Conseils d'optimisation des performances pour MySQL
L'optimisation des performances est un aspect essentiel de la gestion d'une base de données. L'optimisation des performances peut être effectuée à chaque étape de la gestion de la base de données, du choix des composants matériels et logiciels pour l'hébergement des serveurs de base de données à la conception du modèle de données et à la configuration des schémas. Ce document fournit des conseils d'optimisation des performances pour les bases de données MySQL dans le cloud, en particulier Cloud SQL pour MySQL, ainsi que les bonnes pratiques pour instancier de nouvelles bases de données et optimiser les bases de données existantes.
Articles associés
Considérations matérielles
La configuration matérielle est un facteur important à prendre en compte pour les performances des bases de données. Avant de définir les configurations matérielles, il est important de bien comprendre le nombre d'utilisateurs actifs et simultanés d'une application, la taille de la base de données et des index, ainsi que la latence attendue de votre application ou service. Voici quelques points à prendre en compte concernant le matériel :
Processeur (CPU)
La puissance de traitement est l'un des facteurs les plus importants pour un système de base de données performant. Le nombre de connexions/utilisateurs/threads simultanés détermine le nombre de cœurs requis pour traiter les requêtes de base de données. Le processeur alloué à la base de données doit pouvoir gérer la charge de travail normale et la charge de travail maximale (extrême) pour que les applications fonctionnent à des niveaux optimaux.
Dans le cas de Cloud SQL (offre MySQL entièrement gérée de Google Cloud), le processeur est alloué sous la forme d'un processeur virtuel (vCPU). Au final, le nombre de processeurs virtuels alloués à une base de données détermine la quantité de mémoire et le débit du réseau pour une instance de base de données, car chaque processeur virtuel dispose d'une quantité maximale de mémoire et même le débit du réseau varie en fonction du nombre de processeurs virtuels. Cloud SQL offre une flexibilité qui permet de faire évoluer le nombre de processeurs virtuels de votre instance. Il est ainsi plus facile de répondre aux exigences de votre application en termes de mémoire et de débit de réseau.
Mémoire
Pour déterminer la quantité de mémoire à allouer à une base de données, il est important de s'assurer que l'ensemble de travail s'intègre dans le pool de mémoire tampon. Un ensemble de travail correspond aux données activement utilisées à tout moment par la base de données. La mémoire allouée doit être suffisante pour contenir cet ensemble de travail ou des données fréquemment consultées, généralement constituées de données de base de données, d'index, de tampons de session, de caches de dictionnaires et de tables de hachage. Pour vérifier si la mémoire allouée est suffisante, vous pouvez vérifier l'état des lectures du disque dans la base de données. Idéalement, les lectures sur le disque devraient être inférieures ou très minimales dans des conditions de charge de travail normales.
En cas d'allocation de mémoire insuffisante pour l'instance, celle-ci peut rencontrer des problèmes d'insuffisance de mémoire qui entraîneront le redémarrage de l'instance de base de données et causeront des interruptions des bases de données ou des applications.
Stockage
Le stockage de base de données est un autre composant qui joue un rôle important dans l'optimisation des performances. Cloud SQL propose deux types de stockage
- SSD (par défaut)
- HDD
Le stockage SSD offre des performances et un débit bien meilleurs que le stockage HDD. C'est pourquoi nous avons toujours choisi le stockage SSD pour de meilleures performances, en particulier pour les charges de travail de production.
Les opérations d'entrée/sortie par seconde (IOPS) de lecture et d'écriture allouées à l'instance dépendent de la quantité d'espace de stockage allouée lors de la création de l'instance. Plus la taille du disque est grande, plus les IOPS de lecture et d'écriture sont élevées. Par conséquent, il est conseillé de créer des instances avec une taille de données plus élevée pour améliorer les performances des IOPS. La capture d'écran ci-dessous de la console Google Cloud affiche une synthèse des ressources (y compris la capacité maximale) allouées à l'instance de base de données au moment de la création. Les utilisateurs peuvent ainsi vérifier et comprendre exactement comment leur base de données sera configurée une fois qu'ils l'instancient.
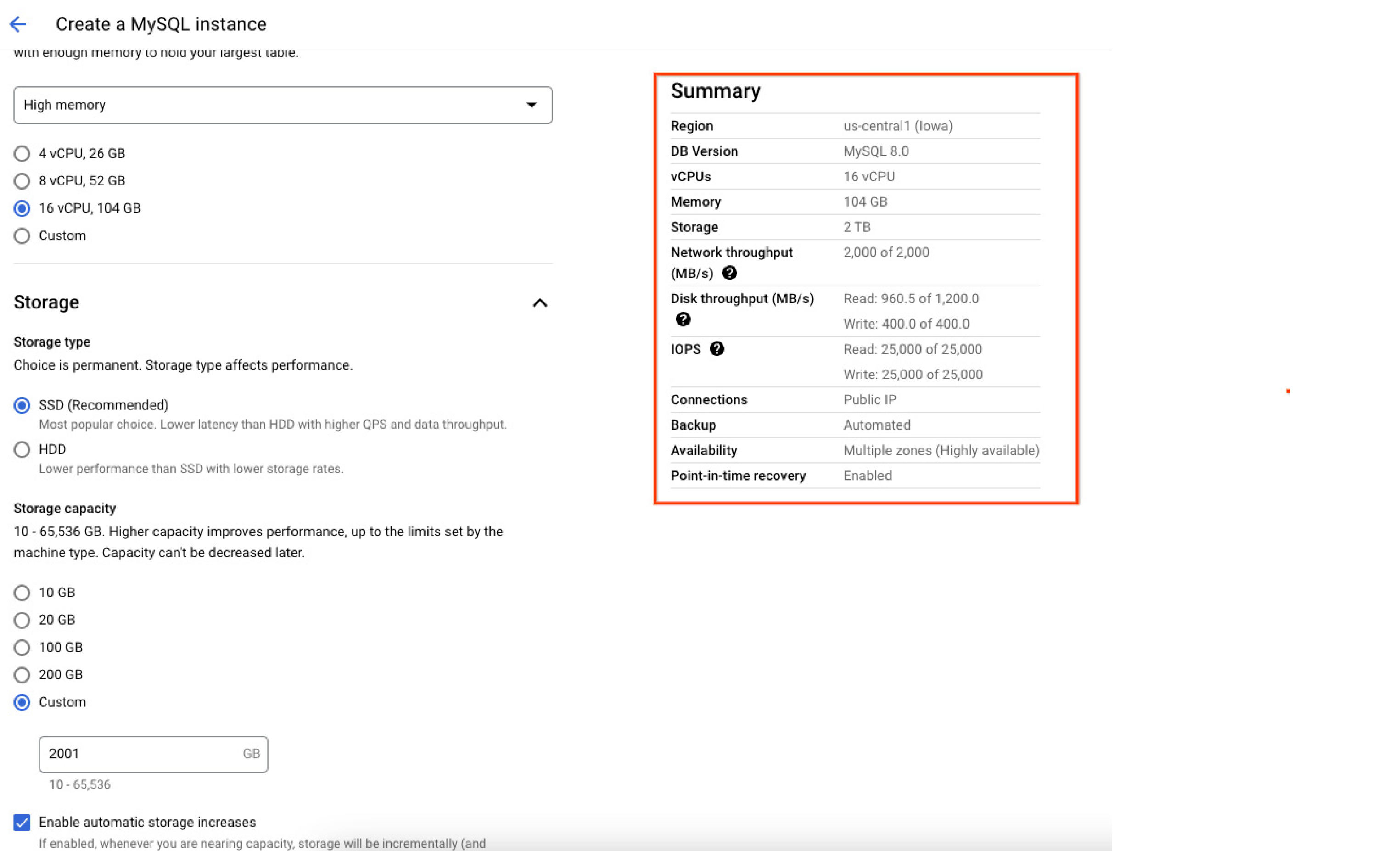
Région
L'un des moyens de réduire la latence du réseau consiste à choisir la région de l'instance la plus proche de l'application ou du service. Cloud SQL pour MySQL est disponible dans toutes les régions Google Cloud, ce qui permet aux utilisateurs d'instancier plus facilement une base de données le plus près possible des utilisateurs finaux.
Scaling élastique
Cloud SQL permet d'augmenter ou de réduire facilement les ressources (processeur, mémoire ou stockage) attribuées à une instance de base de données. Cela peut s'avérer utile pour les charges de travail ayant des besoins variables en ressources. Par exemple, les utilisateurs peuvent augmenter le nombre de ressources pendant la période où la charge de travail augmente, puis les réduire une fois le pic de charge de travail terminé.
Configurations MySQL
Cette section présente les bonnes pratiques de configuration des bases de données MySQL permettant d'améliorer les performances.
Version
Choisissez la dernière version de MySQL lorsque vous créez une base de données. Les dernières versions comportent des corrections de bugs et des optimisations permettant d'améliorer les performances par rapport aux anciennes versions. Cloud SQL fournit la dernière version de MySQL disponible sur le marché et en fait la version par défaut lorsque vous créez une base de données. En savoir plus sur les versions MySQL compatibles avec Cloud SQL.
Taille du pool de mémoire tampon InnoDB
Pour les instances MySQL, InnoDB est le seul moteur de stockage compatible. La taille du pool de mémoire tampon Innodb est le premier paramètre qu'un utilisateur doit définir pour obtenir des performances optimales. Le pool de tampons est la zone de mémoire allouée pour stocker les caches de table, les caches d'index, les données modifiées avant le vidage et d'autres structures internes telles que l'indice de hachage adaptatif.
Cloud SQL définit la valeur par défaut approximative (~72 %) de la mémoire de l'instance à allouer au pool de mémoire tampon InnoDB, en fonction de la taille de l'instance (les valeurs par défaut varient selon la taille de l'instance). En savoir plus sur les paramètres du pool de mémoire tampon pour différentes tailles d'instances Cloud SQL vous permet de modifier la taille du pool de mémoire tampon en fonction des besoins de vos applications à l'aide des options de base de données.
La taille du pool de mémoire tampon doit être suffisante pour que la mémoire disponible sur l'instance soit suffisante pour le tampon de session, le cache du dictionnaire et les tables performance_schema (si cette option est activée), en dehors du pool de mémoire tampon InnoDB.
Les utilisateurs peuvent comparer les lectures de disques à partir de l'instance pour déterminer la quantité de données lues à partir des disques par rapport aux lectures satisfaites à partir du pool de mémoire tampon. Si le nombre de lectures de disques est plus important, l'augmentation de la taille du pool de mémoire tampon et de la mémoire de l'instance améliorera les performances des requêtes de lecture.
Taille du fichier journal de rétablissement/InnoDB
Le fichier journal InnoDB ou journal de rétablissement enregistre les modifications des données de la table. La taille du fichier journal InnoDB définit la taille du fichier journal de rétablissement unique.
Pour les charges de travail lourdes en écriture ayant une taille de journal de rétablissement plus élevée, il y a plus d'espace pour les écritures sans avoir à effectuer une activité de vidage fréquente des points de contrôle et à enregistrer les E/S de disque, ce qui améliore les performances d'écriture. La taille totale du journal de rétablissement, qui peut être calculée comme suit : (innodb_log_file_size * innodb_log_file_size) doit être suffisante pour au moins 1 à 2 heures de données en écriture pendant les périodes chargées d'accès à la base de données.
Cloud SQL définit une valeur par défaut de 512 Mo. Cloud SQL permet également d'augmenter la taille du fichier journal InnoDB à l'aide d'options de base de données.
REMARQUE : L'augmentation de la valeur de la taille du fichier journal InnoDB augmente le temps de récupération après plantage.
Durabilité
L'option innodb_flush_log_at_trx_commit contrôle la fréquence à laquelle les données de journal sont vidées sur le disque et indique s'il faut les vider à chaque commit de transaction.
Vous pouvez augmenter les performances en écriture sur les instances répliquées avec accès en lecture en définissant les valeurs de innodb_flush_log_at_trx_commit sur 0 ou 2.
Cloud SQL ne permet pas de modifier le paramètre de durabilité de l'instance Cloud SQL principale. Toutefois, Cloud SQL permet de modifier l'option sur les instances répliquées avec accès en lecture. La réduction de la durabilité des instances répliquées avec accès en lecture permet d'améliorer les performances d'écriture sur ces instances. Cela permet de réduire le délai de réplication sur les instances répliquées. En savoir plus sur innodb_flush_log_at_trx_commit.
Taille de la mémoire tampon du journal InnoDB
La taille de la mémoire tampon du journal InnoDB correspond à la quantité de mémoire tampon utilisée par InnoDB pour écrire dans le fichier journal (journal de rétablissement).
Si les transactions (insertions, mises à jour ou suppressions) de la base de données sont volumineuses et que la mémoire tampon utilise plus de 16 Mo, InnoDB doit effectuer une E/S de disque avant de valider la transaction, ce qui affecte les performances. Pour éviter les E/S de disque, augmentez la valeur de innodb_log_buffer_size.
Cloud SQL définit une valeur par défaut de 16 Mo pour la taille de la mémoire tampon des journaux InnoDB. La variable d'état MySQL innodb_log_waits indique le nombre de fois où la taille de innodb_log_buffer_size était trop petite et que InnoDB a dû attendre le vidage avant de valider la transaction. Si la valeur de innodb_log_waits est supérieure à 0 et qu'elle augmente, augmentez la valeur de innodb_log_buffer_size à l'aide des options de base de données pour améliorer les performances. La valeur des paramètres innodb_log_buffer_size et innodb_log_waits peut être identifiée en exécutant les requêtes suivantes dans le shell MySQL (CLI). Ces requêtes affichent la valeur des variables d'état et des variables globales dans MySQL.
SHOW GLOBAL VARIABLES LIKE 'innodb_log_buffer_size';
SHOW GLOBAL STATUS LIKE 'innodb_log_waits';
Capacité d'E/S d'InnoDB
La capacité d'E/S d'InnoDB définit le nombre d'IOPS disponibles pour les tâches en arrière-plan (comme le vidage de la page du pool de mémoire tampon et la fusion des données à partir de la mémoire tampon de modification).
Cloud SQL définit les valeurs par défaut de 5 000 pour innodb_io_capacity et de 10 000 pour innodb_io_capacity.
Ces valeurs par défaut sont optimales pour la plupart des charges de travail. Toutefois, si votre charge de travail est lourde en écriture ou si les modifications non appliquées sur l'instance sont élevées, et si vous disposez de suffisamment d'IOPS disponibles sur l'instance, envisagez d'augmenter le nombre les valeurs de innodb_io_capacity et innodb_io_capacity. La valeur des modifications appliquées est obtenue à l'aide de la requête suivante dans le shell MySQL :
mysql -e 'show engine InnoDB status \G;' | grep Ibuf
Tampons de session
Les tampons de session sont la mémoire allouée aux sessions individuelles. Si votre application ou vos requêtes incluent de nombreuses insertions, mises à jour, tris et jointures, et que vous avez besoin de tampons plus élevés, définir des valeurs de tampon élevées lors de l'exécution de la requête au cours d'une session particulière permet d'éviter une surcharge des performances. Les utilisateurs peuvent éviter une allocation excessive de la mémoire tampon au niveau global, ce qui augmente les valeurs de toutes les connexions et augmente l'utilisation totale de la mémoire de l'instance. La modification de la valeur par défaut des tampons suivants permet d'améliorer les performances des requêtes. Ces valeurs peuvent être modifiées à l'aide des options de base de données.
Notez qu'il s'agit de valeurs de tampon par session. L'augmentation des limites peut affecter toutes les connexions et, à terme, entraîner une hausse de l'utilisation de la mémoire globale.
Table_open_cache et Table_definition_cache
Si l'instance de base de données contient trop de tables (dépasse les milliers) (dans une ou plusieurs bases de données), augmentez les valeurs de table_open_cache et table_open_cache pour améliorer la vitesse d'ouverture des tables.
Table_definition_cache accélère l'ouverture des tables et ne dispose que d'une seule entrée par table. Le cache de définition de table prend moins d'espace et n'utilise pas de descripteurs de fichier. Si le nombre d'instances de table dans le cache des objets du dictionnaire dépasse la limite définie par table_definition_cache, un mécanisme LRU commence à marquer les instances de table pour qu'elles soient supprimées, puis les supprime du cache des objets de dictionnaire pour faire de la place à la nouvelle définition de table. Ce processus est effectué chaque fois qu'un nouvel espace de table est ouvert. Seuls les espaces de table inactifs sont fermés. Ce processus d'éviction ralentirait l'ouverture des tables.
Table_open_cache définit le nombre de tables ouvertes pour tous les threads. Vous pouvez vérifier si vous avez besoin d'augmenter le cache de la table en consultant la variable d'état Opened_tables. Si la valeur de Opened_tables est élevée et que vous n'utilisez pas souvent FLUSH TABLES, envisagez d'augmenter la valeur de la variable table_open_cache.
Les variables Table_open_cache et Table_open_cache peuvent être définies sur le nombre réel de tables dans l'instance.. En savoir plus sur l'outil de recommandation Cloud SQL pour nombre élevé de tables ouvertes.
Remarque : Cloud SQL offre une flexibilité pour modifier ces valeurs.
Recommandations concernant les schémas
Toujours définir des clés primaires
La définition des clés primaires dans la table permet d'organiser physiquement les données de manière à faciliter la recherche, la récupération et le tri des enregistrements, et ainsi à améliorer les performances.
De préférence, les clés primaires incrémentées automatiquement à valeur entière sont idéales pour les systèmes OLTP.
L'absence de clés primaires est également l'une des principales raisons du retard de réplication ou du délai de réplication dans les scénarios de réplication basés sur les lignes.
Créer des index
La création d'index accélère la récupération des données et améliore donc les performances des requêtes de lecture. Créer des index pour les colonnes utilisées dans les clauses WHERE, ORDER BY et GROUP BY des requêtes.
REMARQUE : Un nombre trop important d'index ou des index inutilisés peuvent également nuire aux performances de la base de données.
Bonnes pratiques pour l'optimisation des performances
Exécuter des benchmarks
Effectuez des tests de performance ou des analyses comparatives pour voir si la configuration est optimale. Vous pouvez aussi l'améliorer en ajustant les configurations en termes de matériel, de base de données MySQL ou de conception de schéma. Modifiez un paramètre à la fois et comparez-le aux résultats de l'analyse comparative pour voir s'il y a une amélioration.
Regroupement de connexions
Le pooling de connexions est une technique de création et de gestion d'un pool de connexions prêtes à être utilisées par tous les processus qui en ont besoin. Le pooling de connexions peut améliorer considérablement les performances de votre application, tout en réduisant l'utilisation globale des ressources. Consultez les détails sur la gestion des connexions depuis l'application, y compris le nombre de connexions et leur délai d'inactivité.
Répartir la charge de travail de lecture sur les instances répliquées avec accès en lecture
Vous pouvez utiliser des instances répliquées avec accès en lecture (multiples, dans la zone) pour délester la charge de travail de lecture de l'instance principale. Cela permet de réduire les frais généraux ou la charge sur l'instance principale et, par conséquent, d'améliorer ses performances. D'autres ressources sont également disponibles pour les requêtes de lecture sur l'instance répliquée avec accès en lecture.
ProxySQL, un proxy MySQL Open Source hautes performances capable d'acheminer des requêtes de base de données, peut servir à effectuer un scaling horizontal de la base de données Cloud SQL pour MySQL.
Éviter les requêtes de longue durée
Les requêtes exécutées pendant plusieurs minutes ou plusieurs heures sont connues pour dégrader les performances.
- Les journaux d'annulation permettent de stocker l'ancienne version des lignes modifiées afin d'effectuer un rollback de la transaction et fournir une lecture cohérente (instantané des données) dans une transaction. Ces journaux d'annulation sont stockés sous la forme de listes de liens, avec lesquels les versions récentes pointent vers de plus anciennes, qui pointent à leur tour vers de plus anciennes, et ainsi de suite. Les transactions de longue durée ont tendance à retarder la suppression définitive des journaux d'annulation et donc à augmenter la liste des journaux d'annulation. InnoDB doit balayer un grand nombre de journaux d'annulation et une longue liste de liens, ce qui réduit les performances.
- Les requêtes de longue durée consomment également des ressources (telles que la mémoire, les tampons et les verrous), qui ne sont pas libérées pendant une longue période et affectent les autres requêtes en raison du manque de ressources.
Éviter les transactions importantes
Un trop grand nombre de modifications d'enregistrements (mise à jour, suppression, insertion) au cours d'une même transaction va occuper les ressources (verrous, mémoire tampon) pour un trop grand nombre d'enregistrements, Cela peut conduire à un dépassement de la mémoire tampon des journaux, et entraîner des E/S de disque. Les requêtes restantes devront attendre que les ressources ou les verrous soient libérés. Dans ce cas de figure, une quantité de données trop importante occupe le pool de mémoire tampon, ce qui empêche toute autre utilisation du pool. Le rollback de transactions aussi volumineuses dégrade également les performances de la base de données. Pour contourner ce problème, il est recommandé de diviser les transactions importantes en transactions plus petites et plus rapides à exécuter.
Optimiser les requêtes
Optimisez toujours les requêtes pour obtenir les meilleurs résultats, à savoir moins de ressources et une exécution plus rapide. Consultez les recommandations pour Optimiser les requêtes MySQL.
Outils d'optimisation des performances
Surveillance
Surveillance
Cloud SQL propose des tableaux de bord prédéfinis pour plusieurs produits Google Cloud, y compris un tableau de bord de surveillance Cloud SQL par défaut. Les utilisateurs peuvent utiliser ce tableau de bord pour surveiller l'état général de leurs instances principales et répliquées. Les utilisateurs peuvent également créer leurs propres tableaux de bord personnalisés pour afficher les métriques qui les intéressent. L'utilisation de ces tableaux de bord et métriques permet d'identifier différents goulots d'étranglement affectant les performances, tels qu'une utilisation élevée du processeur ou de la mémoire, et d'y remédier à l'aide des recommandations énumérées précédemment. Des alertes peuvent également être configurées en fonction de ces métriques.
Option de requête lente
Option de requête lente
Vous pouvez activer l'option Requêtes lentes sur l'instance Cloud SQL pour MySQL afin d'identifier les requêtes dont l'exécution prend plus de temps que le paramètre long_query_time. Ces requêtes lentes peuvent être analysées et ajustées plus en détail pour améliorer les performances. Découvrez comment activer et vérifier les requêtes lentes pour les instances Cloud SQL.
Schéma des performances
Schéma des performances
Le Schéma de performances fournit une surveillance de bas niveau de l'instance MySQL. Le schéma de performances peut être activé sur une instance Cloud SQL pour MySQL avec une mémoire supérieure à 15 Go. Les rapports de schéma SYS fournissent divers rapports permettant d'identifier les goulots d'étranglement, les temps d'attente, les index manquants, l'utilisation de la mémoire, etc.
Insights sur les requêtes
Insights sur les requêtes
Les insights sur les requêtes sont une fonctionnalité native de Cloud SQL qui permet d'établir un profil et d'analyser des requêtes afin d'améliorer leurs performances. Les insights sur les requêtes permettent une surveillance intuitive et fournissent des informations de diagnostic qui vous aident à aller au-delà de la simple détection pour identifier la cause première des problèmes de performances.
Recommandations concernant les performances
Recommandations concernant les performances
L'outil de recommandation Cloud SQL pour nombre élevé de tables est également une fonctionnalité native de Cloud SQL qui fournit des recommandations de performances aux utilisateurs de Cloud SQL pour améliorer les performances des bases de données existantes. Il fournit aussi des suggestions de configuration afin d'améliorer les performances et de réduire le coût des instances. Pour en savoir plus, consultez les recommandations de Cloud SQL.
Produits et services associés
Google Cloud propose une base de données MySQL gérée conçue pour répondre aux besoins de votre entreprise, de la suppression de votre centre de données sur site à l'exécution d'applications SaaS, en passant par la migration de systèmes d'entreprise de base.
Passez à l'étape suivante
Profitez de 300 $ de crédits gratuits et de plus de 20 produits Always Free pour commencer à créer des applications sur Google Cloud.
Vous avez besoin d'aide pour démarrer ?
Contacter le service commercialFaites appel à un partenaire de confiance
Trouvez un partenairePoursuivez vos recherches
Voir tous les produits


















