
Spanner
始终开启的数据库,规模近乎无限
使用汇集了关系型、图表、键值对和搜索的单个数据库构建智能应用。没有维护窗口意味着任务关键型应用会不间断地运行。
此外,Google Cloud 新客户可获得 $300 赠金。

功能
多模型:一个数据库,多种可能性
借助 Spanner 的多模型功能,您可以利用原生 Vertex AI 集成、Spanner Graph(用于查询复杂关系)、向量搜索(用于语义搜索)、内置的全文搜索,在运营关系型和 NoSQL 数据之上构建智能、依托 AI 技术的应用,所有这些都具有“真正的 ZeroETL”互操作性。这种统一的方法能够消除数据孤岛,节省费用,减少运营和安全接触点,并确保所有模型的数据一致性。

轻松扩缩
从小处着手,大处着眼,随着需求的增长轻松扩容。Spanner 通过横向扩缩读取和“写入”功能,可无缝处理不断增长的数据集和要求苛刻的工作负载。自动数据库分片可确保以最佳方式分布数据,而地理分区可将数据分布在更靠近用户的位置,从而降低延迟时间。借助 Spanner Data Boost,即使在需求高峰期,也能通过与工作负载隔离的查询处理体验始终如一的出色性能。

Always On 可用性
确保您的应用始终在线,随时为用户提供服务。凭借自动化维护和灵活的部署选项,Spanner 可实现高达 99.999% 的可用性。您可以根据具体的可用性和容错需求,选择单区域、双区域或多区域配置。

保证一致的事务
告别数据不一致和管理数据的复杂性。Spanner 确保强事务一致性,这意味着无论数据的大小或分布如何,每次读取都将反映最新的更新。放心地构建应用,因为您知道应用始终会以一致的方式查看数据。
可信的安全性和合规性
信任 Spanner,将您的数据托付给安全且合规的平台。借助数据库中心,享受集中的管理和控制,简化云数据库管理。Spanner 提供企业级安全和控制机制,包括静态和传输中的数据加密、通过 Identity and Access Management (IAM) 进行精细化访问管理,以及遵守行业标准。借助强大的备份和恢复功能(包括时间点恢复)进一步保护您的数据,让您在运营时无后顾之忧。
数据库比较
| 数据库属性 | 其他关系型数据库 | 其他非关系型数据库 | Spanner |
|---|---|---|---|
架构 | 静态 | 动态 | 动态 |
SQL | 是 | 否 | 是 (PostgreSQL、Google SQL) |
事务 | ACID (原子性、一致性、隔离性、耐用性) | 最终一致 | 强 ACID 使用 TrueTime 排序 |
可伸缩性 | 纵向 (使用更大的机器) | 水平市场 (添加更多机器) | 横向 |
可用性 | 故障切换(停机时间) | 高 | 高,SLA 承诺 99.999% 的可用性 |
复制 | 可配置 | 可配置 | 自动 |
Gartner® 将 Spanner 列为轻量级事务应用场景的首选解决方案。获取完整的报告。
架构
静态
动态
动态
事务
ACID
(原子性、一致性、隔离性、耐用性)
最终一致
强 ACID
使用 TrueTime 排序
可伸缩性
纵向
(使用更大的机器)
水平市场
(添加更多机器)
横向
可用性
故障切换(停机时间)
高
高,SLA 承诺 99.999% 的可用性
复制
可配置
可配置
自动
Gartner® 将 Spanner 列为轻量级事务应用场景的首选解决方案。获取完整的报告。

常见用途
迁移和现代化
简化 MySQL 和 Cassandra 现代化改造
简化 MySQL 和 Cassandra 现代化改造
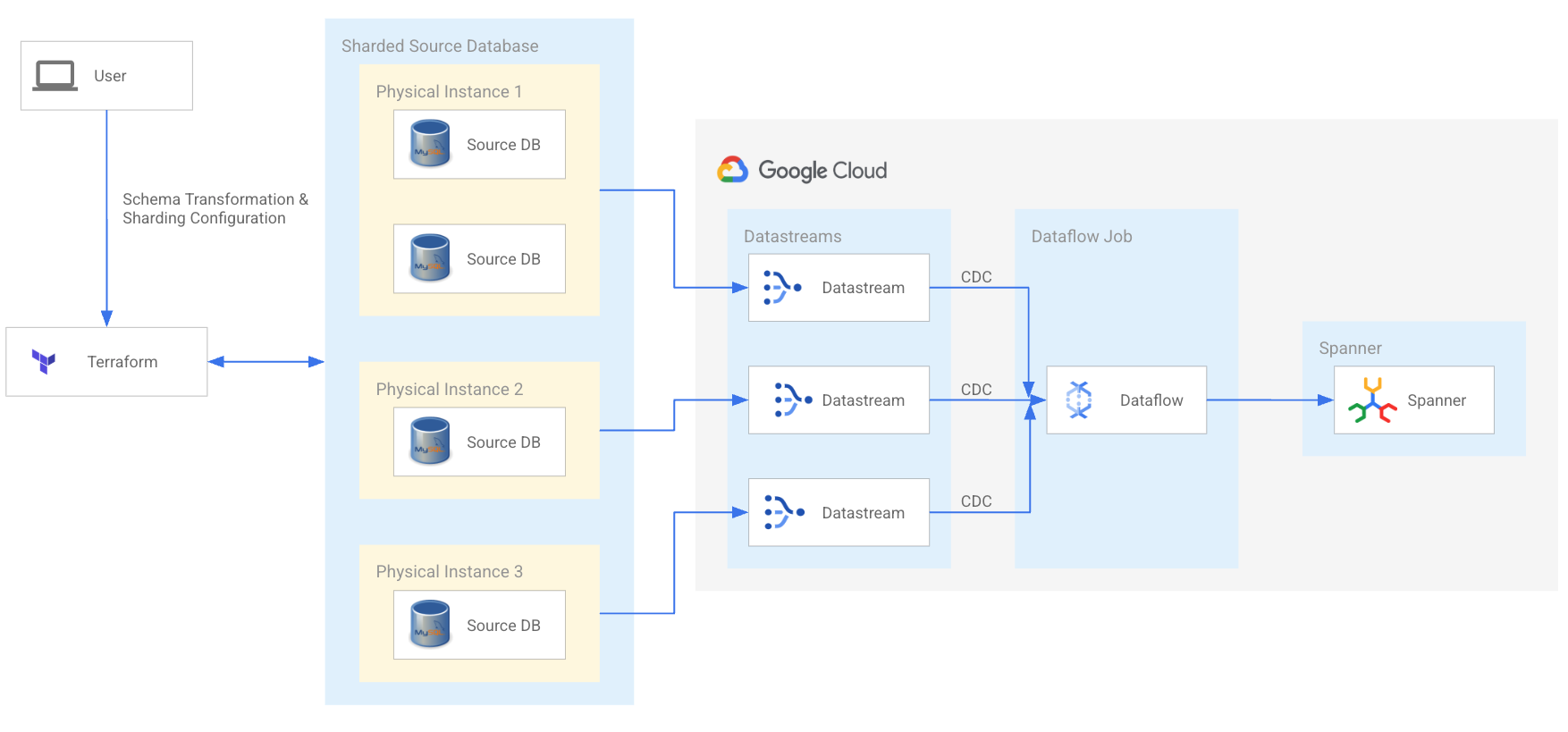
对分片的 MySQL 和 Cassandra 工作负载进行现代化改造,为您的开发团队提供强大支持,并为下一阶段的增长进行扩容。利用开源的 Spanner 迁移工具和一系列合格的服务和技术合作伙伴,简化您的迁移流程。
教程、快速入门和实验
简化 MySQL 和 Cassandra 现代化改造
简化 MySQL 和 Cassandra 现代化改造
对分片的 MySQL 和 Cassandra 工作负载进行现代化改造,为您的开发团队提供强大支持,并为下一阶段的增长进行扩容。利用开源的 Spanner 迁移工具和一系列合格的服务和技术合作伙伴,简化您的迁移流程。
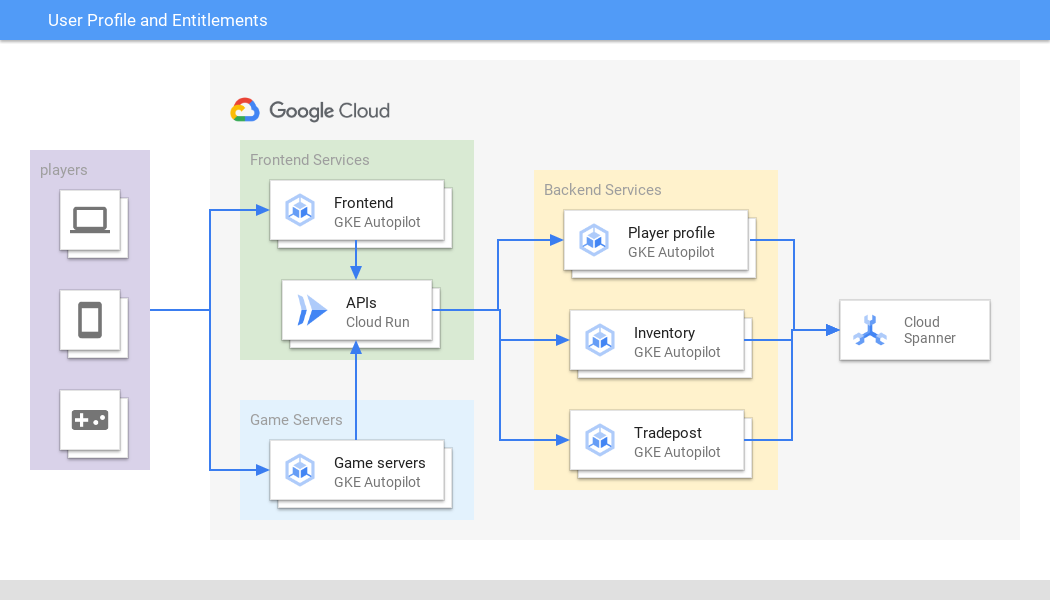
用户个人资料和使用权
安全地管理任何规模的关键用户数据
教程、快速入门和实验
安全地管理任何规模的关键用户数据
财务账目
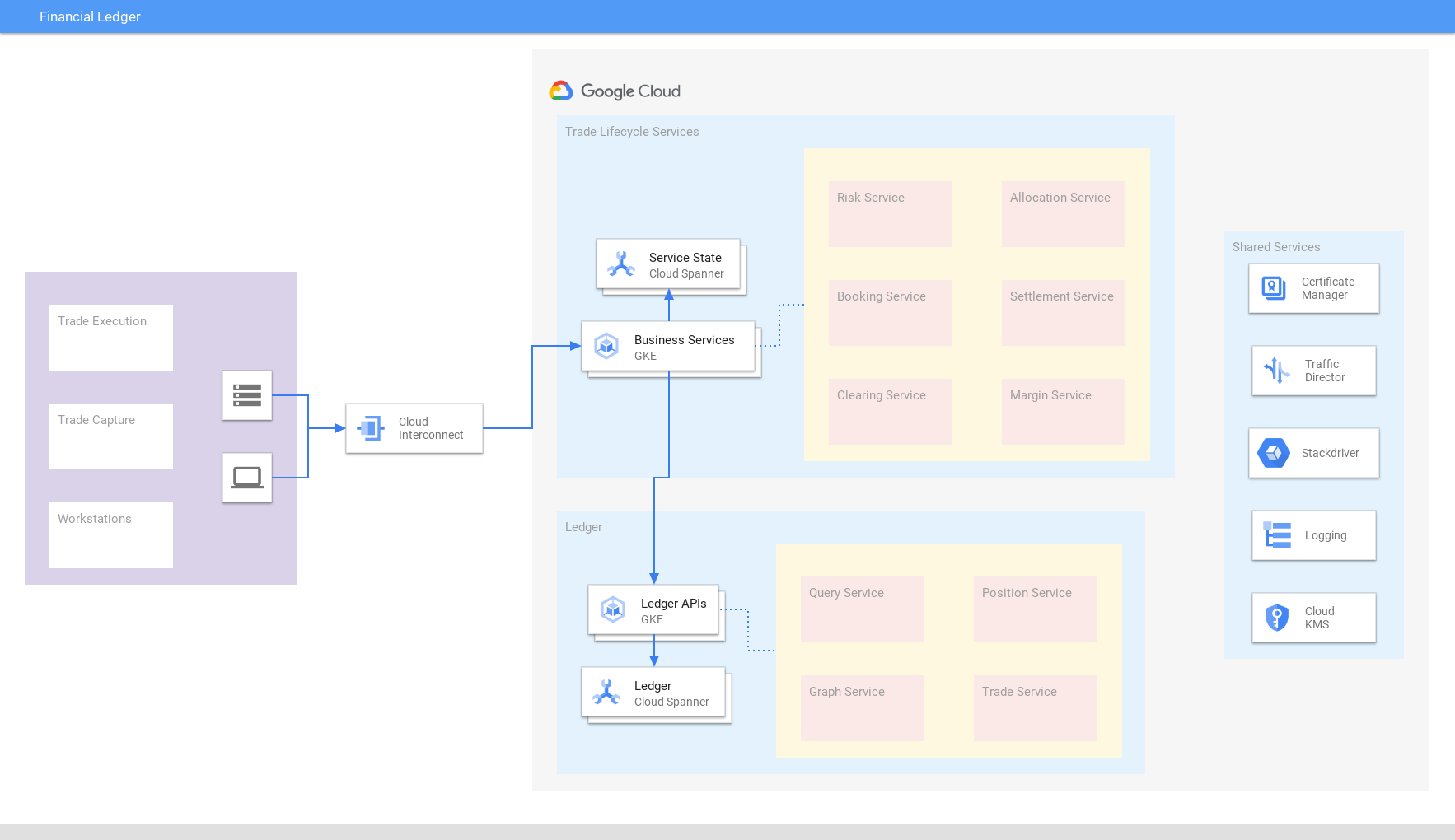
获取一致且最新的全球交易视图
将全球的财务交易、贸易、结算和头寸统一到基于 Spanner 构建的交易合并账目中,Spanner 可确保外部一致性和可伸缩性。整合数据有助于快速适应不断变化的市场情况和监管要求。同样,零售/电子商务企业使用 Spanner 来构建库存账目。
教程、快速入门和实验
获取一致且最新的全球交易视图
将全球的财务交易、贸易、结算和头寸统一到基于 Spanner 构建的交易合并账目中,Spanner 可确保外部一致性和可伸缩性。整合数据有助于快速适应不断变化的市场情况和监管要求。同样,零售/电子商务企业使用 Spanner 来构建库存账目。
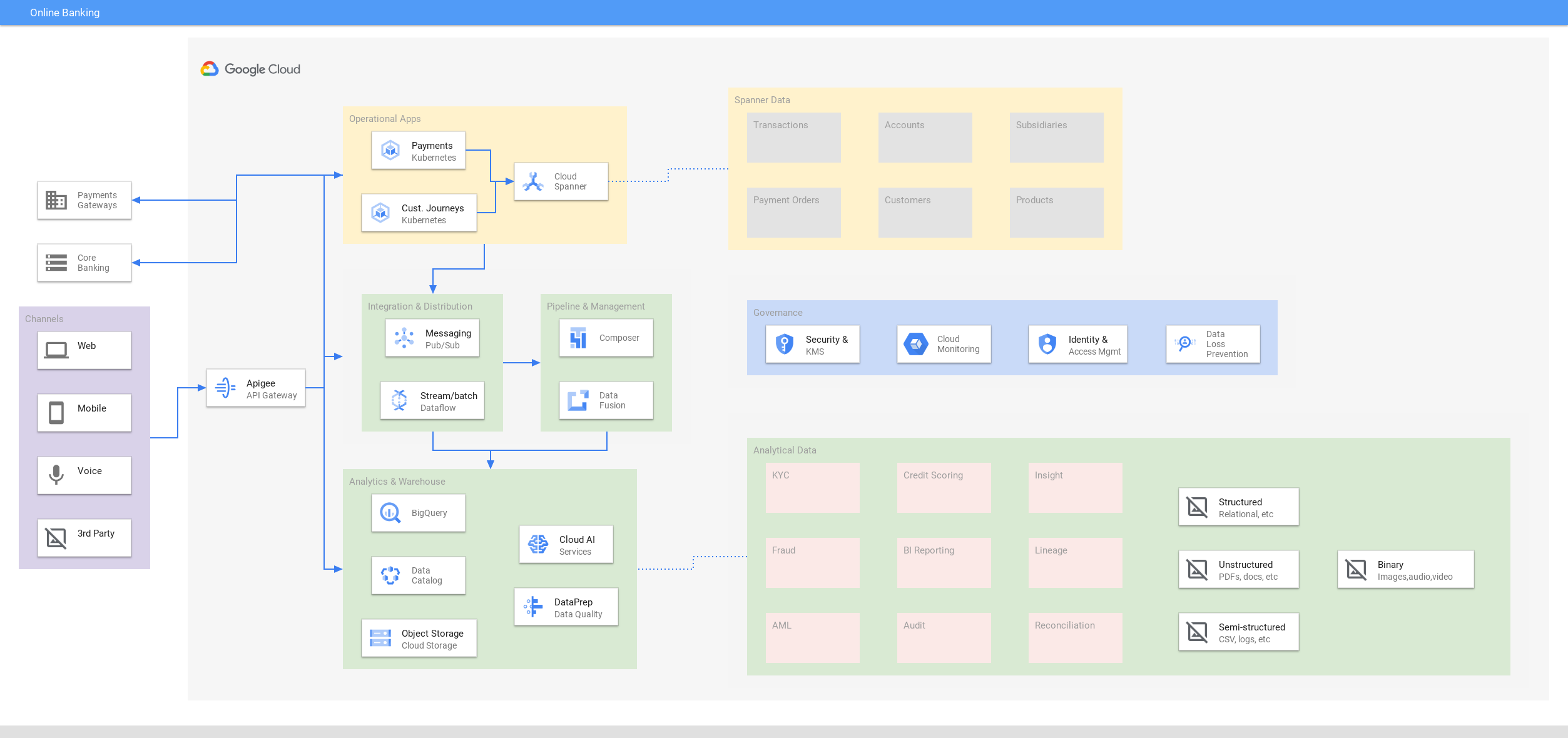
网上银行
提供始终在线交互的数字化体验
教程、快速入门和实验
提供始终在线交互的数字化体验
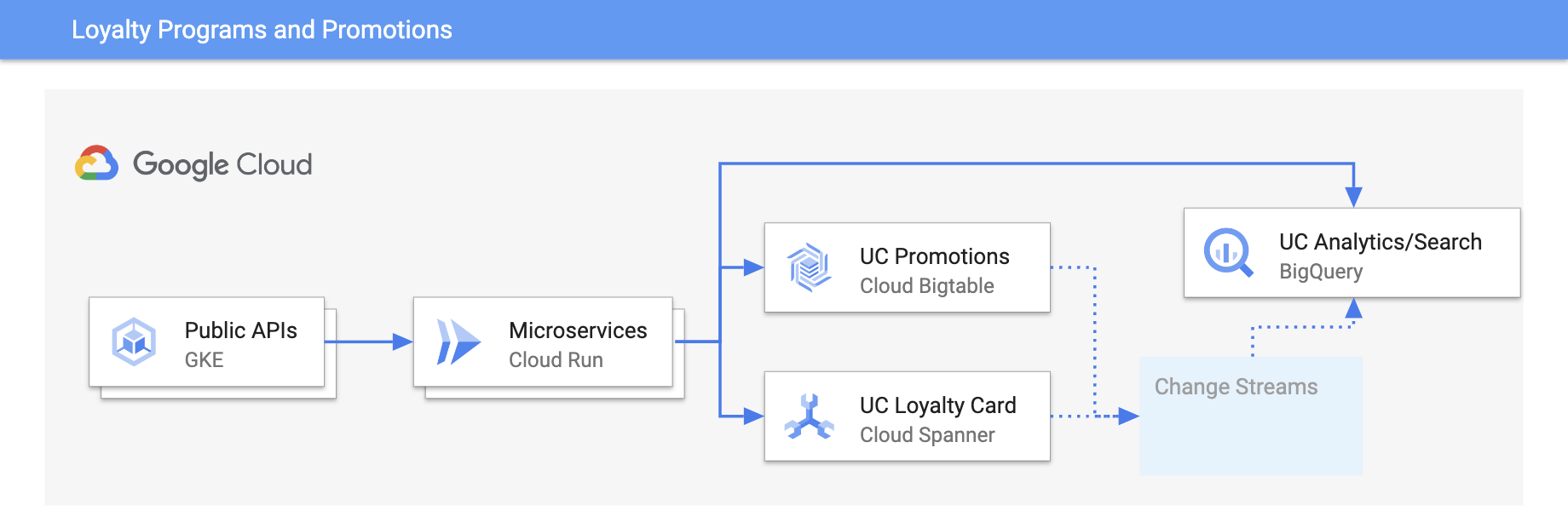
会员忠诚计划和推广活动
利用实时动态信息打造个性化体验
教程、快速入门和实验
利用实时动态信息打造个性化体验
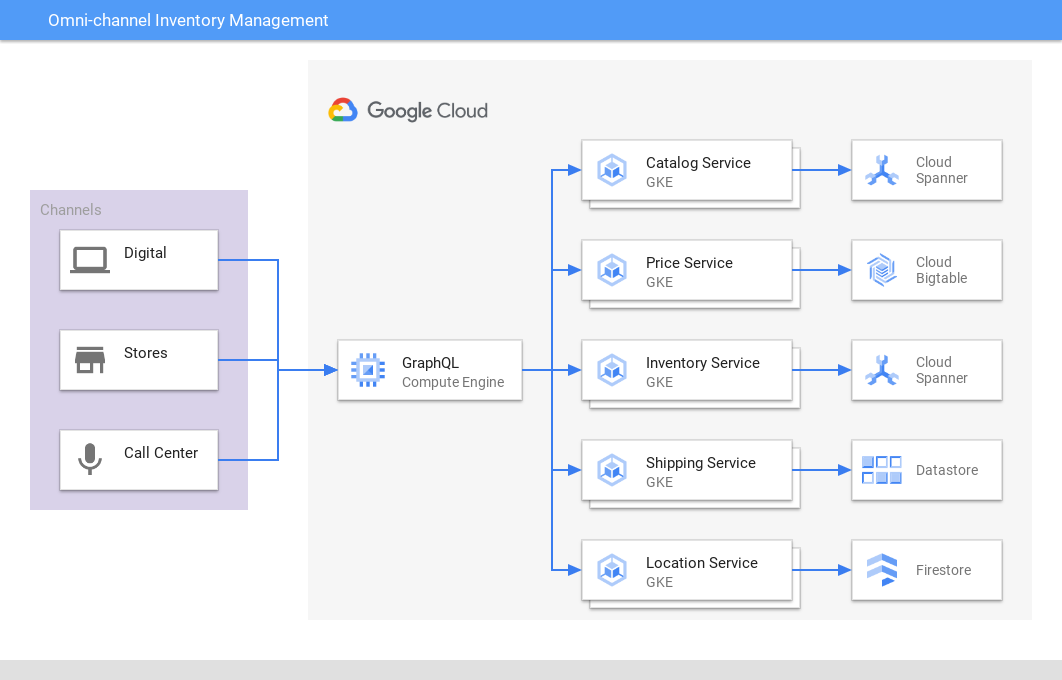
全渠道库存管理
跨多个渠道和应用提供一致的视图
Spanner 跨在线商店、实体店、配送中心和运输网络提供零售库存和订单的高性能单一事实来源,以使库存与需求相匹配,从而改善客户体验和盈利能力。同样,游戏公司使用 Spanner 来存储游戏内库存数据。
教程、快速入门和实验
跨多个渠道和应用提供一致的视图
Spanner 跨在线商店、实体店、配送中心和运输网络提供零售库存和订单的高性能单一事实来源,以使库存与需求相匹配,从而改善客户体验和盈利能力。同样,游戏公司使用 Spanner 来存储游戏内库存数据。
知识图谱
揭示数据中隐藏的关系和连接
揭示数据中隐藏的关系和连接
借助 Spanner Graph,您可以开发知识图谱来捕获实体(表示为节点)之间的复杂连接以及实体的关系(表示为边)。这些连接提供了丰富的上下文,因此对于开发知识库系统和推荐引擎而言,知识图谱具有重要价值。通过集成的搜索功能,您可以将语义理解、基于关键字的检索以及图表无缝地结合在一起,以获得全面的结果。
教程、快速入门和实验
揭示数据中隐藏的关系和连接
揭示数据中隐藏的关系和连接
借助 Spanner Graph,您可以开发知识图谱来捕获实体(表示为节点)之间的复杂连接以及实体的关系(表示为边)。这些连接提供了丰富的上下文,因此对于开发知识库系统和推荐引擎而言,知识图谱具有重要价值。通过集成的搜索功能,您可以将语义理解、基于关键字的检索以及图表无缝地结合在一起,以获得全面的结果。
价格
| Spanner 定价方式 | Spanner 价格基于计算容量、Spanner Data Boost、数据库存储空间、备份存储空间、复制和网络用量。计算价格因所选版本和配置而异。承诺使用折扣可以进一步降低计算价格。 | |
|---|---|---|
| 服务 | 说明 | 价格 (USD) |
计算 | 标准版 包含一整套成熟的功能,适用于区域级(单区域)配置 计算容量预配为处理单元或节点(1 个节点 = 1,000 个处理单元)。 | 起价 $0.030 每个副本每小时每 100 个处理单元 |
企业版 提供额外的多模型和高级搜索功能,可提高操作的简便性和效率 计算容量预配为处理单元或节点(1 个节点 = 1,000 个处理单元)。 | 起价 $0.041 每个副本每小时每 100 个处理单元 | |
企业 Plus 版 以最高级别的可用性、性能、合规性和治理级别,为要求最严苛的工作负载提供支持 计算容量预配为处理单元或节点(1 个节点 = 1,000 个处理单元)。 | 起价 $0.057 每个副本每小时每 100 个处理单元 | |
Data Boost | 按需、隔离的计算资源,包括 CPU、内存和本地数据传输 | 起价 $0.00117 每小时每个无服务器处理单元 |
数据库存储 | 价格基于数据库中存储的数据量,并包含读写副本和只读副本的存储费用;见证者副本是免费的。 SSD 存储空间 当您的运营数据需要低延迟和高吞吐量时,请使用 SSD 存储。 | 起价 $0.10 每个 SSD 副本,每 GB 每月 |
HDD 存储空间 对于不常访问且可以容忍较高读取延迟和较低吞吐量的数据,请使用 HDD 存储。您还可以配置分层政策,以便在指定时间窗口到期后将数据从 SSD 移动到 HDD。 | 起价 $0.02 每个 HDD 副本,每 GB 每月 | |
备份存储 | 单区域配置 价格基于备份存储空间容量,包括所有副本的存储费用。 | 起价 $0.10 每月每 GB(包括所有副本) |
双区域和多区域配置 价格基于备份存储空间容量,包括所有副本的存储费用。 | 起价 $0.30 每月每 GB(包括所有副本) | |
复制 | 区域内复制 | 免费 |
区域间复制 | 起价 $0.04 每 GB | |
网络 | 入站 | 免费 |
区域内出站流量 | 免费 | |
区域间出站流量 | 起价 $0.01 每 GB | |
Spanner 定价方式
Spanner 价格基于计算容量、Spanner Data Boost、数据库存储空间、备份存储空间、复制和网络用量。计算价格因所选版本和配置而异。承诺使用折扣可以进一步降低计算价格。
标准版
包含一整套成熟的功能,适用于区域级(单区域)配置
计算容量预配为处理单元或节点(1 个节点 = 1,000 个处理单元)。
Starting at
$0.030
每个副本每小时每 100 个处理单元
企业版
提供额外的多模型和高级搜索功能,可提高操作的简便性和效率
计算容量预配为处理单元或节点(1 个节点 = 1,000 个处理单元)。
Starting at
$0.041
每个副本每小时每 100 个处理单元
企业 Plus 版
以最高级别的可用性、性能、合规性和治理级别,为要求最严苛的工作负载提供支持
计算容量预配为处理单元或节点(1 个节点 = 1,000 个处理单元)。
Starting at
$0.057
每个副本每小时每 100 个处理单元
Data Boost
按需、隔离的计算资源,包括 CPU、内存和本地数据传输
Starting at
$0.00117
每小时每个无服务器处理单元
数据库存储
价格基于数据库中存储的数据量,并包含读写副本和只读副本的存储费用;见证者副本是免费的。
SSD 存储空间
当您的运营数据需要低延迟和高吞吐量时,请使用 SSD 存储。
Starting at
$0.10
每个 SSD 副本,每 GB 每月
HDD 存储空间
对于不常访问且可以容忍较高读取延迟和较低吞吐量的数据,请使用 HDD 存储。您还可以配置分层政策,以便在指定时间窗口到期后将数据从 SSD 移动到 HDD。
Starting at
$0.02
每个 HDD 副本,每 GB 每月
备份存储
单区域配置
价格基于备份存储空间容量,包括所有副本的存储费用。
Starting at
$0.10
每月每 GB(包括所有副本)
双区域和多区域配置
价格基于备份存储空间容量,包括所有副本的存储费用。
Starting at
$0.30
每月每 GB(包括所有副本)
复制
区域内复制
免费
区域间复制
Starting at
$0.04
每 GB
网络
入站
免费
区域内出站流量
免费
区域间出站流量
Starting at
$0.01
每 GB
业务用例
了解其他企业如何借助 Spanner 构建创新应用、提供出色的客户体验、降低费用并提高投资回报率。




精选产品优势和客户案例
利用可无限扩缩以满足任何需求的创新应用拓展您的业务。
降低总拥有成本,让您的开发者从繁琐的运营中解放出来,实现远大目标并提高工作效率。
优越的性价比,用多少,付多少,每月低至 $40。















合作伙伴与集成
从评估和业务案例,到迁移和在 Spanner 上构建新应用,具备 Spanner 专业知识的合作伙伴可在您整个历程的每一步提供帮助。











系统集成商
Spanner 合作伙伴可帮助您对应用进行现代化改造并无缝迁移到云端。您可以在我们的名录中找到理想的合作伙伴或第三方集成服务。
常见问题解答
Spanner 是关系型数据库还是非关系型数据库?
Spanner 将关系型、键值对、图表和向量搜索工作负载整合到同一数据库,从而简化数据架构。Spanner 是一个扩缩能力极强的数据库,它将无限扩缩能力与关系型语义(例如二级索引、强一致性、架构和 SQL)相结合,通过一个简单的解决方案提供 99.999% 的可用性。因此,它同时适用于关系型工作负载和非关系型工作负载。
Spanner 是否使用 SQL?
如何将数据库迁移到 Spanner?
将现有工作负载迁移到 Spanner,为未来的业务增长奠定基础,且不必在可靠性或性价比上做出妥协。如今,各行各业的创新型组织都在使用 Spanner 的多模型接口,处理来自关系型数据库(如 MySQL 和 SQL)、键值存储(如 Cassandra 和 DynamoDB),以及图形、搜索和文档工具的运营工作负载。迁移的具体方法将取决于数据量、性能 SLO 和可用性方面的要求。Spanner 迁移工具可为分片的 MySQL 和 Cassandra 数据库提供端到端评估、架构和数据迁移,以及低停机时间切换,同时还为 PostgreSQL 提供评估和迁移服务。我们拥有一个由优质技术和服务合作伙伴组成的网络,可帮助您加快从几乎任何来源迁移的速度。
运营 Spanner 的关键注意事项是什么?
Spanner 是一个全代管式数据库,因此它自动提供全面的基础架构管理功能,但根据您的工作负载,您可能需要执行一些应用特定的管理操作。您需要确保设置适当的提醒和监控功能,并密切监控,以确保生产始终顺利运行。您需要了解当流量自然增长、或者预计将出现流量峰值时需要执行什么操作,或者如何处理应用 bug 导致的数据损坏,最后但同样重要的是,如何排查性能问题并了解什么组件造成延迟时间增加。











