Cloud Healthcare API
解锁医疗保健数据,为数据洞见和 AI 赋能
安全、合规的全代管式服务,用于注入、转换和存储 FHIR、HL7v2 和 DICOM 格式的医疗保健数据以及非结构化文本。

功能
与预构建的 AI 和机器学习工具集成
可扩缩的代管式服务
对开发者友好
服务
| API | 说明 |
|---|---|
创建、检索、存储和搜索 FHIR 格式的临床数据 | |
注入、创建、存储和搜索流式临床数据 | |
注入、检索和存储医学成像数据 | |
从非结构化医疗保健数据中提取医疗概念和关系并对其进行标准化 | |
在共享数据进行研究和分析时,对医疗保健数据进行去标识化处理,以满足合规性要求 | |
利用 Google 出色的生成式 AI 功能构建医疗保健解决方案 |
工作方式
凭借对医疗保健数据标准(例如 HL7® FHIR®、HL7® v2 和 DICOM®)的支持,Cloud Healthcare API 提供了一种可伸缩性很强的全代管式企业级开发环境,在 Google Cloud 上安全构建临床和分析解决方案。

常见用途
存储、管理和查询 FHIR 数据
将现有 FHIR 数据导入 Cloud Healthcare API
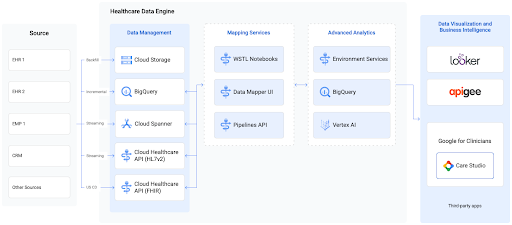
Healthcare Data Engine,由 Cloud Healthcare API 提供支持
使用 Google Cloud 的 Healthcare Data Engine 自动将各种医疗保健数据格式转换和协调到 FHIR,以创建纵向患者记录并加速应用开发、分析和 AI/机器学习工作流。
教程、快速入门和实验
将现有 FHIR 数据导入 Cloud Healthcare API
合作伙伴与集成
Healthcare Data Engine,由 Cloud Healthcare API 提供支持
使用 Google Cloud 的 Healthcare Data Engine 自动将各种医疗保健数据格式转换和协调到 FHIR,以创建纵向患者记录并加速应用开发、分析和 AI/机器学习工作流。
存储、管理和查看 DICOM 数据
注入、检索和存储医学成像数据
注入、检索和存储医学成像数据
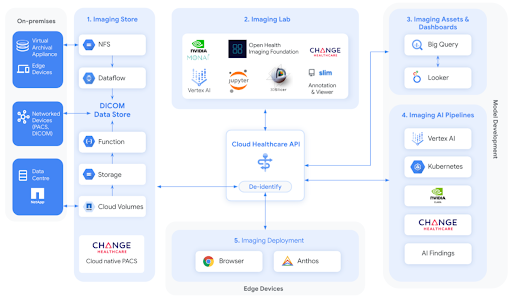
Medical Imaging Suite,由 Cloud Healthcare API 提供支持
教程、快速入门和实验
注入、检索和存储医学成像数据
注入、检索和存储医学成像数据
合作伙伴与集成
Medical Imaging Suite,由 Cloud Healthcare API 提供支持
从非结构化文本中获取数据洞见
Healthcare Natural Language API
Claims Acceleration Suite,由 Cloud Healthcare API 提供支持

教程、快速入门和实验
Healthcare Natural Language API
合作伙伴与集成
Claims Acceleration Suite,由 Cloud Healthcare API 提供支持
价格
| Cloud Healthcare API 定价方式 | Cloud Healthcare API 的价格取决于区域、服务和用量。下面显示了美国区域的价格。 | |
|---|---|---|
| 服务和用量 | 订阅类型 | 价格 (USD) |
数据存储 | 结构化存储 存储量为所提取数据的字节数加上索引开销(即编入索引的字节数)和备份字节数。 | Ranges from $0.19-$0.39 每月每 GB。前 1 GB 免费。 |
Blob 存储 Blob 存储费用按注入和存储的非结构化或 BLOB 字节数计算。 | Ranges from $0.003-$0.026 每月每 GB。前 1 GB 免费。 | |
请求量 | 标准请求 所有请求的默认值。 | Starting at $0.39 每月 100,000 个请求。前 25,000 个请求免费。 |
复杂请求 与标准请求相比,这一类型包含计算量较大的 API 请求。 | Starting at $0.69 每月 100,000 个请求。前 25,000 个请求免费。 | |
通知量 | 标准通知 通知是从数据存储区发送到 Google Cloud 或外部端点的流式事件。 | $0.29 每月每 100 万条通知。前 10 万条通知(每 100 万条)免费。 |
ETL 操作 | 批量导出 | Ranges from $0.09-$0.19 每月每 GB。 |
导出数据流 | Ranges from $0.24-$0.34 每月每 GB。 | |
去标识化操作 | 检查 检查自由文本或图片中有无敏感数据。 | Ranges from $0.10-$0.30 每千兆单位 (GU)。前 1 GU 免费。 |
转换 去标识化过程的一部分,包含对敏感数据的隐去、替换、哈希处理或更改。 | Ranges from $1-$3 每 GU。前 1 GU 免费。 | |
正在处理 涵盖操作的基本费用。结构化存储和 blob 存储的费用有所不同。 | Ranges from $0.05-$0.60 每 GB。前 1 GB 免费。 | |
Healthcare Natural Language API | 实体分析 Healthcare Natural Language API 的用量根据每月文本记录量计算得出。一条文本记录包含 1,000 个字符。 | Ranges from $0.03-$0.10 每 1 条文本记录。前 2500 条文本记录是免费的。 |
按区域、服务和用量查看完整价格详情。
Cloud Healthcare API 定价方式
Cloud Healthcare API 的价格取决于区域、服务和用量。下面显示了美国区域的价格。
结构化存储
存储量为所提取数据的字节数加上索引开销(即编入索引的字节数)和备份字节数。
Ranges from
$0.19-$0.39
每月每 GB。前 1 GB 免费。
Blob 存储
Blob 存储费用按注入和存储的非结构化或 BLOB 字节数计算。
Ranges from
$0.003-$0.026
每月每 GB。前 1 GB 免费。
标准请求
所有请求的默认值。
Starting at
$0.39
每月 100,000 个请求。前 25,000 个请求免费。
复杂请求
与标准请求相比,这一类型包含计算量较大的 API 请求。
Starting at
$0.69
每月 100,000 个请求。前 25,000 个请求免费。
标准通知
通知是从数据存储区发送到 Google Cloud 或外部端点的流式事件。
$0.29
每月每 100 万条通知。前 10 万条通知(每 100 万条)免费。
批量导出
Ranges from
$0.09-$0.19
每月每 GB。
导出数据流
Ranges from
$0.24-$0.34
每月每 GB。
检查
检查自由文本或图片中有无敏感数据。
Ranges from
$0.10-$0.30
每千兆单位 (GU)。前 1 GU 免费。
转换
去标识化过程的一部分,包含对敏感数据的隐去、替换、哈希处理或更改。
Ranges from
$1-$3
每 GU。前 1 GU 免费。
正在处理
涵盖操作的基本费用。结构化存储和 blob 存储的费用有所不同。
Ranges from
$0.05-$0.60
每 GB。前 1 GB 免费。
实体分析
Healthcare Natural Language API 的用量根据每月文本记录量计算得出。一条文本记录包含 1,000 个字符。
Ranges from
$0.03-$0.10
每 1 条文本记录。前 2500 条文本记录是免费的。
按区域、服务和用量查看完整价格详情。
业务用例
探索医疗保健与生命科学组织如何使用 Cloud Healthcare API




精选客户