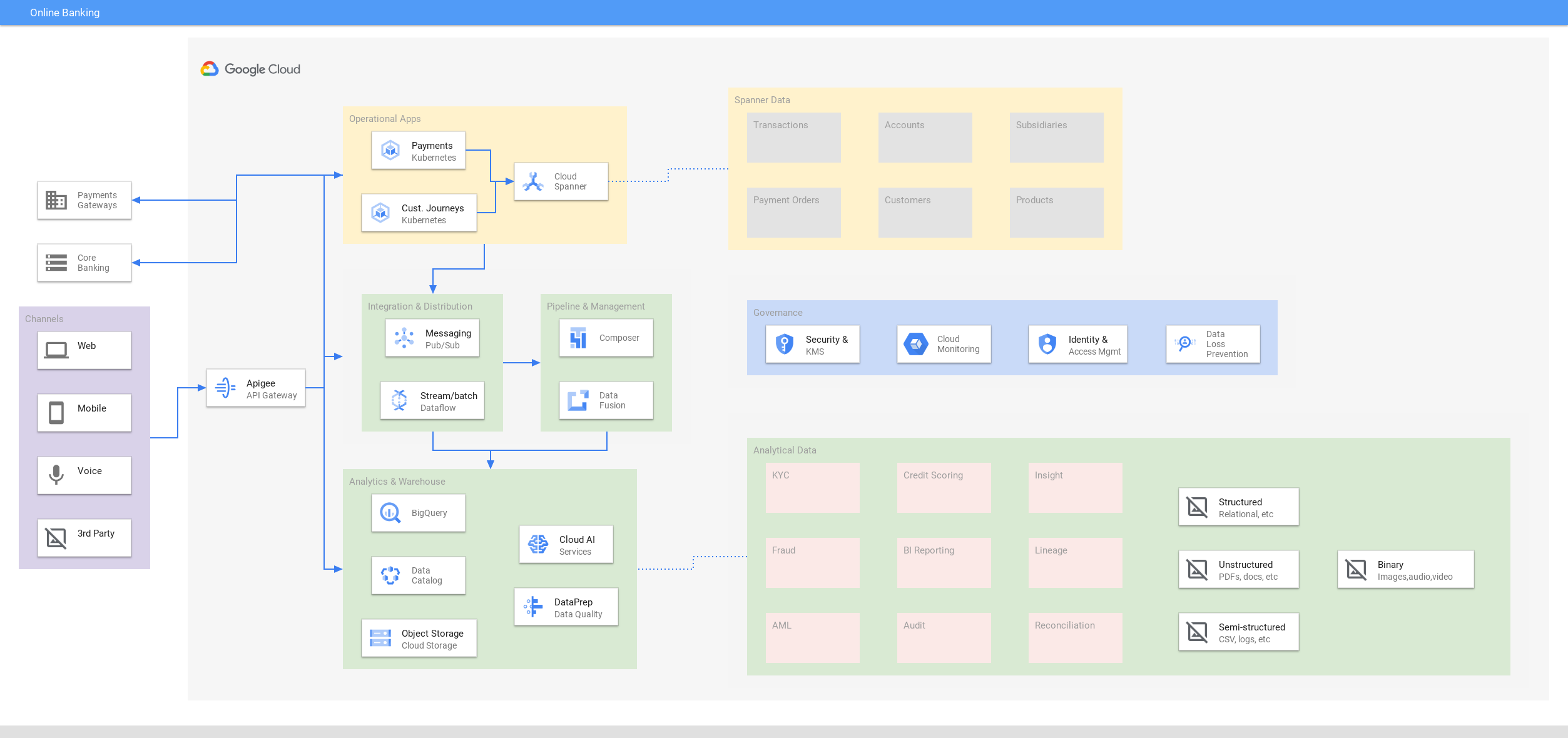
Tutoriels, guides de démarrage rapide et ateliers
Proposez une expérience interactive disponible en permanence pour les expériences numériques
Programmes de fidélité et promotions
Personnalisez les expériences avec des mises à jour en temps réel
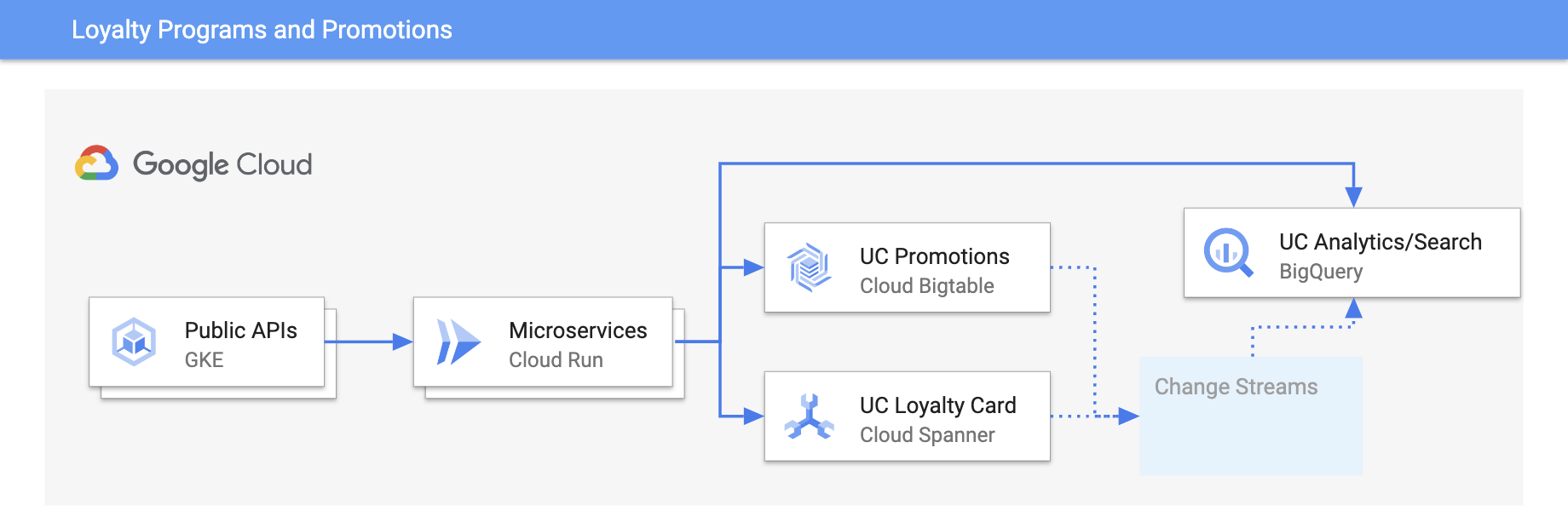
Tutoriels, guides de démarrage rapide et ateliers
Personnalisez les expériences avec des mises à jour en temps réel
Gestion d'inventaire omnicanal
Offrez une vue cohérente sur plusieurs canaux et applications
Spanner fournit une source de référence unique à hautes performances pour l'inventaire et les commandes de vente au détail sur différents canaux (en ligne, en magasin, en centre de distribution, etc.), et pour l'expédition afin de mettre en correspondance l'inventaire et la demande, ce qui permet d'améliorer l'expérience client et la rentabilité.Des éditeurs de jeux vidéo utilisent également Spanner pour stocker des données d'inventaire intrajeu.
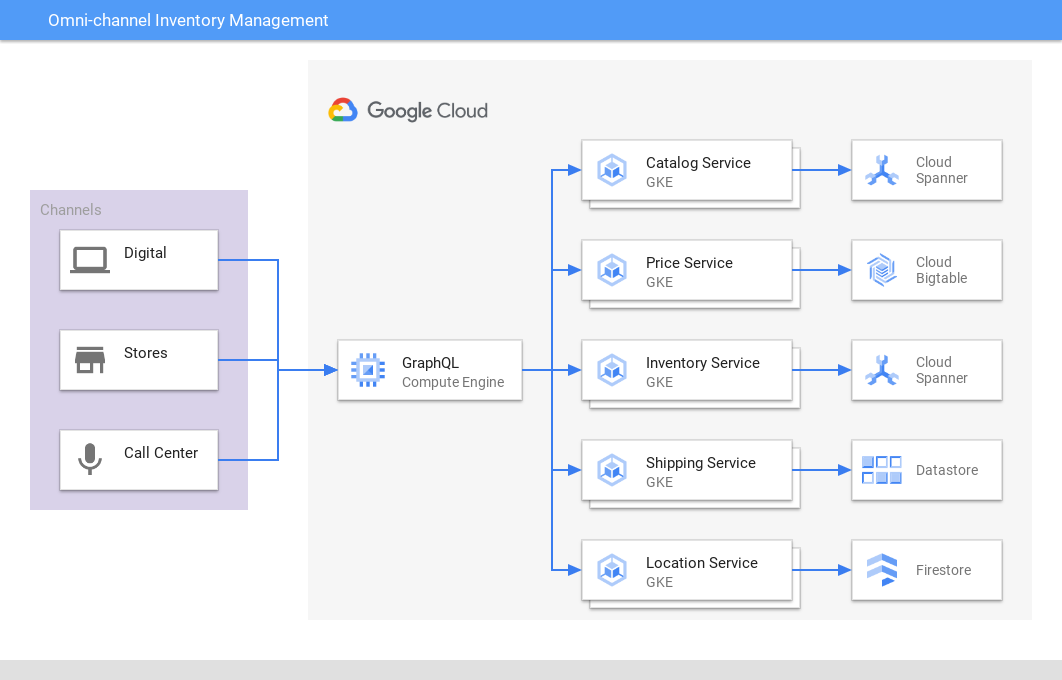
Tutoriels, guides de démarrage rapide et ateliers
Offrez une vue cohérente sur plusieurs canaux et applications
Spanner fournit une source de référence unique à hautes performances pour l'inventaire et les commandes de vente au détail sur différents canaux (en ligne, en magasin, en centre de distribution, etc.), et pour l'expédition afin de mettre en correspondance l'inventaire et la demande, ce qui permet d'améliorer l'expérience client et la rentabilité.Des éditeurs de jeux vidéo utilisent également Spanner pour stocker des données d'inventaire intrajeu.
Knowledge Graph
Détecter les relations et les connexions cachées dans vos données
Détecter les relations et les connexions cachées dans vos données
Avec Spanner Graph, vous pouvez développer des Knowledge Graphs qui capturent les connexions complexes entre les entités, représentées par des nœuds, et leurs relations, représentées par des arêtes. Ces connexions fournissent un contexte riche, ce qui fait des Knowledge Graphs un outil précieux pour développer des systèmes de base de connaissances et des moteurs de recommandations. Grâce aux fonctionnalités de recherche intégrées, vous pouvez combiner facilement la compréhension sémantique, la récupération basée sur des mots clés et les graphiques pour obtenir des résultats complets.
Tutoriels, guides de démarrage rapide et ateliers
Détecter les relations et les connexions cachées dans vos données
Détecter les relations et les connexions cachées dans vos données
Avec Spanner Graph, vous pouvez développer des Knowledge Graphs qui capturent les connexions complexes entre les entités, représentées par des nœuds, et leurs relations, représentées par des arêtes. Ces connexions fournissent un contexte riche, ce qui fait des Knowledge Graphs un outil précieux pour développer des systèmes de base de connaissances et des moteurs de recommandations. Grâce aux fonctionnalités de recherche intégrées, vous pouvez combiner facilement la compréhension sémantique, la récupération basée sur des mots clés et les graphiques pour obtenir des résultats complets.
Tarification
| Fonctionnement des tarifs de Spanner | Les tarifs de Spanner sont basés sur la capacité de calcul, Spanner Data Boost, le stockage de base de données, le stockage de sauvegarde, la réplication et l'utilisation du réseau. Les tarifs de calcul varient en fonction de l'édition et de la configuration sélectionnées. Les remises sur engagement d'utilisation peuvent réduire davantage le prix du calcul. | |
|---|---|---|
| Service | Description | Prix (USD) |
Calcul | Édition Standard Une suite complète de fonctionnalités éprouvées pour les configurations régionales (à région unique) La capacité de calcul est provisionnée sous forme d'unités de traitement ou de nœuds (1 nœud = 1 000 unités de traitement). | À partir de 0,030 $ pour 100 unités de traitement par heure et par instance répliquée |
Édition Enterprise Des fonctionnalités de recherche multimodèles et avancées supplémentaires, avec une simplicité et une efficacité opérationnelles optimisées La capacité de calcul est provisionnée sous forme d'unités de traitement ou de nœuds (1 nœud = 1 000 unités de traitement). | À partir de 0,041 $ pour 100 unités de traitement par heure et par instance répliquée | |
Édition Enterprise Plus Gérez les charges de travail les plus exigeantes avec les plus hauts niveaux de disponibilité, de performances, de conformité et de gouvernance La capacité de calcul est provisionnée sous forme d'unités de traitement ou de nœuds (1 nœud = 1 000 unités de traitement). | À partir de 0,057 $ pour 100 unités de traitement par heure et par instance répliquée | |
Data Boost | Ressources de calcul isolées à la demande, y compris le processeur, la mémoire et le transfert de données local | À partir de 0,00117 $ par unité de traitement sans serveur et par heure |
Stockage des bases de données | Le prix est basé sur la quantité de données stockées dans la base de données et inclut le coût du stockage dans les instances répliquées en lecture/écriture et en lecture seule. Les instances répliquées témoin sont gratuites. Stockage SSD Utilisez le stockage SSD lorsque vous avez besoin d'une faible latence et d'un débit élevé pour vos données opérationnelles. | À partir de 0,10 $ par Go et par mois et par instance répliquée pour les SSD |
Stockage HDD Utilisez le stockage HDD pour les données qui doivent être consultées moins fréquemment et qui peuvent tolérer des latences de lecture plus élevées et un débit inférieur. Vous pouvez également configurer des règles de hiérarchisation pour déplacer les données d'un SSD vers un HDD après l'expiration d'une période spécifiée. | À partir de 0,02 $ par Go et par mois et par instance répliquée pour les HDD | |
Stockage des sauvegardes | Configuration régionale La tarification est basée sur la quantité de données de sauvegarde stockées et inclut le coût du stockage dans toutes les instances dupliquées. | À partir de 0,10 $ par Go et par mois (toutes les instances répliquées incluses) |
Configuration à double région et multirégionale La tarification est basée sur la quantité de données de sauvegarde stockées et inclut le coût du stockage dans toutes les instances dupliquées. | À partir de 0,30 $ par Go et par mois (toutes les instances répliquées incluses) | |
Duplication | Réplication intrarégionale | Gratuit |
Réplication interrégionale | À partir de 0,04 $ par Go | |
Réseau | Entrée | Gratuit |
Sortie intrarégionale | Gratuit | |
Sortie interrégionale | À partir de 0,01 $ par Go | |
En savoir plus sur les tarifs de Spanner et les remises sur engagement d'utilisation.
Fonctionnement des tarifs de Spanner
Les tarifs de Spanner sont basés sur la capacité de calcul, Spanner Data Boost, le stockage de base de données, le stockage de sauvegarde, la réplication et l'utilisation du réseau. Les tarifs de calcul varient en fonction de l'édition et de la configuration sélectionnées. Les remises sur engagement d'utilisation peuvent réduire davantage le prix du calcul.
Édition Standard
Une suite complète de fonctionnalités éprouvées pour les configurations régionales (à région unique)
La capacité de calcul est provisionnée sous forme d'unités de traitement ou de nœuds (1 nœud = 1 000 unités de traitement).
Starting at
0,030 $
pour 100 unités de traitement par heure et par instance répliquée
Édition Enterprise
Des fonctionnalités de recherche multimodèles et avancées supplémentaires, avec une simplicité et une efficacité opérationnelles optimisées
La capacité de calcul est provisionnée sous forme d'unités de traitement ou de nœuds (1 nœud = 1 000 unités de traitement).
Starting at
0,041 $
pour 100 unités de traitement par heure et par instance répliquée
Édition Enterprise Plus
Gérez les charges de travail les plus exigeantes avec les plus hauts niveaux de disponibilité, de performances, de conformité et de gouvernance
La capacité de calcul est provisionnée sous forme d'unités de traitement ou de nœuds (1 nœud = 1 000 unités de traitement).
Starting at
0,057 $
pour 100 unités de traitement par heure et par instance répliquée
Data Boost
Ressources de calcul isolées à la demande, y compris le processeur, la mémoire et le transfert de données local
Starting at
0,00117 $
par unité de traitement sans serveur et par heure
Stockage des bases de données
Le prix est basé sur la quantité de données stockées dans la base de données et inclut le coût du stockage dans les instances répliquées en lecture/écriture et en lecture seule. Les instances répliquées témoin sont gratuites.
Stockage SSD
Utilisez le stockage SSD lorsque vous avez besoin d'une faible latence et d'un débit élevé pour vos données opérationnelles.
Starting at
0,10 $
par Go et par mois et par instance répliquée pour les SSD
Stockage HDD
Utilisez le stockage HDD pour les données qui doivent être consultées moins fréquemment et qui peuvent tolérer des latences de lecture plus élevées et un débit inférieur. Vous pouvez également configurer des règles de hiérarchisation pour déplacer les données d'un SSD vers un HDD après l'expiration d'une période spécifiée.
Starting at
0,02 $
par Go et par mois et par instance répliquée pour les HDD
Stockage des sauvegardes
Configuration régionale
La tarification est basée sur la quantité de données de sauvegarde stockées et inclut le coût du stockage dans toutes les instances dupliquées.
Starting at
0,10 $
par Go et par mois (toutes les instances répliquées incluses)
Configuration à double région et multirégionale
La tarification est basée sur la quantité de données de sauvegarde stockées et inclut le coût du stockage dans toutes les instances dupliquées.
Starting at
0,30 $
par Go et par mois (toutes les instances répliquées incluses)
Duplication
Réplication intrarégionale
Gratuit
Réplication interrégionale
Starting at
0,04 $
par Go
Réseau
Entrée
Gratuit
Sortie intrarégionale
Gratuit
Sortie interrégionale
Starting at
0,01 $
par Go
En savoir plus sur les tarifs de Spanner et les remises sur engagement d'utilisation.
Commencer votre démonstration de faisabilité
Cas d'utilisation métier
Découvrez comment d'autres entreprises ont créé des applications innovantes pour offrir une expérience client de qualité, réduire les coûts et augmenter le ROI avec Spanner.
- Selon l'étude Total Economic Impact™ de Forrester, Spanner offre un ROI de 132 %, un délai de rentabilisation de neuf mois et des avantages de plusieurs millions de dollars pour une organisation composite représentative. Téléchargez l'étude complète pour en savoir plus.
- Gartner® identifie 13 fonctionnalités essentielles pour les bases de données opérationnelles et classe Spanner au premier rang dans le cas d'utilisation des transactions légères. Télécharger le rapport complet.

Comment Uber peut-il effectuer un scaling pour traiter des millions de requêtes simultanées ?
Découvrez comment Uber a repensé sa plate-forme de traitement grâce à Spanner.



Avantages et clients (sélection)
Développez votre activité grâce à des applications innovantes qui évoluent sans limites pour répondre à n'importe quel niveau de demande.
Réduisez le coût total de possession et libérez vos développeurs des opérations fastidieuses afin de voir plus grand et d'accélérer le développement.
Bénéficiez d'un rapport prix-performances supérieur et payez à l'utilisation, à partir de 40 $ par mois.















Partenaires et intégration
Profitez de l'expertise de Spanner et de nos partenaires pour vous accompagner à chaque étape de votre parcours, des évaluations aux cas d'utilisation, en passant par la migration et la création d'applications.











Intégrateurs système
Les partenaires Spanner vous aident à moderniser vos applications et à migrer vers le cloud en toute simplicité. Trouvez le partenaire ou l'intégration tierce idéale dans notre annuaire.
Questions fréquentes
Spanner est-il une base de données relationnelle ou non-relationnelle ?
Spanner simplifie votre architecture de données en rassemblant les charges de travail relationnelles, de clé-valeur, de graphes et de recherche vectorielle dans la même base de données. C'est une base de données hautement évolutive qui combine évolutivité illimitée et sémantique relationnelle (index secondaires, cohérence forte, schémas et langage SQL) pour offrir une disponibilité de 99,999 % dans une solution simple et autonome. Par conséquent, Cloud Spanner il convient aux charges de travail relationnelles et non-relationnelles.
Spanner utilise-t-il SQL ?
Spanner fournit deux dialectes SQL basés sur ANSI pour un même vaste ensemble de fonctionnalités : GoogleSQL et PostgreSQL. Google SQL partage sa syntaxe avec BigQuery pour permettre aux équipes de standardiser leurs workflows de gestion des données. L'interface PostgreSQL est familière pour les équipes qui connaissent déjà PostgreSQL ainsi que la portabilité des schémas et des requêtes vers d'autres environnements PostgreSQL. Pour en savoir plus sur l'interface PostgreSQL de Spanner, consultez notre documentation.
Comment migrer des bases de données vers Spanner ?
En migrant vos charges de travail existantes vers Spanner, vous vous assurez une base pour une croissance future, sans faire de compromis sur la fiabilité ou le rapport prix/performances. L'interface multimodèle de Spanner est aujourd'hui utilisée par des entreprises innovantes de tous les secteurs qui ont des charges de travail opérationnelles provenant de bases de données relationnelles (comme MySQL et SQL Server), de magasins de clés/valeurs (comme Cassandra ou DynamoDB) et d'outils de graphes, de recherche et de documents. L'approche spécifique à adopter pour une migration dépend des exigences concernant le volume de données, les SLO de performances et la disponibilité. L'outil de migration Spanner fournit une évaluation de bout en bout, une migration de schéma et de données, et un basculement avec un temps d'arrêt réduit pour les bases de données MySQL et Cassandra partitionnées, ainsi qu'une évaluation et une migration pour PostgreSQL. Un réseau qualifié de partenaires technologiques et de services peut accélérer les migrations depuis presque n'importe quelle source.
Quels sont les principaux points à prendre en compte pour exploiter Spanner ?
Spanner est une base de données entièrement gérée qui fournit automatiquement des fonctionnalités complètes de gestion d'infrastructure. Cependant, en fonction de votre charge de travail, certaines actions de gestion spécifiques à l'application peuvent être requises. Vous devez vous assurer d'avoir correctement configuré les alertes et la surveillance, et les surveiller de près pour que la production fonctionne toujours correctement. Vous devez connaître les mesures à prendre lorsque le trafic augmente naturellement dans le temps ou en cas de pic de trafic attendu, savoir comment gérer la corruption des données suite à des bugs d'application, ou encore comment résoudre les problèmes de performances et identifier les composants à l'origine d'une latence accrue.











