
Spanner
Database sempre attivo con scalabilità praticamente illimitata
Crea app intelligenti con un unico database che combina elementi di relazione, grafici, coppie chiave-valore e ricerca. Senza periodi di manutenzione significa app mission-critical senza interruzioni.
Inoltre, i nuovi clienti Google Cloud ricevono 300 $ di crediti gratuiti.

Funzionalità
Multi-modello: un database, tante possibilità
Le funzionalità multi-modello di Spanner ti consentono di creare applicazioni intelligenti e con l'AI integrata sui tuoi dati NoSQL erelazionali e operativi sfruttando l'integrazione nativa con Vertex AI, Spanner Graph per eseguire query su relazioni complesse, ricerca vettoriale per la ricerca semantica, ricerca a testo intero integrata, il tutto con un'interoperabilità "true ZeroETL". Questo approccio unificato elimina i silo di dati, consente di risparmiare sui costi, riduce i touchpoint operativi e di sicurezza e garantisce la coerenza dei dati in tutti i modelli.

Scalabilità senza problemi
Sogna in grande, inizia in piccolo e scala senza sforzi man mano che le tue esigenze crescono. Spanner gestisce senza problemi set di dati in crescita e workload impegnativi grazie alla sua scalabilità orizzontale di lettura e scrittura. Lo sharding automatico del database garantisce una distribuzione ottimale dei dati, mentre il partizionamento geografico avvicina i dati agli utenti per una latenza inferiore. Goditi prestazioni sempre elevate con l'elaborazione delle query in modalità isolata dai workload con Spanner Data Boost, anche durante i picchi di domanda.

Disponibilità perenne
Assicurati che le tue applicazioni siano sempre attive e pronte a soddisfare le esigenze dei tuoi utenti. Spanner offre fino al 99,999% di disponibilità con opzioni di deployment flessibili e manutenzione automatizzata. Scegli tra configurazioni a regione singola, a due regioni o più regioni per soddisfare i tuoi requisiti specifici di disponibilità e tolleranza di errore.

Transazioni coerenti garantite
Di' addio alle incoerenze dei dati e alle complessità della loro gestione. Spanner garantisce una forte coerenza a livello di transazioni, il che significa che ogni lettura riflette gli aggiornamenti più recenti, indipendentemente dalle dimensioni o dalla distribuzione dei dati. Crea con sicurezza, sapendo che le tue applicazioni hanno sempre una visione coerente dei tuoi dati.
Sicurezza e conformità affidabili
Affida i tuoi dati a una piattaforma sicura e conforme con Spanner. Goditi l'amministrazione e il controllo centralizzati con Database Center, semplificando la gestione di database cloud. Spanner offre sicurezza e controlli di livello aziendale, tra cui la crittografia dei dati at-rest e in transito, la gestione granulare degli accessi tramite Identity and Access Management (IAM) e la conformità agli standard di settore. Proteggi ulteriormente i tuoi dati con solide funzionalità di backup e ripristino, tra cui il recupero point-in-time per la massima tranquillità operativa.
Confronto di database
| Attributo di database | Altro database relazionale | Altro database non relazionale | Spanner |
|---|---|---|---|
Schema | Statiche | Dinamica | Dinamica |
SQL | Sì | No | Sì (PostgreSQL, Google SQL) |
Transazioni | ACID (atomicità, coerenza, isolamento, durabilità) | Finale | ACID solido con ordine TrueTime |
Scalabilità | Verticale (utilizza una macchina più grande) | Orizzontale (aggiungi altre macchine) | Orizzontale |
Disponibilità | Failover (tempo di inattività) | Alta | SLA alto del 99,999% |
Replica | Configurabile | Configurabile | Automatico |
Gartner® ha assegnato a Spanner il primo posto per il caso d'uso Transazioni leggere. Accedi al report completo.
Schema
Statiche
Dinamica
Dinamica
Transazioni
ACID
(atomicità, coerenza, isolamento, durabilità)
Finale
ACID solido
con ordine TrueTime
Scalabilità
Verticale
(utilizza una macchina più grande)
Orizzontale
(aggiungi altre macchine)
Orizzontale
Disponibilità
Failover (tempo di inattività)
Alta
SLA alto del 99,999%
Replica
Configurabile
Configurabile
Automatico
Gartner® ha assegnato a Spanner il primo posto per il caso d'uso Transazioni leggere. Accedi al report completo.
Come funziona
Le istanze Spanner forniscono computing e archiviazione in una o più regioni. Un orologio distribuito chiamato TrueTime garantisce una forte coerenza delle transazioni anche tra le regioni. I dati vengono suddivisi automaticamente per la scalabilità e replicati utilizzando uno schema sincrono basato su Paxos per la disponibilità.
Le istanze Spanner forniscono computing e archiviazione in una o più regioni. Un orologio distribuito chiamato TrueTime garantisce una forte coerenza delle transazioni anche tra le regioni. I dati vengono suddivisi automaticamente per la scalabilità e replicati utilizzando uno schema sincrono basato su Paxos per la disponibilità.

Utilizzi comuni
Migrazione e modernizzazione
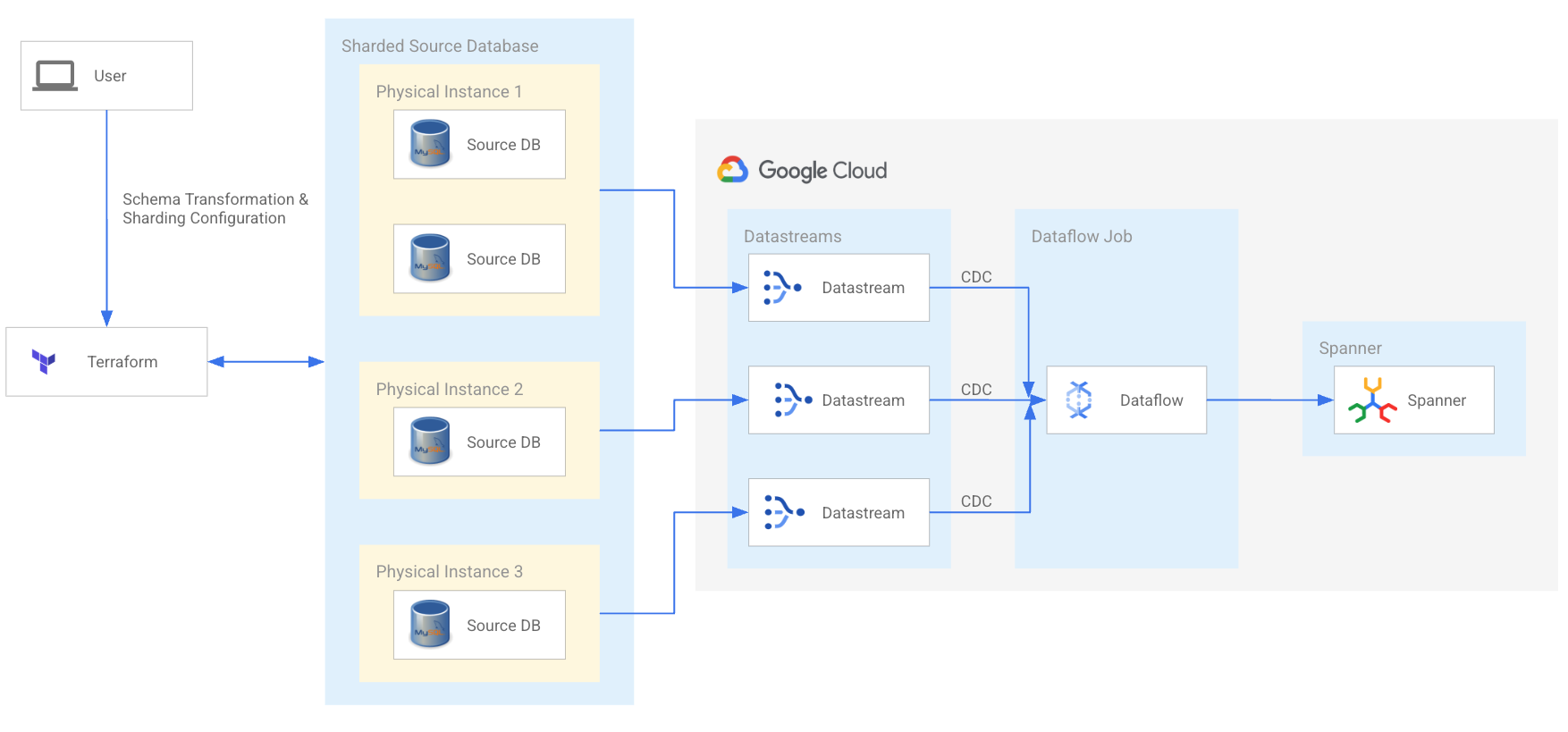
Semplifica la modernizzazione di MySQL e Cassandra
Semplifica la modernizzazione di MySQL e Cassandra
Modernizza i tuoi workload MySQL e Cassandra con shard per potenziare i tuoi team di sviluppo e scalare per la prossima fase di crescita. Sfrutta lo strumento di migrazione Spanner open source e una rete di servizi qualificati e partner tecnologici che possono semplificare la tua migrazione.
Tutorial, guide rapide e lab
Semplifica la modernizzazione di MySQL e Cassandra
Semplifica la modernizzazione di MySQL e Cassandra
Modernizza i tuoi workload MySQL e Cassandra con shard per potenziare i tuoi team di sviluppo e scalare per la prossima fase di crescita. Sfrutta lo strumento di migrazione Spanner open source e una rete di servizi qualificati e partner tecnologici che possono semplificare la tua migrazione.
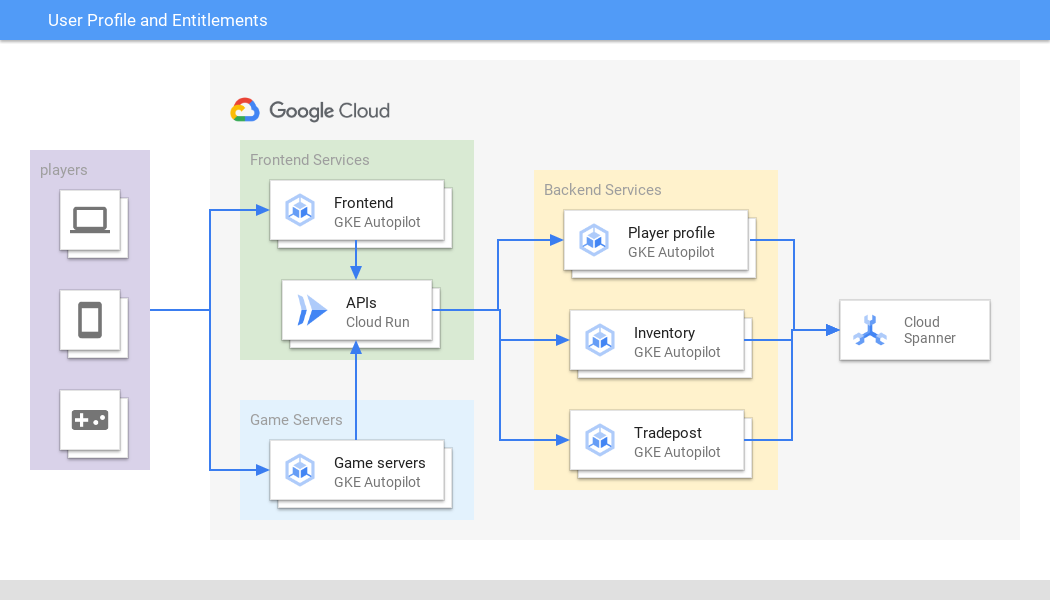
Profilo utente e diritti
Gestisci in modo sicuro i dati utente critici su qualsiasi scala
Tutorial, guide rapide e lab
Gestisci in modo sicuro i dati utente critici su qualsiasi scala
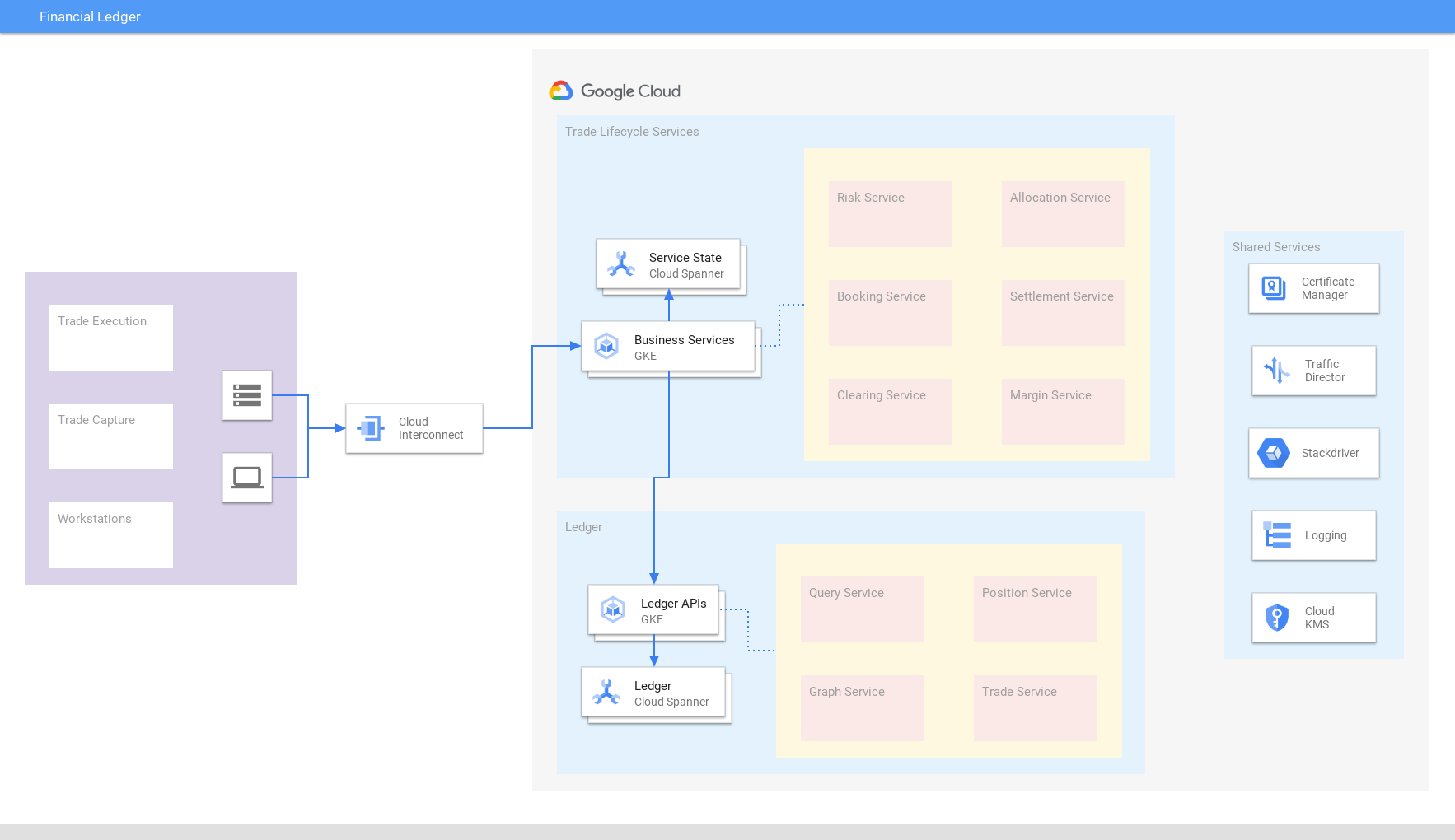
Riepilogo finanziario
Ottieni una visualizzazione aggiornata e coerente delle transazioni globali
Unifica transazioni finanziarie, scambi, accordi e posizioni in tutto il mondo in un registro commerciale consolidato basato su Spanner che garantisce coerenza esterna e scalabilità. Il consolidamento dei dati aiuta ad adattarsi rapidamente alle mutevoli condizioni del mercato e ai requisiti normativi. Analogamente, le aziende di vendita al dettaglio/e-commerce utilizzano Spanner per la contabilità dell'inventario.
Tutorial, guide rapide e lab
Ottieni una visualizzazione aggiornata e coerente delle transazioni globali
Unifica transazioni finanziarie, scambi, accordi e posizioni in tutto il mondo in un registro commerciale consolidato basato su Spanner che garantisce coerenza esterna e scalabilità. Il consolidamento dei dati aiuta ad adattarsi rapidamente alle mutevoli condizioni del mercato e ai requisiti normativi. Analogamente, le aziende di vendita al dettaglio/e-commerce utilizzano Spanner per la contabilità dell'inventario.
Online banking
Offri un'interattività sempre attiva per le esperienze digitali
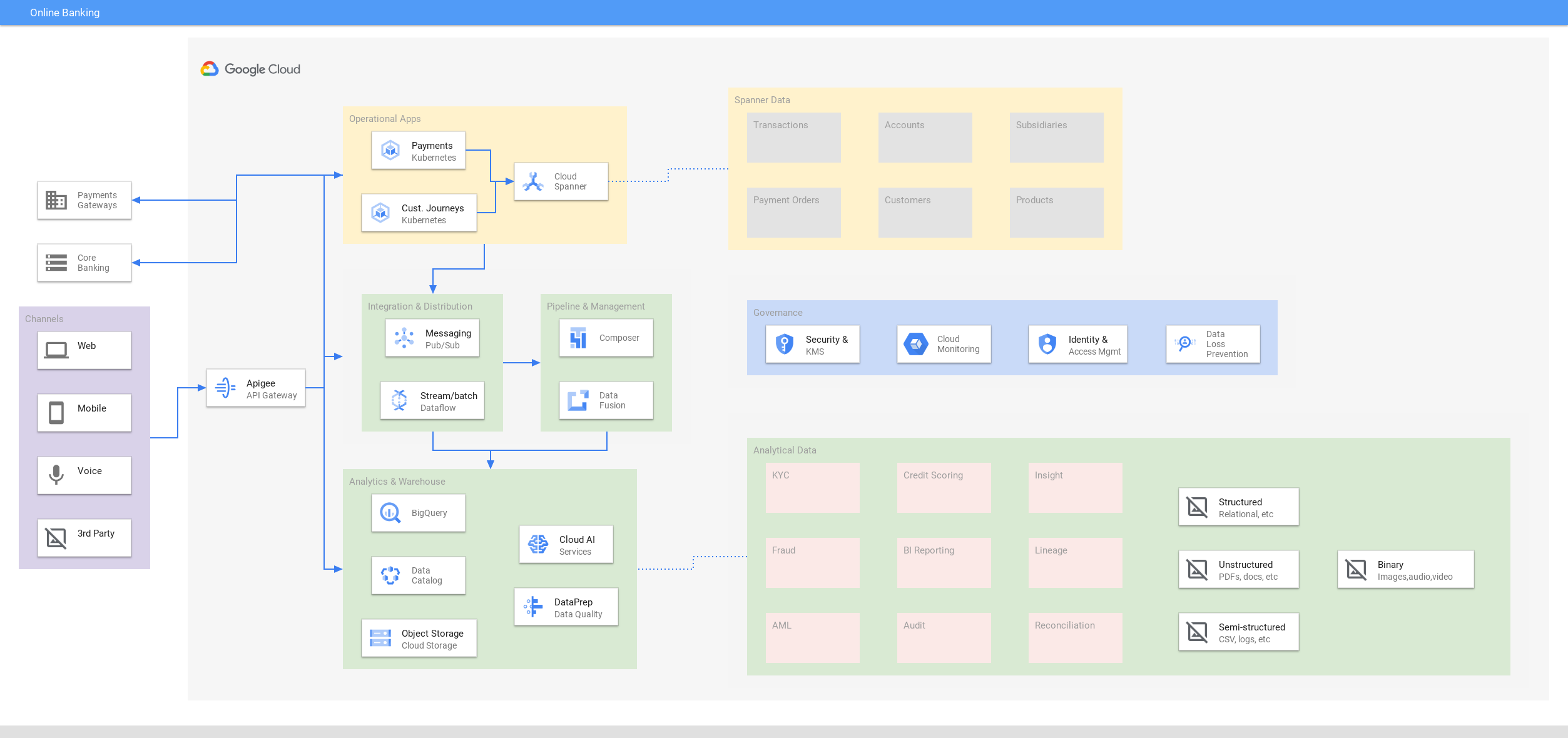
Tutorial, guide rapide e lab
Offri un'interattività sempre attiva per le esperienze digitali
Promozioni e programmi fedeltà
Personalizza le esperienze con gli aggiornamenti in tempo reale
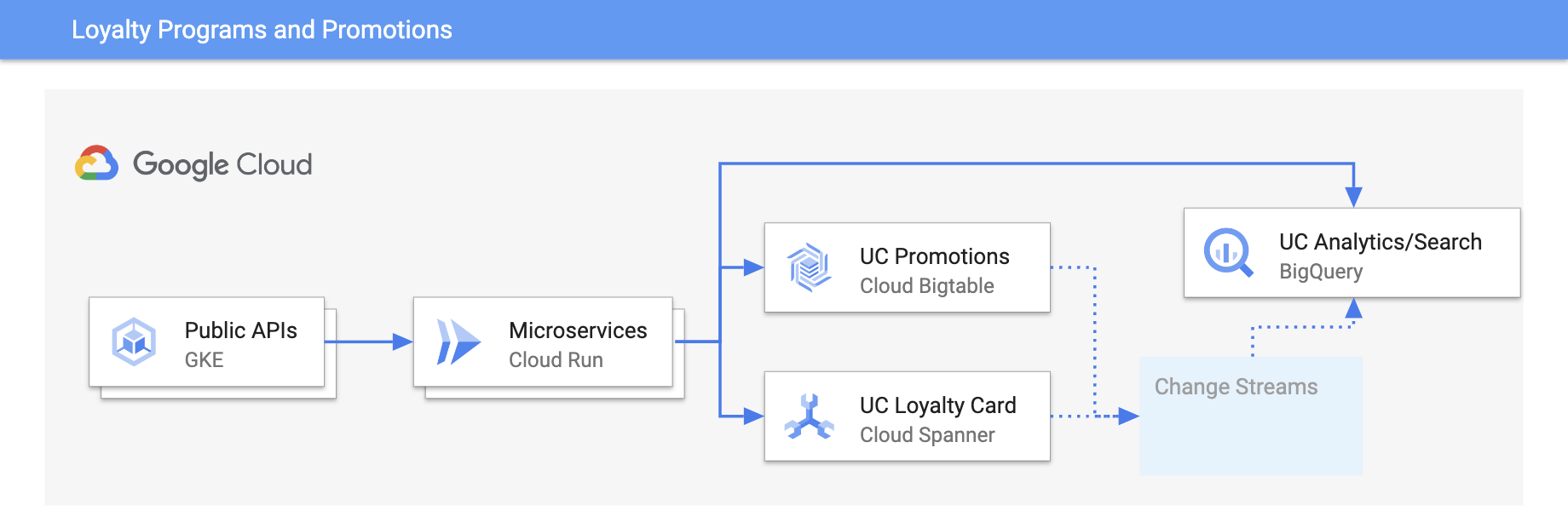
Tutorial, guide rapide e lab
Personalizza le esperienze con gli aggiornamenti in tempo reale
Gestione dell'inventario omnicanale
Fornisci una visualizzazione coerente su più canali e app
Spanner fornisce una singola fonte attendibile ad alte prestazioni per l'inventario e gli ordini di vendita al dettaglio in centri di distribuzione, online e in negozio, e per la spedizione per abbinare l'inventario alla domanda, migliorando la customer experience e la redditività.Analogamente, le aziende di giochi utilizzano Spanner per archiviare i dati di inventario in-game.
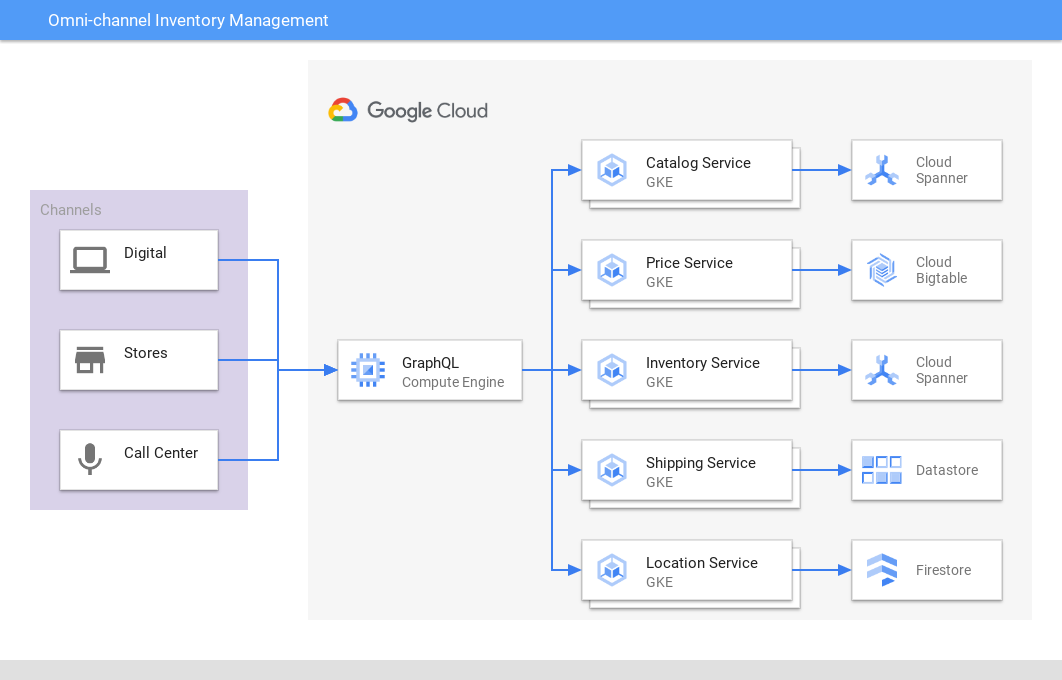
Tutorial, guide rapide e lab
Fornisci una visualizzazione coerente su più canali e app
Spanner fornisce una singola fonte attendibile ad alte prestazioni per l'inventario e gli ordini di vendita al dettaglio in centri di distribuzione, online e in negozio, e per la spedizione per abbinare l'inventario alla domanda, migliorando la customer experience e la redditività.Analogamente, le aziende di giochi utilizzano Spanner per archiviare i dati di inventario in-game.
Knowledge Graph
Rileva le relazioni e le connessioni nascoste nei dati
Rileva le relazioni e le connessioni nascoste nei dati
Con Spanner Graph puoi sviluppare Knowledge Graph che acquisiscono le connessioni complesse tra le entità, rappresentate come nodi, e le loro relazioni, rappresentate da archi. Queste connessioni forniscono un ricco contesto, rendendo i Knowledge Graph preziosi per lo sviluppo di sistemi di knowledge base e motori per suggerimenti. Con le funzionalità di ricerca integrate, puoi combinare perfettamente comprensione semantica, recupero basato su parole chiave e grafici per risultati completi.
Tutorial, guide rapide e lab
Rileva le relazioni e le connessioni nascoste nei dati
Rileva le relazioni e le connessioni nascoste nei dati
Con Spanner Graph puoi sviluppare Knowledge Graph che acquisiscono le connessioni complesse tra le entità, rappresentate come nodi, e le loro relazioni, rappresentate da archi. Queste connessioni forniscono un ricco contesto, rendendo i Knowledge Graph preziosi per lo sviluppo di sistemi di knowledge base e motori per suggerimenti. Con le funzionalità di ricerca integrate, puoi combinare perfettamente comprensione semantica, recupero basato su parole chiave e grafici per risultati completi.
Prezzi
| Come funzionano i prezzi di Spanner | I prezzi di Spanner si basano sulla capacità di calcolo, su Spanner Data Boost, sull'archiviazione dei database, sull'archiviazione di backup, sulla replica e sull'utilizzo della rete. I prezzi del calcolo variano in base alla versione e alla configurazione selezionate. Gli sconti per impegno di utilizzo possono ridurre ulteriormente il prezzo del calcolo. | |
|---|---|---|
| Servizio | Descrizione | Prezzo ($) |
Computing | Versione Standard Dotato di una suite completa di funzionalità consolidate per configurazioni a livello di regione (a regione singola) Il provisioning della capacità di calcolo viene eseguito sotto forma di unità di elaborazione o nodi (1 nodo = 1000 unità di elaborazione). | A partire da 0,030 $ per 100 unità di elaborazione all'ora per replica |
Versione Enterprise Forniscono funzionalità di ricerca avanzata e multimodello con semplicità ed efficienza operative migliorate Il provisioning della capacità di calcolo viene eseguito sotto forma di unità di elaborazione o nodi (1 nodo = 1000 unità di elaborazione). | A partire da 0,041 $ per 100 unità di elaborazione all'ora per replica | |
Versione Enterprise Plus Supporta i carichi di lavoro più impegnativi con i livelli più elevati di disponibilità, prestazioni, conformità e governance Il provisioning della capacità di calcolo viene eseguito sotto forma di unità di elaborazione o nodi (1 nodo = 1000 unità di elaborazione). | A partire da 0,057 $ per 100 unità di elaborazione all'ora per replica | |
Data Boost | Risorse di calcolo isolate on demand, tra cui CPU, memoria e trasferimento di dati locali | A partire da 0,00117 $ per unità di elaborazione serverless all'ora |
Spazio di archiviazione dei database | Il prezzo si basa sulla quantità di dati archiviati nel database e include il costo di archiviazione nelle repliche di sola lettura e di sola scrittura; le repliche secondarie sono senza costi. Archiviazione SSD Utilizza l'archiviazione SSD quando hai bisogno di bassa latenza e throughput elevato per i tuoi dati operativi. | A partire da 0,10 $ per GB al mese per replica per SSD |
Archiviazione HDD Usa lo spazio di archiviazione HDD per i dati a cui è necessario accedere con meno frequenza e che possono tollerare una latenza di lettura più elevata e una velocità effettiva inferiore. Puoi anche configurare i criteri di categorizzazione per spostare i dati da SSD a HDD dopo la scadenza di una finestra temporale specificata. | A partire da 0,02 $ per GB al mese per replica per HDD | |
Spazio di archiviazione dei backup | Configurazione per singole regioni I prezzi si basano sulla quantità di spazio di archiviazione di backup e includono il costo dell'archiviazione in tutte le repliche. | A partire da 0,10 $ per GB al mese (incluse tutte le repliche) |
Configurazione a due o più regioni I prezzi si basano sulla quantità di spazio di archiviazione di backup e includono il costo dell'archiviazione in tutte le repliche. | A partire da $ 0,30 per GB al mese (incluse tutte le repliche) | |
Replica | Replica all'interno della regione | Nessun costo |
Replica tra aree geografiche | A partire da 0,04 $ per GB | |
Rete | In entrata | Nessun costo |
In uscita all'interno della regione | Nessun costo | |
In uscita all'interno della regione | A partire da 0,01 $ per GB | |
Scopri di più sui prezzi e sugli sconti per impegno di utilizzo di Spanner.
Come funzionano i prezzi di Spanner
I prezzi di Spanner si basano sulla capacità di calcolo, su Spanner Data Boost, sull'archiviazione dei database, sull'archiviazione di backup, sulla replica e sull'utilizzo della rete. I prezzi del calcolo variano in base alla versione e alla configurazione selezionate. Gli sconti per impegno di utilizzo possono ridurre ulteriormente il prezzo del calcolo.
Versione Standard
Dotato di una suite completa di funzionalità consolidate per configurazioni a livello di regione (a regione singola)
Il provisioning della capacità di calcolo viene eseguito sotto forma di unità di elaborazione o nodi (1 nodo = 1000 unità di elaborazione).
Starting at
0,030 $
per 100 unità di elaborazione all'ora per replica
Versione Enterprise
Forniscono funzionalità di ricerca avanzata e multimodello con semplicità ed efficienza operative migliorate
Il provisioning della capacità di calcolo viene eseguito sotto forma di unità di elaborazione o nodi (1 nodo = 1000 unità di elaborazione).
Starting at
0,041 $
per 100 unità di elaborazione all'ora per replica
Versione Enterprise Plus
Supporta i carichi di lavoro più impegnativi con i livelli più elevati di disponibilità, prestazioni, conformità e governance
Il provisioning della capacità di calcolo viene eseguito sotto forma di unità di elaborazione o nodi (1 nodo = 1000 unità di elaborazione).
Starting at
0,057 $
per 100 unità di elaborazione all'ora per replica
Data Boost
Risorse di calcolo isolate on demand, tra cui CPU, memoria e trasferimento di dati locali
Starting at
0,00117 $
per unità di elaborazione serverless all'ora
Spazio di archiviazione dei database
Il prezzo si basa sulla quantità di dati archiviati nel database e include il costo di archiviazione nelle repliche di sola lettura e di sola scrittura; le repliche secondarie sono senza costi.
Archiviazione SSD
Utilizza l'archiviazione SSD quando hai bisogno di bassa latenza e throughput elevato per i tuoi dati operativi.
Starting at
0,10 $
per GB al mese per replica per SSD
Archiviazione HDD
Usa lo spazio di archiviazione HDD per i dati a cui è necessario accedere con meno frequenza e che possono tollerare una latenza di lettura più elevata e una velocità effettiva inferiore. Puoi anche configurare i criteri di categorizzazione per spostare i dati da SSD a HDD dopo la scadenza di una finestra temporale specificata.
Starting at
0,02 $
per GB al mese per replica per HDD
Spazio di archiviazione dei backup
Configurazione per singole regioni
I prezzi si basano sulla quantità di spazio di archiviazione di backup e includono il costo dell'archiviazione in tutte le repliche.
Starting at
0,10 $
per GB al mese (incluse tutte le repliche)
Configurazione a due o più regioni
I prezzi si basano sulla quantità di spazio di archiviazione di backup e includono il costo dell'archiviazione in tutte le repliche.
Starting at
$ 0,30
per GB al mese (incluse tutte le repliche)
Replica
Replica all'interno della regione
Nessun costo
Replica tra aree geografiche
Starting at
0,04 $
per GB
Rete
In entrata
Nessun costo
In uscita all'interno della regione
Nessun costo
In uscita all'interno della regione
Starting at
0,01 $
per GB
Scopri di più sui prezzi e sugli sconti per impegno di utilizzo di Spanner.
Business case
Scopri come altre aziende hanno creato app innovative per offrire customer experience straordinarie, ridurre i costi e aumentare il ROI con Spanner.
- Lo studio Total Economic Impact™ di Forrester mostra che Spanner offre un ROI del 132%, un periodo di ritorno sull'investimento di 9 mesi e vantaggi per un'organizzazione rappresentativa composita di diversi milioni di dollari. Scarica lo studio integrale per scoprire di più.
- Gartner® identifica 13 funzionalità critiche per i database operativi e assegna a Spanner il primo posto nel caso d'uso Transazioni leggere. Accedi al report completo.

In che modo Uber scala a milioni di richieste in parallelo?
Scopri come Uber ha riprogettato la sua piattaforma di distribuzione utilizzando Spanner.



Vantaggi e clienti in primo piano
Fai crescere la tua attività con applicazioni innovative che scalano senza limiti per soddisfare qualsiasi domanda.
Riduci il TCO e libera i tuoi sviluppatori da operazioni ingombranti per sognare in grande e creare più velocemente.
Ottieni un rapporto prezzo/prestazioni superiore e paga per ciò che utilizzi, a partire da 40 $ al mese.















Partner e integrazione
Approfitta dell'aiuto di partner esperti di Spanner in ogni fase del percorso, dalle valutazioni e business case alle migrazioni e alla creazione di nuove app su Spanner.











Integratori di sistemi
I partner Spanner ti aiutano a modernizzare le applicazioni e a eseguire la migrazione al cloud senza problemi. Trova il partner o l'integrazione di terze parti ideale nella nostra directory.
Domande frequenti
Spanner è un database relazionale o non relazionale?
Spanner semplifica l'architettura dei dati riunendo carichi di lavoro di ricerca relazionale, chiave-valore, grafici e vettoriale, il tutto sullo stesso database. Spanner è un database a scalabilità elevata che combina scalabilità illimitata con semantica relazionale, come indici secondari, elevata coerenza, schemi e SQL, fornendo una disponibilità del 99,999% in un'unica semplice soluzione. Quindi, è adatto sia per carichi di lavoro relazionali che non relazionali.
Spanner utilizza SQL?
Spanner fornisce due dialetti SQL basati su ANSI sullo stesso ricco set di funzionalità: GoogleSQL e PostgreSQL. GoogleSQL condivide la sintassi con BigQuery per i team che standardizzano i flussi di lavoro di gestione dei dati. L'interfaccia PostgreSQL fornisce familiarità ai team che già conoscono PostgreSQL e la portabilità di schemi e query ad altri ambienti PostgreSQL. Per saperne di più sull'interfaccia PostgreSQL di Spanner, consulta la nostra documentazione.
Come faccio a eseguire la migrazione dei database a Spanner?
La migrazione dei workload esistenti a Spanner garantisce una base per la crescita futura, senza dover scendere a compromessi in termini di affidabilità o rapporto prezzo-prestazioni. L'interfaccia multi-modello di Spanner è utilizzata oggi da organizzazioni innovative di tutti i settori con workload operativi provenienti da database relazionali, come MySQL e SQL Server, da store di coppie chiave-valore, come Cassandra o DynamoDB, oltre a strumenti grafici, di ricerca e di documentazione. L'approccio specifico per una migrazione dipenderà dai requisiti relativi a volume di dati, SLO sulle prestazioni e disponibilità. Lo strumento di migrazione Spanner fornisce test end-to-end, migrazione di dati e schemi e cutover con tempi di inattività ridotti per i database MySQL e Cassandra con shard, nonché test e migrazione per PostgreSQL. Una rete qualificata di partner tecnologici e di servizi può accelerare le migrazioni da praticamente qualsiasi origine.
Quali sono le considerazioni chiave da tenere a mente per l'utilizzo di Spanner?
Spanner è un database completamente gestito, che fornisce automaticamente funzionalità complete di gestione dell'infrastruttura, ma potrebbero essere necessarie alcune azioni di gestione specifiche per l'applicazione, a seconda del tuo carico di lavoro. Sarà necessario assicurarsi di aver configurato gli avvisi e il monitoraggio appropriati e osservarli attentamente per garantire che la produzione funzioni sempre senza problemi. Devi capire quali azioni intraprendere quando il traffico aumenta in modo organico nel tempo, se è previsto un picco di traffico o come gestire il danneggiamento dei dati dovuto a bug delle applicazioni e infine come risolvere i problemi di prestazioni e comprendere quali componenti sono responsabili dell'aumento delle latenze.











