クラウド ネイティブへの再構築
DevOps Research and Assessment(DORA's)の調査によると、エリート DevOps チームは、1 日に複数回デプロイし、1 日未満で本番環境に対する変更をリリースし、変更の失敗率は 0〜15% です。
このホワイトペーパーでは、アプリケーションをクラウドネイティブのパラダイムに再構築し、チームの規模が拡大したときに新機能を迅速に配信できるようにするとともに、ソフトウェアの品質を改善し、より高レベルの安定性と可用性を実現する方法を紹介します。
クラウドネイティブのアーキテクチャに移行する理由
多くの会社では、カスタムのソフトウェア サービスをモノリシック アーキテクチャで構築しています。 この方法には、モノリシックなシステムは設計とデプロイが比較的簡単という利点があります。ただし、それは最初のうちだけです。アプリケーションが複雑化するとデベロッパーの生産性とデプロイメントの速さを維持するのが困難になり、システムの変更は高価で時間を要するものになって、デプロイはリスクを伴うようになります。
サービスと、それらのサービスを担当するチームの規模が拡大すると、複雑性が増し、進化や運用が困難になる傾向があります。 テストとデプロイメントに必要な労力が増え、新機能の追加が困難になり、信頼性と可用性の維持が大きな問題になる可能性があります。
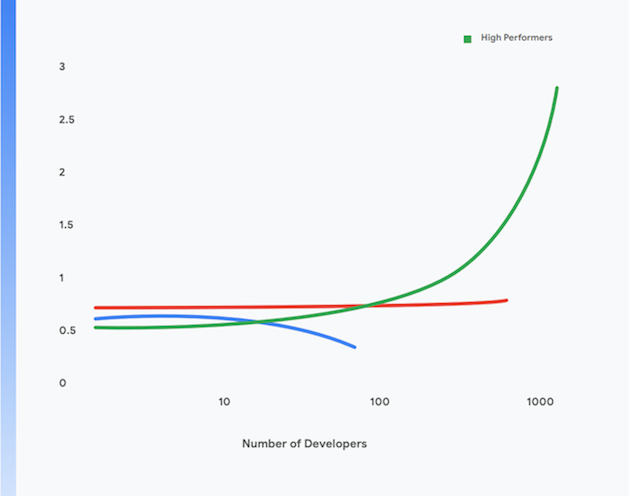
Google の DORA チームによる調査では、あらゆる規模と分野の組織で、その全体にわたって高レベルのソフトウェア デリバリー スループットとサービスの安定性および可用性を達成可能であることが示されています。パフォーマンスの高いチームは 1 日に何回もデプロイし、変更を 1 日以内で本番環境に適用でき、1 時間以内でサービスを復元し、変更失敗率を 0~15% に抑えています1。
さらに、パフォーマンスの高いチームはデベロッパーあたり 1 日ごとのデプロイメント件数で測定してもデベロッパーの生産性が高く、チームの規模が拡大してもパフォーマンスが維持されます。 これを図 1 に示します。
これらの結果を達成するため、アプリケーションを現代的なクラウドネイティブのパラダイムに移行する方法については後述します。このホワイトペーパーに記載されている技術的な実践方式を実装することで、次の目標を達成可能です。
- デベロッパーの生産性の向上: チームの規模が拡大しても維持されます。
- 製品化までの時間の短縮: 新機能を追加し、不具合をより迅速に修正できます。
- 可用性の向上: ソフトウェアの稼働時間を増やし、デプロイメントの障害発生率を減らし、インシデントの発生時に復元時間を短縮できます。
- セキュリティの強化: アプリケーションの攻撃対象部分を減らし、攻撃や、新たに見つかった脆弱性を迅速に検出して対応できます。
- スケーラビリティの向上: クラウドネイティブのプラットフォームとアプリケーションにより、必要に応じて簡単に水平方向のスケーリングと、スケールダウンを行えます。
- コストの削減: 合理化されたソフトウェア デリバリー プロセスにより新機能のリリースコストが低減し、クラウド プラットフォームの有効な使用によってサービスの運用コストが大幅に削減されます。
1 これら 4 つの主要な指標でチームのパフォーマンスを測定した結果は、https://cloud.google.com/devops/ で見られます。
クラウドネイティブのアーキテクチャとは
モノリシック アプリケーションは単一のユニットとしてビルド、テスト、デプロイする必要があります。 多くの場合、オペレーティング システム、ミドルウェア、アプリケーションの言語スタックはアプリケーションごとにカスタマイズされるか、カスタム構成されます。 ビルド、テスト、デプロイメントのスクリプトと処理も、一般にアプリケーションごとに固有のものです。 これはグリーンフィールド アプリケーションでは簡単かつ効果的ですが、アプリケーションが拡張されていくにつれ、このようなシステムの変更、テスト、デプロイ、運用は困難になっていきます。
さらに、システムが拡張されるにつれ、サービスのビルド、テスト、デプロイ、運用を行うチームの規模と複雑性も増大していきます。 一般的な、ただし欠陥のあるアプローチは、チームを機能別に分割することですが、これは、チーム間で引き継ぎが行われ、リードタイムやバッチサイズが増大して、多くの再作業が必要になります。DORA の調査では、パフォーマンスの高いチームは単一のクロスファンクショナルなチームでソフトウェアの開発と配布を行っている割合が 2 倍も高いことが示されています。
この問題の症状には、次のものがあります
- ビルドプロセスが長く、多くの場合は正常に動作しない
- 統合とテストのサイクルの頻度が低い
- ビルドとテストの処理をサポートするための労力が大きくなる
- デベロッパーの生産性低下
- デプロイメント処理を時間外に行う必要があり、計画的なダウンタイムが必要になるため、負担が大きい
- テスト環境と本番環境の構成を管理するため多くの労力が必要
これに対して、クラウドネイティブのパラダイムでは次のようになります³。
- 複雑なシステムはサービスに分解され、別々にテストされて、コンテナ化されたランタイムにデプロイされます(マイクロサービスまたはサービス指向アーキテクチャ)。
- アプリケーションは、プラットフォームで提供されるデータベース管理システム(DBMS)、blob ストレージ、メッセージング、CDN、SSL 終端などの標準のサービスを使用します。
- 標準化されたクラウド プラットフォームが、デプロイメント、自動スケーリング、構成、シークレット管理、モニタリング、アラートなど多くの運用上の作業を処理します。 これらのサービスには、アプリケーション開発チームがオンデマンドでアクセスできます
- アプリケーション開発者向けに、標準化されたオペレーティング システム、ミドルウェア、言語に固有のスタックが用意され、これらのスタックの保守とパッチ適用はプラットフォームのプロバイダ、または別のチームによって帯域外で行われます。
- 複数の職能にまたがる単一のチームが、各サービスのソフトウェア デリバリー ライフサイクル全体を担当できます。
3 これは、「クラウドネイティブ」の意味についての完全な説明を意図したものではありません。クラウドネイティブ アーキテクチャのいくつかの原則の解説については、https://cloud.google.com/blog/products/ application-development/5-principles-for-cloud-native-architecture-what-it-is-and-how-to-master-it をご覧ください。
このパラダイムには、次のような多くの利点があります。
迅速な配布 | 信頼性の高いリリース | コスト削減 |
サービスが小規模で疎結合になるため、それらのサービスに関連するチームは自律的に作業を行えます。 これにより、デベロッパーの生産性と開発の速度が向上します。 | デベロッパーは本番環境と類似したテスト環境で、新規と既存のサービスを迅速にビルド、テスト、デプロイできます。 本番環境へのデプロイメントも単純でアトミックな作業です。 これによりソフトウェア デリバリーの処理が大幅に高速化し、デプロイメントのリスクが低減します。 | 共有され、標準化されたサービスがプラットフォームによって提供され、アプリケーションが共有の物理インフラストラクチャ上で実行されるため、テスト環境と本番環境の費用や複雑さが大幅に軽減されます。 |
セキュリティの強化 | 高可用性 | コンプライアンスが単純で低コスト |
DBMS やメッセージング インフラストラクチャなどの共有サービスを最新の状態で、パッチが適用され、コンプライアンスが保たれた状態に維持する作業はベンダーにより行われます。 また、アプリケーションのデプロイと管理の標準的な方法が存在するため、アプリケーションをパッチが適用された最新の状態に維持することもはるかに簡単です。 | 運用環境の複雑さが軽減し、構成変更を簡単にし、プラットフォーム レベルでの自動スケーリングと自動修復を処理できるので、アプリケーションの可用性と信頼性が向上します。 | ほとんどの情報セキュリティ管理はプラットフォーム レイヤに実装できるため、コンプライアンスの実装および実証が低コストかつ容易になります。多くのクラウド プロバイダは SOC2 や FedRAMP などのリスク管理フレームワークへのコンプライアンスを維持しているため、これらの上にデプロイされたアプリケーションは、プラットフォーム レイヤに実装されていない残りの管理へのコンプライアンスを示せば十分です。 |
迅速な配布
信頼性の高いリリース
コスト削減
サービスが小規模で疎結合になるため、それらのサービスに関連するチームは自律的に作業を行えます。 これにより、デベロッパーの生産性と開発の速度が向上します。
デベロッパーは本番環境と類似したテスト環境で、新規と既存のサービスを迅速にビルド、テスト、デプロイできます。 本番環境へのデプロイメントも単純でアトミックな作業です。 これによりソフトウェア デリバリーの処理が大幅に高速化し、デプロイメントのリスクが低減します。
共有され、標準化されたサービスがプラットフォームによって提供され、アプリケーションが共有の物理インフラストラクチャ上で実行されるため、テスト環境と本番環境の費用や複雑さが大幅に軽減されます。
セキュリティの強化
高可用性
コンプライアンスが単純で低コスト
DBMS やメッセージング インフラストラクチャなどの共有サービスを最新の状態で、パッチが適用され、コンプライアンスが保たれた状態に維持する作業はベンダーにより行われます。 また、アプリケーションのデプロイと管理の標準的な方法が存在するため、アプリケーションをパッチが適用された最新の状態に維持することもはるかに簡単です。
運用環境の複雑さが軽減し、構成変更を簡単にし、プラットフォーム レベルでの自動スケーリングと自動修復を処理できるので、アプリケーションの可用性と信頼性が向上します。
ほとんどの情報セキュリティ管理はプラットフォーム レイヤに実装できるため、コンプライアンスの実装および実証が低コストかつ容易になります。多くのクラウド プロバイダは SOC2 や FedRAMP などのリスク管理フレームワークへのコンプライアンスを維持しているため、これらの上にデプロイされたアプリケーションは、プラットフォーム レイヤに実装されていない残りの管理へのコンプライアンスを示せば十分です。
ただし、クラウドネイティブのモデルにはいくつかのトレードオフが存在します。
- すべてのアプリケーションは分散システムとなるため、運用の一部として多くのリモート呼び出しが行われます。 このため、ネットワークの障害やパフォーマンスの問題を処理する方法、および本番環境で問題をデバッグする方法について注意深く考慮する必要があります。
- デベロッパーは、プラットフォームで提供される標準化されたオペレーティング システム、ミドルウェア、アプリケーション スタックを使用する必要があります。これにより、ローカルでの開発は難しくなります。
- アーキテクトは、システムの設計に結果整合性の導入などのイベント ドリブン型の手法を採用する必要があります。
クラウドネイティブへの移行
多くの組織は、サービスをクラウドに移行するため「リフト&シフト」手法を採用してきました。この手法では、システムにはごく小さな変更しか加える必要がなく、クラウドが基本的に従来型のデータセンターとして扱われますが、従来型のデータセンターと比較して大幅に優れた API、サービス、管理ツールを使用できます。ただし、リフト&シフト手法だけでは上述のようなクラウドネイティブのパラダイムの利点は一切得られません。
アプリケーションをクラウドネイティブのアーキテクチャに移動するには、アプリケーションのアーキテクチャから本番運用まで、実際のところはソフトウェア デリバリーのライフサイクル全体を再考する必要があり、その費用と複雑性から、多くの組織はリフト&シフトで停止しています。この懸念には妥当性があります。多くの組織は何年にもわたる「全面的な」プラットフォーム再構築作業に失敗し、損害を被った経験があるためです。
この解決策は、システムをクラウド ネイティブに再構築する作業を増分的、反復的、革新的な手法で行い、チームが新機能(移行して改良と呼ぶアプローチ)を提供し続けながら、この新しいパラダイムで効果的に機能する方法を学ぶことです。
進化アーキテクチャの主要なパターンはストラングラー フィグ アプリケーションとして知られています。4 システムを一から完全に書き換えるのではなく、新しい機能をクラウド ネイティブの最先端のスタイルで記述しつつ、オリジナルのモノリシック アプリケーションと連携して既存の機能を利用できるようにします。図 2 に示すように、新しいサービスの概念的な完全性のための必要に応じて、時間をかけて徐々に既存の機能を移行させます。
4 説明については、https://martinfowler.com/bliki/StranglerFigApplication.html をご覧ください
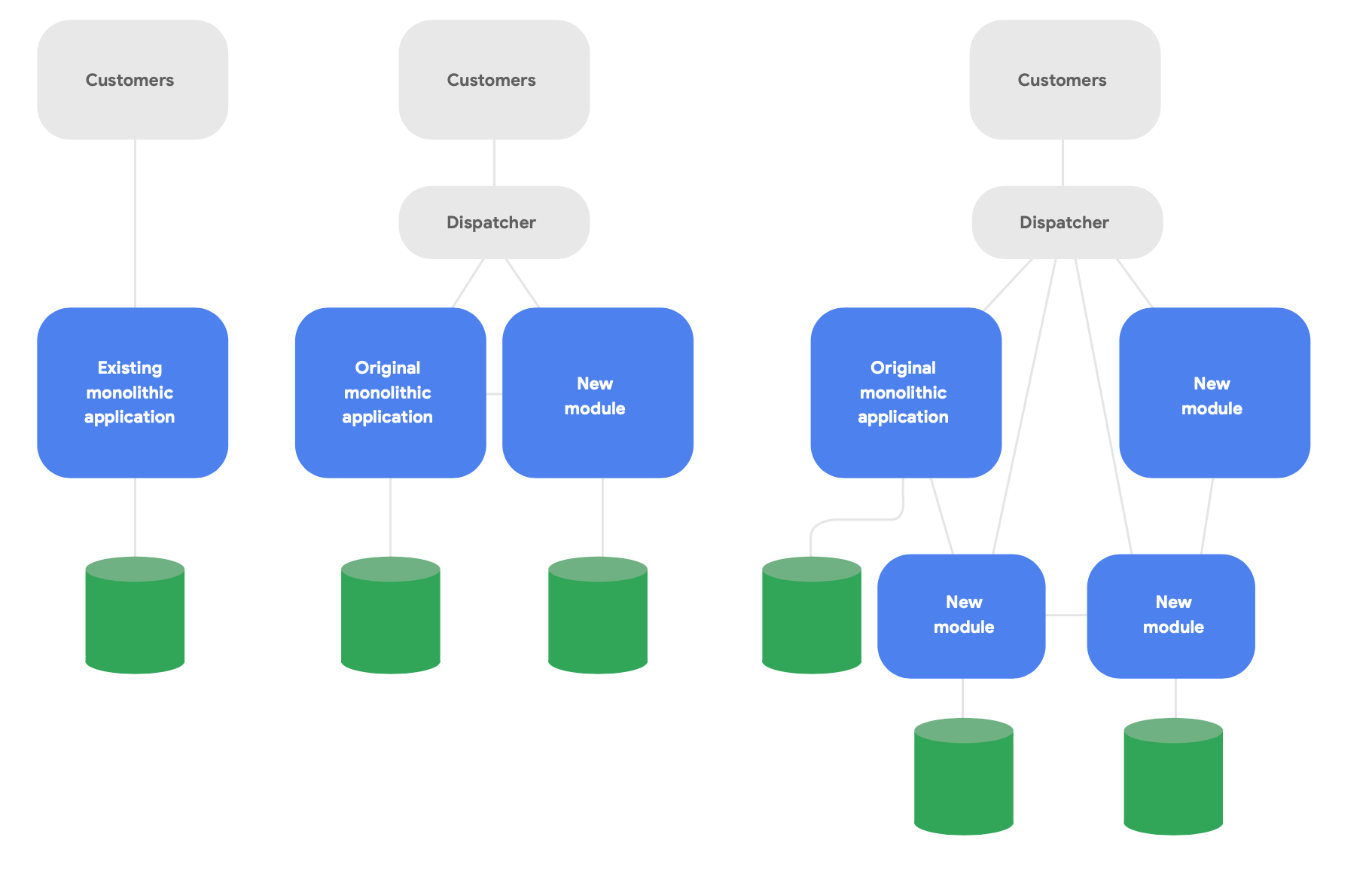
再構築を正しく行うための 3 つの重要なガイドラインをご紹介します。
最初は、既存の機能を再現するのではなく、新しい機能を迅速に提供することから開始します。重要な指標は、新しいサービスを使用して新機能を迅速に提供できるスピードです。これにより、このパラダイムの中で実際に作業を行ったことで得られた優れた方法をすばやく学び、伝えることができます。実際のユーザーに成果を数か月ではなく数週間で配布できるよう、大胆に範囲を切り捨てます。
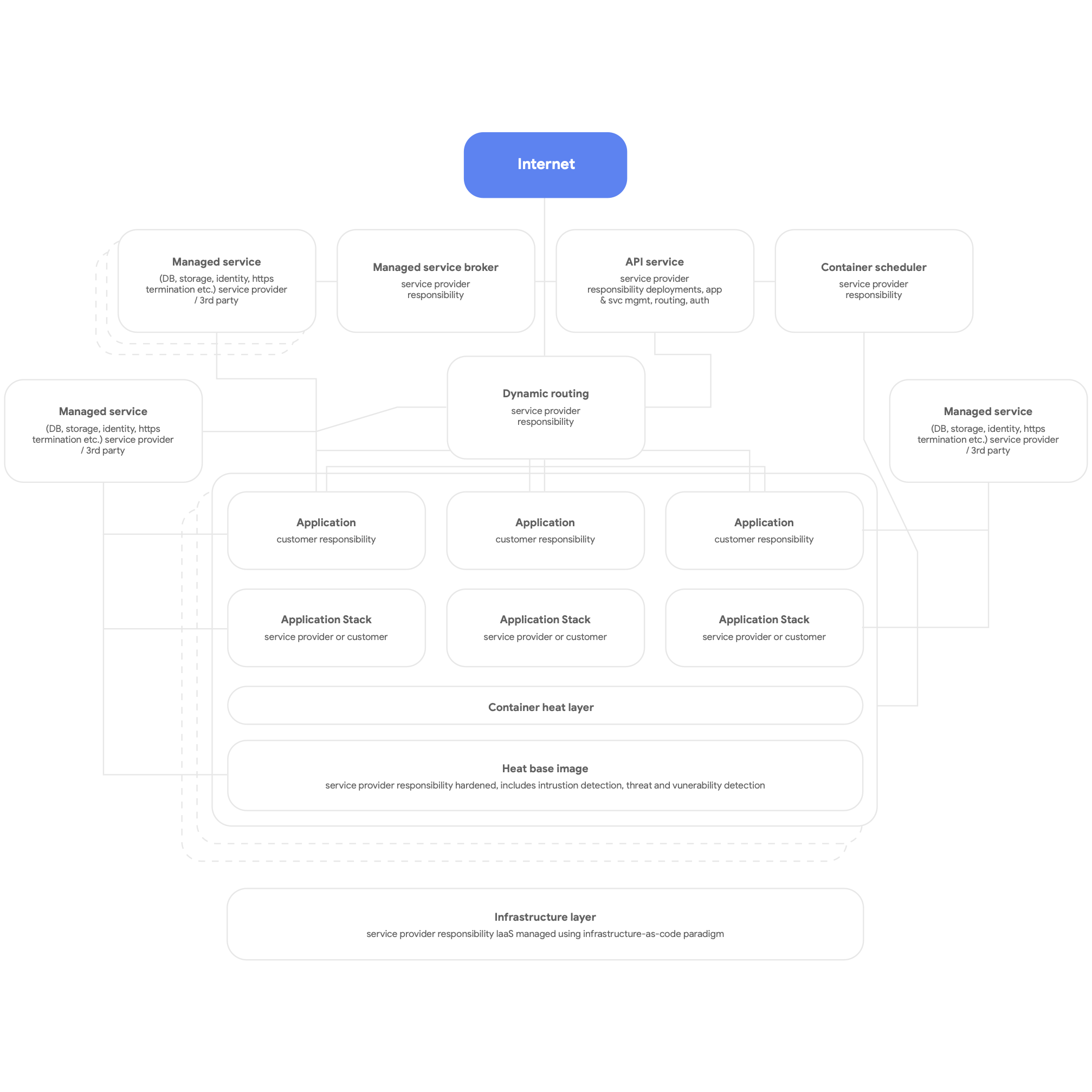
次は、クラウドネイティブの設計です。これは、クラウド プラットフォームの DBMS、メッセージング、CDN、ネットワーキング、blob ストレージなどのネイティブのサービスを使用し、プラットフォームで提供される標準化されたアプリケーション スタックを可能な限り使用するということです。サービスはコンテナ化する必要があり、可能な限りサーバーレスのパラダイムを使用して、ビルド、テスト、デプロイの処理は完全に自動化する必要があります。 すべてのアプリケーションで、ロギング、モニタリング、アラートにはプラットフォームで提供される共有のサービスを使用します(この種類のプラットフォーム アーキテクチャは、ベアメタルのオンプレミス環境も含め、あらゆるマルチテナントのアプリケーション プラットフォームに有益にデプロイ可能であることに注目してください)。 クラウドネイティブ プラットフォームの高レベルの構造を、次の図 3 に示します。
最後は、自分たちのサービスのテストとデプロイを行える、自律的で疎結合されたチームの設計です。Google の調査では、アーキテクチャ上の最も重要な結果は、ソフトウェア デリバリー チームが次の 6 つの質問に「はい」と回答できるかどうかであることが示されています。
- チーム外の誰かの許可を得ることなく、システムの設計に大規模な変更を加えることができます。
- 他のチームに頼んで、そのチームのシステムに変更を加えてもらう、または他のチームに大きな作業を行ってもらうことなく、システムの設計に大規模な変更を加えることができます。
- チーム外のメンバーとの連絡や調整なしに、チームの作業を完了できます。
- プロダクトやサービスを、それが依存している他のサービスに関係なく、オンデマンドでデプロイおよびリリースできます。
- ほとんどのテストをオンデマンドで、統合テスト環境の必要なしに行うことができます。
- 通常の営業時間内にデプロイメントを行うことができ、ダウンタイムは無視できます。
チームがこれらの目標に向けて作業し、目標の達成を優先順位付けしているかどうかを、定期的にチェックします。 これには通常、組織とエンタープライズのアーキテクチャの再考が伴います。
特に、ソフトウェアのビルド、テスト、デプロイに必要な、プロダクト マネージャーを含む各種の役割が共同で作業し、現代的なプロダクト管理の実践手法を使用して、作業しているサービスのビルドと進化を実現できるよう、チームを編成することが重要です。 これには、組織構造の変化を伴う必要はありません。 開発者、テスター、リリースチームが別々に運用を行うのではなく、それらの人々が日常的にチームとして共同で作業(可能なら物理的に同じ空間を共有)するだけで、生産性に大きな変化が生まれます。
Google の調査では、チームがこれらの声明に合意している範囲から、ソフトウェアの高いパフォーマンス、すなわち信頼性が高く高可用性のサービスを 1 日に複数回供給できることが強く予測されることが示されています。さらに、これは高パフォーマンスのチームで、チームの数が増加してもデベロッパーの生産性(デベロッパーあたり、1 日ごとのデプロイメント数で測定されます)を向上させる方法でもあります。
原則と実践
マイクロサービス アーキテクチャの原則と実践
マイクロサービスやサービス指向のアーキテクチャを採用する場合、いくつかの重要な原則と実践方法に必ず従う必要があります。 これらを後から導入するのは多くのコストが必要になるため、最初から厳密に従うのが得策です。
- すべてのサービスに独自のデータベース スキーマを持たせます。 リレーショナル データベースと NoSQL ソリューションのどちらを使用する場合でも、各サービスに独自のスキーマを持たせ、他のサービスからはそのスキーマにアクセスしないようにします。複数のサービスが同じスキーマを使用すると、時間の経過とともにそれらのサービスはデータベース レイヤで互いに密結合するようになります。 このような依存関係があると、サービスの独立したテストとデプロイが困難になり、変更が行いにくく、デプロイに伴うリスクが大きくなります。
- サービスはネットワーク上で、公開 API でのみ通信を行うようにします。すべてのサービスが公開 API で動作を公開し、サービスは互いにこれらの API でのみ通信を行うようにします。 「バックドア」アクセスや、サービスが他のサービスのデータベースに直接アクセスすることは行うべきではありません。 これにより、サービスの密結合を防止し、サービス相互の通信では十分に文書化されたサポート対象の API が使用されることを保証できます。
- サービスはクライアントに対して下位互換性の責任を負います。 サービスのビルドと運用を行うチームは、サービスの更新によって消費者への悪影響が発生しないことを保証する責任があります。 このためには、下位互換性を保証するため API のバージョニングとテストを計画し、新しいバージョンをリリースするとき既存の顧客に悪影響を与えないようにします。 チームは、カナリア リリースを使用してこの検証を行えます。また、Blue/Green デプロイや段階的な公開などの技法を使用し、デプロイメントによってダウンタイムが発生しないことも保証します。
- 開発ワークステーションでサービスを実行する、標準的な方法を規定します。デベロッパーは、本番サービスの任意のサブセットを、開発用ワークステーションで、単一のコマンドによりオンデマンドで起動可能である必要があります。また、サービスのスタブ バージョンもオンデマンドで実行可能である必要があります。多くのクラウド プロバイダで支援用に提供されている、クラウド サービスのエミュレートされたバージョンを必ず使用するようにします。デベロッパーがサービスのテストとデバッグをローカルで簡単に行えるようにすることが目標です。
- 本番環境のモニタリングとオブザーバビリティに投資します。本番環境でのパフォーマンスなどの問題の多くは、複数のサービス間の連携により引き起こされ、出現します。Google の調査では、システム全体の健全性をレポートするソリューションを導入することが重要であると判明しています。(たとえば、システムが機能しているか、システムには十分なリソースがあるか、など)また、本番環境でのインフラストラクチャの問題を、サービス間の連携も含めてトレース、把握、診断するため役立つツールとデータをチームが使用できるようにすることも重要であると判明しています。
- サービスのサービスレベル目標(SLO)を設定し、障害復旧テストを定期的に行います。 サービスの SLO を設定することで、サービスのパフォーマンスの期待値を設定でき、サービスが停止した場合にシステムがどのように動作するべきかを計画できます(復元性のある分散システムを構築するときの主要な考慮事項)。障害復旧のテスト計画の一部として、本番環境システムが実際の環境でどのように動作するかを、管理された障害注入などの技法を使用してテストします。DORA の調査から、このような手法を使用して障害復旧のテストを実施している組織では、サービスの可用性が高くなる傾向が示されています。 この作業は開始が早ければ早いほどよいので、この種の重要な作業を正規化することもできます。
このような多くの考慮点があるため、このようなアイデアの実装をテストする容量と能力を持つチームと協力し、この種の作業の試験を行っておくことが重要です。 成功も失敗も発生するでしょう。重要なのは、これらのチームから教訓を得て、組織全体に新しいアーキテクチャのパラダイムを拡大するとき応用することです。
Google の調査では、成功を収めた会社は概念実証を使用し、チームが教訓を共有する機会(たとえば実践のコミュニティを作り上げるなどの方法)を用意していることが判明しています。複数のチームのメンバーが定期的に会合を持ち、アイデアを交換できるよう、時間、場所、リソースを用意します。 また、すべてのメンバーは新しいスキルとテクノロジーを学ぶ必要があります。 メンバーの成長を促すため、書籍の購入、トレーニング コースの受講、会議への参加などの予算を与えます。 メンバーがグループの知識や優れた実践化方式を周囲に広められるよう、会社のメーリング リスト、ナレッジベース、直接対面のインフラストラクチャと時間を提供します。
リファレンス アーキテクチャ
このセクションでは、次のガイドラインに基づくリファレンス アーキテクチャについて解説します。
- 本番環境サービスにコンテナを使用し、Cloud Run や Kubernetes などのコンテナ スケジューラでオーケストレーションを行います。
- 効果的な CI / CD パイプラインの作成
- セキュリティの重視
本番環境サービスのコンテナ化
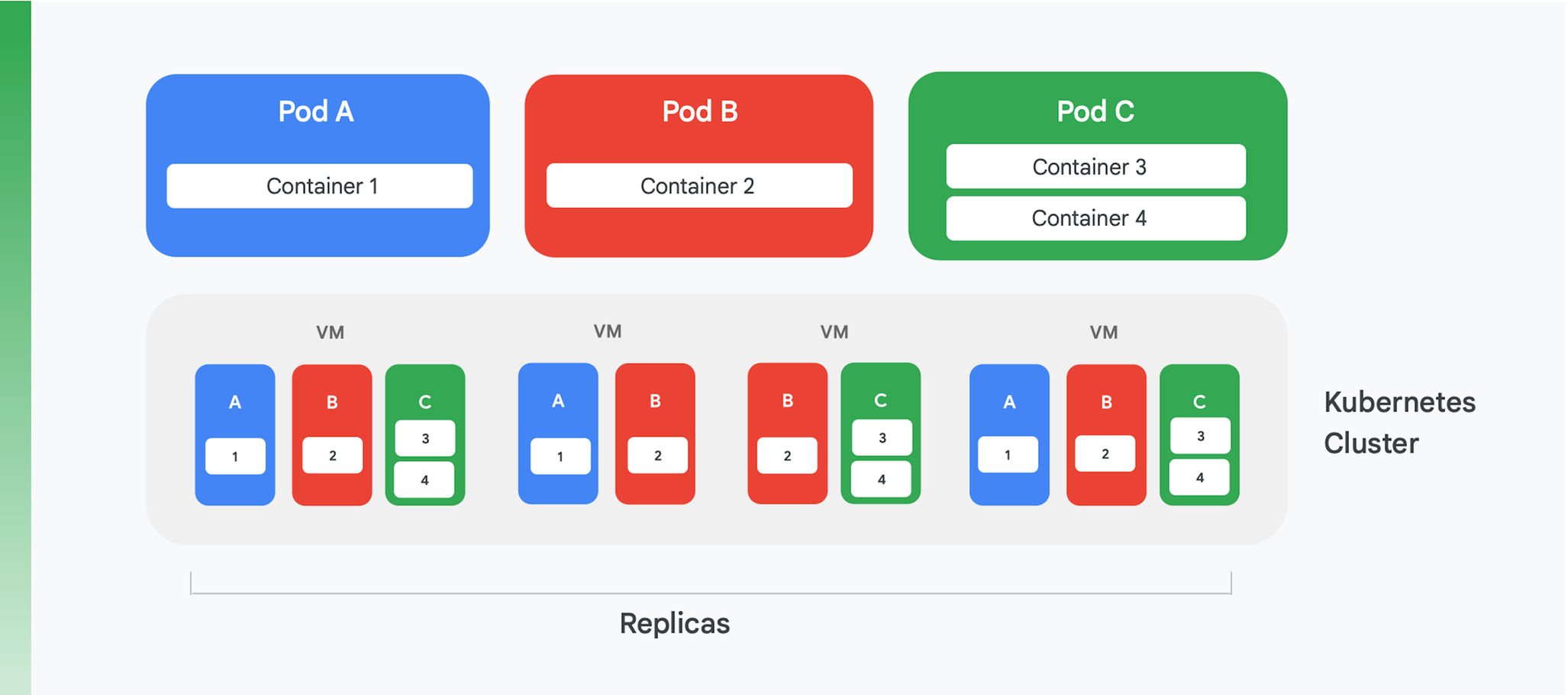
コンテナ化されたクラウド アプリケーションの基礎となっているのは、コンテナ管理とオーケストレーション サービスです。 多くの異なるサービスが作成されていますが、今日の主流になっているのは Kubernetes です。Kubernetes は、コンテナ オーケストレーションの業界標準となっており、活発なコミュニティをホストし、多くの大手商用ベンダーからの支持を集めています。Kubernetes クラスタの論理構造の要約を、図 4 に示します。
Kubernetes は、Pod と呼ばれる抽象化を定義します。各 Pod には多くの場合、図 4 の Pod A や B のようにコンテナが 1 つだけ含まれますが、Pod C のように複数のコンテナを含めることもできます。各 Kubernetes サービスはクラスタを運用し、クラスタにはいくつかのノードが含まれ、これらのノードは一般に仮想マシン(VM)です。 図 4 では 4 つの VM だけが示されていますが、実際のクラスタには数百またはそれ以上の VM が含まれることもあります。 Kubernetes クラスタに Pod がデプロイされるとき、サービスはその Pod のコンテナをどの VM で実行するかを決定します。コンテナは必要なリソースを指定するため、Kubernetes は各 VM にどの Pod を割り当てるかをインテリジェントに選択できます。
Pod のデプロイメント情報の一部は、Pod が運用すべきインスタンス(レプリカ)の数を示すものです。 その後で、Kubernetes サービスはそれと同じ数だけ Pod のコンテナのインスタンスを作成し、VM に割り当てます。 たとえば図 4 では、Pod A のデプロイメントに 3 つのレプリカが必要で、Pod C のデプロイメントも同様です。 これに対して Pod B のデプロイメントには 4 つのレプリカが必要なため、この例のクラスタにはコンテナ 2 の運用中のインスタンスが 4 つ含まれています。 この図から示されるように、Pod C のように複数のコンテナを持つ Pod は常に、それらのコンテナが同じノードに割り当てられます。
Kubernetes は、次のような他のサービスも提供します。
- 運用中の Pod のモニタリングにより、コンテナに障害が発生した場合、サービスは新しいインスタンスを開始します。これにより、Pod のデプロイメントで要求されたすべてのレプリカが利用可能に維持されることが保証されます。
- トラフィックの負荷分散により、各 Pod に対して発行されたリクエストをコンテナのレプリカ間でインテリジェントに分散します。
- 新しいコンテナのダウンタイムなしでの自動ロールアウトにより、新しいインスタンスは既存のインスタンスを段階的に置き換え、最終的には新しいバージョンが完全にデプロイされます。
- 自動スケーリングにより、クラスタはオンデマンドで VM を自律的に追加または削除します。
効果的な CI / CD パイプラインの作成
モノリシック アプリケーションのリファクタリングにはコストの低減などの利点があり、そのいくつかは Kubernetes で運用することによる直接的な利点です。 しかし、最も重要な利点の一つである、アプリケーションの頻繁な更新を可能にするには、ソフトウェアのビルドとリリースの方法を変更する必要があります。 この利点を得るには、組織内で効果的な CI / CD パイプラインを作成する必要があります。
継続的インテグレーションのためには、自動化されたビルドとテストのワークフローにより、デベロッパーに迅速なフィードバックを行う必要があります。同じコード(たとえば、単一のサービスのコード)の作業を行っているチームのすべてのメンバーが、自分たちの作業を共有のメインライン、またはトランクに定期的に統合する必要があります。 この統合はデベロッパーごとに最低でも毎日行い、統合ごとに自動テストを含むビルドプロセスにより検証する必要があります。 継続的デリバリーは、この統合コードのデプロイメントを迅速かつ低リスクにすることを目指すもので、主にビルド、テスト、デプロイメントの処理を自動化し、パフォーマンス、セキュリティ、データ探索のテストなどの作業を継続的に行えるようにすることで実現されます。簡単に述べると、CI によりデベロッパーは統合の問題を迅速に検出でき、CD によりデプロイメントの信頼性が高く、日常的なものになります。
これを明確にするには、実際の例について調べるのが役立ちます。 図 5 は、Google Kubernetes Engine 上で動作するコンテナ用の Google ツールを使用する CD / CD パイプラインがどのようなものかを示したものです。
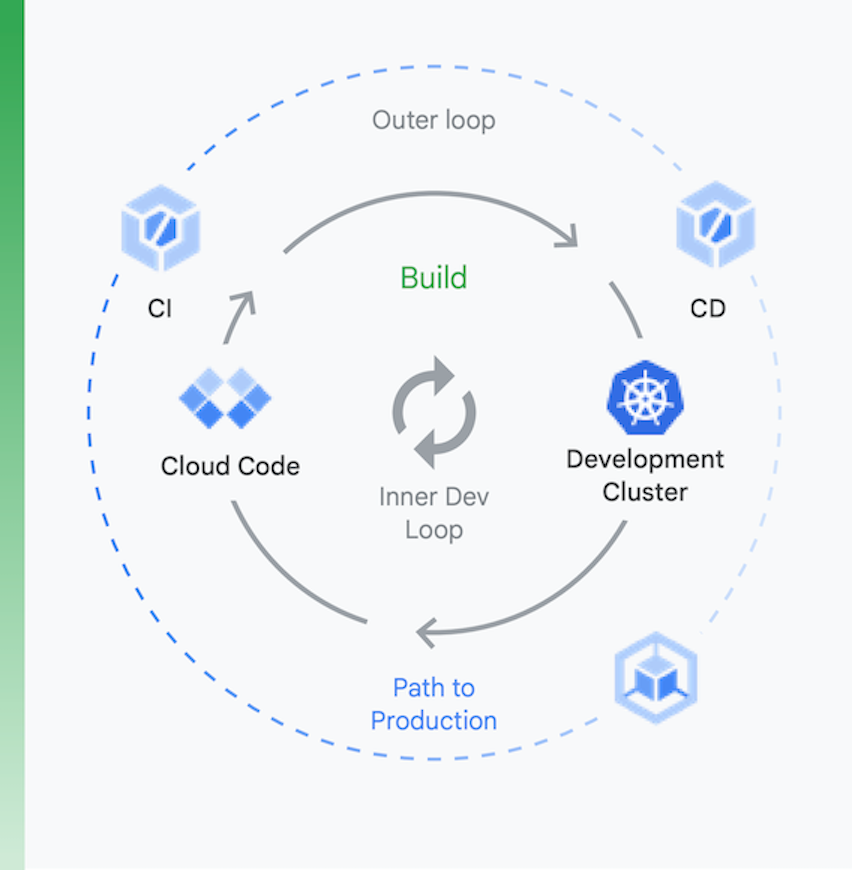
この処理は、図 6 に示すように 2 つの部分に分割して考えるのが適切です。
ローカルでの開発 | リモート開発 |
ここでの目標は、内部の開発ループを高速化し、ローカルコードの変更の影響に関するフィードバックを迅速に得られるようなツールをデベロッパーに与えることです。 これには、lint チェック、YAML の自動コンプリート、ローカルビルドの高速化のサポートが含まれます。 | pull リクエスト(PR)が送信されると、リモートの開発ループが開始されます。ここでの目標は、PR の検証とテストに要する時間を CI で劇的に短縮し、脆弱性スキャンやバイナリ署名など他の作業を実行すると同時に、自動化された方法でリリースの承認を得ることです。 |
ローカルでの開発
リモート開発
ここでの目標は、内部の開発ループを高速化し、ローカルコードの変更の影響に関するフィードバックを迅速に得られるようなツールをデベロッパーに与えることです。 これには、lint チェック、YAML の自動コンプリート、ローカルビルドの高速化のサポートが含まれます。
pull リクエスト(PR)が送信されると、リモートの開発ループが開始されます。ここでの目標は、PR の検証とテストに要する時間を CI で劇的に短縮し、脆弱性スキャンやバイナリ署名など他の作業を実行すると同時に、自動化された方法でリリースの承認を得ることです。
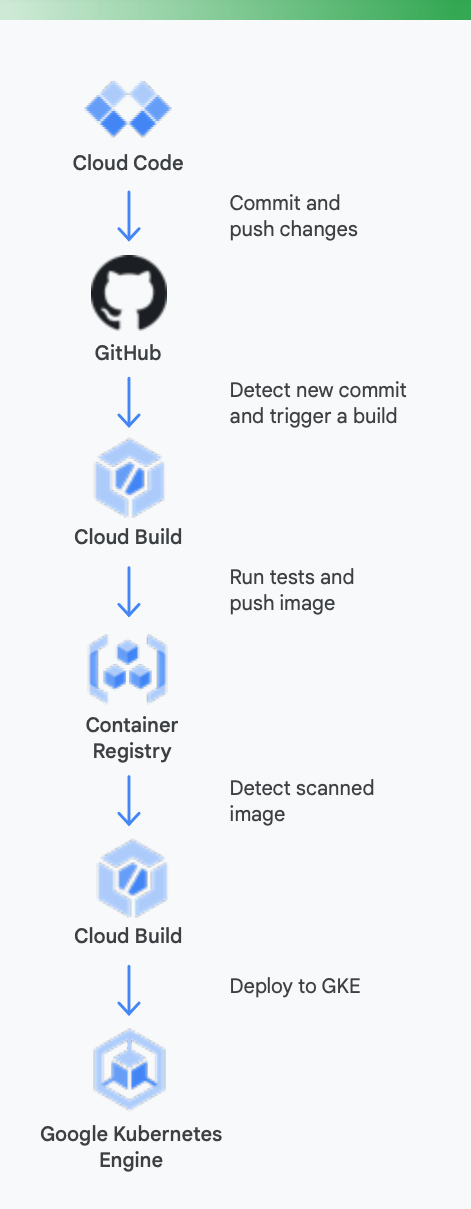
この処理に Google Cloud ツールがどのように役立つか
ローカルでの開発: ローカルでのアプリ開発で生産性を高めることが不可欠です。 ローカルでの開発は、ローカルとリモートのクラスタにデプロイ可能なアプリケーションのビルドを伴います。 GitHub などのソース制御管理システムに変更をコミットする前に、高速なローカル開発ループがあれば、デベロッパーが変更をローカル クラスタでテストしデプロイすることを保証できます。
Google Cloud は、結果として Cloud Code を提供します。 Cloud Code には Visual Studio Code や Intellij などの IDE への拡張機能が付属しているため、デベロッパーは Kubernetes 上でコードのイテレーション、デバッグ、実行を迅速に行えます。Cloud Code は Skaffold、Jib、Kubectl など一般的なツールをバックグラウンドで使用するため、デベロッパーはコードへのフィードバックを継続的にリアルタイムで得ることができます。
継続的インテグレーション: 新しい Cloud Build GitHub アプリにより、チームはさまざまなリポジトリ イベント(pull リクエスト、ブランチ、タグイベント)で、GitHub 内から直接ビルドをトリガーできます。Cloud Build は完全なサーバーレス プラットフォームで、負荷に応じてスケールアップとスケールダウンを行い、サーバーの事前プロビジョニングや、追加容量を事前に購入するなどの要件はありません。GitHub アプリでトリガーされるビルドは、ステータスを自動的に GitHub へ返信します。 このフィードバックは GitHub のデベロッパー ワークフローに直接統合されるため、コンテキスト切り替えが減少します。
アーティファクト管理:Container Registryで、チームは Docker イメージの管理、脆弱性スキャンの実行、および誰が何にアクセスできるかの細かいアクセス制御を、すべて 1 か所で行うことができます。脆弱性スキャンを Cloud Build と統合することで、デベロッパーは Cloud Build がイメージを作成し、Container Registry に保存するとすぐに、セキュリティへの脅威を特定できます。
継続的デリバリー: Cloud Build は、ビルドステップを使用し、ビルド、テスト、デプロイの一部として特定のステップを実行します。たとえば、新しいコンテナが作成され Container Registry に push されると、それ以後のビルドステップでそのコンテナを、関連する構成やポリシーとともに Google Kubernetes Engine(GKE)や Cloud Run にデプロイできます。また、マルチクラウド戦略を追求する場合は他のクラウド プロバイダにもデプロイできます。最後に、GitOps 形式の継続的デリバリーをお求めの場合は、Cloud Build により、Git リポジトリに保存されているファイル(Kubernetes マニフェストなど)を使用してデプロイメントを宣言的に記述できます。
ただし、コードのデプロイですべての作業が完了するわけではありません。 組織では、実行時のコードの管理も必要です。 Google Cloud では、これを実現するために運用チーム向けに Cloud Monitoring や Cloud Logging などのツールを提供しています。
GKE では、Google の CI / CD ツールの使用が必須ではありません。希望するなら、別のツールチェーンも使用できます。 例として、CI / CD に Jenkins を、アーティファクト管理に Artifactory を利用できます。
VM ベースのクラウド アプリケーションを持つほとんどの組織は、十分な能力を持つ CI / CD システムを現状ではおそらく保有していません。 再構築されたアプリケーションの利点を活用するには、このようなシステムの設置が不可欠ですが、これには作業が必要です。 パイプラインを作成するため必要なテクノロジーが利用可能な理由の一部は、Kubernetes の成熟性です。 しかし、人間側の変更も大きなものになる可能性があります。デリバリー チームのメンバーは、開発、テスト、運用を含む各種職能のスキルを持つ必要があります。 文化の転換には時間が必要なため、メンバーが CI / CD の世界へ移行するときに知識と行動を変えるための労力を費やす準備が必要です。
セキュリティの重視
モノリシック アプリケーションをクラウドネイティブのパラダイムに再構築するのは大きな変更です。これによって新たなセキュリティの課題が発生し、対処が必要となるのは驚くにあたりません。 最も重要なのは次の 2 つです。
- コンテナ間のアクセスのセキュリティ保護
- セキュリティ保護されたソフトウェア サプライ チェーンの保証
最初の課題は、アプリケーションをコンテナ化されたサービス(おそらくはマイクロサービス)に分割するには、それらのサービスが通信を行う方法が必要であるという明白な事実に起因するものです。 そして、これらのサービスはすべて同じ Kubernetes クラスタで動作している可能性がありますが、サービス間のアクセスを管理する方法については依然として考慮が必要です。 結局のところ、その Kubernetes クラスタは他のアプリケーションと共有している可能性があるため、コンテナをそれら他のアプリに対して開放しておくことはできません。
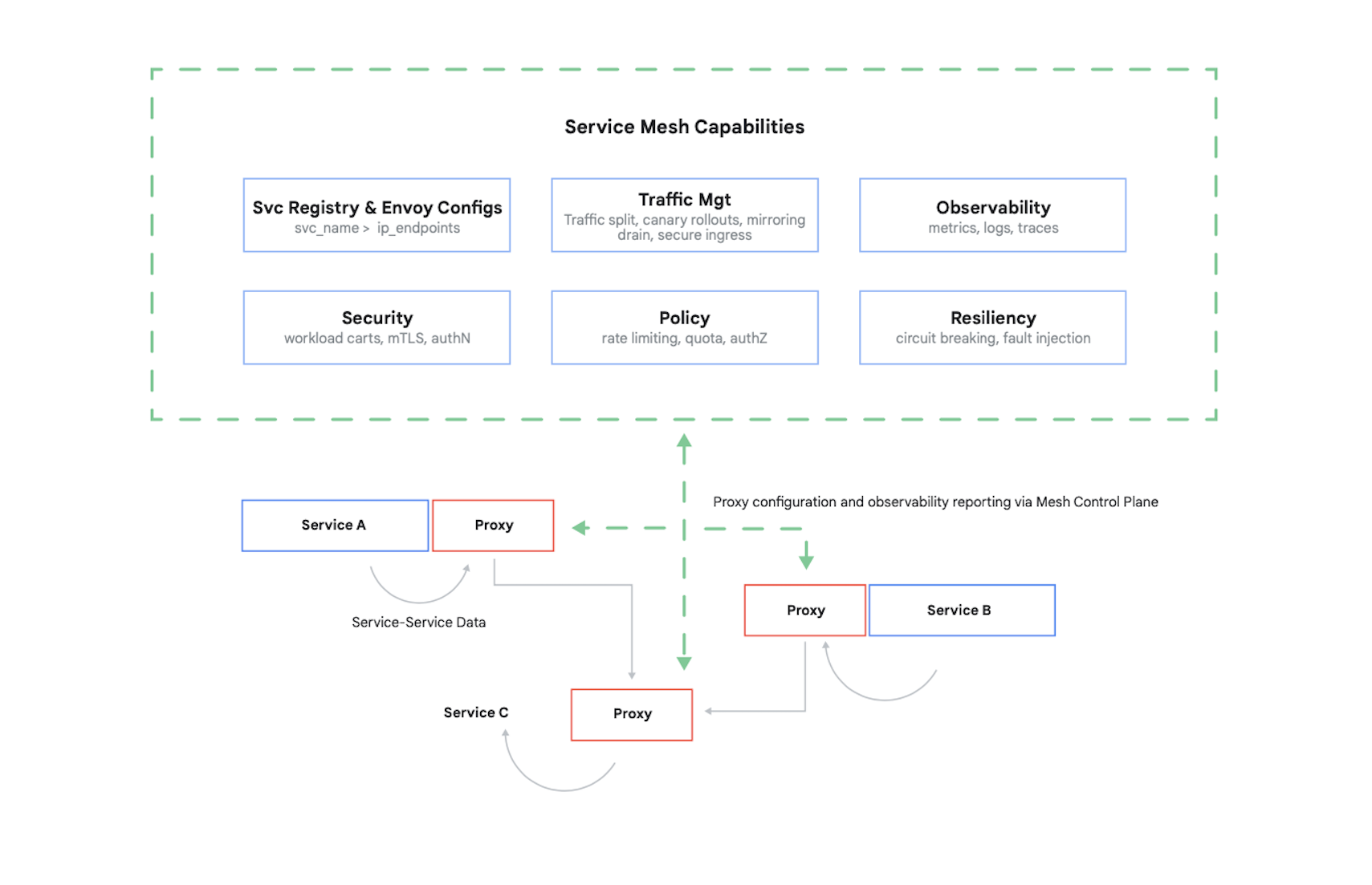
コンテナへのアクセスを制御するには、呼び出し元を認証してから、他のコンテナが承認する 17 件のリクエストを判断する必要があります。今日では、この問題(および、いくつかの他の問題)をサービス メッシュで解決するのが一般的です。 主な例として、Google、IBM、他の会社により作成されたオープンソースである Istio が挙げられます。Kubernetes クラスタ内で Istio が占める位置を、図 7 に示します。
この図に示されているように、Istio プロキシはアプリケーション内のコンテナ間に発生するすべてのトラフィックを傍受します。 これにより、サービス メッシュはアプリケーション コードの変更なしに、いくつかの有用なサービスを提供できます。 次のようなサービスがあります。
- セキュリティ、TLS を使用するサービス間認証と、エンドユーザー認証の両方
- トラフィック管理で、アプリケーション内のコンテナ間でリクエストのルーティング方法を管理
- オブザーバビリティで、コンテナ間の通信のログと指標をキャプチャ
Google Cloud では、GKE クラスタに Istio を追加できます。サービス メッシュの使用は必須ではありませんが、クラウド アプリケーションの顧客に知識がある場合、貴社のセキュリティが Istio と同等のレベルがどうかを問い合わせる可能性があります。 顧客はセキュリティについて深い関心があり、コンテナベースの世界において、Istio はセキュリティを提供するための重要な部分です。
オープンソースの Istio のサポートとともに、Google Cloud は完全な Google Cloud マネージド サービス メッシュ制御プレーンである Traffic Director を提供しています。これにより、複数のリージョン内のクラスタや VM インスタンスの間でグローバルな負荷分散を実現し、ヘルスチェックをサービス プロキシからオフロードし、上述のような洗練されたトラフィック管理やその他の機能を提供できます。
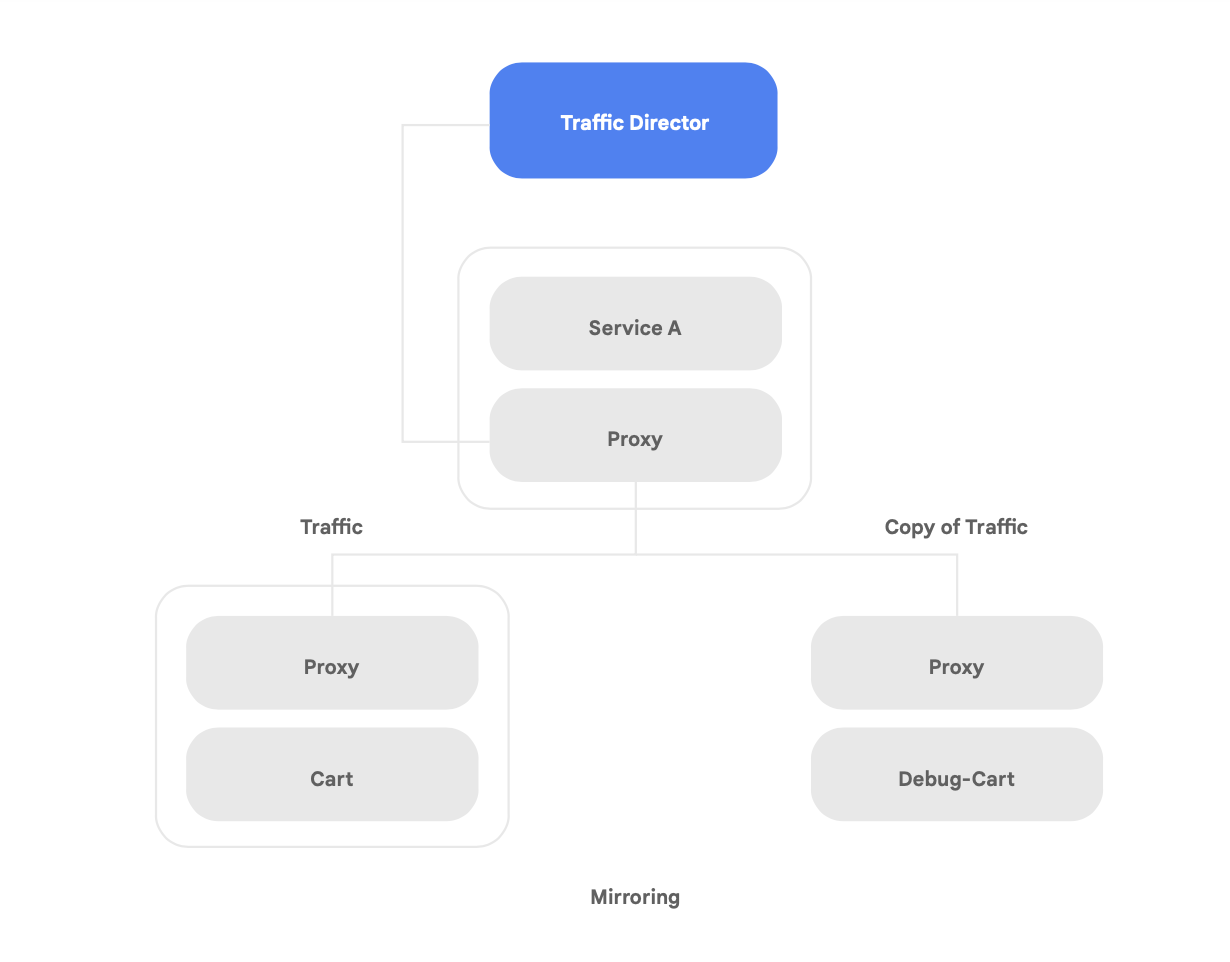
Traffic Director 固有の機能の一つは、メッシュ内のマイクロサービスについて、リージョン間フェイルオーバーとオーバーフローを自動的に行う機能(図 8 に示すもの)です。
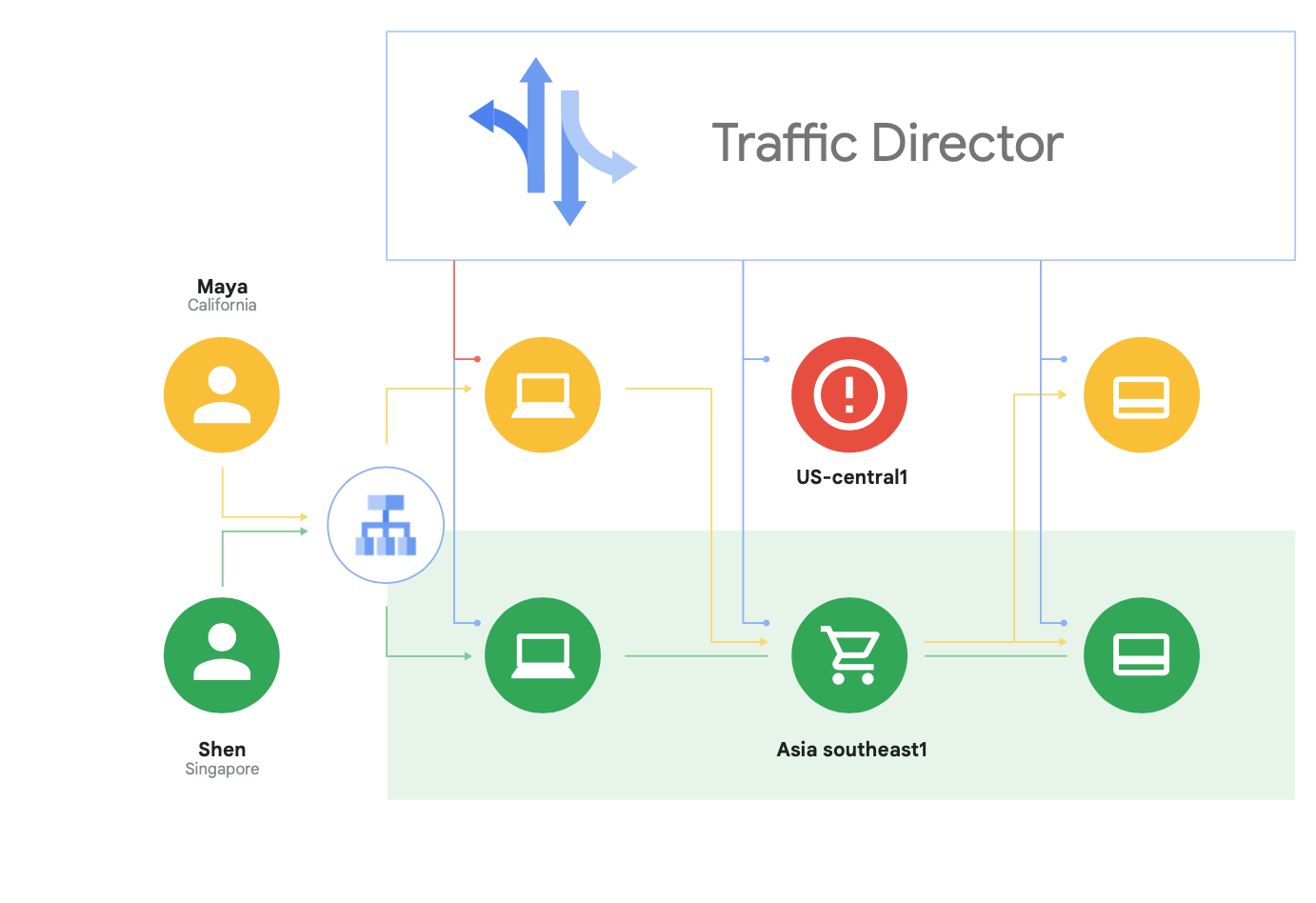
この機能を使用して、サービス メッシュ内のサービスでグローバルな復元性とセキュリティとを結合できます。
Traffic Director には、いくつかのトラフィック管理機能があり、サービス メッシュのセキュリティ態勢を強化するため役立ちます。 たとえば、図 9 に示すトラフィックのミラーリング機能はポリシーとして簡単にセットアップでき、アプリのメイン バージョンが処理している実際のトラフィックのコピーをシャドウ アプリケーションが受信できます。シャドウ サービスによって受信されたコピーの応答は、処理後に破棄されます。トラフィックのミラーリングは、本番環境のトラフィックにおけるセキュリティの異常のテストやエラーのデバッグを、本番環境のトラフィックに影響を及ぼす、または触れることなく行える強力なツールです。
しかし、リファクタリングされたアプリケーションで発生する新しいセキュリティの課題は、コンテナ間の連携の保護だけではありません。 動作しているコンテナ イメージが信頼できるものであると保証することが、別の問題点です。 このためには、ソフトウェアのサプライ チェーンにセキュリティとコンプライアンスが組み込まれていることを確認する必要があります。
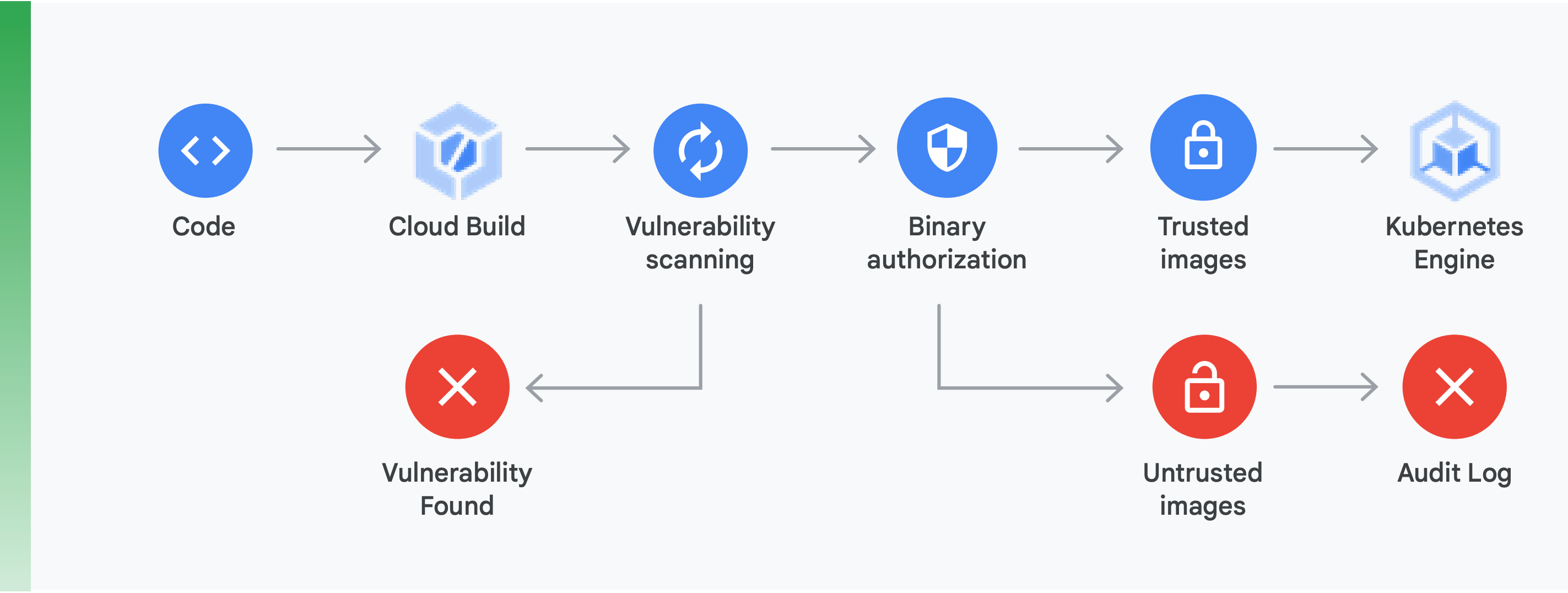
このためには、2 つの主な作業を行う必要があります(図 10 を参照)。
脆弱性スキャン: Container Registry の脆弱性スキャンを使用すると、Cloud Build でコンテナがビルドされ、Container Registry に保存されるとすぐに、潜在的な脅威について迅速にフィードバックを得て、問題点を特定できます。Ubuntu、Debian、Alpine のパッケージの脆弱性はアプリケーションの開発処理の間に特定され、CentOS や RHEL も近日中にサポートされます。 これによって、多くの費用を浪費する非効率性が避けられ、既知の脆弱性を修正するため必要な時間を短縮できます。
Binary Authorization: Binary Authorization と Container Registry 脆弱性スキャンを統合することで、デプロイ ポリシー全体の一部として、脆弱性スキャンでの検出事項に基づいてデプロイメントをゲーティングできます。Binary Authorization はデプロイ時のセキュリティ管理で、信頼できるコンテナ イメージのみが GKE にデプロイされることを、人手による介入なしに保証できます。
コンテナとサービス メッシュとの間のアクセスを保護し、ソフトウェアのサプライ チェーンが保護されていることを保証するのは、セキュアなコンテナベースのアプリケーションを作成するための重要な要素です。 これ以外にも、ビルドの基礎となるクラウド プラットフォーム インフラストラクチャのセキュリティの検証など、多くの要素があります。 しかし最も重要なのは、モノリシック アプリケーションから現代的なクラウドネイティブのパラダイムに移動することで、セキュリティの新たな課題が発生すると理解することです。この移行を正しく行うには、どのような課題が発生するかを理解してから、それぞれの課題に対処するための明確な計画を作成する必要があります。
使ってみる
クラウドネイティブのアーキテクチャへの移動を、何年にもわたる大規模なプロジェクトとみなすべきではありません。
代わりに、概念実証を開始するための容量と専門的技術を持つ、またはすでにその実績があるチームを見つけます。次に、得られた教訓を基に、組織全体への拡大を開始します。 チームがストラングラー フィグ パターンを採用し、サービスに新機能を継続的に追加するとともに、クラウドネイティブのアーキテクチャへと段階的かつ反復的に移行するようにします。
成功のためには、チームの日常業務の一部としてシステム アーキテクチャの進化を行えるだけの容量、リソース、権限がチームに存在することが不可欠です。 先ほど提示した 6 つのアーキテクチャの結果に従い、新しい作業には明確なアーキテクチャの目標を設定します。ただし、それらの目標を達成する方法はチームで自由に決めます。
最も重要なのは、今すぐ作業を始めることです。チームの生産性とアジリティを向上させて、サービスのセキュリティと安定性を強化するのは、組織の成功のためますます重要になっていきます。 日常業務の一部として統制された実験と改良を行うチームが、最高の結果を収めることができます。
Google は、社内で何年も使用してきたソフトウェアを基礎として Kubernetes を作成しました。そのため、Google はクラウドネイティブのテクノロジーについて最も深い経験を保有しています。
Google の CI / CD やセキュリティのプロダクトから明らかなように、Google Cloud はコンテナ化されたアプリケーションに特化しています。実際に、Google Cloud はコンテナ化されたアプリケーションのサポートにおいて現在最先端のプロダクトとなっています。
cloud.google.com/devops をご覧になるか、Google のクイック チェックを使用して、貴社の現状と、このホワイト ペーパーで解説した疎結合アーキテクチャなどのパターンを実装する方法など、次に行うべき手順についてのアドバイスを確認してください。
多くの Google Cloud パートナーはすでに、この移行について貴社のような組織を支援しています。再構築の道筋を自分で探す必要はありません。経験を積んだガイドから支援を受けることができます。
最初の手順として Google にお問い合わせください。Google のソリューション アーキテクトとのミーティングをスケジュールさせていただきます。 Google は貴社が変化を理解できるよう支援し、さらにそれを実現するため貴社と共同で作業します。
関連情報
https://cloud.google.com/devops - 6 年分の State of DevOps Report です。ソフトウェア デリバリーのパフォーマンスを予測する機能に関する詳細な情報や、お客様のやり方や改善方法を見つけるのに役立つ簡単なチェック。
Site Reliability Engineering: How Google Runs Production Systems(O'Reilly 2016 年)
The Site Reliability Workbook: Practical Ways to Implement SRE(O'Reilly 2018 年)
「How to break a Monolith into Microservices: What to decouple and when」(Zhamak Dehghani 著)
「マイクロサービス: この新しいアーキテクチャ用語の定義」(Martin Fowler 著)
「Strangler Fig Application(ストラングラー フィグ アプリケーション)」(Martin Fowler 著)


















