
Spanner
Selalu ada di database dengan skala yang hampir tak terbatas
Membangun aplikasi cerdas dengan satu database yang menyatukan workload relasional, grafik, nilai kunci, dan penelusuran. Tanpa masa pemeliharaan, sehingga aplikasi penting tidak akan terganggu.
Selain itu, pelanggan baru Google Cloud akan mendapatkan kredit gratis senilai $300.

Fitur
Multi-model: satu database, banyak kemungkinan
Kemampuan multi-model Spanner mendukung Anda untuk membangun aplikasi yang cerdas dan didukung AI menggunakan data operasional relasional dan NoSQL Anda dengan memanfaatkan integrasi Vertex AI native, Spanner Graph untuk membuat kueri hubungan yang kompleks, penelusuran vektor untuk penelusuran semantik, penelusuran teks lengkap bawaan, —semuanya dengan interoperabilitas "true ZeroETL". Pendekatan terpadu ini menghilangkan data silo, menghemat biaya, mengurangi poin kontak operasional dan keamanan, serta memastikan konsistensi data di semua model.

Skalabilitas yang mudah
Bermimpilah besar, mulailah dari yang kecil, dan skalakan dengan mudah sesuai kebutuhan Anda yang terus berkembang. Spanner menangani set data yang terus bertambah dan workload yang menuntut dengan lancar menggunakan skalabilitas "tulis" dan baca horizontalnya. Sharding database otomatis memastikan distribusi data yang optimal, sementara partisi geografis mendekatkan data ke pengguna Anda untuk latensi yang lebih rendah. Nikmati performa yang konsisten dan tinggi dengan pemrosesan kueri yang terisolasi workload menggunakan Spanner Data Boost, bahkan selama periode permintaan puncak.

Ketersediaan Selalu Aktif
Pastikan aplikasi Anda selalu aktif dan siap melayani pengguna. Spanner memberikan ketersediaan hingga 99,999% dengan pemeliharaan otomatis dan opsi deployment yang fleksibel. Pilih dari konfigurasi satu region, dual-region, atau multi-region untuk menyesuaikan dengan persyaratan ketersediaan dan fault-tolerance spesifik Anda.

Transaksi konsisten yang terjamin
Ucapkan selamat tinggal pada inkonsistensi data dan kerumitan dalam mengelolanya. Spanner menjamin konsistensi transaksional yang kuat, yang berarti setiap pembacaan akan mencerminkan update terbaru, terlepas dari ukuran atau distribusi data Anda. Bangun solusi dengan percaya diri, karena Anda tahu bahwa aplikasi Anda selalu memiliki tampilan data yang konsisten.
Keamanan dan kepatuhan tepercaya
Amankan data Anda di platform yang aman dan patuh dengan Spanner. Nikmati administrasi dan kontrol terpusat dengan Database Center, yang menyederhanakan pengelolaan database cloud Anda. Spanner menawarkan keamanan dan kontrol tingkat perusahaan, termasuk enkripsi data dalam penyimpanan dan dalam pengiriman, pengelolaan akses terperinci melalui Identity and Access Management (IAM), serta kepatuhan terhadap standar industri. Lindungi data Anda lebih jauh dengan kemampuan pencadangan dan pemulihan yang andal, termasuk pemulihan point-in-time untuk memberikan ketenangan pikiran dalam operasional.
Perbandingan database
| Atribut database | DB Relasional lain | DB Non-relasional lain | Spanner |
|---|---|---|---|
Skema | Statis | Dinamis | Dinamis |
SQL | Ya | Tidak | Ya (PostgreSQL, Google SQL) |
Transaksi | ACID (atomicity, consistency, isolation, durability) | Tidak pasti | ACID kuat dengan pengaturan TrueTime |
Skalabilitas | Vertikal (menggunakan mesin yang lebih besar) | Horizontal (tambah mesin lain) | Horizontal |
Ketersediaan | Failover (periode nonaktif) | Tinggi | SLA tinggi 99,999% |
Replikasi | Dapat Dikonfigurasi | Dapat Dikonfigurasi | Otomatis |
Gartner® menempatkan Spanner di peringkat #1 untuk Kasus Penggunaan Transaksi Ringan. Dapatkan laporan lengkapnya.
Skema
Statis
Dinamis
Dinamis
Transaksi
ACID
(atomicity, consistency, isolation, durability)
Tidak pasti
ACID kuat
dengan pengaturan TrueTime
Skalabilitas
Vertikal
(menggunakan mesin yang lebih besar)
Horizontal
(tambah mesin lain)
Horizontal
Ketersediaan
Failover (periode nonaktif)
Tinggi
SLA tinggi 99,999%
Replikasi
Dapat Dikonfigurasi
Dapat Dikonfigurasi
Otomatis
Gartner® menempatkan Spanner di peringkat #1 untuk Kasus Penggunaan Transaksi Ringan. Dapatkan laporan lengkapnya.
Cara Kerjanya
Instance Spanner menyediakan komputasi dan penyimpanan di satu atau beberapa region. Clock terdistribusi yang disebut TrueTime menjamin transaksi memiliki konsistensi kuat, bahkan lintas region. Data secara otomatis "dipisah" untuk skalabilitas dan direplikasi menggunakan skema sinkron berbasis Paxos untuk ketersediaan.
Instance Spanner menyediakan komputasi dan penyimpanan di satu atau beberapa region. Clock terdistribusi yang disebut TrueTime menjamin transaksi memiliki konsistensi kuat, bahkan lintas region. Data secara otomatis "dipisah" untuk skalabilitas dan direplikasi menggunakan skema sinkron berbasis Paxos untuk ketersediaan.

Penggunaan Umum
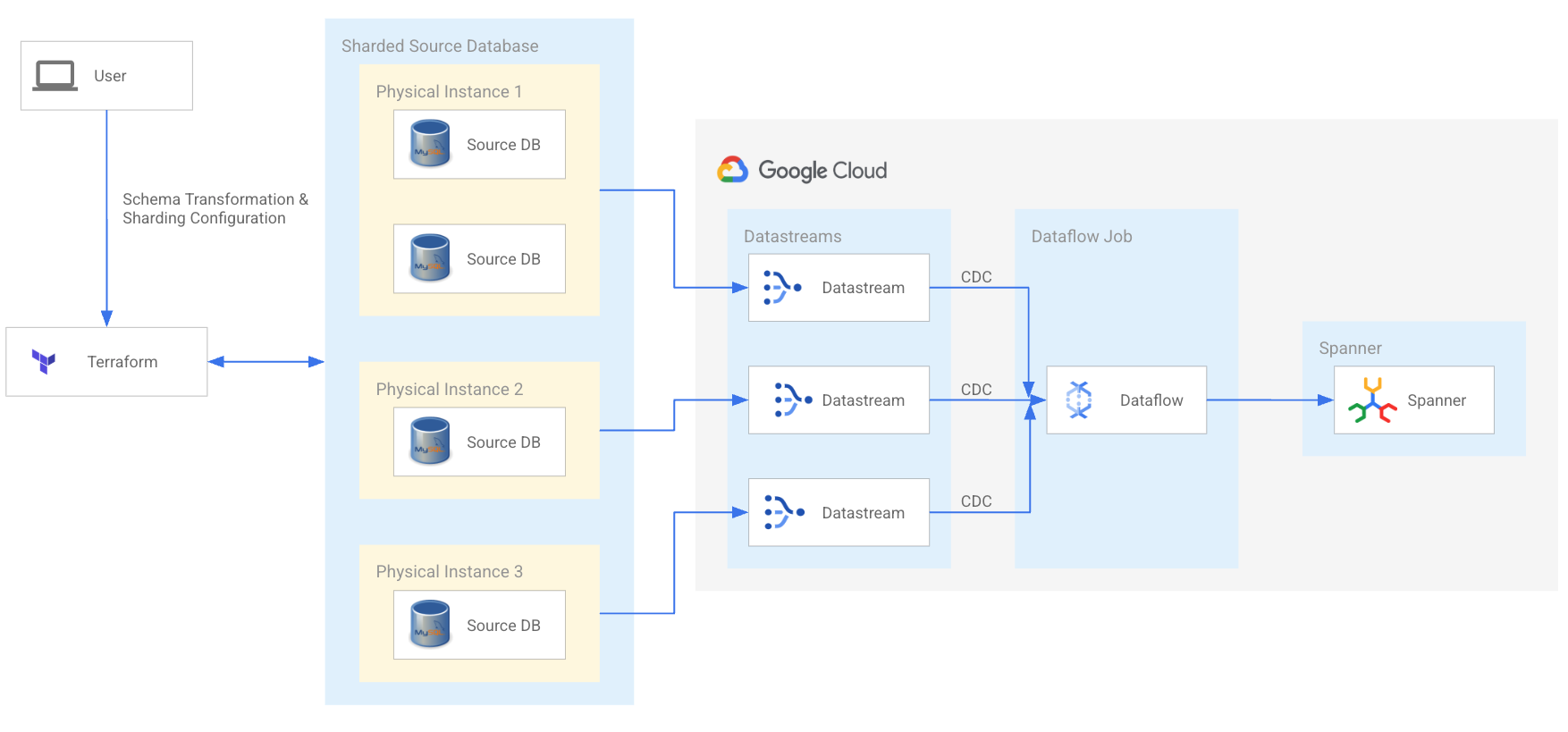
Migrasi dan modernisasi
Menyederhanakan modernisasi MySQL & Cassandra
Menyederhanakan modernisasi MySQL & Cassandra
Modernkan workload MySQL dan Cassandra yang di-sharding untuk mendukung tim pengembangan Anda dan menskalakan untuk fase pertumbuhan berikutnya. Manfaatkan alat migrasi Spanner open source dan jaringan partner teknologi dan layanan berkualitas yang dapat menyederhanakan migrasi Anda.
Tutorial, panduan memulai, dan lab
Menyederhanakan modernisasi MySQL & Cassandra
Menyederhanakan modernisasi MySQL & Cassandra
Modernkan workload MySQL dan Cassandra yang di-sharding untuk mendukung tim pengembangan Anda dan menskalakan untuk fase pertumbuhan berikutnya. Manfaatkan alat migrasi Spanner open source dan jaringan partner teknologi dan layanan berkualitas yang dapat menyederhanakan migrasi Anda.
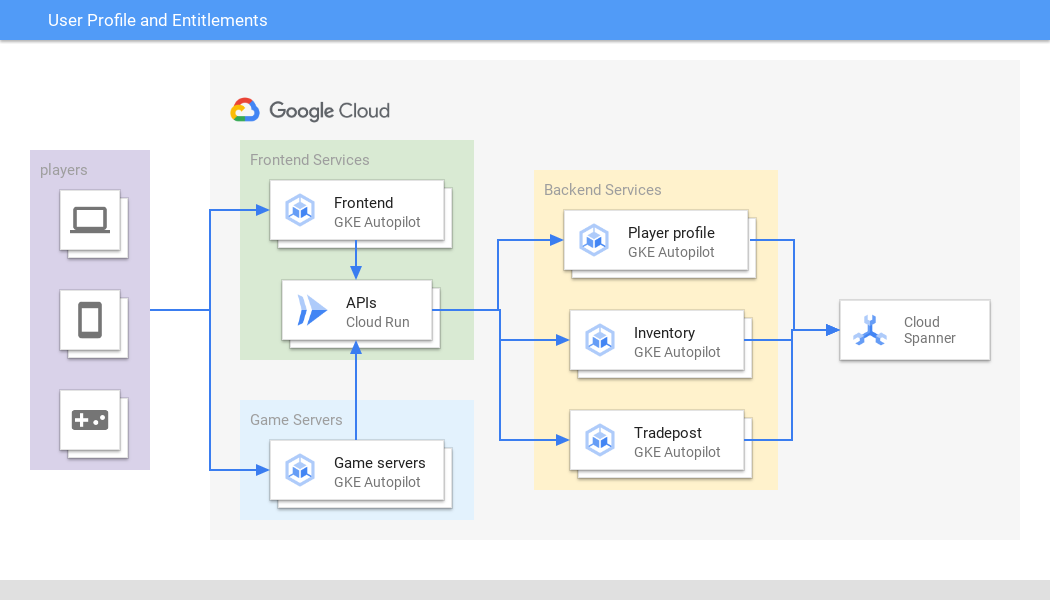
Profil pengguna dan hak
Mengelola data pengguna yang penting dengan aman pada skala berapa pun
Tutorial, panduan memulai, dan lab
Mengelola data pengguna yang penting dengan aman pada skala berapa pun
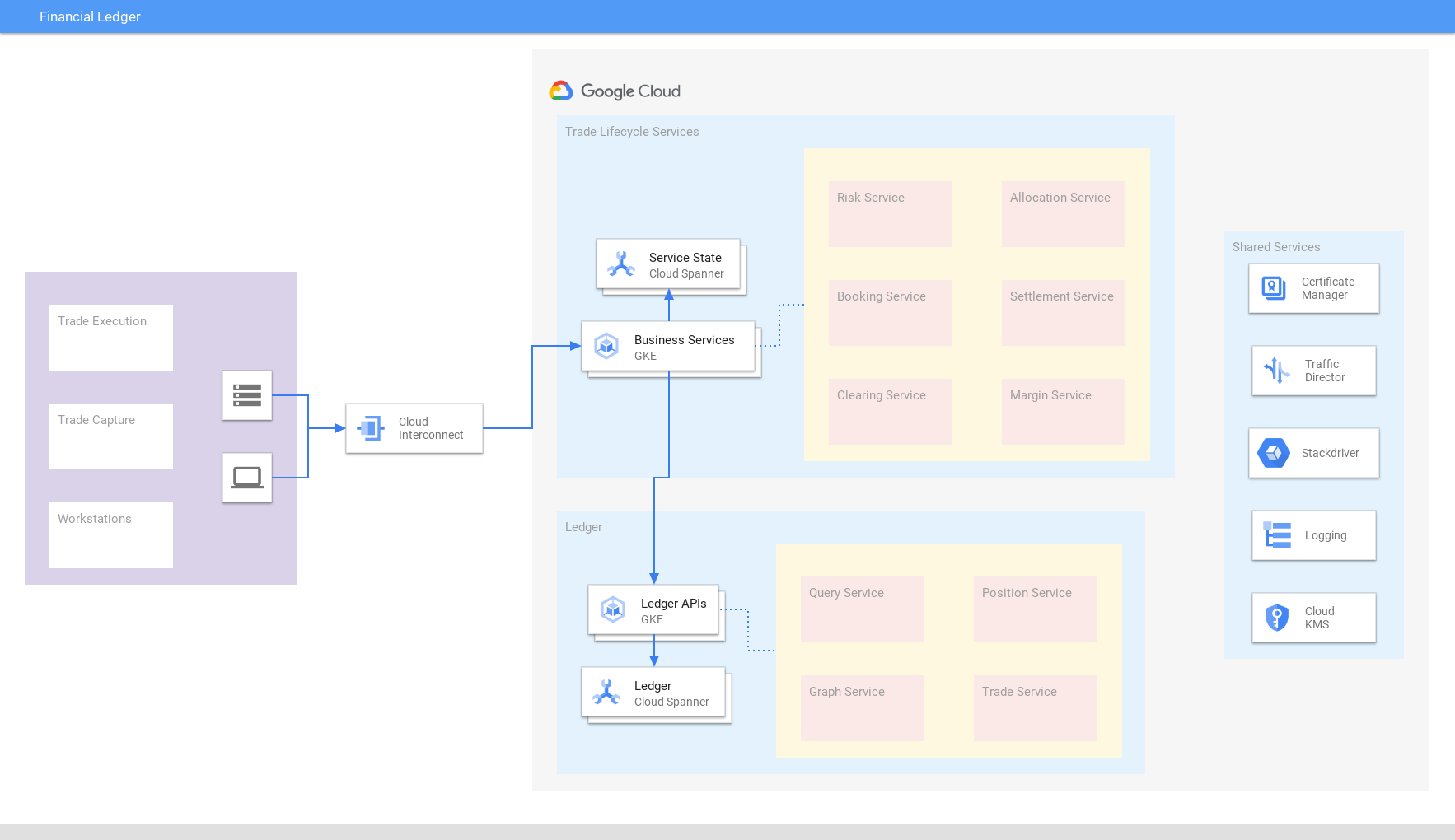
Buku besar keuangan
Dapatkan tampilan transaksi global yang terbaru dan konsisten
Satukan transaksi keuangan, perdagangan, pembayaran, dan posisi di seluruh dunia ke dalam buku besar perdagangan gabungan yang dibangun di Spanner yang menjamin konsistensi dan skalabilitas eksternal. Gabungan data membantu adaptasi yang cepat dengan perubahan kondisi pasar dan persyaratan peraturan. Demikian pula, bisnis retail/e-commerce menggunakan Spanner untuk buku besar inventaris.
Tutorial, panduan memulai, dan lab
Dapatkan tampilan transaksi global yang terbaru dan konsisten
Satukan transaksi keuangan, perdagangan, pembayaran, dan posisi di seluruh dunia ke dalam buku besar perdagangan gabungan yang dibangun di Spanner yang menjamin konsistensi dan skalabilitas eksternal. Gabungan data membantu adaptasi yang cepat dengan perubahan kondisi pasar dan persyaratan peraturan. Demikian pula, bisnis retail/e-commerce menggunakan Spanner untuk buku besar inventaris.
Perbankan online
Menghadirkan interaktivitas yang selalu aktif untuk pengalaman digital
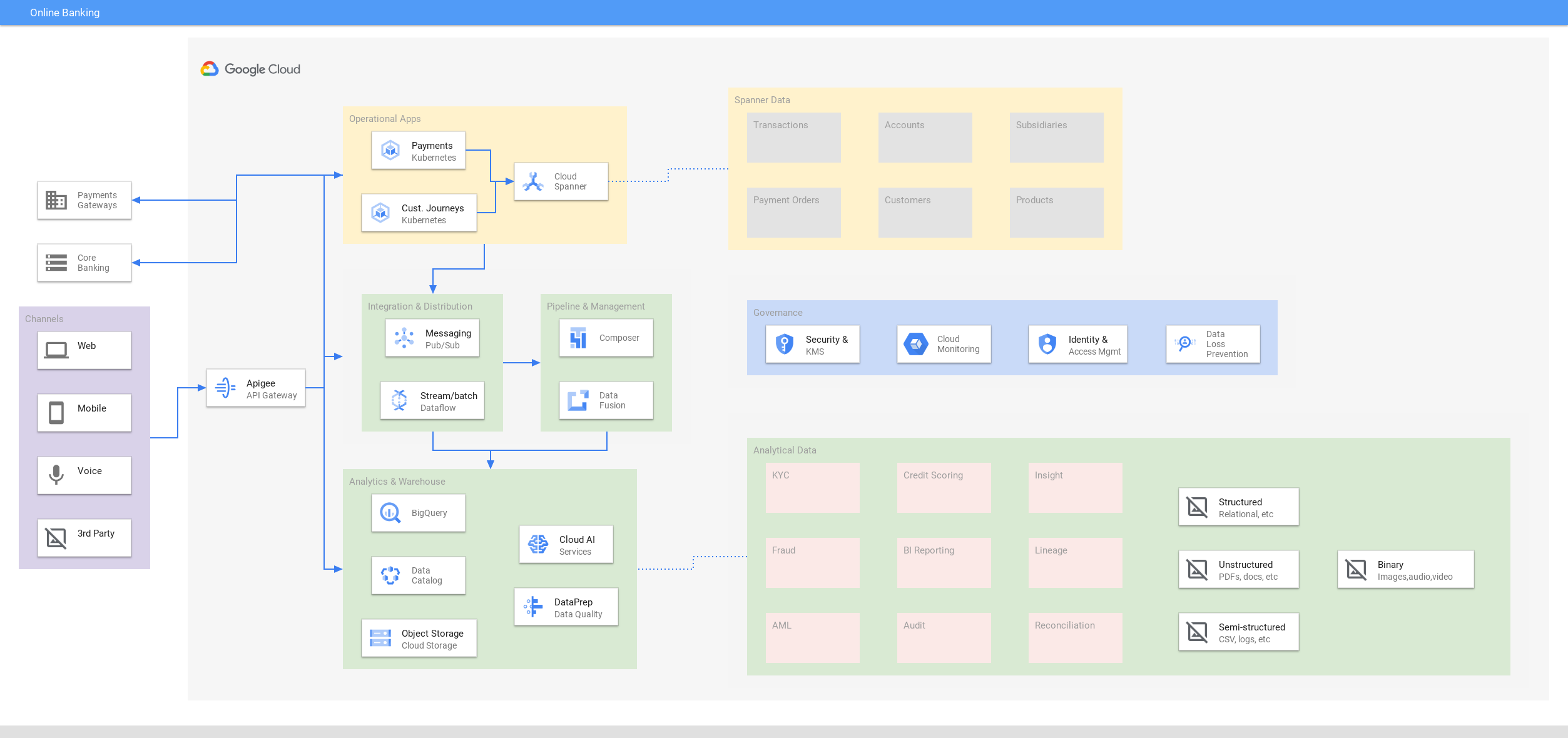
Tutorial, panduan memulai, dan lab
Menghadirkan interaktivitas yang selalu aktif untuk pengalaman digital
Program loyalitas dan promosi
Personalisasikan pengalaman dengan update real-time
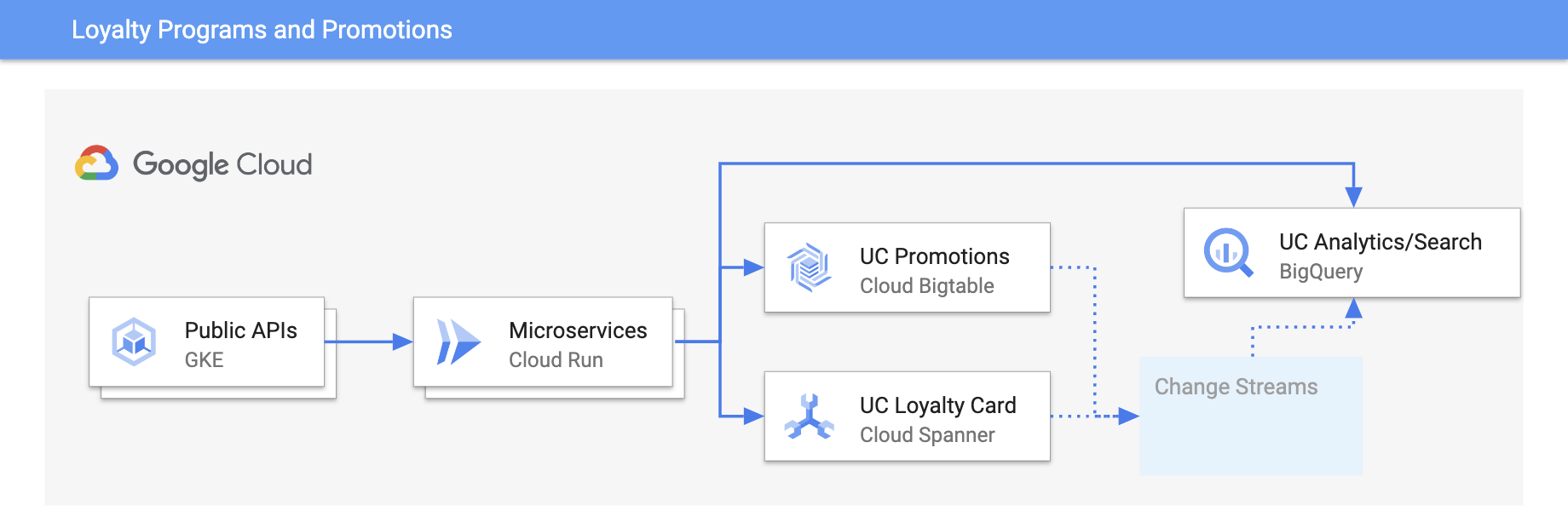
Tutorial, panduan memulai, dan lab
Personalisasikan pengalaman dengan update real-time
Pengelolaan inventaris omnichannel
Memberikan tampilan yang konsisten di berbagai saluran dan aplikasi
Spanner memberikan satu sumber tepercaya dan berperforma tinggi untuk inventaris retail dan pesanan di seluruh pusat distribusi online, di toko, dan pengiriman untuk mencocokkan inventaris dengan permintaan, sehingga meningkatkan pengalaman pelanggan dan profitabilitas. Perusahaan game juga menggunakan Spanner untuk menyimpan data inventaris dalam game.
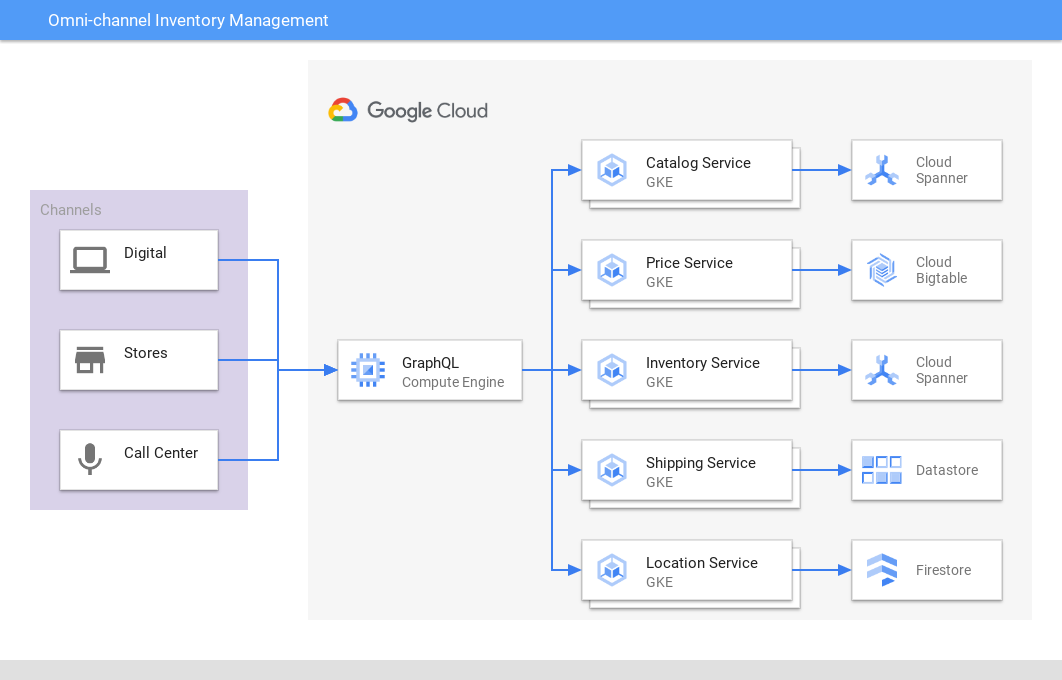
Tutorial, panduan memulai, dan lab
Memberikan tampilan yang konsisten di berbagai saluran dan aplikasi
Spanner memberikan satu sumber tepercaya dan berperforma tinggi untuk inventaris retail dan pesanan di seluruh pusat distribusi online, di toko, dan pengiriman untuk mencocokkan inventaris dengan permintaan, sehingga meningkatkan pengalaman pelanggan dan profitabilitas. Perusahaan game juga menggunakan Spanner untuk menyimpan data inventaris dalam game.
Pustaka pengetahuan
Mengungkap hubungan dan koneksi tersembunyi dalam data
Mengungkap hubungan dan koneksi tersembunyi dalam data
Dengan Spanner Graph, Anda dapat mengembangkan pustaka pengetahuan yang menangkap koneksi kompleks antara entity, yang direpresentasikan sebagai node, dan hubungan antara entity, yang direpresentasikan sebagai edge. Koneksi ini memberikan konteks yang lengkap, sehingga pustaka pengetahuan menjadi sangat berharga untuk mengembangkan sistem pusat informasi dan mesin pemberi saran. Dengan kemampuan penelusuran terintegrasi, Anda dapat memadukan pemahaman semantik, pengambilan berbasis kata kunci, dan grafik dengan lancar untuk hasil yang komprehensif.
Tutorial, panduan memulai, dan lab
Mengungkap hubungan dan koneksi tersembunyi dalam data
Mengungkap hubungan dan koneksi tersembunyi dalam data
Dengan Spanner Graph, Anda dapat mengembangkan pustaka pengetahuan yang menangkap koneksi kompleks antara entity, yang direpresentasikan sebagai node, dan hubungan antara entity, yang direpresentasikan sebagai edge. Koneksi ini memberikan konteks yang lengkap, sehingga pustaka pengetahuan menjadi sangat berharga untuk mengembangkan sistem pusat informasi dan mesin pemberi saran. Dengan kemampuan penelusuran terintegrasi, Anda dapat memadukan pemahaman semantik, pengambilan berbasis kata kunci, dan grafik dengan lancar untuk hasil yang komprehensif.
Harga
| Mekanisme penetapan harga Spanner | Penetapan harga Spanner didasarkan pada kapasitas komputasi, Spanner Data Boost, penyimpanan database, penyimpanan cadangan, replikasi, dan penggunaan jaringan. Harga komputasi bervariasi bergantung pada edisi dan konfigurasi yang dipilih. Diskon abonemen dapat mengurangi harga komputasi lebih lanjut. | |
|---|---|---|
| Layanan | Deskripsi | Harga (USD) |
Komputasi | Edisi Standard Dilengkapi dengan serangkaian kemampuan yang sudah mapan dan komprehensif untuk konfigurasi regional (satu region) Kapasitas komputasi disediakan sebagai unit pemrosesan atau node (1 node = 1.000 unit pemrosesan). | Mulai dari $0,030 per 100 unit pemrosesan per jam per replika |
Edisi Enterprise Memberikan kemampuan multi-model tambahan dan penelusuran lanjutan dengan kesederhanaan dan efisiensi operasional yang ditingkatkan Kapasitas komputasi disediakan sebagai unit pemrosesan atau node (1 node = 1.000 unit pemrosesan). | Mulai dari $0,041 per 100 unit pemrosesan per jam per replika | |
Edisi Enterprise Plus Mendukung workload yang paling populer dengan ketersediaan, performa, kepatuhan, dan tata kelola tingkat tertinggi Kapasitas komputasi disediakan sebagai unit pemrosesan atau node (1 node = 1.000 unit pemrosesan). | Mulai dari $0,057 per 100 unit pemrosesan per jam per replika | |
Data Boost | Resource komputasi terisolasi yang dapat diakses secara on-demand, termasuk CPU, memori, dan transfer data lokal | Mulai dari $0,00117 per unit pemrosesan serverless per jam |
Penyimpanan database | Harga didasarkan pada jumlah data yang tersimpan dalam database dan mencakup biaya penyimpanan di replika baca-tulis dan replika hanya baca. Replika saksi tidak dikenai biaya. Penyimpanan SSD Gunakan penyimpanan SSD jika Anda memerlukan latensi rendah dan throughput tinggi untuk data operasional. | Mulai dari $0,10 per GB per bulan per replika untuk SSD |
Penyimpanan HDD Gunakan penyimpanan HDD untuk data yang jarang diakses dan masih dapat mentolerir latensi baca yang lebih tinggi dan throughput yang lebih rendah. Anda juga dapat mengonfigurasi kebijakan tingkatan untuk memindahkan data dari SSD ke HDD setelah periode waktu tertentu berakhir. | Mulai dari $0,02 per GB per bulan per replika untuk HDD | |
Penyimpanan cadangan | Konfigurasi regional Penetapan harga didasarkan pada jumlah penyimpanan cadangan dan mencakup biaya penyimpanan dalam semua replika. | Mulai dari $0,10 per GB per bulan (termasuk semua replika) |
Konfigurasi dual-region dan multi-region Penetapan harga didasarkan pada jumlah penyimpanan cadangan dan mencakup biaya penyimpanan dalam semua replika. | Mulai dari $0,30 per GB per bulan (termasuk semua replika) | |
Replikasi | Replikasi intra-region | Gratis |
Replikasi antar-region | Mulai dari $0,04 per GB | |
Jaringan | Ingress | Gratis |
Traffic keluar intra-region | Gratis | |
Egress antar-region | Mulai dari $0,01 per GB | |
Pelajari lebih lanjut penetapan harga dan diskon abonemen Cloud Spanner.
Mekanisme penetapan harga Spanner
Penetapan harga Spanner didasarkan pada kapasitas komputasi, Spanner Data Boost, penyimpanan database, penyimpanan cadangan, replikasi, dan penggunaan jaringan. Harga komputasi bervariasi bergantung pada edisi dan konfigurasi yang dipilih. Diskon abonemen dapat mengurangi harga komputasi lebih lanjut.
Edisi Standard
Dilengkapi dengan serangkaian kemampuan yang sudah mapan dan komprehensif untuk konfigurasi regional (satu region)
Kapasitas komputasi disediakan sebagai unit pemrosesan atau node (1 node = 1.000 unit pemrosesan).
Starting at
$0,030
per 100 unit pemrosesan per jam per replika
Edisi Enterprise
Memberikan kemampuan multi-model tambahan dan penelusuran lanjutan dengan kesederhanaan dan efisiensi operasional yang ditingkatkan
Kapasitas komputasi disediakan sebagai unit pemrosesan atau node (1 node = 1.000 unit pemrosesan).
Starting at
$0,041
per 100 unit pemrosesan per jam per replika
Edisi Enterprise Plus
Mendukung workload yang paling populer dengan ketersediaan, performa, kepatuhan, dan tata kelola tingkat tertinggi
Kapasitas komputasi disediakan sebagai unit pemrosesan atau node (1 node = 1.000 unit pemrosesan).
Starting at
$0,057
per 100 unit pemrosesan per jam per replika
Data Boost
Resource komputasi terisolasi yang dapat diakses secara on-demand, termasuk CPU, memori, dan transfer data lokal
Starting at
$0,00117
per unit pemrosesan serverless per jam
Penyimpanan database
Harga didasarkan pada jumlah data yang tersimpan dalam database dan mencakup biaya penyimpanan di replika baca-tulis dan replika hanya baca. Replika saksi tidak dikenai biaya.
Penyimpanan SSD
Gunakan penyimpanan SSD jika Anda memerlukan latensi rendah dan throughput tinggi untuk data operasional.
Starting at
$0,10
per GB per bulan per replika untuk SSD
Penyimpanan HDD
Gunakan penyimpanan HDD untuk data yang jarang diakses dan masih dapat mentolerir latensi baca yang lebih tinggi dan throughput yang lebih rendah. Anda juga dapat mengonfigurasi kebijakan tingkatan untuk memindahkan data dari SSD ke HDD setelah periode waktu tertentu berakhir.
Starting at
$0,02
per GB per bulan per replika untuk HDD
Penyimpanan cadangan
Konfigurasi regional
Penetapan harga didasarkan pada jumlah penyimpanan cadangan dan mencakup biaya penyimpanan dalam semua replika.
Starting at
$0,10
per GB per bulan (termasuk semua replika)
Konfigurasi dual-region dan multi-region
Penetapan harga didasarkan pada jumlah penyimpanan cadangan dan mencakup biaya penyimpanan dalam semua replika.
Starting at
$0,30
per GB per bulan (termasuk semua replika)
Replikasi
Replikasi intra-region
Gratis
Replikasi antar-region
Starting at
$0,04
per GB
Jaringan
Ingress
Gratis
Traffic keluar intra-region
Gratis
Egress antar-region
Starting at
$0,01
per GB
Pelajari lebih lanjut penetapan harga dan diskon abonemen Cloud Spanner.
Kasus Bisnis
Jelajahi cara bisnis lain memangun aplikasi yang inovatif untuk memberikan pengalaman pelanggan yang luar biasa, memangkas biaya, dan meningkatkan ROI dengan Spanner
- Studi Total Economic Impact™ Forrester menunjukkan bahwa Spanner menghasilkan ROI 132%, periode pengembalian modal 9 bulan, dan manfaat bernilai jutaan dolar untuk perwakilan organisasi gabungan. Download studi lengkapnya untuk mempelajari lebih lanjut.
- Gartner® mengidentifikasi 13 Kemampuan Penting untuk database operasional, dan menempatkan Spanner di peringkat #1 dalam Kasus Penggunaan Transaksi Ringan. Dapatkan laporan lengkapnya.

Bagaimana cara Uber menskalakan hingga jutaan permintaan serentak?
Pelajari cara Uber mendesain ulang platform fulfillment dengan memanfaatkan Spanner.



Manfaat dan pelanggan unggulan
Kembangkan bisnis Anda dengan aplikasi inovatif yang dapat diskalakan tanpa batas untuk memenuhi permintaan apa pun.
Turunkan TCO dan bebaskan developer Anda dari operasi rumit agar memiliki target besar dan membangun solusi lebih cepat.
Dapatkan performa harga terbaik dan bayar sesuai penggunaan Anda, mulai dari $40 per bulan.















Partner & Integrasi
Manfaatkan partner dengan keahlian Spanner untuk membantu Anda di setiap langkah perjalanan, mulai dari penilaian dan kasus bisnis hingga migrasi dan pembuatan aplikasi baru di Spanner.











Integrator sistem
Partner Spanner membantu Anda memodernisasi aplikasi dan bermigrasi ke cloud dengan lancar. Temukan partner atau integrasi pihak ketiga yang ideal di direktori kami.
FAQ
Apakah Spanner termasuk database relasional atau non-relasional?
Spanner menyederhanakan arsitektur data Anda dengan menyatukan workload penelusuran relasional, nilai kunci, grafik, dan penelusuran vektor—semuanya di database yang sama. Spanner adalah database yang sangat skalabel yang menggabungkan skalabilitas tak terbatas dengan semantik relasional, seperti indeks sekunder, konsistensi kuat, skema, dan SQL yang memberikan ketersediaan 99,999% dalam satu solusi mudah. Oleh sebab itu, layanan ini cocok untuk workload relasional dan non-relasional.
Apakah Spanner menggunakan SQL?
Spanner memiliki dua dialek SQL berbasis ANSI dengan serangkaian kemampuan yang sama: GoogleSQL dan PostgreSQL. GoogleSQL memiliki sintaksis yang sama dengan BigQuery untuk tim yang menstandardisasikan alur kerja pengelolaan data mereka. Antarmuka PostgreSQL memberikan pemahaman bagi tim yang sudah mengetahui PostgreSQL serta portabilitas skema dan kueri ke lingkungan PostgreSQL lainnya. Untuk informasi selengkapnya tentang antarmuka PostgreSQL Spanner, lihat dokumentasi kami.
Bagaimana cara memigrasikan database ke Spanner?
Memigrasikan workload yang ada ke Spanner memastikan fondasi untuk pertumbuhan masa depan, tanpa harus mengorbankan keandalan atau rasio harga-performa. Antarmuka multi-model Spanner saat ini digunakan oleh organisasi inovatif di berbagai industri dengan workload operasional yang berasal dari database relasional, seperti MySQL dan SQL Server, penyimpanan nilai-kunci, seperti Cassandra atau DynamoDB, serta alat grafik, penelusuran, dan dokumen. Pendekatan spesifik untuk migrasi akan bergantung pada persyaratan seputar volume data, SLO performa, dan ketersediaan. Alat migrasi Spanner memberikan penilaian menyeluruh, migrasi skema dan data, serta migrasi sistem dengan periode nonaktif yang rendah untuk database MySQL dan Cassandra yang di-sharding, serta penilaian dan migrasi untuk PostgreSQL. Jaringan partner teknologi dan layanan yang memenuhi syarat dapat mempercepat migrasi dari hampir semua sumber.
Apa pertimbangan utama untuk mengoperasikan Spanner?
Spanner adalah database yang terkelola sepenuhnya, sehingga menyediakan fitur pengelolaan infrastruktur yang komprehensif secara otomatis. Namun, ada beberapa tindakan pengelolaan khusus aplikasi yang mungkin diperlukan, bergantung pada workload Anda. Anda perlu memastikan bahwa Anda telah menyiapkan peringatan dan pemantauan yang tepat dan bahwa Anda mengawasinya dengan cermat untuk memastikan proses produksi selalu berjalan lancar. Anda perlu memahami tindakan yang harus diambil ketika traffic tumbuh secara organik dari waktu ke waktu, atau jika diperkirakan akan terjadi puncak traffic, atau cara menangani kerusakan data karena bug aplikasi, serta cara memecahkan masalah performa dan memahami komponen apa saja yang bertanggung jawab atas peningkatan latensi.











