
Spanner
Base de datos siempre disponible con una escala prácticamente ilimitada
Crea aplicaciones inteligentes con una única base de datos que aúna datos relacionales, gráficos, de pares clave-valor y de búsqueda. Al no tener ventanas de mantenimiento, podrás usar aplicaciones esenciales sin interrupciones.
Además, los nuevos clientes de Google Cloud reciben 300 USD en crédito gratis.

Características
Multimodelo: una base de datos, muchas posibilidades
Las funciones multimodelo de Spanner te permiten crear aplicaciones inteligentes basadas en IA sobre tus datos operativos relacionales y NoSQL aprovechando la integración nativa de Vertex AI, Spanner Graph para consultar relaciones complejas, la búsqueda de vectores para la búsqueda semántica y la búsqueda de texto completo integrada, todo ello con una interoperabilidad "verdaderamente ZeroETL". Esta estrategia unificada elimina los silos de datos, ahorra costes, reduce los puntos de contacto operativos y de seguridad, y garantiza la coherencia de los datos en todos los modelos.

Escalabilidad sin esfuerzo
Tienes grandes ambiciones, pero puedes empezar con poco y escalar sin esfuerzo a medida que tus necesidades cambien. Spanner gestiona a la perfección los conjuntos de datos en crecimiento y las cargas de trabajo exigentes gracias a su escalabilidad horizontal de lectura y escritura. El fragmentado automático de la base de datos garantiza una distribución óptima de los datos, mientras que la partición geográfica acerca los datos a los usuarios para reducir la latencia. Disfruta de un rendimiento alto y constante con el procesamiento de consultas aislado de las cargas de trabajo con Spanner Data Boost, incluso durante los picos de demanda.

Disponibilidad continua
Asegúrate de que tus aplicaciones estén siempre disponibles para servir a tus usuarios. Spanner ofrece una disponibilidad de hasta el 99,999 % con mantenimiento automatizado y opciones de implementación flexibles. Elige entre configuraciones de una sola región, dos regiones o varias regiones para que se adapten a tus requisitos específicos de disponibilidad y tolerancia a fallos.

Transacciones coherentes garantizadas
Despídete de las incoherencias de los datos y de las dificultades que entraña gestionarlos. Spanner garantiza una consistencia transaccional sólida, lo que significa que cada lectura refleja las actualizaciones más recientes, independientemente del tamaño o la distribución de tus datos. Crea aplicaciones con confianza, sabiendo que siempre tendrán una vista coherente de tus datos.
Seguridad y cumplimiento de confianza
Confía tus datos a una plataforma segura y conforme con Spanner. Disfruta de una administración y un control centralizados con Database Center, que simplifica la gestión de bases de datos en la nube. Spanner ofrece seguridad y controles de nivel empresarial, como el cifrado de datos en reposo y en tránsito, la gestión de accesos detallada a través de Gestión de Identidades y Accesos (IAM) y el cumplimiento de estándares del sector. Protege aún más tus datos con funciones sólidas de copia de seguridad y restauración, como la recuperación a un momento dado, que te ofrece la tranquilidad que necesitas en tus operaciones.
Comparación de bases de datos
| Atributo de base de datos | Otra base de datos relacional | Otra base de datos no relacional | Spanner |
|---|---|---|---|
Esquema | Estática | Dinámico | Dinámico |
SQL | Sí | No | Sí (PostgreSQL, Google SQL) |
Transacciones | ACID (atomicidad, coherencia, aislamiento, durabilidad) | Eventualmente | ACID fuertes con el orden de TrueTime |
Escalabilidad | Vertical (usar un equipo mayor) | Horizontal (añadir más equipos) | Horizontal |
Disponibilidad | Conmutación por error (período de inactividad) | Alta | Acuerdo de nivel de servicio alto del 99,999 % |
Replicación | Se pueden configurar. | Se pueden configurar. | Automática |
Gartner® ha clasificado Spanner como la solución número 1 para casos prácticos de transacciones ligeras. Descarga el informe completo.
Esquema
Estática
Dinámico
Dinámico
SQL
Sí
No
Sí
(PostgreSQL, Google SQL)
Transacciones
ACID
(atomicidad, coherencia, aislamiento, durabilidad)
Eventualmente
ACID fuertes
con el orden de TrueTime
Escalabilidad
Vertical
(usar un equipo mayor)
Horizontal
(añadir más equipos)
Horizontal
Disponibilidad
Conmutación por error (período de inactividad)
Alta
Acuerdo de nivel de servicio alto del 99,999 %
Replicación
Se pueden configurar.
Se pueden configurar.
Automática
Gartner® ha clasificado Spanner como la solución número 1 para casos prácticos de transacciones ligeras. Descarga el informe completo.
Cómo funciona
Las instancias de Spanner ofrecen recursos de computación y almacenamiento en una o varias zonas. Gracias a un reloj distribuido denominado TrueTime, las transacciones se mantienen siempre igual en todas las zonas. Los datos se "dividen" automáticamente para ofrecer escalabilidad y se replican mediante un esquema síncrono y basado en Paxos para comprobar la disponibilidad.
Las instancias de Spanner ofrecen recursos de computación y almacenamiento en una o varias zonas. Gracias a un reloj distribuido denominado TrueTime, las transacciones se mantienen siempre igual en todas las zonas. Los datos se "dividen" automáticamente para ofrecer escalabilidad y se replican mediante un esquema síncrono y basado en Paxos para comprobar la disponibilidad.

Usos habituales
Migración y modernización
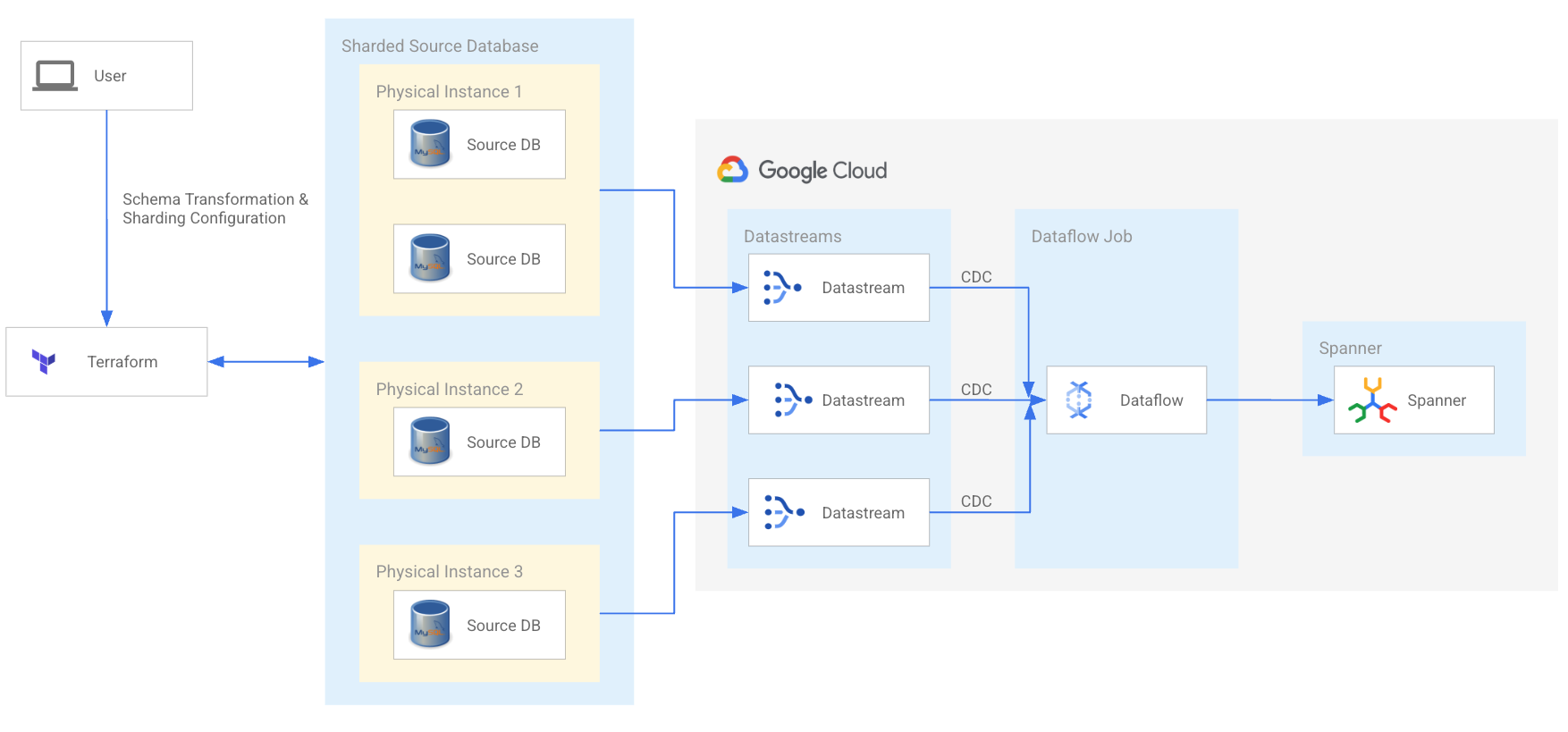
Modernizar MySQL y Cassandra de forma eficiente
Modernizar MySQL y Cassandra de forma eficiente
Moderniza tus cargas de trabajo fragmentadas de MySQL y Cassandra para potenciar a tus equipos de desarrollo y escalar de cara a la siguiente fase de crecimiento. Aprovecha la herramienta de migración de código abierto Spanner y una red de partners tecnológicos y de servicios cualificados que pueden optimizar tu migración.
Tutoriales, guías de inicio rápido y experimentos
Modernizar MySQL y Cassandra de forma eficiente
Modernizar MySQL y Cassandra de forma eficiente
Moderniza tus cargas de trabajo fragmentadas de MySQL y Cassandra para potenciar a tus equipos de desarrollo y escalar de cara a la siguiente fase de crecimiento. Aprovecha la herramienta de migración de código abierto Spanner y una red de partners tecnológicos y de servicios cualificados que pueden optimizar tu migración.
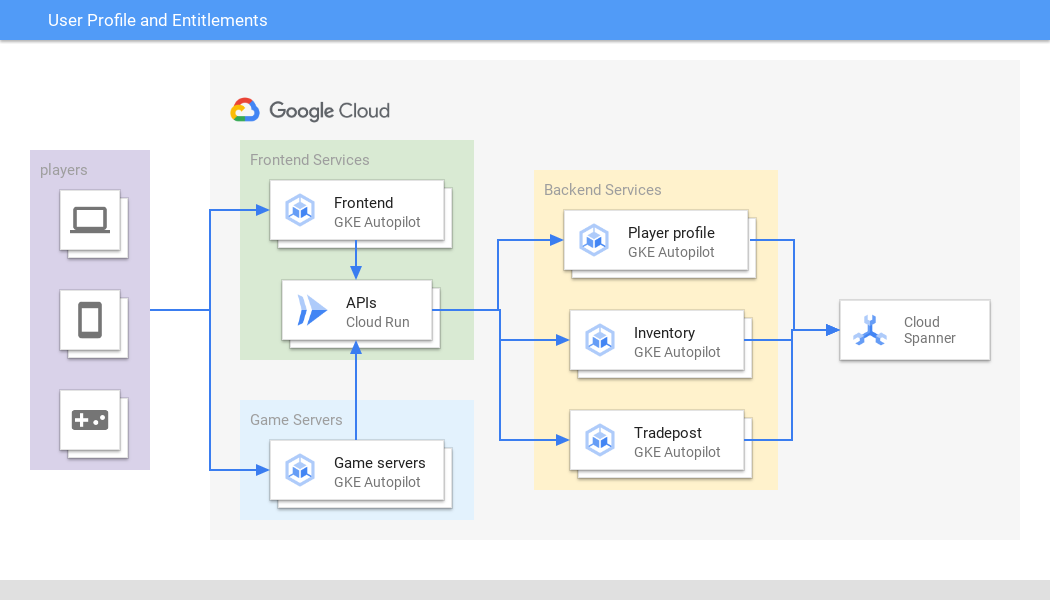
Perfil de usuario y derechos
Gestionar de forma segura los datos más importantes de los usuarios a cualquier escala
Tutoriales, guías de inicio rápido y experimentos
Gestionar de forma segura los datos más importantes de los usuarios a cualquier escala
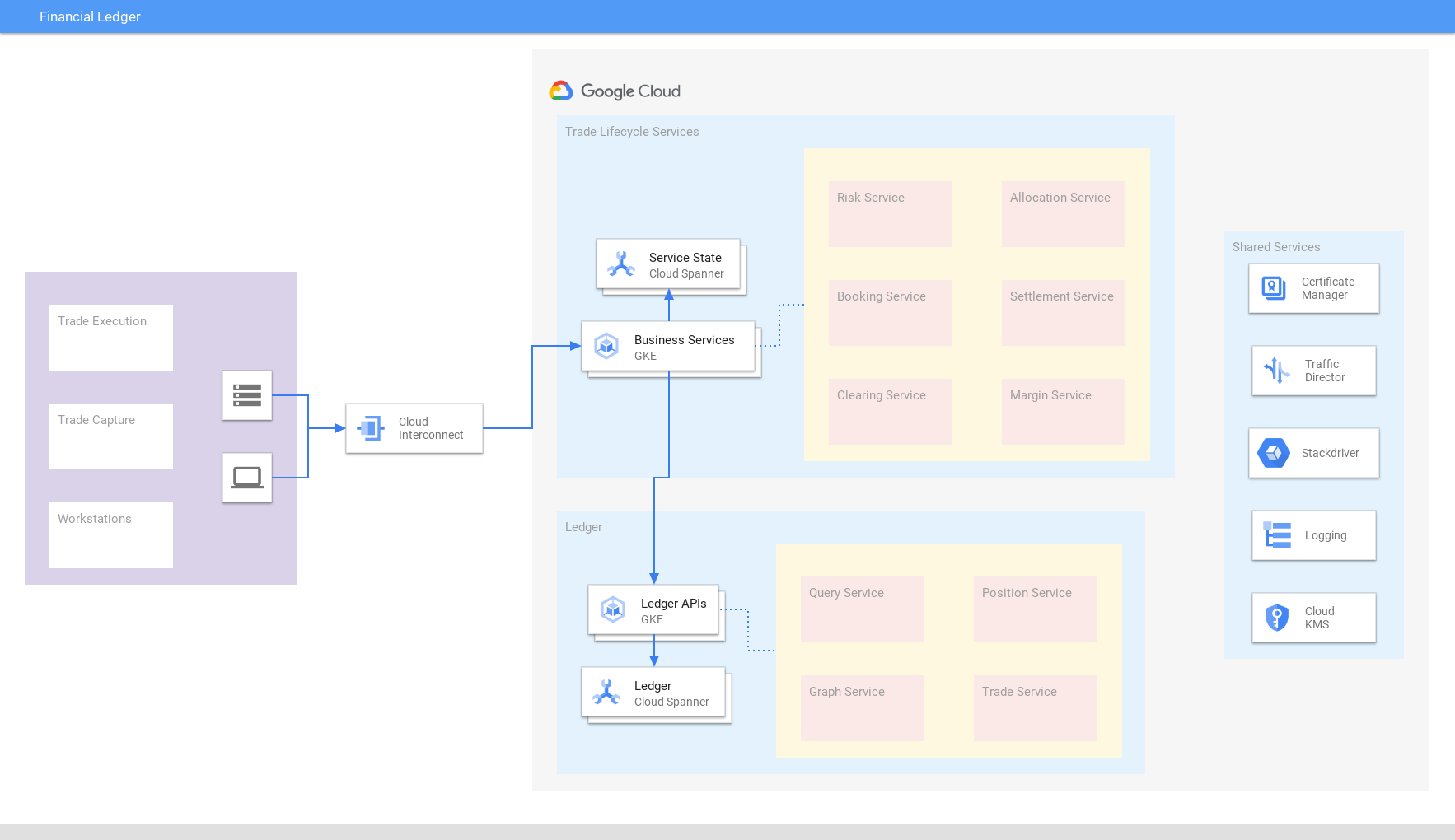
Libro de contabilidad
Obtener una vista actualizada y coherente de las transacciones globales
Unifica transacciones financieras, operaciones, liquidaciones y posiciones de todo el mundo en un libro de operaciones comercial consolidado basado en Spanner que garantiza la coherencia y la escalabilidad externas. La consolidación de datos ayuda a adaptarse rápidamente a los cambios en los requisitos normativos y las condiciones del mercado. Del mismo modo, las empresas de comercio electrónico y minorista usan Spanner para llevar un registro del inventario.
Tutoriales, guías de inicio rápido y experimentos
Obtener una vista actualizada y coherente de las transacciones globales
Unifica transacciones financieras, operaciones, liquidaciones y posiciones de todo el mundo en un libro de operaciones comercial consolidado basado en Spanner que garantiza la coherencia y la escalabilidad externas. La consolidación de datos ayuda a adaptarse rápidamente a los cambios en los requisitos normativos y las condiciones del mercado. Del mismo modo, las empresas de comercio electrónico y minorista usan Spanner para llevar un registro del inventario.
Banca online
Ofrecer interactividad siempre activa en las experiencias digitales
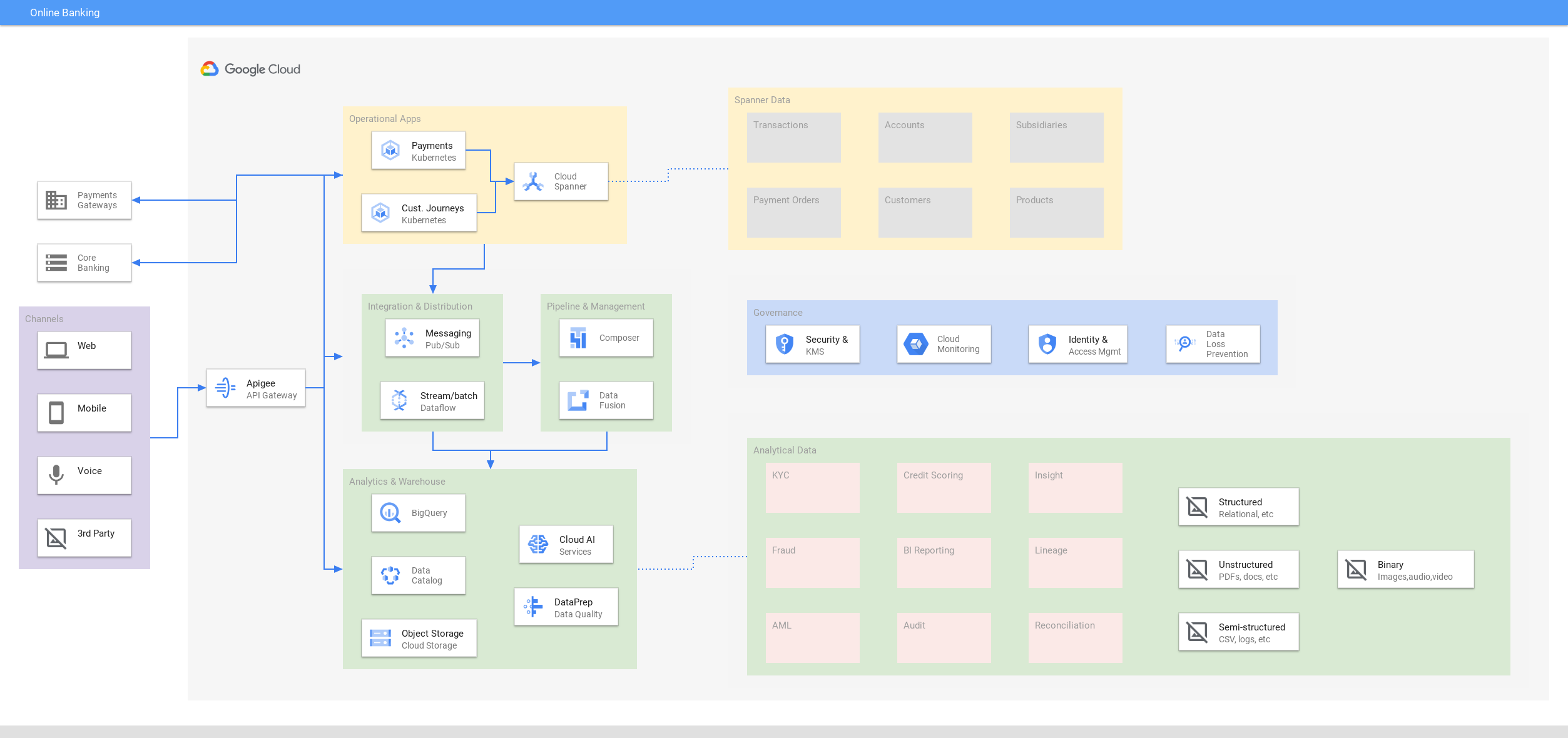
Tutoriales, guías de inicio rápido y experimentos
Ofrecer interactividad siempre activa en las experiencias digitales
Promociones y programas de fidelización
Personaliza las experiencias con actualizaciones en tiempo real
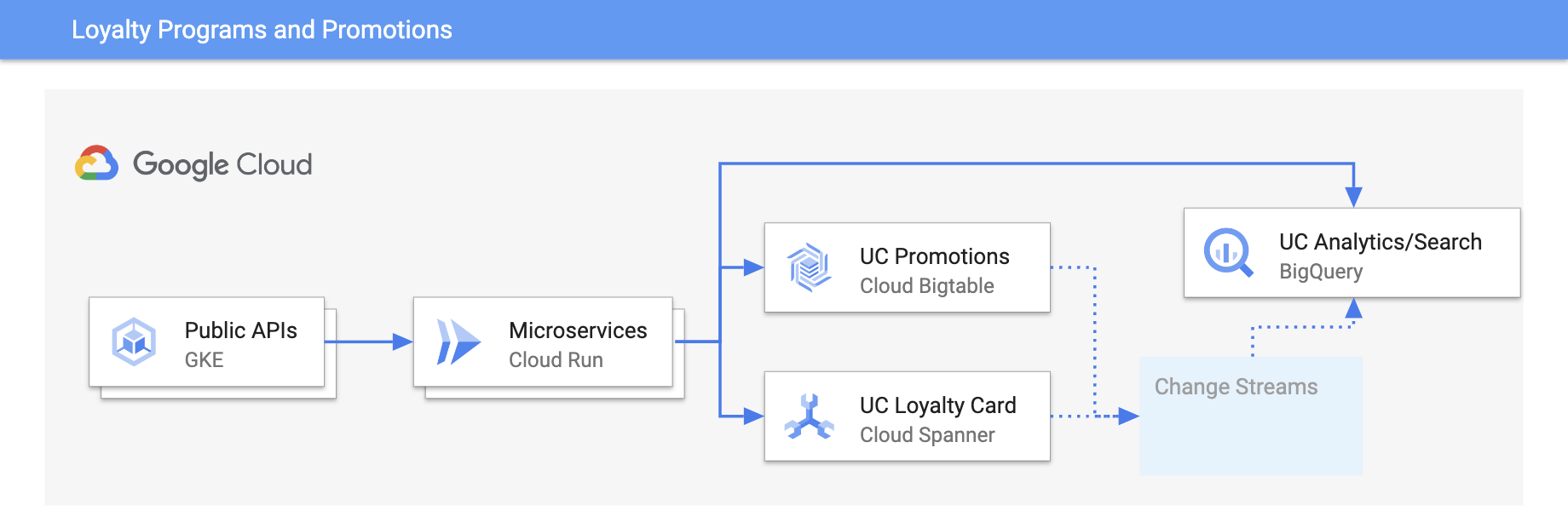
Tutoriales, guías de inicio rápido y experimentos
Personaliza las experiencias con actualizaciones en tiempo real
Gestión de inventario omnicanal
Proporciona una vista coherente en varios canales y aplicaciones
Spanner ofrece una única fuente de información y de alto rendimiento para el inventario y los pedidos de los comercios minoristas, online, en tiendas y de distribución, así como envíos que relacionan el inventario con la demanda y mejoran la experiencia de usuario y la rentabilidad. De forma similar, las empresas de videojuegos usan Spanner para almacenar datos de inventario de los juegos.
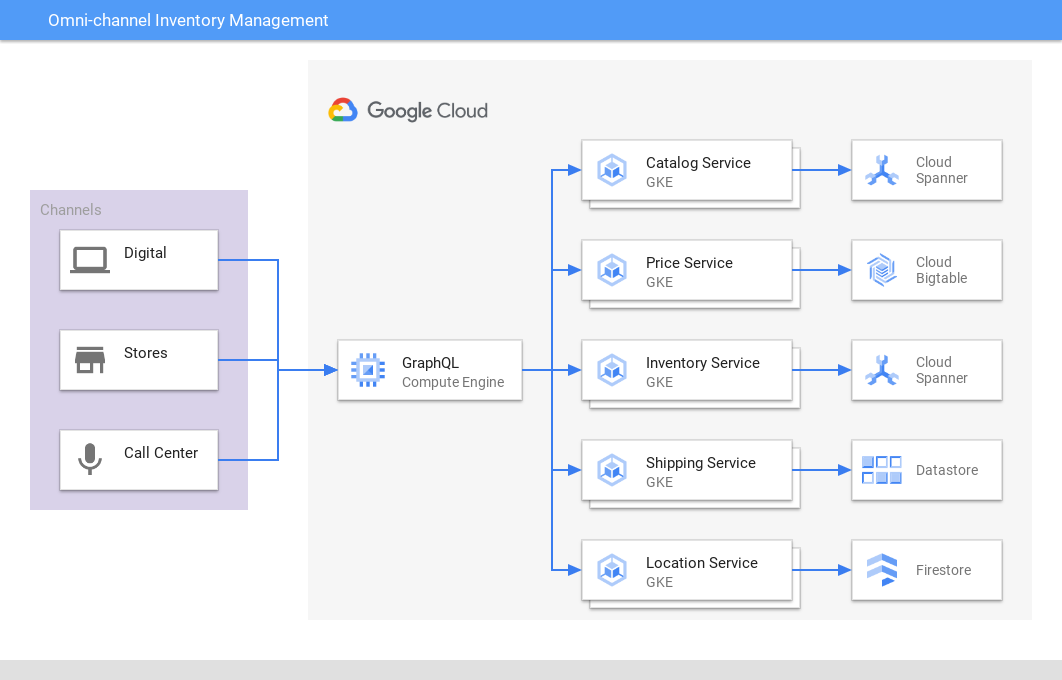
Tutoriales, guías de inicio rápido y experimentos
Proporciona una vista coherente en varios canales y aplicaciones
Spanner ofrece una única fuente de información y de alto rendimiento para el inventario y los pedidos de los comercios minoristas, online, en tiendas y de distribución, así como envíos que relacionan el inventario con la demanda y mejoran la experiencia de usuario y la rentabilidad. De forma similar, las empresas de videojuegos usan Spanner para almacenar datos de inventario de los juegos.
Gráfico de conocimiento
Revela relaciones y conexiones ocultas en tus datos
Revela relaciones y conexiones ocultas en tus datos
Spanner Graph te permite desarrollar gráficos de conocimiento que capturen las complejas conexiones entre entidades, representadas como nodos, y sus relaciones, representadas como aristas. Estas conexiones proporcionan contexto enriquecido, lo que hace que los gráficos de conocimiento sean muy útiles para desarrollar sistemas de base de conocimientos y motores de recomendaciones. Con las funciones de búsqueda integradas, puedes combinar a la perfección la comprensión semántica, la recuperación basada en palabras clave y los gráficos para obtener resultados exhaustivos.
Tutoriales, guías de inicio rápido y experimentos
Revela relaciones y conexiones ocultas en tus datos
Revela relaciones y conexiones ocultas en tus datos
Spanner Graph te permite desarrollar gráficos de conocimiento que capturen las complejas conexiones entre entidades, representadas como nodos, y sus relaciones, representadas como aristas. Estas conexiones proporcionan contexto enriquecido, lo que hace que los gráficos de conocimiento sean muy útiles para desarrollar sistemas de base de conocimientos y motores de recomendaciones. Con las funciones de búsqueda integradas, puedes combinar a la perfección la comprensión semántica, la recuperación basada en palabras clave y los gráficos para obtener resultados exhaustivos.
Precios
| Cómo funcionan los precios de Spanner | Los precios de Spanner se basan en la capacidad de computación, Data Boost de Spanner, el almacenamiento en bases de datos, el almacenamiento de copias de seguridad, la replicación y el uso de redes. Los precios de Compute varían en función de la edición y la configuración que elijas. Los descuentos por uso confirmado pueden reducir aún más el precio. | |
|---|---|---|
| Servicio | Descripción | Precio (USD) |
Computación | Edición Estándar Incluye un completo paquete de funciones consolidadas para configuraciones regionales (de una sola región) La capacidad de computación se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1000 unidades de procesamiento). | Desde 0,03 USD por 100 unidades de procesamiento por hora y réplica |
Edición Enterprise Ofrece funciones de búsqueda multimodelo y avanzadas adicionales con una mayor simplicidad y eficiencia operativas La capacidad de computación se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1000 unidades de procesamiento). | Desde 0,041 USD por 100 unidades de procesamiento por hora y réplica | |
Edición Enterprise Plus Cubre las necesidades de las cargas de trabajo más exigentes con los niveles más altos de disponibilidad, rendimiento, cumplimiento y gobernanza La capacidad de computación se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1000 unidades de procesamiento). | Desde 0,057 USD por 100 unidades de procesamiento por hora y réplica | |
Data Boost | Recursos de computación aislados y bajo demanda, como CPU, memoria y transferencia de datos local | Desde 0,00117 USD por unidad de procesamiento sin servidor por hora |
Almacenamiento en bases de datos | El precio se basa en la cantidad de datos almacenados en la base de datos e incluye el coste de almacenamiento en las réplicas de lectura y escritura y en las de solo lectura. La réplica testigo no tiene coste. Almacenamiento en SSD Usa el almacenamiento en SSD cuando necesites una latencia baja y un rendimiento alto para tus datos operativos. | Desde 0,10 USD por GB al mes por réplica para SSD |
Espacio de almacenamiento en HDD Usa el almacenamiento en HDD para los datos a los que se necesite acceder con menos frecuencia y que puedan tolerar latencias de lectura más altas y un rendimiento reducido. También puedes configurar políticas de clasificación para que los datos pasen de la SSD a la HDD cuando se cumpla un periodo de tiempo determinado. | Desde 0,02 USD por GB al mes por réplica en HDD | |
Almacenamiento de copias de seguridad | Configuración regional El precio se basa en la cantidad de almacenamiento de copia de seguridad e incluye el coste de almacenamiento en las réplicas. | Desde 0,10 USD por GB al mes (incluidas todas las réplicas) |
Configuración dual y multirregional El precio se basa en la cantidad de almacenamiento de copia de seguridad e incluye el coste de almacenamiento en las réplicas. | Desde 0,30 USD por GB al mes (incluidas todas las réplicas) | |
Replicación | Réplica en la misma región | Gratis |
Replicación interregional | Desde 0,04 USD Por GB | |
Red | Ingress | Gratis |
Salida en la misma región | Gratis | |
Salida entre regiones | Desde 0,01 USD Por GB | |
Consulta más información sobre los precios y los descuentos por uso confirmado de Spanner.
Cómo funcionan los precios de Spanner
Los precios de Spanner se basan en la capacidad de computación, Data Boost de Spanner, el almacenamiento en bases de datos, el almacenamiento de copias de seguridad, la replicación y el uso de redes. Los precios de Compute varían en función de la edición y la configuración que elijas. Los descuentos por uso confirmado pueden reducir aún más el precio.
Edición Estándar
Incluye un completo paquete de funciones consolidadas para configuraciones regionales (de una sola región)
La capacidad de computación se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1000 unidades de procesamiento).
Starting at
0,03 USD
por 100 unidades de procesamiento por hora y réplica
Edición Enterprise
Ofrece funciones de búsqueda multimodelo y avanzadas adicionales con una mayor simplicidad y eficiencia operativas
La capacidad de computación se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1000 unidades de procesamiento).
Starting at
0,041 USD
por 100 unidades de procesamiento por hora y réplica
Edición Enterprise Plus
Cubre las necesidades de las cargas de trabajo más exigentes con los niveles más altos de disponibilidad, rendimiento, cumplimiento y gobernanza
La capacidad de computación se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1000 unidades de procesamiento).
Starting at
0,057 USD
por 100 unidades de procesamiento por hora y réplica
Data Boost
Recursos de computación aislados y bajo demanda, como CPU, memoria y transferencia de datos local
Starting at
0,00117 USD
por unidad de procesamiento sin servidor por hora
Almacenamiento en bases de datos
El precio se basa en la cantidad de datos almacenados en la base de datos e incluye el coste de almacenamiento en las réplicas de lectura y escritura y en las de solo lectura. La réplica testigo no tiene coste.
Almacenamiento en SSD
Usa el almacenamiento en SSD cuando necesites una latencia baja y un rendimiento alto para tus datos operativos.
Starting at
0,10 USD
por GB al mes por réplica para SSD
Espacio de almacenamiento en HDD
Usa el almacenamiento en HDD para los datos a los que se necesite acceder con menos frecuencia y que puedan tolerar latencias de lectura más altas y un rendimiento reducido. También puedes configurar políticas de clasificación para que los datos pasen de la SSD a la HDD cuando se cumpla un periodo de tiempo determinado.
Starting at
0,02 USD
por GB al mes por réplica en HDD
Almacenamiento de copias de seguridad
Configuración regional
El precio se basa en la cantidad de almacenamiento de copia de seguridad e incluye el coste de almacenamiento en las réplicas.
Starting at
0,10 USD
por GB al mes (incluidas todas las réplicas)
Configuración dual y multirregional
El precio se basa en la cantidad de almacenamiento de copia de seguridad e incluye el coste de almacenamiento en las réplicas.
Starting at
0,30 USD
por GB al mes (incluidas todas las réplicas)
Replicación
Réplica en la misma región
Gratis
Replicación interregional
Starting at
0,04 USD
Por GB
Red
Ingress
Gratis
Salida en la misma región
Gratis
Salida entre regiones
Starting at
0,01 USD
Por GB
Consulta más información sobre los precios y los descuentos por uso confirmado de Spanner.
Caso de negocio
Descubre cómo han creado aplicaciones innovadoras otras empresas para ofrecer una experiencia excelente a sus clientes, reducir costes y aumentar el retorno de inversión con Spanner.
- El estudio Total Economic Impact™ de Forrester muestra que Spanner ofrece un retorno de inversión del 132 %, un periodo de amortización de 9 meses y beneficios de varios millones de dólares para una organización hipotética representativa. Descarga el estudio completo para obtener más información.
- Gartner® identifica 13 prestaciones cruciales para las bases de datos operativas y sitúa a Spanner en el primer puesto en el caso práctico de transacciones ligeras. Descarga el informe completo.

¿Cómo se escala Uber a millones de solicitudes simultáneas?
Descubre cómo rediseñó Uber su plataforma de cumplimiento con Spanner.



Ventajas y clientes destacados
Haz crecer tu negocio con aplicaciones innovadoras que se escalan sin límites para satisfacer cualquier demanda.
Reduce el CTP y libera a tus desarrolladores de operaciones tediosas para soñar a lo grande y agilizar el proceso.
Disfruta de una relación precio-rendimiento superior y paga por lo que uses, a partir de solo 40 USD al mes.















Partners e integración
Aprovecha las ventajas de los partners con experiencia en Spanner que te ayudarán en cada paso del proceso, desde las evaluaciones y el caso de negocio hasta las migraciones y la creación de nuevas aplicaciones en Spanner.











Integradores de sistemas
Los partners de Spanner te ayudan a modernizar aplicaciones y migrar a la nube sin problemas. Encuentra el partner o la integración con terceros ideal en nuestro directorio.
Preguntas frecuentes
¿Spanner es una base de datos relacional o no relacional?
Spanner simplifica la arquitectura de datos combinando cargas de trabajo de búsqueda relacional, de pares clave-valor, de gráficos y de vectores en la misma base de datos. Es una base de datos de alta escalabilidad que combina escalabilidad ilimitada con semánticas relacionales, como índices secundarios, coherencia fija, esquemas y SQL. Por ello, ofrece una disponibilidad del 99,999 % en una sencilla solución, así que es apropiada para cargas de trabajo tanto relacionales como no relacionales.
¿Spanner usa SQL?
Spanner proporciona dos dialectos SQL basados en ANSI en el mismo conjunto enriquecido de funciones: GoogleSQL y PostgreSQL. GoogleSQL comparte sintaxis con BigQuery para que los equipos puedan estandarizar los flujos de trabajo de gestión de datos. La interfaz PostgreSQL resulta familiar a los equipos que ya conocen PostgreSQL, y proporciona portabilidad de esquemas y consultas a otros entornos de PostgreSQL. Para obtener más información sobre la interfaz PostgreSQL para Spanner, consulta nuestra documentación.
¿Cómo migro bases de datos a Spanner?
La migración de las cargas de trabajo a Spanner garantiza una base para el crecimiento futuro sin tener que renunciar a la fiabilidad ni al precio-rendimiento. La interfaz multimodelo de Spanner la usan hoy en día empresas innovadoras de distintos sectores con cargas de trabajo operativas procedentes de bases de datos relacionales, como MySQL y SQL Server, y de almacenes de valores clave, como Cassandra o DynamoDB, junto con herramientas de gráficos, búsqueda y documentos. El enfoque concreto de la migración dependerá de los requisitos en cuanto al volumen de datos, los objetivos de nivel de servicio de rendimiento y la disponibilidad. La herramienta de migración de Spanner proporciona una evaluación integral, migración de esquemas y datos, y cambio con poco tiempo de inactividad para las bases de datos fragmentadas de MySQL y Cassandra, así como la evaluación y la migración para PostgreSQL. Una red cualificada de partners de tecnología y servicios puede agilizar las migraciones desde prácticamente cualquier fuente.
¿Cuáles son las consideraciones clave para utilizar Spanner?
Spanner es una base de datos totalmente gestionada, por lo que ofrece funciones completas de gestión de la infraestructura. No obstante, en función de tu carga de trabajo, es posible que debas llevar a cabo determinadas acciones de gestión según cada aplicación. Debes asegurarte de que has configurado las alertas y la monitorización adecuadas, y de que las estás supervisando detenidamente para que la producción se ejecute siempre sin problemas. Debes conocer las medidas que tomar cuando el tráfico crece de forma orgánica con el tiempo, si hay un pico de tráfico esperado o cómo gestionar la corrupción de datos producida por errores en las aplicaciones. Por último, conviene saber cómo solucionar problemas de rendimiento y qué componentes son responsables de una mayor latencia.











