Suggerimenti per l'ottimizzazione delle prestazioni di MySQL
L'ottimizzazione delle prestazioni è un aspetto fondamentale della gestione di qualsiasi database. L'ottimizzazione delle prestazioni può essere eseguita in ogni fase della gestione di database, a partire dalla scelta dei componenti hardware e software per l'hosting dei server di database, fino alla progettazione del modello di dati e alle configurazioni dello schema. Questo documento fornisce suggerimenti per l'ottimizzazione delle prestazioni per i database MySQL nel cloud, in particolare Cloud SQL per MySQL, comprese le best practice per creare nuove istanze di database e ottimizzare quelle esistenti.
Articoli correlati
Considerazioni relative all'hardware
Le configurazioni hardware sono una considerazione importante per le prestazioni del database. Prima di definire le configurazioni hardware, è importante conoscere il numero di utenti attivi e simultanei di un'applicazione, le dimensioni del database e degli indici e la latenza prevista dell'applicazione o del servizio. Di seguito sono riportate alcune importanti considerazioni relative all'hardware:
CPU
La potenza di elaborazione è uno dei fattori più importanti in un sistema di database ad alte prestazioni. Il numero di connessioni/utenti/thread simultanei determina il numero di core necessari per elaborare le richieste di database. La CPU allocata al database deve essere in grado di gestire il normale carico di lavoro + di picco (estremo) affinché le applicazioni funzionino a livelli ottimali.
Nel caso di Cloud SQL, l'offerta MySQL completamente gestita di Google Cloud, la CPU è allocata sotto forma di CPU virtuali (vCPU). Il numero di vCPU allocate a un database determina, in ultima istanza, la quantità di memoria e la velocità effettiva di rete per un'istanza di database, poiché ogni vCPU ha una quantità massima di memoria allocata e anche la velocità effettiva di rete varia in base al numero di vCPU. Cloud SQL offre la flessibilità necessaria per scalare il numero di vCPU per la tua istanza, consentendoti di soddisfare facilmente i requisiti di memoria e velocità effettiva di rete della tua applicazione.
Memoria
Un aspetto importante per determinare la quantità di memoria da allocare per un database è assicurarsi che le dimensioni del pool di buffer siano sufficienti per contenere il set di lavoro. Il set di lavoro corrisponde ai dati utilizzati attivamente in qualsiasi momento dal database. La memoria allocata deve essere sufficiente per contenere il set di lavoro o i dati a cui si accede di frequente, che di solito sono costituiti da dati di database, indici, buffer di sessione, cache del dizionario e tabelle hash. Un modo per verificare se è stata allocata abbastanza memoria è controllare lo stato delle letture da disco nel database. Idealmente, le letture dal disco dovrebbero essere inferiori o molto ridotte in condizioni di carico di lavoro normali.
In caso di allocazione di memoria insufficiente per l'istanza, l'istanza potrebbe presentare problemi di tipo "Memoria esaurita", che causeranno il riavvio dell'istanza del database e tempo di inattività del database o dell'applicazione.
Archiviazione
L'archiviazione dei database è un altro componente che svolge un ruolo importante nell'ottimizzazione delle prestazioni. Cloud SQL offre due tipi di archiviazione
- SSD (predefinito)
- HDD
Un'SSD offre prestazioni e velocità effettiva molto migliori rispetto all'HDD. Per questo motivo è consigliabile scegliere sempre SSD per prestazioni migliori, in particolare per i carichi di lavoro di produzione.
Le operazioni di I/O al secondo (IOPS) in lettura e scrittura allocate all'istanza dipendono dalla quantità di spazio di archiviazione allocato durante la creazione dell'istanza. Maggiore è la dimensione del disco, maggiore è il numero di IOPS in lettura e scrittura. Per questo motivo, è consigliabile creare istanze con dimensioni dei dati più elevate per migliorare le prestazioni delle IOPS. Lo screenshot di seguito della console Google Cloud mostra il riepilogo delle risorse (inclusa la capacità massima) allocate all'istanza di database al momento della creazione, aiutando gli utenti a confermare e comprendere esattamente come verrà configurato il loro database una volta creata l'istanza.
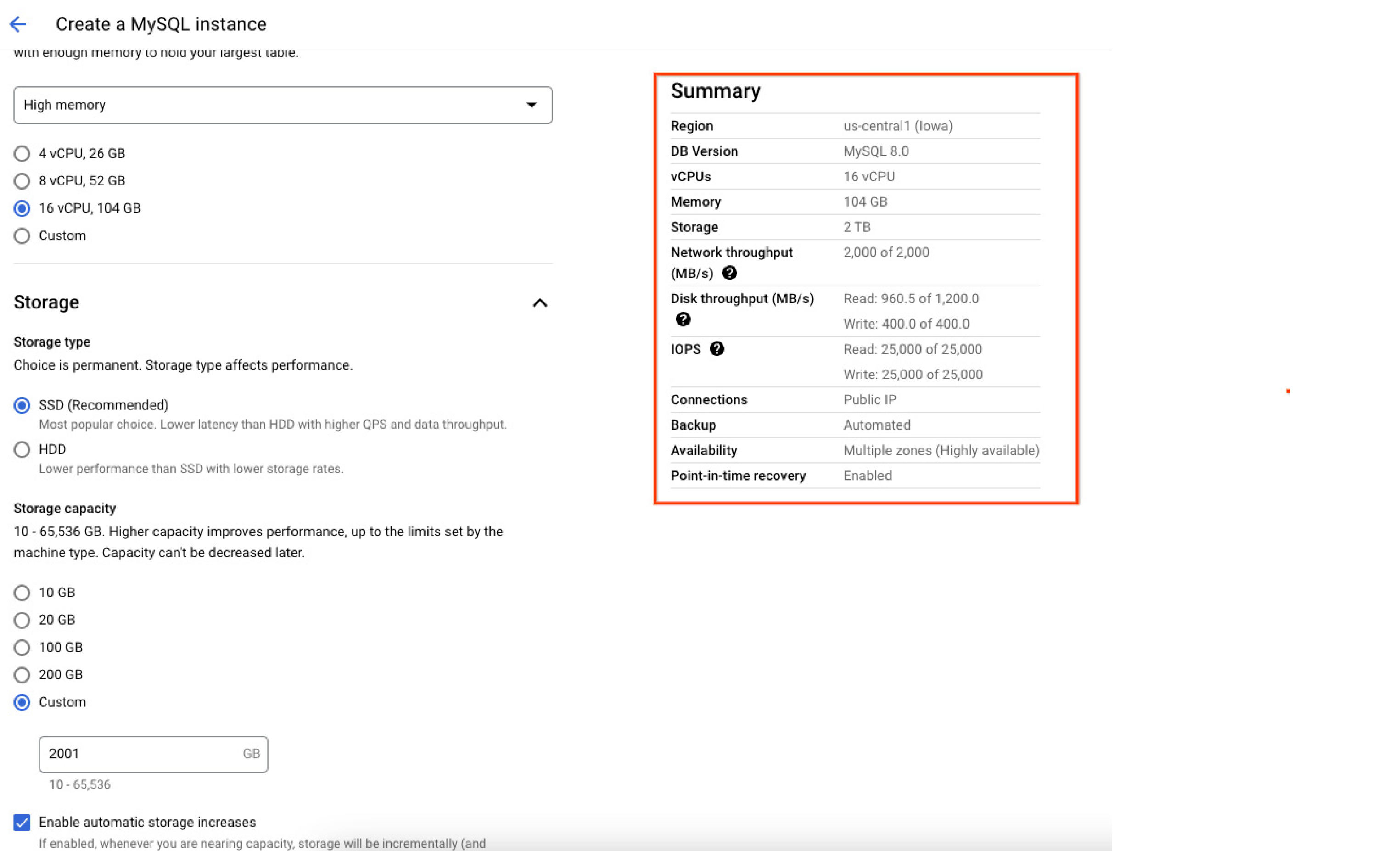
Regione
Un modo per ridurre la latenza di rete è scegliere la regione dell'istanza più vicina all'applicazione o al servizio. Cloud SQL per MySQL è disponibile in tutte le regioni Google Cloud. In questo modo, è più facile creare istanze di un database il più vicino possibile agli utenti finali.
Scalabilità elastica
Cloud SQL offre un modo semplice per eseguire lo scale up o lo scale down delle risorse (CPU, memoria o archiviazione) assegnate a un'istanza di database. Può essere utile per workload con requisiti di risorse variabili. Ad esempio, gli utenti possono aumentare (fare lo scale up) le risorse durante il periodo di aumento del requisito del workload e poi fare lo scale down delle risorse quando la situazione di picco del workload è terminata.
Configurazioni MySQL
Questa sezione contiene le best practice per le configurazioni dei database MySQL al fine di migliorare le prestazioni.
Versione
Scegli la versione più recente di MySQL quando crei un nuovo database. Le versioni più recenti hanno correzioni di bug e ottimizzazioni che migliorano le prestazioni rispetto alle versioni precedenti. Cloud SQL offre la versione più recente di MySQL disponibile sul mercato e lo rende la versione predefinita alla creazione di un nuovo database. Ulteriori dettagli sulle versioni MySQL supportate su Cloud SQL.
Dimensioni del pool del buffer InnoDB
Per le istanze MySQL, InnoDB è l'unico motore di archiviazione supportato. Le dimensioni del pool del buffer Innodb è il primo parametro che un utente dovrebbe definire per prestazioni ottimali. Il pool del buffer è l'area di memoria allocata per archiviare cache delle tabelle, cache di indici, dati modificati prima del flush e altre strutture interne come l'indice di hashing adattivo (AHI, Adaptive Hash Index).
Cloud SQL definisce un valore predefinito pari a circa il 72% della memoria dell'istanza da allocare per il pool del buffer InnoDB, in base alle dimensioni dell'istanza (i valori predefiniti variano in base alle dimensioni dell'istanza). Scopri di più sulle impostazioni del pool del buffer su istanze di diverse dimensioni. Cloud SQL offre la flessibilità di modificare le dimensioni del pool del buffer in base alle esigenze delle tue applicazioni utilizzando i flag di database.
Il pool del buffer deve avere dimensioni tali che sia disponibile una memoria libera sufficiente nell'istanza per il buffer di sessione, la cache del dizionario, le tabelle performance_schema (se abilitate) oltre al pool del buffer InnoDB.
Gli utenti possono controllare le letture del disco effettuate dall'istanza per identificare la quantità di dati letti dai dischi rispetto alle letture soddisfatte dal pool del buffer. Se ci sono più letture dal disco, l'aumento della dimensione del pool del buffer e della memoria dell'istanza migliorerebbe le prestazioni delle query di lettura.
Dimensioni file di log di ripetizione/InnoDB
Il file di log InnoDB o il log di ripetizione registra le modifiche apportate ai dati della tabella. Le dimensioni del file di log InnoDB definiscono le dimensioni del singolo file di log di ripetizione.
Per i carichi di lavoro che richiedono elevati volumi di scrittura, dimensioni dei log di ripetizione più elevate consentono più spazio per le scritture senza che sia necessario eseguire flush di checkpoint frequenti e salvataggi dell'I/O del disco, migliorando così le prestazioni di scrittura. Le dimensioni totali del log di ripetizione, che possono essere calcolate come (innodb_log_file_size * innodb_log_file_size), dovrebbero essere sufficienti per gestire almeno 1-2 ore di scrittura dei dati durante i periodi con intense attività di accesso al database.
Cloud SQL definisce un valore predefinito di 512 MB. Cloud SQL offre inoltre la flessibilità di aumentare le dimensioni del file di log InnoDB utilizzando i flag del database.
NOTA: l'aumento del valore delle dimensioni del file di log InnoDB comporta l'aumento dei tempi di ripristino dagli arresti anomali.
Durabilità
Il flag innodb_flush_log_at_trx_commit controlla la frequenza con cui viene eseguito il flush dei dati di log sul disco e se viene eseguito o meno il flush per ogni commit di transazione.
Le prestazioni di scrittura sulle repliche di lettura possono essere aumentate modificando i valori di innodb_flush_log_at_trx_commit in 0 o 2.
Cloud SQL non supporta la modifica dell'impostazione di durabilità in Cloud SQL Primary. Tuttavia, Cloud SQL consente di modificare il flag sulle repliche di lettura. La riduzione della durabilità delle repliche di lettura migliora le prestazioni di scrittura sulle repliche. Ciò consente di risolvere il ritardo della replica sulle repliche. Scopri di più su innodb_flush_log_at_trx_commitinnodb_flush_log_at_trx_commit
Dimensione del buffer di log InnoDB
La dimensione del buffer del log InnoDB corrisponde alla quantità del buffer che InnoDB utilizza per scrivere nel file di log (log di ripetizione).
Se le transazioni (inserimenti, aggiornamenti o eliminazioni) nel database sono di grandi dimensioni e il buffer utilizzato è superiore a 16 MB, InnoDB deve eseguire l'I/O del disco prima di eseguire il commit della transazione, il che influisce sulle prestazioni. Per evitare l'I/O del disco, aumenta il valore di innodb_log_buffer_size.
Cloud SQL definisce un valore predefinito di 16 MB per la dimensione del buffer di log InnoDB. La variabile di stato MySQL innodb_log_waits mostra il numero di volte in cui innodb_log_buffer_size era piccolo e che InnoDB ha dovuto attendere il flush prima di eseguire il commit della transazione. Se il valore di innodb_log_waits è maggiore di 0 e aumenta, aumenta il valore di innodb_log_buffer_size utilizzando i flag di database per ottenere prestazioni migliori. Il valore di innodb_log_buffer_size e innodb_log_waits può essere identificato eseguendo le seguenti query nella shell di MySQL (interfaccia a riga di comando). Queste query mostrano il valore delle variabili di stato e delle variabili globali in MySQL.
SHOW GLOBAL VARIABLES LIKE 'innodb_log_buffer_size';
SHOW GLOBAL STATUS LIKE 'innodb_log_waits';
Capacità IO InnoDB
La capacità di I/O di InnoDB definisce il numero di operazioni di input/output disponibili per le attività in background (come il flush delle pagine dal pool del buffer e l'unione dei dati dal buffer di modifica).
Il valore predefinito di Cloud SQL per innodb_io_capacity è 5000 e 10.000 per innodb_io_capacity.
Questa impostazione predefinita funziona al meglio per la maggior parte dei carichi di lavoro, ma se il carico di lavoro richiede elevati volumi di scrittura o le modifiche non applicate sull'istanza sono elevate e se sull'istanza è disponibile un numero di operazioni di input/output sufficiente, valuta la possibilità di aumentare innodb_io_capacity e innodb_io_capacity. Puoi trovare il valore delle modifiche applicate utilizzando la seguente query nella shell MySQL:
mysql -e 'show engine InnoDB status \G;' | grep Ibuf
Buffer delle sessioni
I buffer di sessione sono la memoria allocata per le singole sessioni. Se l'applicazione o le query includono molti inserimenti, aggiornamenti, ordinamenti e unioni e hanno bisogno di buffer più elevati, la definizione di valori di buffer più alti durante l'esecuzione della query in una determinata sessione evita il sovraccarico delle prestazioni. Gli utenti possono evitare un'allocazione eccessiva dei buffer a livello globale con un aumento dei valori per tutte le connessioni che, a sua volta, aumenta l'utilizzo totale della memoria dell'istanza. La modifica del valore predefinito per i buffer seguenti contribuisce a migliorare le prestazioni delle query. Questi valori possono essere modificati utilizzando i flag di database.
Tieni presente che si tratta di valori dei buffer per sessione; l'aumento dei limiti può influire su tutte le connessioni e potrebbe determinare un aumento dell'utilizzo della memoria complessivo.
Table_open_cache e Table_definition_cache
Se sono presenti troppe tabelle (oltre le migliaia) nell'istanza di database (in database singoli o multipli), aumenta i valori di table_open_cache e table_open_cache per migliorare la velocità di apertura delle tabelle.
Table_definition_cache velocizza l'apertura delle tabelle e include una sola voce per tabella. La cache di definizione delle tabelle occupa meno spazio e non utilizza descrittori dei file. Se il numero di istanze delle tabelle nella cache degli oggetti del dizionario supera il limite table_definition_cache, un meccanismo LRU inizia a contrassegnare le istanze delle tabelle per l'eliminazione e alla fine le rimuove dalla cache degli oggetti del dizionario per creare spazio per la nuova definizione delle tabelle. Questo processo viene eseguito ogni volta che viene aperto un nuovo tablespace. Solo i tablespace inattivi vengono chiusi. Questa procedura di eliminazione rallenterà l'apertura delle tabelle.
Table_open_cache definisce il numero di tabelle aperte per tutti i thread. Per verificare se è necessario aumentare la cache della tabella, controlla la variabile di stato Opened_tables. Se il valore di Opened_tables è elevato e non utilizzi FLUSH TABLES spesso, considera di aumentare il valore della variabile table_open_cache.
Table_open_cache e Table_open_cache possono essere impostate sul numero effettivo di tabelle nell'istanza. Scopri di più sul motore per suggerimenti per i numeri elevati di tabelle aperte in Cloud SQL.
Nota: Cloud SQL offre la flessibilità per la modifica di questi valori.
Suggerimenti per gli schemi
Definire sempre le chiavi primarie
La definizione di chiavi primarie nelle tabelle consente di organizzare fisicamente i dati in modo da velocizzare la ricerca, il recupero e l'ordinamento dei record e, di conseguenza, di migliorare le prestazioni.
Le chiavi primarie che utilizzano preferibilmente valori interi con incremento automatico sono ideali per i sistemi OLTP.
L'assenza di chiavi primarie è anche uno dei motivi principali dei ritardi del processo di replica o del suo rallentamento negli scenari di replica basati su righe.
Crea indici
La creazione di indici consente di recuperare più rapidamente i dati e quindi di migliorare le prestazioni delle query di lettura. Crea indici per le colonne utilizzate nelle clausole WHERE, ORDER BY e GROUP BY delle query.
NOTA: troppi indici o indici non utilizzati possono ostacolare le prestazioni del database.
Best practice per l'ottimizzazione delle prestazioni
Eseguire benchmark
Esegui test delle prestazioni o benchmark per scoprire se la configurazione è ottimale o può essere migliorata ulteriormente regolando le configurazioni per hardware, database MySQL o progettazione dello schema. Modifica un parametro alla volta ed esamina i risultati rispetto al benchmark per determinare eventuali miglioramenti.
Pool di connessioni
Il pool di connessioni è una tecnica per creare e gestire un pool di connessioni pronte per essere utilizzate da qualsiasi processo che ne abbia bisogno. Il pool di connessioni può aumentare notevolmente le prestazioni dell'applicazione, riducendo al contempo l'utilizzo complessivo delle risorse. Vedi la descrizione dettagliata di come gestire le connessioni dall'applicazione, inclusi il conteggio delle connessioni e il timeout.
Distribuire il carico di lavoro di lettura alle repliche di lettura
Le repliche di lettura (più repliche in tutta la zona) possono essere utilizzate per trasferire il carico di lavoro di lettura dall'istanza principale. Ciò riduce l'overhead o il carico sull'istanza primaria e, a sua volta, migliora le prestazioni dell'istanza primaria. Inoltre, sono disponibili più risorse per le query di lettura sulla replica di lettura.
ProxySQL, un proxy MySQL open source ad alte prestazioni in grado di eseguire il routing delle query di database, può essere utilizzato per scalare orizzontalmente il database Cloud SQL per MySQL.
Evitare query a lunga esecuzione
È noto che le query che vengono eseguite per diversi minuti oppure ore causano un peggioramento delle prestazioni.
- I log di annullamento vengono utilizzati per archiviare la versione precedente delle righe modificate per eseguire il rollback della transazione e anche per fornire la lettura coerente (snapshot di dati) in una transazione. Questi log di annullamento vengono memorizzati sotto forma di elenchi collegati con versioni recenti che fanno riferimento a versioni precedenti, che a loro volta rimandano a versioni precedenti e così via. Le transazioni a lunga esecuzione tendono a ritardare l'eliminazione definitiva dei log di annullamento e pertanto aumentano l'elenco dei log di annullamento. InnoDB deve attraversare l'elevato volume di log di annullamento e il lungo elenco collegato, con conseguente peggioramento delle prestazioni.
- Le query a lunga esecuzione consumano anche risorse (come memoria, buffer, blocchi), che non vengono liberate a lungo e influiscono sulle altre query a causa della mancanza di risorse.
Evitare transazioni di grandi dimensioni
Troppe modifiche ai record (aggiornamento, eliminazione, inserimento) in una singola transazione riserveranno risorse (blocchi, buffer) per troppi record. Questo potrebbe causare un overflow dei buffer dei log comportando I/O su disco. Le query rimanenti dovranno attendere il rilascio delle risorse o dei blocchi. Ciò comporta l'inserimento di una quantità eccessiva di dati nel pool del buffer, impedendone l'ulteriore utilizzo. Il rollback di transazioni di queste dimensioni riduce anche le prestazioni del database. Per ovviare a questo problema, il consiglio è quello di suddividere le transazioni di grandi dimensioni in transazioni più piccole e a esecuzione più rapida.
Ottimizzare le query
Ottimizza sempre le query per ottenere risultati ottimali, ovvero meno risorse ed esecuzione più rapida. Esamina i suggerimenti per l'ottimizzazione delle query MySQL.
Strumenti per l'ottimizzazione delle prestazioni
Monitoraggio
Monitoraggio
Cloud SQL offre dashboard predefinite per diversi prodotti Google Cloud, tra cui una dashboard di monitoraggio di Cloud SQL predefinita. Gli utenti possono utilizzare questa dashboard per monitorare l'integrità generale delle istanze principali e di replica. Gli utenti possono anche creare dashboard personalizzate per visualizzare le metriche di loro interesse. Queste dashboard e metriche consentono di identificare e risolvere vari colli di bottiglia delle prestazioni, come un elevato utilizzo di CPU o memoria, utilizzando i suggerimenti riportati in precedenza. Anche gli avvisi possono essere configurati in base a queste metriche.
Flag relativo alle query lente
Flag relativo alle query lente
Il flag relativo alle query lente può essere abilitato sull'istanza Cloud SQL per MySQL per identificare le query la cui esecuzione richiede più tempo di quello specificato in long_query_time. Queste query lente possono essere analizzate e ottimizzate ulteriormente per migliorare le prestazioni. Scopri come abilitare e verificare le query lente per le istanze Cloud SQL.
Schema delle prestazioni
Schema delle prestazioni
Lo schema delle prestazioni fornisce un monitoraggio di basso livello dell'istanza MySQL. Lo schema delle prestazioni può essere abilitato su un'istanza Cloud SQL per MySQL con memoria superiore a 15 GB. I report dello schema sys forniscono vari report per identificare i colli di bottiglia, le attese, gli indici mancanti, la memoria utilizzata e così via.
Query Insights
Query Insights
Query Insights è una funzionalità nativa di Cloud SQL in cui le query possono essere profilate e analizzate per migliorarne le prestazioni. Query Insights supporta il monitoraggio intuitivo e fornisce informazioni diagnostiche che non si limitano al rilevamento per identificare la causa principale dei problemi di prestazioni.
Suggerimenti sulle prestazioni
Suggerimenti sulle prestazioni
Anche il motore per suggerimenti per un numero elevato di tabelle Cloud SQL è una funzionalità nativa di Cloud SQL che fornisce agli utenti di Cloud SQL suggerimenti per migliorare le prestazioni dei database esistenti, consigli per definire la configurazione al fine di migliorare le prestazioni e ridurre i costi delle istanze. Per ulteriori dettagli, consulta i motori per suggerimenti di Cloud SQL.
Prodotti e servizi correlati
Google Cloud offre un database MySQL gestito che è stato creato per soddisfare le tue esigenze aziendali, dal ritiro del data center on-premise all'esecuzione di applicazioni SaaS, fino alla migrazione dei sistemi aziendali principali.
Fai il prossimo passo
Inizia a creare su Google Cloud con 300 $ di crediti gratuiti e oltre 20 prodotti Always Free.
Hai bisogno di aiuto per iniziare?
Contatta il team di venditaCollabora con un partner di fiducia
Trova un partnerContinua la navigazione
Visualizza tutti i prodotti


















