Ingress multi-cluster è un controller ospitato sul cloud per i cluster Google Kubernetes Engine (GKE). Si tratta di un servizio ospitato da Google che supporta il deployment di risorse di bilanciamento del carico condivise tra cluster e regioni. Per eseguire il deployment di Ingress multi-cluster su più cluster, completa la configurazione di Ingress multi-cluster, quindi consulta Deployment di Ingress su più cluster.
Per un confronto dettagliato tra Ingress multi-cluster (MCI), gateway multi-cluster (MCG) e bilanciatore del carico con gruppi di endpoint di rete autonomi (bilanciatore del carico e gruppi di endpoint di rete autonomi), consulta Scegliere l'API di bilanciamento del carico multi-cluster per GKE.
Networking multi-cluster
Molti fattori determinano le topologie multicluster, tra cui la vicinanza degli utenti per le app, l'alta disponibilità di cluster e regioni, la separazione organizzativa e di sicurezza, la migrazione dei cluster e la località dei dati. Questi casi d'uso sono raramente isolati. Man mano che i motivi per utilizzare più cluster aumentano, diventa più urgente la necessità di una piattaforma multicluster formale e commercializzata.
Ingress multi-cluster è progettato per soddisfare le esigenze di bilanciamento del carico di ambienti multi-cluster e multiregionali. È un controller per il bilanciatore del carico HTTP(S) esterno per fornire l'ingresso per il traffico proveniente da internet in uno o più cluster.
Il supporto multi-cluster di Ingress multi-cluster soddisfa molti casi d'uso, tra cui:
- Un unico IP virtuale (VIP) coerente per un'app, indipendentemente da dove viene implementata a livello globale.
- Disponibilità multiregionale e multicluster tramite il controllo dell'integrità e il failover del traffico.
- Routing basato sulla prossimità tramite VIP Anycast pubblici per una bassa latenza del client.
- Migrazione trasparente del cluster per upgrade o ricostruzioni del cluster.
Quote predefinite
Ingress multi-cluster ha le seguenti quote predefinite:
- Per informazioni dettagliate sui limiti dei membri per i parchi risorse, consulta le quote di gestione del parco risorse. per il numero di membri supportati in un parco risorse.
- 100 risorse
MultiClusterIngresse 100 risorseMultiClusterServiceper progetto. Puoi creare fino a 100 risorseMultiClusterIngresse 100 risorseMultiClusterServicein un cluster di configurazione per un numero qualsiasi di cluster di backend fino al massimo di cluster per progetto.
Prezzi e prove
Per informazioni sui prezzi di Ingress multi-cluster, consulta la sezione Prezzi di Ingress multi-cluster.
Come funziona Ingress multi-cluster
Ingress multi-cluster si basa sull'architettura del bilanciatore del carico delle applicazioni esterno globale. Il bilanciatore del carico delle applicazioni esterno globale è un bilanciatore del carico distribuito a livello globale con proxy di cui è stato eseguito il deployment in oltre 100 punti di presenza (PoP) di Google in tutto il mondo. Questi proxy, chiamati Google Front End (GFE), si trovano al limite della rete di Google, in una posizione vicina ai client. Ingress multi-cluster crea bilanciatori del carico delle applicazioni esterni nel livello Premium. Questi bilanciatori del carico utilizzano indirizzi IP esterni globali pubblicizzati tramite anycast. Le richieste vengono gestite dai GFE e dal cluster più vicino al client. Il traffico internet viene indirizzato al POP di Google più vicino e utilizza la rete backbone di Google per raggiungere un cluster GKE. Questa configurazione del bilanciamento del carico comporta una latenza inferiore dal client al GFE. Puoi anche ridurre la latenza tra i cluster GKE di serving e i GFE eseguendo i cluster GKE nelle regioni più vicine ai tuoi client.
L'interruzione delle connessioni HTTP e HTTPS perimetrali consente al bilanciatore del carico Google di decidere dove instradare il traffico determinando la disponibilità del backend prima che il traffico entri in un data center o in una regione. In questo modo, il traffico ha il percorso più efficiente dal client al backend, tenendo conto dell'integrità e della capacità dei backend.
Ingress multi-cluster è un controller Ingress che programma il bilanciatore del carico HTTP(S) esterno utilizzando i gruppi di endpoint di rete (NEG).
Quando crei una risorsa MultiClusterIngress, GKE esegue il deployment
delle risorse del bilanciatore del carico di Compute Engine e configura i pod appropriati nei cluster come backend. I NEG vengono utilizzati per monitorare dinamicamente gli endpoint dei pod, in modo che il bilanciatore del carico Google disponga del giusto insieme di backend integri.

Quando esegui il deployment delle applicazioni nei cluster in GKE, Ingress multi-cluster garantisce che il bilanciatore del carico sia sincronizzato con gli eventi che si verificano nel cluster:
- Viene creato un deployment con le etichette di corrispondenza corrette.
- Il processo di un pod termina e non supera il controllo di integrità.
- Un cluster viene rimosso dal pool di backend.
Ingress multi-cluster aggiorna il bilanciatore del carico, mantenendolo coerente con l'ambiente e lo stato desiderato delle risorse Kubernetes.
Architettura di Ingress multi-cluster
Ingress multi-cluster utilizza un server API Kubernetes centralizzato per eseguire il deployment di Ingress in più cluster. Questo server API centralizzato è chiamato cluster di configurazione. Qualsiasi
cluster GKE può fungere da cluster di configurazione. Il cluster di configurazione
utilizza due tipi di risorse personalizzate: MultiClusterIngress e MultiClusterService.
Se esegui il deployment di queste risorse sul cluster di configurazione, il controller Ingress multi-cluster
esegue il deployment dei bilanciatori del carico in più cluster.
I seguenti concetti e componenti costituiscono Ingress multi-cluster:
Controller Ingress multi-cluster: si tratta di un control plane distribuito a livello globale che viene eseguito come servizio al di fuori dei cluster. Ciò consente il ciclo di vita e le operazioni del controller di essere indipendenti dai cluster GKE.
Cluster di configurazione: si tratta di un cluster GKE scelto in esecuzione su Google Cloud dove vengono sottoposte a deployment le risorse
MultiClusterIngresseMultiClusterService. Si tratta di un punto di controllo centralizzato per queste risorse multi-cluster. Queste risorse multi-cluster esistono e sono accessibili da una singola API logica per mantenere la coerenza in tutti i cluster. Il controller Ingress monitora il cluster di configurazione e riconcilia l'infrastruttura di bilanciamento del carico.Un parco risorse consente di raggruppare e normalizzare logicamente i cluster GKE, semplificando l'amministrazione dell'infrastruttura e consentendo l'utilizzo di funzionalità multi-cluster come Ingress multi-cluster. Puoi scoprire di più sui vantaggi dei parchi risorse e su come crearli nella documentazione sulla gestione dei parchi risorse. Un cluster può essere membro di una sola flotta.
Cluster membro: i cluster registrati in un parco risorse sono chiamati cluster membro. I cluster membri del parco risorse comprendono l'intero ambito dei backend di cui Ingress multi-cluster è a conoscenza. La visualizzazione di gestione dei cluster Google Kubernetes Engine fornisce una console sicura per visualizzare lo stato di tutti i cluster registrati.

Flusso di lavoro di deployment
I seguenti passaggi illustrano un flusso di lavoro di alto livello per l'utilizzo di Ingress multi-cluster in più cluster.
Registra i cluster GKE in un parco risorse nel progetto che hai scelto.
Configura un cluster GKE come cluster di configurazione centrale. Questo cluster può essere un control plane dedicato o può eseguire altri carichi di lavoro.
Esegui il deployment delle applicazioni nei cluster GKE in cui devono essere eseguite.
Esegui il deployment di una o più risorse
MultiClusterServicenel cluster di configurazione con corrispondenze di etichette e cluster per selezionare cluster, spazi dei nomi e pod considerati backend per un determinato servizio. Vengono creati NEG in Compute Engine, che inizia a registrare e gestire gli endpoint di servizio.Esegui il deployment di una risorsa
MultiClusterIngressnel cluster di configurazione che fa riferimento a una o più risorseMultiClusterServicecome backend per il bilanciatore del carico. Vengono implementate le risorse del bilanciatore del carico esterno di Compute Engine e gli endpoint vengono esposti nei cluster tramite un singolo VIP del bilanciatore del carico.
Concetti di Ingress
Ingress multi-cluster utilizza un server API Kubernetes centralizzato per eseguire il deployment di Ingress su più cluster. Le sezioni seguenti descrivono il modello di risorsa Ingress multi-cluster, come eseguire il deployment di Ingress e i concetti importanti per la gestione di questo piano di controllo di rete a disponibilità elevata.
Risorse MultiClusterService
Un MultiClusterService è una risorsa personalizzata utilizzata da Ingress multi-cluster
per rappresentare la condivisione di servizi tra cluster. Una risorsa MultiClusterService
seleziona i pod, in modo simile alla risorsa Service, ma una
risorsa MultiClusterService può selezionare anche etichette e cluster. Il pool di cluster tra cui
MultiClusterService seleziona è chiamato cluster membri. Tutti i cluster registrati nel parco risorse sono cluster membri.
Un MultiClusterService esiste solo nel cluster di configurazione e non esegue il routing
come un servizio ClusterIP, LoadBalancer o NodePort. Consente invece al controller Ingress multi-cluster di fare riferimento a una singola risorsa distribuita.
Il seguente manifest di esempio descrive un MultiClusterService per un'applicazione denominata foo:
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: foo
namespace: blue
spec:
template:
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
Questo manifest esegue il deployment di un servizio in tutti i cluster membri con il selettore app:
foo. Se in quel cluster esistono pod app: foo, gli indirizzi IP dei pod vengono aggiunti come backend per MultiClusterIngress.
Il seguente mci-zone1-svc-j726y6p1lilewtu7 è un servizio derivato
generato in uno dei cluster di destinazione. Questo servizio crea un NEG che monitora
gli endpoint dei pod per tutti i pod che corrispondono al selettore di etichette specificato in questo
cluster. In ogni cluster di destinazione esisterà un servizio e un NEG derivati per ogni
MultiClusterService (a meno che non vengano utilizzati selettori di cluster). Se non esistono pod corrispondenti in un cluster di destinazione, il servizio e il NEG saranno vuoti. I servizi derivati
sono gestiti interamente da MultiClusterService e non direttamente dagli utenti.
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/neg: '{"exposed_ports":{"8080":{}}}'
cloud.google.com/neg-status: '{"network_endpoint_groups":{"8080":"k8s1-a6b112b6-default-mci-zone1-svc-j726y6p1lilewt-808-e86163b5"},"zones":["us-central1-a"]}'
networking.gke.io/multiclusterservice-parent: '{"Namespace":"default","Name":"zone1"}'
name: mci-zone1-svc-j726y6p1lilewtu7
namespace: blue
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
Alcune note sul servizio derivato:
- La sua funzione è quella di raggruppare logicamente gli endpoint come backend per Ingress multi-cluster.
- Gestisce il ciclo di vita del NEG per un determinato cluster e una determinata applicazione.
- Viene creato come servizio headless. Tieni presente che solo i campi
SelectorePortsvengono trasferiti daMultiClusterServiceal servizio derivato. - Il controller Ingress gestisce il proprio ciclo di vita.
Risorsa MultiClusterIngress
Una risorsa MultiClusterIngress si comporta in modo identico per molti aspetti alla risorsa Ingress di base. Entrambi hanno la stessa specifica per la definizione di host,
percorsi, terminazione del protocollo e backend.
Il seguente manifest descrive un MultiClusterIngress che indirizza il traffico ai backend foo e bar a seconda delle intestazioni host HTTP:
apiVersion: networking.gke.io/v1
kind: MultiClusterIngress
metadata:
name: foobar-ingress
namespace: blue
spec:
template:
spec:
backend:
serviceName: default-backend
servicePort: 80
rules:
- host: foo.example.com
backend:
serviceName: foo
servicePort: 80
- host: bar.example.com
backend:
serviceName: bar
servicePort: 80
Questa risorsa MultiClusterIngress corrisponde al traffico verso l'indirizzo IP virtuale su foo.example.com e bar.example.com inviando questo traffico alle risorse MultiClusterService denominate foo e bar. Questo MultiClusterIngress
ha un backend predefinito che corrisponde a tutto il resto del traffico e lo invia
al backend predefinito MultiClusterService.
Il seguente diagramma mostra il flusso di traffico da un Ingress a un cluster:

Nel diagramma sono presenti due cluster: gke-us e gke-eu. Il traffico
va da foo.example.com ai pod con l'etichetta app:foo in entrambi
i cluster. Da bar.example.com, il traffico viene indirizzato ai pod con l'etichetta
app:bar in entrambi i cluster.
Risorse Ingress in più cluster
Il cluster di configurazione è l'unico cluster che può avere risorse MultiClusterIngress e
MultiClusterService. Ogni cluster di destinazione con pod che corrispondono
ai selettori di etichette MultiClusterService ha anche un servizio derivato
corrispondente pianificato. Se un cluster non viene selezionato esplicitamente da un
MultiClusterService, in quel cluster non viene creato un servizio derivato corrispondente.

Uguaglianza dello spazio dei nomi
L'identicità dello spazio dei nomi è una proprietà dei cluster Kubernetes in cui uno spazio dei nomi si estende su più cluster ed è considerato lo stesso spazio dei nomi.
Nel seguente diagramma, lo spazio dei nomi blue esiste nei cluster GKE gke-cfg,
gke-eu e gke-us. L'identicità dello spazio dei nomi considera
lo spazio dei nomi blue come lo stesso in tutti i cluster. Ciò significa che un utente
ha gli stessi privilegi per le risorse nello spazio dei nomi blue in ogni cluster.
L'identicità dello spazio dei nomi significa anche che le risorse Service con lo stesso nome in più cluster nello spazio dei nomi blue sono considerate lo stesso servizio.
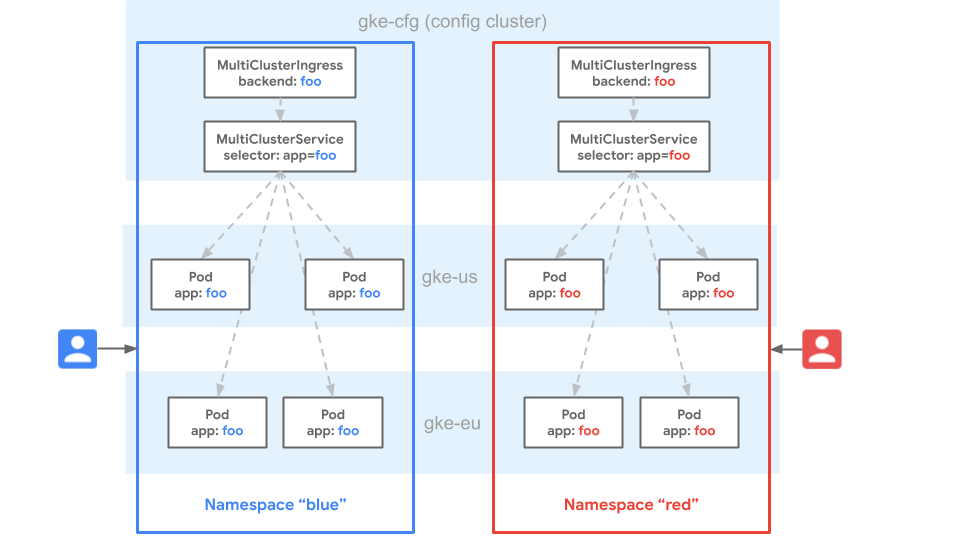
Il gateway considera il servizio come un unico pool di endpoint nei tre cluster. Poiché le risorse Route e MultiClusterIngress possono eseguire il routing solo ai servizi all'interno dello stesso spazio dei nomi, ciò fornisce un multitenancy coerente per la configurazione in tutti i cluster del parco risorse. I fleet offrono un elevato grado di portabilità, poiché le risorse possono essere implementate o spostate tra i cluster senza modifiche alla configurazione. Il deployment nello stesso spazio dei nomi del parco risorse garantisce
la coerenza tra i cluster.
Tieni presente i seguenti principi di progettazione per l'identità dello spazio dei nomi:
- Gli spazi dei nomi per scopi diversi non devono avere lo stesso nome nei cluster.
- Gli spazi dei nomi devono essere riservati in modo esplicito, allocando uno spazio dei nomi, o implicito, tramite criteri out-of-band, per i team e i cluster all'interno di un parco risorse.
- Gli spazi dei nomi con lo stesso scopo nei vari cluster devono condividere lo stesso nome.
- L'autorizzazione utente per gli spazi dei nomi nei cluster deve essere controllata rigidamente per impedire l'accesso non autorizzato.
- Non devi utilizzare lo spazio dei nomi predefinito o spazi dei nomi generici come "prod" o "dev" per il normale deployment delle applicazioni. È troppo facile per gli utenti eseguire il deployment delle risorse nello spazio dei nomi predefinito per errore e violare i principi di segmentazione degli spazi dei nomi.
- Lo stesso spazio dei nomi deve essere creato in tutti i cluster in cui un determinato team o gruppo di utenti deve eseguire il deployment delle risorse.
Configurazione della progettazione del cluster
Il cluster di configurazione Ingress multi-cluster è un singolo cluster GKE che ospita le risorse MultiClusterIngress e MultiClusterService e funge da punto di controllo unico per Ingress nell'intera flotta di cluster GKE di destinazione. Scegli il
cluster di configurazione quando abiliti Ingress multi-cluster. Puoi scegliere qualsiasi cluster GKE come cluster di configurazione e modificarlo in qualsiasi momento.
Configura la disponibilità del cluster
Poiché il cluster di configurazione è un unico punto di controllo, le risorse Ingress multi-cluster
non possono essere create o aggiornate se l'API del cluster di configurazione non è disponibile. I bilanciatori del carico e il traffico gestito da questi non saranno interessati da un'interruzione del cluster di configurazione, ma le modifiche alle risorse MultiClusterIngress e MultiClusterService non verranno riconciliate dal controller finché non sarà di nuovo disponibile.
Considera i seguenti principi di progettazione per i cluster di configurazione:
- Il cluster di configurazione deve essere scelto in modo che sia a disponibilità elevata. I cluster regionali sono preferibili ai cluster a livello di zona.
- Per abilitare Ingress multi-cluster, il cluster di configurazione non deve essere
un cluster dedicato. Il cluster di configurazione può ospitare carichi di lavoro amministrativi o persino
applicativi, anche se devi assicurarti che le applicazioni ospitate non
influenzino la disponibilità del server API del cluster di configurazione. Il cluster
di configurazione può essere un cluster di destinazione che ospita i backend per le risorse
MultiClusterServiceanche se, se sono necessarie precauzioni aggiuntive, il cluster di configurazione può anche essere escluso come backend tramite la selezione del cluster. - I cluster di configurazione devono avere tutti gli spazi dei nomi utilizzati dai backend dei cluster di destinazione. Una risorsa
MultiClusterServicepuò fare riferimento solo ai pod nello stesso spazio dei nomi nei cluster, quindi lo spazio dei nomi deve essere presente nel cluster di configurazione. - Gli utenti che eseguono il deployment di Ingress in più cluster devono avere accesso al cluster di configurazione per eseguire il deployment delle risorse
MultiClusterIngresseMultiClusterService. Tuttavia, gli utenti devono avere accesso solo agli spazi dei nomi che hanno l'autorizzazione a utilizzare.
Selezionare ed eseguire la migrazione del cluster di configurazione
Devi scegliere il cluster di configurazione quando abiliti Ingress multi-cluster. Qualsiasi cluster
membro di un parco risorse può essere selezionato come cluster di configurazione. Puoi aggiornare il cluster di configurazione in qualsiasi momento, ma devi fare attenzione a non causare interruzioni. Il controller Ingress riconcilierà le risorse esistenti nel cluster di configurazione. Quando esegui la migrazione del cluster di configurazione
da quello attuale a quello successivo, le risorse MultiClusterIngress e
MultiClusterService devono essere identiche.
Se le risorse non sono identiche, i bilanciatori del carico Compute Engine
potrebbero essere aggiornati o eliminati dopo l'aggiornamento del cluster di configurazione.
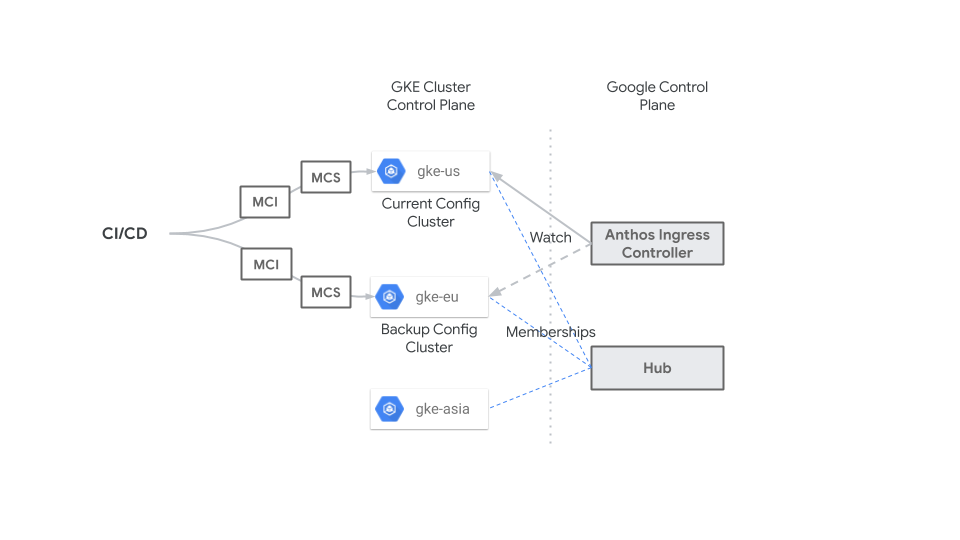
Il seguente diagramma mostra come un sistema CI/CD centralizzato applica le risorse MultiClusterIngress e MultiClusterService al server API GKE per il cluster di configurazione (gke-us) e un cluster di backup (gke-eu) in modo che le risorse siano identiche nei due cluster. Puoi modificare il cluster di configurazione per emergenze o
tempi di inattività pianificati in qualsiasi momento senza alcun impatto perché le risorse MultiClusterIngress
e MultiClusterService sono identiche.
Selezione del cluster
MultiClusterService risorse possono essere selezionate tra i cluster. Per impostazione predefinita, il
controller pianifica un servizio derivato su ogni cluster di destinazione. Se non vuoi un servizio derivato in ogni cluster di destinazione, puoi definire un elenco di cluster utilizzando il campo spec.clusters nel manifest MultiClusterService.
Potresti voler definire un elenco di cluster se devi:
- Isola il cluster di configurazione per impedire la selezione delle risorse
MultiClusterServicenel cluster di configurazione. - Controlla il traffico tra i cluster per la migrazione delle applicazioni.
- Esegui il routing ai backend delle applicazioni che esistono solo in un sottoinsieme di cluster.
- Utilizza un singolo indirizzo IP virtuale HTTP(S) per il routing ai backend che si trovano su cluster diversi.
Devi assicurarti che i cluster membri all'interno dello stesso parco risorse e della stessa regione abbiano nomi univoci per evitare conflitti di denominazione.
Per scoprire come configurare la selezione del cluster, consulta l'articolo Configurazione di Ingress multi-cluster.
Il seguente manifest descrive un MultiClusterService con un campo clusters che fa riferimento a europe-west1-c/gke-eu e asia-northeast1-a/gke-asia:
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: foo
namespace: blue
spec:
template:
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
clusters:
- link: "europe-west1-c/gke-eu"
- link: "asia-northeast1-a/gke-asia-1"
Questo manifest specifica che i pod con le etichette corrispondenti nei cluster gke-asia
e gke-eu possono essere inclusi come backend per MultiClusterIngress.
Tutti gli altri cluster vengono esclusi anche se hanno pod con l'etichetta app: foo.
Il seguente diagramma mostra un esempio di configurazione di MultiClusterService utilizzando
il manifest precedente:
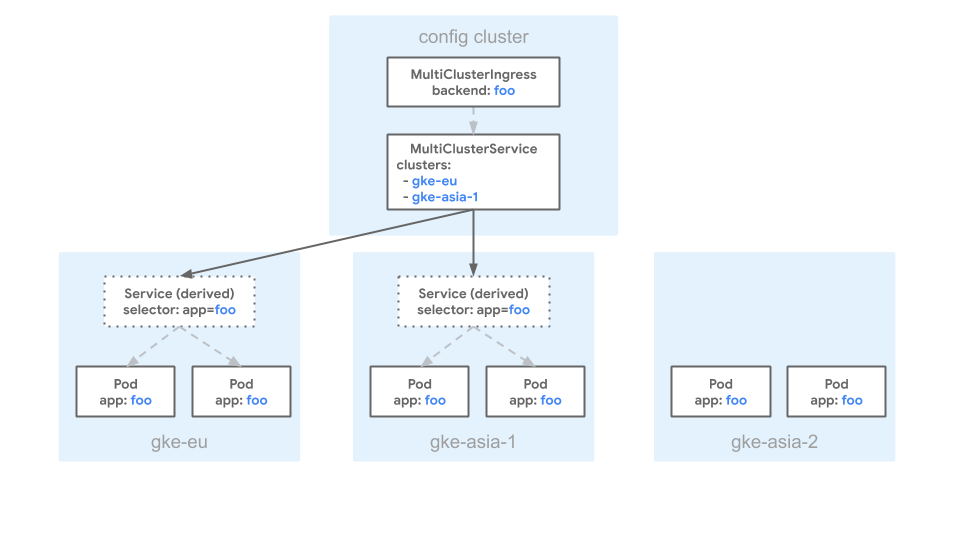
Nel diagramma sono presenti tre cluster: gke-eu, gke-asia-1 e
gke-asia-2. Il cluster gke-asia-2 non è incluso come backend, anche se
sono presenti pod con etichette corrispondenti, perché il cluster non è incluso nell'elenco
dei manifest spec.clusters. Il cluster non riceve traffico per
la manutenzione o altre operazioni.
Passaggi successivi
- Scopri come configurare Ingress multi-cluster.
- Scopri di più sul deployment di gateway multi-cluster.
- Scopri di più sull'implementazione di Ingress multi-cluster.
- Implementa Ingress multi-cluster per il bilanciamento del carico esterno.