Sugerencias de optimización de rendimiento para MySQL
La optimización del rendimiento es un aspecto fundamental de la administración de cualquier base de datos. La optimización del rendimiento se puede realizar en cada paso de la administración de bases de datos, desde la selección de los componentes de hardware y software para alojar los servidores de la base de datos hasta el diseño del modelo de datos y la configuración del esquema. En este documento, se abordan las sugerencias de optimización del rendimiento para las bases de datos de MySQL en la nube, específicamente Cloud SQL para MySQL, incluidas las prácticas recomendadas para crear instancias de bases de datos nuevas y optimizar las existentes.
Artículos relacionados
Consideraciones sobre el hardware
La configuración del hardware es muy importante para el rendimiento de la base de datos. Antes de definir la configuración de hardware, es importante comprender correctamente la de cantidad de usuarios activos y simultáneos de una aplicación, el tamaño de los índices y la base de datos, además de la latencia esperada de la aplicación o el servicio. A continuación, se muestran algunas de las consideraciones de hardware importantes:
Unidad central de procesamiento (CPU)
La potencia de procesamiento es uno de los factores más importantes en un sistema de base de datos de buen rendimiento. La cantidad de conexiones, usuarios y subprocesos simultáneos determina la cantidad de núcleos necesarios para procesar las solicitudes de la base de datos. La CPU asignada a la base de datos debe poder manejar la carga de trabajo normal + la carga de trabajo máxima (extrema) para que las aplicaciones funcionen con niveles óptimos.
En el caso de Cloud SQL, la oferta de MySQL completamente administrada de Google Cloud, la CPU se asigna en forma de CPU virtual. La cantidad de CPU virtuales asignadas a una base de datos determina en última instancia la cantidad de memoria y la capacidad de procesamiento de la red para una instancia de base de datos, ya que cada CPU virtual tiene una cantidad máxima de memoria asignada e incluso la capacidad de procesamiento de red varía según la cantidad de CPU virtuales. Cloud SQL proporciona flexibilidad para escalar la cantidad de CPU virtuales de la instancia, lo que facilita el cumplimiento de los requisitos de memoria y capacidad de procesamiento de red de tu aplicación.
Memoria
Una consideración importante para determinar la cantidad de memoria que se asigna a una base de datos es asegurarse de que el conjunto operativo se ajuste al grupo de búferes. Un conjunto de trabajo son los datos que la base de datos usa de forma activa en cualquier momento. La memoria asignada debe ser suficiente para contener este conjunto de trabajo o los datos a los que se accede con frecuencia, que suelen incluir datos de bases de datos, índices, búferes de sesión, caché de diccionario y tablas hash. Una forma de comprobar si se asignó suficiente memoria es verificar el estado de las lecturas del disco en la base de datos. Lo ideal sería que las lecturas del disco sean mínimas o muy bajas en condiciones normales de carga de trabajo.
En caso de que la asignación de memoria no sea suficiente para la instancia, puede que esta se encuentre con problemas de “memoria insuficiente”, que harán que la instancia de base de datos se reinicie y genere un tiempo de inactividad en la base de datos o la aplicación.
Almacenamiento
El almacenamiento de la base de datos es otro componente que desempeña un papel importante en la optimización del rendimiento. Cloud SQL ofrece 2 tipos de almacenamiento
- SSD (predeterminado)
- HDD
SSD ofrece un rendimiento y una capacidad de procesamiento mucho mejores que HDD. Por lo tanto, siempre debes elegir SSD para obtener un mejor rendimiento, en especial en cargas de trabajo de producción.
Las operaciones de entrada y salida por segundo (IOPs) de lectura y escritura asignadas a la instancia dependen de la cantidad de almacenamiento asignado durante su creación. Cuanto mayor sea el tamaño del disco, mayores serán las IOPs de lectura y escritura. Por lo tanto, se recomienda crear instancias con un tamaño de datos mayor para obtener un mejor rendimiento de IOPs. En la siguiente captura de pantalla de la consola de Google Cloud, se muestra el resumen de los recursos (incluida la capacidad máxima) asignados a la instancia de base de datos en el momento de la creación, lo que ayuda a los usuarios a confirmar y comprender de forma exacta cómo su base de datos se configurará una vez creada la instancia.
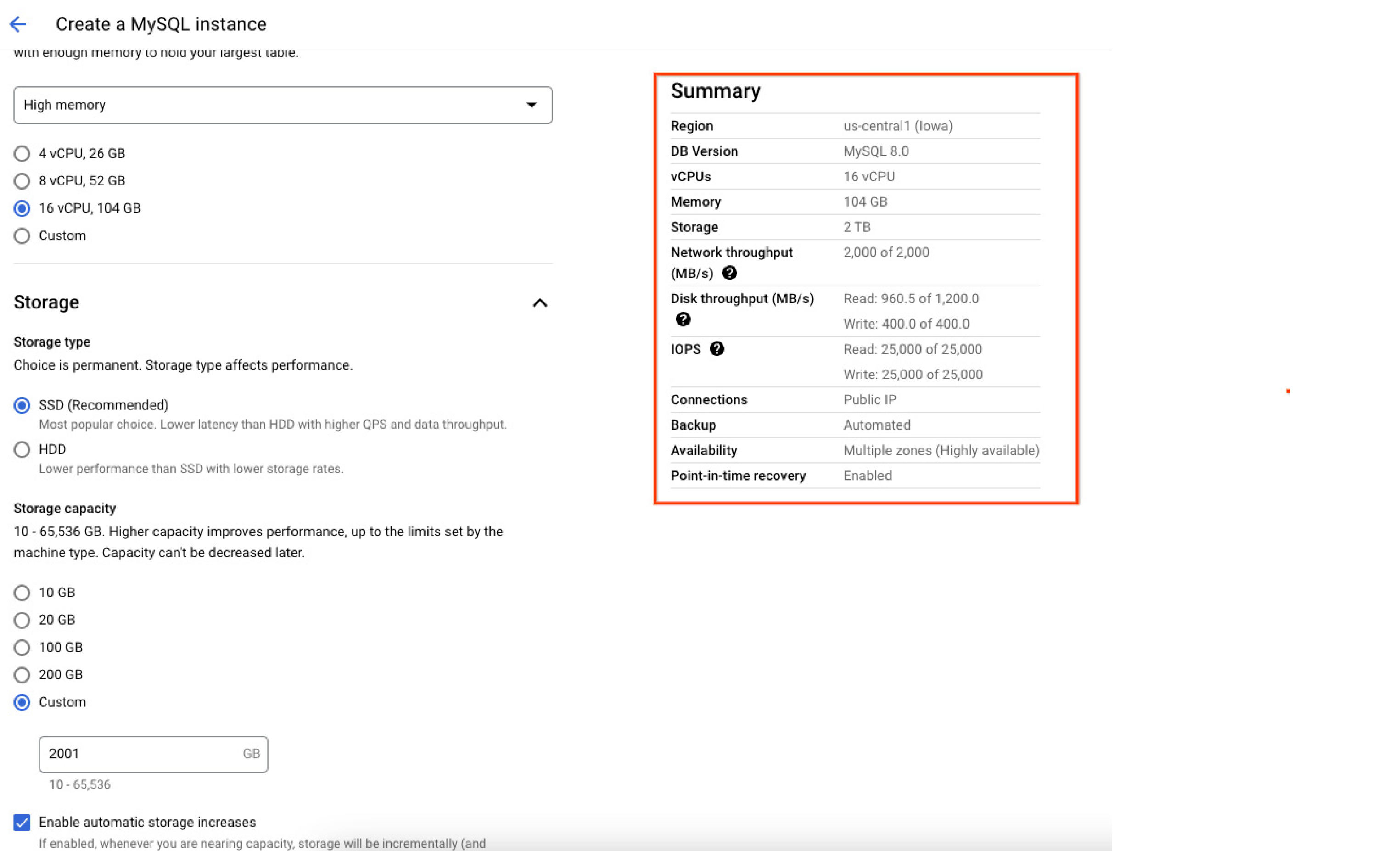
Región
Una de las formas de reducir la latencia de red es elegir la región de la instancia más cercana a la aplicación o el servicio. Cloud SQL para MySQL está disponible en todas las regiones de Google Cloud, lo que facilita que los usuarios creen instancias de bases de datos lo más cerca posible de los usuarios finales.
Escalamiento elástico
Cloud SQL ofrece una manera fácil de aumentar o reducir la escala verticalmente de los recursos (CPU, memoria o almacenamiento) asignados a una instancia de base de datos. Esto puede ser útil para las cargas de trabajo con distintos requisitos de recursos. Por ejemplo, los usuarios pueden aumentar (escalar verticalmente) los recursos durante el período de mayor requisito de carga de trabajo y, luego, reducir verticalmente la escala de los recursos cuando finaliza ese período.
Configuraciones de MySQL
En esta sección, se incluyen las prácticas recomendadas para la configuración de la base de datos de MySQL a fin de mejorar el rendimiento.
Versión
Elige la versión más reciente de MySQL cuando crees una base de datos nueva. Las versiones más recientes tienen correcciones de errores y optimizaciones para un mejor rendimiento en comparación con las versiones anteriores. Cloud SQL proporciona la última versión de MySQL disponible en el mercado y la convierte en la versión predeterminada cuando se crea una base de datos nueva. Obtén más información sobre las versiones de MySQL compatibles con Cloud SQL.
InnoDB Buffer pool size
El único motor de almacenamiento compatible con las instancias MySQL es InnoDB. El tamaño del grupo de búferes de Innodb es el primer parámetro que un usuario debería definir para un rendimiento óptimo. El grupo de búferes es el área de la memoria que se asigna a la caché de tablas de almacenamiento, la caché de índices, los datos modificados antes de la limpieza y otras estructuras internas como el índice de hash adaptable (AHI).
Cloud SQL define el valor predeterminado de alrededor del 72% de la memoria de instancia que se asignará al grupo de búferes de InnoDB, según el tamaño de la instancia (los valores predeterminados varían según el tamaño de la instancia). Obtén más detalles sobre la configuración del grupo de búferes en diferentes tamaños de instancias. Cloud SQL proporciona la flexibilidad de modificar el tamaño del grupo de búferes según las necesidades de la aplicación mediante marcas de base de datos.
El tamaño del grupo de búferes debe ser adecuado para que haya suficiente memoria libre disponible en la instancia para el búfer de sesión, la caché de diccionario y las tablas de performance_schema (si están habilitadas), además del grupo de búferes de InnoDB.
Los usuarios pueden verificar las lecturas de disco que se generan en la instancia para identificar la cantidad de datos que se leen desde los discos y compararlas con las que se completan en el grupo de búferes. Si hay más lecturas de disco, aumentar el tamaño del grupo de búferes y la memoria de la instancia mejoraría el rendimiento de las consultas de lectura.
Tamaño del archivo de registro de rehacer o InnoDB
El archivo de registro de InnoDB o de rehacer registra los cambios en los datos de la tabla. El tamaño del archivo de registro de InnoDB define el tamaño del archivo de registro de rehacer único.
Para las cargas de trabajo de escritura pesadas con un mayor tamaño de registro de rehacer, se ofrece más espacio para escrituras sin tener que realizar actividades de limpieza de puntos de control frecuentes y guardar E/S de disco, lo que mejora el rendimiento de escritura. El tamaño total del registro para rehacer, que se puede calcular como (innodb_log_file_size * innodb_log_file_size), debería ser suficiente para incluir al menos 1 o 2 horas de escritura de datos durante los períodos de gran actividad de acceso a la base de datos.
Cloud SQL define un valor predeterminado de 512 MB. Cloud SQL también ofrece la flexibilidad de aumentar el tamaño del archivo de registro de InnoDB mediante marcas de base de datos.
NOTA: Aumentar el valor del tamaño del archivo de registro de InnoDB aumenta el tiempo de recuperación ante fallas.
Durabilidad
El marcador innodb_flush_log_at_trx_commit controla la frecuencia con la que se vacían los datos de registro en el disco y si se deben limpiar para cada confirmación de transacción o no.
El rendimiento de escritura de las réplicas de lectura se puede aumentar si cambias los valores de innodb_flush_log_at_trx_commit a 0 o 2.
Cloud SQL no admite el cambio de la configuración de durabilidad en la instancia principal de Cloud SQL. Sin embargo, Cloud SQL sí permite cambiar la marca en las réplicas de lectura. Reducir la durabilidad de las réplicas de lectura mejora el rendimiento de las operaciones de escritura en las réplicas. Esto ayuda a abordar el retraso de la replicación en las réplicas. Obtén más información sobre innodb_flush_log_at_trx_commit.
Tamaño del búfer de registro de InnoDB
El tamaño del búfer de registro de InnoDB es la cantidad de búfer que usa InnoDB para escribir en el archivo de registro (registro de rehacer).
Si las transacciones (inserciones, actualizaciones o eliminaciones) en la base de datos son grandes y el búfer usado supera los 16 MB, entonces InnoDB debe realizar el E/S del disco antes de confirmar la transacción, lo que afecta el rendimiento. Para evitar el E/S de disco, aumenta el valor de innodb_log_buffer_size.
Cloud SQL define un valor predeterminado de 16 MB para el tamaño del búfer de registro de InnoDB. La variable de estado de MySQL innodb_log_waits muestra la cantidad de veces que innodb_log_buffer_size era pequeño y que InnoDB tuvo que esperar a que se hiciera la limpieza antes de confirmar la transacción. Si el valor de innodb_log_waits es mayor que 0 y aumenta, entonces aumenta el valor de innodb_log_buffer_size con marcas de base de datos para obtener un mejor rendimiento. El valor de innodb_log_buffer_size y de innodb_log_waits se puede identificar si ejecutas las siguientes consultas en la shell de MySQL (CLI). Estas consultas muestran el valor de las variables de estado y las variables globales en MySQL.
SHOW GLOBAL VARIABLES LIKE 'innodb_log_buffer_size';
SHOW GLOBAL STATUS LIKE 'innodb_log_waits';
Capacidad de E/S de InnoDB
La capacidad de E/S de InnoDB define la cantidad de IOPS disponibles para las tareas en segundo plano (como limpieza de páginas del grupo de búferes y combinación de datos del búfer de cambio).
Cloud SQL define los valores predeterminados de 5,000 para innodb_io_capacity y 10,000 para innodb_io_capacity.
Este valor predeterminado funciona mejor para la mayoría de las cargas de trabajo, pero si la carga de trabajo tiene mucha escritura o hay un alto número de cambios sin aplicar en la instancia y si tienes suficientes IOPS disponibles en la instancia, considera aumentar los valores de innodb_io_capacity y innodb_io_capacity. El valor de los cambios aplicados se puede encontrar con la siguiente consulta en la shell de MySQL:
mysql -e 'show engine InnoDB status \G;' | grep Ibuf
Búferes de sesión
Los búferes de sesión son la memoria asignada para las sesiones individuales. Si tu aplicación o tus consultas incluyen muchas inserciones, actualizaciones, clasificaciones y combinaciones, además necesitan búferes más altos, entonces definir valores de búfer altos mientras se ejecuta la consulta en una sesión en particular evita la sobrecarga de rendimiento. Los usuarios pueden evitar la asignación excesiva de búfer a nivel global, lo que aumenta los valores para todas las conexiones y, a su vez, aumenta el uso de memoria total de la instancia. Cambiar el valor predeterminado de los siguientes búferes ayuda a mejorar el rendimiento de las consultas. Estos valores se pueden cambiar mediante las marcas de base de datos.
Ten en cuenta que estos son valores de búfer por sesión. Aumentar los límites puede afectar a todas las conexiones y, finalmente, generar un aumento en el uso general de la memoria.
Table_open_cache y Table_definition_cache
Si tienes demasiadas (miles en exceso) tablas en la instancia de base de datos (en una o varias bases de datos), aumenta los valores de table_open_cache y table_open_cache para mejorar la velocidad de apertura de las tablas.
Table_definition_cache acelera la apertura de tablas y tiene una sola entrada por tabla. La caché de definición de tablas ocupa menos espacio y no usa descriptores de archivos. Si la cantidad de instancias de tablas en la caché de objetos del diccionario excede el límite de table_definition_cache, un mecanismo de LRU comienza a marcar las instancias de tablas para expulsión y, luego, las quita de la caché de objetos del diccionario a fin de dejar espacio para la nueva definición de tabla. Este proceso se realiza cada vez que se abre un nuevo espacio de tabla. Solo se cierran los espacios de tabla inactivos. Este proceso de expulsión ralentizaría la apertura de las tablas.
Table_open_cache define la cantidad de tablas abiertas para todos los subprocesos. Para verificar si necesitas aumentar la caché de tablas, consulta la variable de estado Opened_tables. Si el valor de Opened_tables es alto y no usas FLUSH TABLES con frecuencia, entonces considera aumentar el valor de la variable table_open_cache.
Table_open_cache y Table_open_cache se pueden configurar para la cantidad real de tablas en la instancia. Obtén más información sobre el recomendador high-number-of-open-tables de Cloud SQL.
Nota: Cloud SQL proporciona flexibilidad para cambiar estos valores.
Recomendaciones de esquema
Definir siempre las claves primarias
Cuando se definen las claves primarias en la tabla, se organizan físicamente los datos, de modo que se facilita la búsqueda, la recuperación y el ordenamiento de los registros y, por lo tanto, mejora el rendimiento.
En el caso de los sistemas OLTP, es preferible usar claves primarias con valores enteros que aumenten automáticamente.
La ausencia de claves primarias también es uno de los principales motivos del retraso o la lentitud de replicación en situaciones de replicación basadas en filas.
Crear índices
Crear índices ayuda a recuperar datos más rápido y, por lo tanto, mejora el rendimiento de las consultas de lectura. Crea índices para las columnas que se usan en las cláusulas WHERE, ORDER BY y GROUP BY de las consultas.
NOTA: Demasiados índices, o incluso sin usar, también pueden dificultar el rendimiento de la base de datos.
Prácticas recomendadas para la optimización del rendimiento
Ejecuta comparativas
Ejecuta pruebas de rendimiento o comparativas para ver si la configuración es óptima o se puede mejorar mediante el ajuste de la configuración del hardware, la base de datos de MySQL o el diseño de esquemas. Cambia un parámetro a la vez y revisa los resultados comparativos para ver si hay una mejora.
Agrupación de conexiones
La agrupación de conexiones es una técnica de creación y administración de un grupo de conexiones listas para usar en cualquier proceso que las necesite. La reducción de conexiones puede aumentar de forma considerable el rendimiento de tu aplicación y, al mismo tiempo, reducir el uso general de recursos. Revisa los detalles sobre cómo administrar las conexiones desde la aplicación, incluido el tiempo de espera y el recuento de conexiones.
Distribuye la carga de trabajo de lectura en réplicas de lectura
Se pueden usar réplicas de lectura (varias, en toda la zona) para descargar la carga de trabajo de lectura de la instancia principal. Esto reduce la sobrecarga o la carga en la instancia principal y, a su vez, mejora el rendimiento de la instancia principal. Además, hay más recursos disponibles para consultas de lectura en la réplica de lectura.
ProxySQL, un proxy de MySQL de código abierto y alto rendimiento capaz de enrutar consultas a la base de datos, se puede usar para escalar horizontalmente la base de datos de Cloud SQL para MySQL.
Evita las consultas de larga duración
Se sabe que las consultas que se ejecutan durante varios minutos o algunas horas degradan el rendimiento.
- Los registros de deshacer se usan para almacenar la versión anterior de las filas modificadas a fin de revertir la transacción y proporcionar la lectura coherente (instantánea de datos) en una transacción. Estos registros de deshacer se almacenan en forma de listas vinculadas con versiones recientes que apuntan a otras más antiguas, las que a su vez apuntan a otras más antiguas y así sucesivamente. Las transacciones de larga duración suelen retrasar la eliminación definitiva de los registros y, por lo tanto, aumentan la lista de estos registros. InnoDB debe atravesar el alto volumen de registros de deshacer y la lista vinculada larga, lo que reduce el rendimiento.
- Las consultas de larga duración también consumen recursos (como memoria, búferes y bloqueos), que no se liberan durante mucho tiempo y afectan a las demás consultas debido a la falta de recursos.
Evita las transacciones grandes
Demasiados cambios en los registros (actualización, eliminación, inserción) en una sola transacción retendrán los recursos (bloqueos, búfer) para demasiados registros. Es posible que desborde los búferes de registro que generan E/S de disco. Las consultas restantes deberán esperar a que se liberen los recursos o los bloqueos. Esto trae demasiados datos al grupo de búferes, lo que evita un uso mayor del grupo de búferes. La reversión de tales transacciones también degrada el rendimiento de la base de datos. Para solucionar este problema, se recomienda dividir las transacciones grandes en transacciones pequeñas y de ejecución más rápida.
Optimiza las consultas
Siempre optimiza las consultas para obtener los mejores resultados, es decir, con menos recursos y una ejecución más rápida. Revisa las recomendaciones para el ajuste de consultas de MySQL.
Herramientas para ajustar el rendimiento
Supervisión
Supervisión
Cloud SQL ofrece paneles predefinidos para varios productos de Google Cloud, incluido un panel de supervisión de Cloud SQL predeterminado. Los usuarios pueden usar este panel para supervisar el estado general de sus instancias principales y de réplica. Los usuarios también pueden crear sus propios paneles personalizados para mostrar las métricas que les interesen. Con estos paneles y métricas, se pueden identificar y abordar varios cuellos de botella de rendimiento, como el uso alto de CPU o de memoria, mediante las recomendaciones enumeradas anteriormente. Las alertas también se pueden configurar según estas métricas.
Marca de consultas lentas
Marca de consultas lentas
Se puede habilitar la marca de consultas lentas en la instancia de Cloud SQL para MySQL a fin de identificar las consultas que tardan más que long_query_time en ejecutarse. Estas consultas lentas se pueden analizar y ajustar aún más para mejorar el rendimiento. Obtén información sobre cómo habilitar y verificar las consultas lentas para las instancias de Cloud SQL.
Esquema de rendimiento
Esquema de rendimiento
El esquema de rendimiento proporciona una supervisión de bajo nivel de la instancia de MySQL. El esquema de rendimiento se puede habilitar en una instancia de Cloud SQL para MySQL con una memoria superior a 15 Gb. Los informes de esquema Sys proporcionan varios informes para identificar los cuellos de botella, las esperas, los índices faltantes, el uso de memoria, etcétera.
Estadísticas de consultas
Estadísticas de consultas
Las estadísticas de consultas son funciones nativas de Cloud SQL en las que se pueden generar perfiles de las consultas y analizarlas para mejorar su rendimiento. Las estadísticas de consultas admiten la supervisión intuitiva y proporcionan información de diagnóstico que te ayuda a ir más allá de la detección para identificar la causa raíz de los problemas de rendimiento.
Recomendaciones de rendimiento
Recomendaciones de rendimiento
El recomendador high-number-of-tables de Cloud SQL también es una función nativa de Cloud SQL que proporciona recomendaciones de rendimiento a los usuarios de Cloud SQL a fin de mejorar el rendimiento de las bases de datos existentes, proporcionar sugerencias para definir la configuración a fin de mejorar el rendimiento, y reducir el costo de las instancias. Consulta las recomendaciones de Cloud SQL para obtener más detalles.
Productos y servicios relacionados
Google Cloud ofrece una base de datos administrada de MySQL que se adapta a las necesidades de tu empresa, desde la eliminación de tu centro de datos local hasta la ejecución de aplicaciones SaaS y la migración de los sistemas empresariales principales.
Da el siguiente paso
Comienza a desarrollar en Google Cloud con el crédito gratis de $300 y los más de 20 productos del nivel Siempre gratuito.
¿Necesitas ayuda para comenzar?
Comunicarse con VentasTrabaja con un socio confiable
Buscar un socioSigue explorando
Ver todos los productos


















