Tipps zur Leistungsoptimierung für MySQL
Die Leistungsoptimierung ist ein wichtiger Aspekt bei der Verwaltung einer Datenbank. Die Leistungsoptimierung kann bei jedem Schritt der Datenbankverwaltung in Betracht gezogen werden, angefangen bei der Auswahl der Hardware- und Softwarekomponenten für das Hosting der Datenbankserver bis hin zum Datenmodelldesign und den Schemakonfigurationen. Dieses Dokument enthält Tipps zur Leistungsoptimierung für MySQL-Datenbanken in der Cloud, insbesondere Cloud SQL for MySQL, einschließlich Best Practices für die Instanziierung neuer Datenbanken und die Optimierung vorhandener Datenbanken.
Hinweise zur Hardware
Hardwarekonfigurationen sind ein wichtiger Faktor für die Datenbankleistung. Es ist wichtig, die Anzahl der aktiven und gleichzeitigen Nutzer einer Anwendung, die Größe der Datenbank und der Indexe sowie die erwartete Latenz Ihrer Anwendung oder Ihres Dienstes gut zu kennen, bevor Sie Hardwarekonfigurationen definieren. Im Folgenden finden Sie einige wichtige Hinweise zu Hardware:
Zentrale Verarbeitungseinheit (CPU)
Die Rechenleistung ist einer der wichtigsten Faktoren in einem leistungsfähigen Datenbanksystem. Die Anzahl der gleichzeitigen Verbindungen/Nutzer/Threads bestimmt die Anzahl der Kerne, die zum Verarbeiten von Datenbankanfragen erforderlich sind. Die der Datenbank zugewiesene CPU muss die normale Arbeitslast und die höchste (extreme) Arbeitslast bewältigen können, damit Anwendungen die bestmögliche Leistung erzielen.
Im Fall von Cloud SQL, dem vollständig verwalteten MySQL-Angebot von Google Cloud, wird die CPU in Form einer virtuellen CPU (vCPU) zugewiesen. Die Anzahl der vCPUs, die einer Datenbank zugewiesen sind, bestimmt den Umfang des Arbeitsspeichers und des Netzwerkdurchsatzes für eine Datenbankinstanz, da jeder vCPU ein maximaler Arbeitsspeicher zugeordnet ist und selbst der Netzwerkdurchsatz basierend auf der Anzahl der vCPUs variiert. Mit Cloud SQL können Sie die Anzahl der vCPUs für Ihre Instanz flexibel skalieren und so die Speicher- und Netzwerkdurchsatzanforderungen Ihrer Anwendung einfach erfüllen.
Arbeitsspeicher
Eine wichtige Überlegung, wie viel Arbeitsspeicher für eine Datenbank zugewiesen werden soll, besteht darin, sicherzustellen, dass der Arbeitssatz in den Pufferpool passt. Ein Arbeitssatz umfasst die Daten, die zu einem beliebigen Zeitpunkt aktiv von der Datenbank verwendet werden. Der zugewiesene Arbeitsspeicher sollte ausreichen, um diesen Arbeitssatz oder Daten, auf die häufig zugegriffen wird, zu speichern. Diese bestehen normalerweise aus Datenbankdaten, Indexen, Sitzungspuffern, Wörterbuch-Caches und Hashtabellen. Eine Möglichkeit, zu prüfen, ob genügend Arbeitsspeicher zugewiesen wurde, besteht darin, den Status der Laufwerklesevorgänge in der Datenbank zu prüfen. Im Idealfall sind die Laufwerklesevorgänge unter normalen Arbeitslasten wenig oder sehr gering.
Bei unzureichender Arbeitsspeicherzuordnung für die Instanz können Probleme mit nicht genügend Arbeitsspeicher auftreten, die dazu führen, dass die Datenbankinstanz neu gestartet wird und die Datenbank oder Anwendung Ausfallzeiten hat.
Speicher
Der Datenbankspeicher ist eine weitere Komponente, die bei der Leistungsoptimierung eine wichtige Rolle spielt. Cloud SQL bietet 2 Speichertypen
- SSD (Standard)
- HDD
SSD bietet deutlich bessere Leistung und höheren Durchsatz als HDD. Daher wählen Sie für eine bessere Leistung immer SSD, insbesondere für Produktionsarbeitslasten.
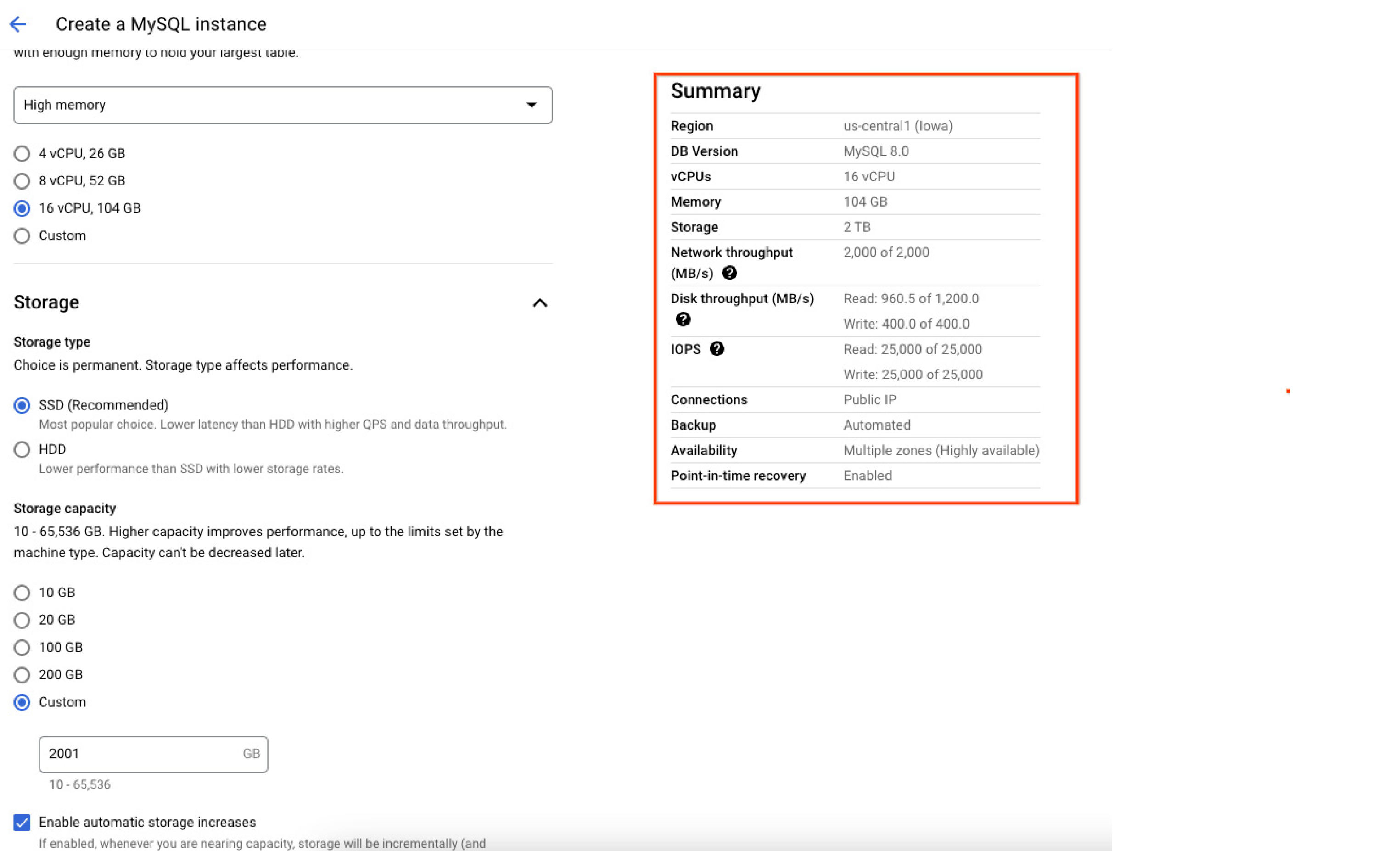
Lese-/Schreibvorgänge pro Sekunde (IOPS), die der Instanz zugewiesen sind, hängen von der Speichermenge ab, die beim Erstellen der Instanz zugewiesen wird. Je größer das Laufwerk, desto größer die Lese- und Schreib-IOPS. Daher ist es empfehlenswert, Instanzen mit einer höheren Datengröße zu erstellen, um die IOPs-Leistung zu verbessern. Der folgende Screenshot der Google Cloud Console zeigt die Zusammenfassung der Ressourcen (einschließlich der maximalen Kapazität), die der Datenbankinstanz zum Zeitpunkt der Erstellung zugewiesen wurden, damit Nutzer genau prüfen und nachvollziehen können, wie ihre Datenbank konfiguriert ist, sobald sie instanziiert wurde.
Region
Eine der Möglichkeiten, die Netzwerklatenz zu reduzieren, besteht darin, die Instanzregion auszuwählen, die der Anwendung oder dem Dienst am nächsten ist. Cloud SQL for MySQL ist in allen Google Cloud-Regionen verfügbar, sodass Nutzer eine Datenbank möglichst nah an den Endnutzern instanziieren können.
Elastische Skalierung
CloudSQL bietet eine einfache Möglichkeit zum Hoch- oder Herunterskalieren der Ressourcen (CPU, Arbeitsspeicher oder Speicher), die einer Datenbankinstanz zugewiesen sind. Dies kann für Arbeitslasten mit unterschiedlichen Ressourcenanforderungen nützlich sein. Nutzer können beispielsweise die Ressourcen während der erhöhten Arbeitslastanforderung vermehren (hochskalieren) und dann die Ressourcen herunterskalieren, wenn die Spitzenlast wieder vorbei ist.
MySQL-Konfigurationen
Dieser Abschnitt enthält Best Practices für MySQL-Datenbankkonfigurationen, um die Leistung zu verbessern.
Version
Wählen Sie die neueste MySQL-Version aus, wenn Sie eine neue Datenbank erstellen. Die neuesten Versionen enthalten Fehlerkorrekturen und Optimierungen, um eine bessere Leistung im Vergleich zu älteren Versionen zu erzielen. CloudSQL stellt die neueste auf dem Markt verfügbare MySQL-Version bereit und macht sie beim Erstellen einer neuen Datenbank zur Standardversion. Weitere Informationen zu von Cloud SQL unterstützten MySQL-Versionen
InnoDB Pufferpoolgröße
Für MySQL-Instanzen ist InnoDB die einzige unterstützte Speicher-Engine. Die Größe des InnoDB-Pufferpools ist der erste Parameter, den ein Nutzer für eine optimale Leistung definieren sollte. Der Pufferpool ist der Speicherbereich, der Tabellencaches, Indexcaches, geänderten Daten vor dem Leeren zugewiesen wird. Auch von anderen internen Strukturen wie der Adaptive Hash Index (AHI) wird der Pufferpool verwendet.
Cloud SQL definiert einen Standardwert von etwa 72 % des Instanzspeichers, der dem InnoDB-Pufferpool zugewiesen werden soll, je nach Größe der Instanz (Standardwerte variieren je nach Instanzgröße). Weitere Informationen zu Pufferpooleinstellungen für verschiedene Instanzgrößen Cloud SQL bietet die Möglichkeit, mithilfe von Datenbankflags die Größe des Pufferpools flexibel an die Anforderungen Ihrer Anwendungen anzupassen.
Der Pufferpool sollte so groß sein, dass der Instanz für das Zwischenspeichern von Sitzungen, den Wörterbuch-Cache und die Performance-Schematabellen (falls aktiviert) ausreichend viel freier Speicher außerhalb des InnoDB-Pufferpools zur Verfügung steht.
Nutzer können die von der Instanz ausgeführten Laufwerklesevorgänge prüfen, um festzustellen, wie viele Daten von Laufwerken gelesen werden und welche aus dem Zwischenspeicherpool. Wenn es mehr Laufwerklesevorgänge gibt, würde das Erhöhen der Pufferpoolgröße und des Instanzspeichers die Leistung von Leseabfragen verbessern.
Größe des Redo-Logs und InnoDB-Logs
InnoDB-Logdatei oder Redo-Log erfassen die Datenänderungen an den Tabellendaten. Die Größe der InnoDB-Logdatei definiert die Größe der einzelnen Redo-Logdatei.
Bei schreibintensiven Arbeitslasten mit einer höheren Redo-Loggröße ist mehr Platz für Schreibvorgänge verfügbar, ohne dass häufig Aktivitäten zur Prüfpunkt-Leerung und zum Speichern der Laufwerks-E/A ausgeführt werden müssen. Damit wird die Schreibleistung verbessert. Die Gesamtgröße des Redo-Logs, die als (innodb_log_file_size * innodb_log_file_size) berechnet werden kann, sollte ausreichen, um mindestens 1-2 Stunden Daten schreiben zu können, wenn der Datenbankzugriff ausgelastet ist.
Cloud SQL definiert einen Standardwert von 512 MB. Cloud SQL bietet außerdem die Flexibilität, die Größe der InnoDB-Logdatei mithilfe von Datenbankflags zu erhöhen.
HINWEIS: Wenn Sie den Wert der InnoDB-Logdatei vergrößern, erhöht sich die Absturzwiederherstellungszeit.
Langlebigkeit
Das Flag innodb_flush_log_at_trx_commit steuert, wie oft die Logdaten auf das Laufwerk geleert werden und ob es für jedes Transaktions-Commit geleert werden soll oder nicht.
Die Schreibleistung von Lesereplikaten kann erhöht werden, indem die Werte von innodb_flush_log_at_trx_commit auf 0 oder 2 geändert werden.
CloudSQL unterstützt nicht das Ändern der Langlebigkeitseinstellung in der CloudSQL-Primärinstanz. Cloud SQL lässt jedoch das Ändern des Flags für Lesereplikate zu. Die Reduzierung der Langlebigkeit von Lesereplikaten verbessert die Schreibleistung für die Replikate. Dies hilft bei der Behebung der Replikationsverzögerung bei den Replikaten. Weitere Informationen zu nnodb_flush_log_at_trx_commit.
Größe des Zwischenspeichers für InnoDB-Logs
Die Größe des Zwischenspeichers für InnoDB-Logs entspricht dem Umfang des Puffers, den InnoDB zum Schreiben in die Logdatei (Redo-Log) verwendet.
Wenn die Transaktionen (Einfügungen, Aktualisierungen oder Löschungen) in der Datenbank umfangreich sind und der verwendete Zwischenspeicher größer als 16 MB ist, muss die InnoDB Laufwerks-E/A ausführen, bevor ein Commit der Transaktion durchgeführt wird, der die Leistung betrifft. Erhöhen Sie den Wert von innodb_log_buffer_size, um Laufwerk-E/A-Vorgänge zu vermeiden.
CloudSQL definiert einen Standardwert von 16 MB für die Zwischenspeichergröße von InnoDB-Logs. Die MySQL-Statusvariable innodb_log_waits gibt an, wie oft innodb_log_buffer_size so klein war, dass InnoDB auf das Leeren warten musste, bevor der Commit der Transaktion ausgeführt werden konnte. Wenn der Wert für innodb_log_waits größer als 0 ist und ansteigt, dann erhöhen Sie den Wert von innodb_log_buffer_size mit Datenbankflags für eine bessere Leistung. Der Wert von innodb_log_buffer_size und innodb_log_waits kann durch Ausführen der folgenden Abfragen in der MySQL-Shell (CLI) ermittelt werden. Diese Abfragen zeigen den Wert von Statusvariablen und globalen Variablen in MySQL an.
GLOBAL VARIABLES LIKE 'innodb_log_buffer_size';
GLOBAL STATUS LIKE 'innodb_log_waits';
InnoDB-E/A-Kapazität
Die InnoDB-E/A-Kapazität definiert die Anzahl der verfügbaren IOPs für Hintergrundaufgaben (z. B. das Leeren von Seiten aus dem Pufferpool und das Zusammenführen von Daten aus dem Änderungspuffer).
Cloud SQL definiert einen Standardwert von 5.000 für innodb_io_capacity und 10.000 für innodb_io_capacity.
Diese Standardeinstellung funktioniert für die meisten Arbeitslasten am besten. Wenn Ihre Arbeitslast jedoch sehr schreiblastig oder nicht angewendete Änderungen auf der Instanz hoch sind, und wenn genügend IOPs auf der Instanz verfügbar sind, sollten Sie die innodb_io_capacity und innodb_io_capacity erhöhen. Der Wert der angewendeten Änderungen kann mit der folgenden Abfrage in MySQL-Shell ermittelt werden:
mysql -e 'show engine InnoDB status \G;' | grep Ibuf
Sitzungszwischenspeicher
Sitzungszwischenspeicher sind Arbeitsspeicher, die einzelnen Sitzungen zugewiesen sind. Wenn Ihre Anwendung oder Abfragen viele Einfügungen, Aktualisierungen, Sortierungen und Joins enthalten und höhere Zwischenspeicher erfordern, dann vermeiden Sie durch das Definieren hoher Zwischenspeicherwerte während der Ausführung der Abfrage in einer bestimmten Sitzung Leistungseinbußen. Nutzer können eine übermäßige Zwischenspeicherzuordnung auf globaler Ebene verhindern, die die Werte für alle Verbindungen und somit auch die Gesamtspeichernutzung der Instanz erhöht. Wenn Sie den Standardwert für die folgenden Zwischenspeicher ändern, können Sie die Abfrageleistung verbessern. Diese Werte können mithilfe von Datenbankflags geändert werden.
Beachten Sie, dass es sich um Werte pro Sitzungszwischenspeicher handelt. Eine Erhöhung der Limits kann sich auf alle Verbindungen auswirken und letztlich zu einer höheren Gesamtspeichernutzung führen.
Table_open_cache und Table_definition_cache
Wenn in der Datenbankinstanz zu viele (über Tausende) Tabellen vorhanden sind (in einer oder mehreren Datenbanken), erhöhen Sie die Werte von table_open_cache und table_open_cache, um Öffnen von Tabellen zu beschleunigen.
Table_definition_cache beschleunigt das Öffnen von Tabellen und hat nur einen Eintrag pro Tabelle. Der Tabellendefinitions-Cache benötigt weniger Speicherplatz und verwendet keine Dateideskriptoren. Wenn die Anzahl der Tabelleninstanzen im Wörterbuchobjekt-Cache den Grenzwert table_definition_cache überschreitet, beginnt ein LRU-Mechanismus mit der Kennzeichnung von Tabellentabellen für die Bereinigung und entfernt sie schließlich aus dem Cache des Wörterbuchobjekts, um Platz für die neue Tabellendefinition zu schaffen. Dieser Vorgang wird jedes Mal ausgeführt, wenn ein neuer Tablespace geöffnet wird. Nur inaktive Tablespaces sind geschlossen. Dieser Bereinigungsvorgang würde das Öffnen von Tabellen verlangsamen.
Table_open_cache definiert die Anzahl der geöffneten Tabellen für alle Threads. Sie können prüfen, ob der Tabellencache erhöht werden muss, indem Sie die Statusvariable Opened_tables prüfen. Wenn der Wert von Opened_tables groß ist und Sie FLUSH TABLES nicht oft verwenden, sollten Sie den Wert der Variablen table_open_cache erhöhen.
Table_open_cache und Table_open_cache können auf die tatsächliche Anzahl von Tabellen in der Instanz festgelegt werden. Weitere Informationen zum Recommender für die hohe Anzahl geöffneter Tabellen in Cloud SQL.
Hinweis: Cloud SQL bietet Flexibilität, um diese Werte zu ändern.
Schemaempfehlungen
Primärschlüssel immer definieren
Das Definieren von Primärschlüsseln für die Tabelle organisiert die Daten so, dass ein schnelleres Suchen, Abrufen und Sortieren der Datensätze ermöglicht wird und somit die Leistung verbessert wird.
Vorzugsweise automatisch erhöhte Primärschlüssel mit Ganzzahlwert sind für OLTP-Systeme ideal.
Das Fehlen von Primärschlüsseln ist auch einer der Hauptgründe für Replikationsverzögerungen oder Replikationverzögerungen in zeilenbasierten Replikationsszenarien.
Indexe erstellen
Durch das Erstellen von Indexen können Daten schneller abgerufen und die Leistung der Leseabfragen verbessert werden. Erstellen Sie Indexe für die Spalten, die in den Klauseln WHERE, ORDER BY und GROUP BY der Abfragen verwendet werden.
Hinweis: Zu viele oder nicht verwendete Indexe können die Leistung der Datenbank beeinträchtigen.
Best Practices für die Leistungsoptimierung
Benchmarks ausführen
Führen Sie Leistungstests oder Benchmarks durch, um festzustellen, ob die Konfiguration optimal ist oder noch verbessert werden kann, indem Sie Konfigurationen für Hardware, MySQL-Datenbank oder Schemadesign anpassen. Ändern Sie nur jeweils einen Parameter und vergleichen Sie die Ergebnisse mit Benchmarks, um festzustellen, ob sich die Leistung verbessert.
Verbindungs-Pooling
Verbindungs-Pooling ist eine Technik zum Erstellen und Verwalten eines Pools von Verbindungen, die von jedem Prozess verwendet werden können, der sie benötigt. Verbindungs-Pooling kann die Leistung Ihrer Anwendung erheblich steigern und gleichzeitig die Ressourcennutzung insgesamt reduzieren. Weitere Informationen zum Verwalten von Verbindungen über die Anwendung, einschließlich Anzahl der Verbindungen und Zeitlimit.
Lesearbeitslast auf Lesereplikate verteilen
Lesereplikate (mehrere, zonenübergreifend) können verwendet werden, um die Lesearbeitslast von der primären Instanz zu nehmen. Dies reduziert den Aufwand oder die Last auf der primären Instanz und verbessert so wiederum die Leistung der primären Instanz. Außerdem sind weitere Ressourcen für Leseabfragen auf dem Lesereplikat verfügbar.
ProxySQL, ein leistungsstarker Open-Source-MySQL-Proxy, der in der Lage ist, Datenbankabfragen weiterzuleiten, kann zur horizontalen Skalierung der Cloud SQL for MySQL-Datenbank verwendet werden.
Lange laufende Abfragen vermeiden
Abfragen, die mehrere Minuten oder Stunden ausgeführt werden, führen bekanntermaßen zu Leistungseinbußen.
- Undo-Logs werden verwendet, um die alte Version der geänderten Zeilen zu speichern, um ein Rollback für die Transaktion durchzuführen und um den konsistenten Lesevorgang (Snapshot der Daten) in einer Transaktion bereitzustellen. Diese Logs werden in Form verknüpfter Listen gespeichert, wobei aktuelle Versionen auf ältere Listen verweisen, die wiederum auf ältere Listen verweisen usw. Lang andauernde Transaktionen verzögern das dauerhafte Löschen der rückgängig gemachten Logs und vergrößern somit die Liste der rückgängig gemachten Logs. InnoDB muss eine große Menge an Undo-Logs und langen verknüpften Listen durchlaufen, wodurch die Leistung reduziert wird.
- Abfragen mit langer Ausführungszeit verbrauchen Ressourcen (wie Arbeitsspeicher, Zwischenspeicher und Sperren), die lange nicht freigegeben werden. Dies kann sich aufgrund eines Ressourcenmangels auch auf andere Abfragen auswirken.
Große Transaktionen vermeiden
Zu viele Datensatzänderungen (Aktualisieren, Löschen, Einfügen) in einer einzelnen Transaktion bindet Ressourcen (Sperren, Zwischenspeicher) für zu viele Datensätze. Es kann zu einem Überlauf der Log-Zwischenspeicher kommen, was zu Laufwerk-E/A-Vorgängen führt. Die verbleibenden Abfragen müssen „warten“, bis die Ressourcen oder die Sperren freigegeben werden. Dies führt dazu, dass zu viele Daten in den Pufferpool gebracht werden und eine anderweitige Verwendung des Pufferpools verhindert wird. Das Rollback solcher großen Transaktionen beeinträchtigt auch die Leistung der Datenbank. Es wird empfohlen, große Transaktionen in kleinere, schneller ausgeführte Transaktionen aufzuteilen.
Abfragen optimieren
Optimieren Sie die Abfragen für optimale Ergebnisse, d. h., reduzieren Sie Ressourcen und beschleunigen Sie die Ausführung. Lesen Sie die Empfehlungen zur MySQL-Feinabstimmung.
Tools zur Leistungsoptimierung
Monitoring
Monitoring
Cloud SQL bietet vordefinierte Dashboards für mehrere Google Cloud-Produkte, einschließlich eines standardmäßigen Cloud SQL Monitoring-Dashboards. Nutzer können mit diesem Dashboard den allgemeinen Zustand ihrer primären Instanzen und Replikatinstanzen überwachen. Nutzer können auch ihre eigenen benutzerdefinierten Dashboards erstellen, um für sie relevante Messwerte anzuzeigen. Mithilfe dieser Dashboards und Messwerte können Sie verschiedene Leistungsengpässe wie hohe CPU- oder hohe Speichernutzung mit den zuvor aufgeführten Empfehlungen identifizieren und beheben. Benachrichtigungen können auch anhand dieser Messwerte konfiguriert werden.
Langsames Abfrage-Flag
Langsames Abfrage-Flag
Das Flag Langsame Abfragen kann in der Cloud SQL for MySQL-Instanz aktiviert werden, um Abfragen zu identifizieren, deren Ausführung länger als long_query_time dauert. Diese langsamen Abfragen können weiter analysiert und optimiert werden, um die Leistung zu verbessern. Langsame Abfragen für Cloud SQL-Instanzen aktivieren und prüfen
Performance-Schema
Performance-Schema
Das Leistungsschema bietet eine einfache Überwachung der MySQL-Instanz. Das Leistungsschema kann in einer Cloud SQL for MySQL-Instanz mit einem Arbeitsspeicher von mehr als 15 GB aktiviert werden. Sys-Schema-Berichte enthalten verschiedene Berichte, um Engpässe, Wartezeiten, fehlende Indexe, Arbeitsspeichernutzung usw. zu identifizieren.
Query Insights
Query Insights
Query Insights ist ein natives Feature von Cloud SQL, mit dem Abfragen mithilfe von Profilen und Analysen die Leistung einer Abfrage verbessern können. Query Insights unterstützt die intuitive Überwachung und bietet Diagnoseinformationen, die mehr als reine Erkennung sind und auch die Ursache von Leistungsproblemen ermitteln.
Leistungsempfehlungen
Leistungsempfehlungen
Der Recommender für die hohe Anzahl von Tabellen in Cloud SQL ist ein natives Feature von Cloud SQL, das Leistungempfehlungen für Cloud SQL-Nutzer bietet, um eine verbesserte Leistung vorhandener Datenbanken zu erzielen, Definitionen der Konfiguration vorschlägt, um die Leistung zu verbessern und die Kosten der Instanzen zu senken. Weitere Informationen finden Sie in den Empfehlungen zu Cloud SQL.
Ähnliche Produkte und Dienste
Google Cloud bietet eine verwaltete MySQL-Datenbank, die auf Ihre geschäftlichen Anforderungen zugeschnitten ist – von der Stilllegung Ihres lokalen Rechenzentrums über die Ausführung von SaaS-Anwendungen bis hin zur Migration von Kerngeschäftssystemen.
Gleich loslegen
Profitieren Sie von einem Guthaben über 300 $, um Google Cloud und mehr als 20 „Immer kostenlos“ Produkte kennenzulernen.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partner arbeiten
Partner findenMehr ansehen
Alle Produkte ansehen


















