教師なし学習とは
AI における教師なし学習は、人間の監督なしでデータから学習する機械学習の一種です。教師あり学習とは異なり、教師なし機械学習モデルにはラベルのないデータが与えられ、明示的なガイダンスや指示がなくてもパターンと分析情報を発見できます。
自覚しているかどうかにかかわらず、AI と機械学習は日常生活のあらゆる側面に影響を与えており、効率の向上、費用の削減、情報に基づくより良い意思決定を行うことができるインサイトにデータを変換するのに役立ちます。現在、企業は機械学習アルゴリズムを使用して、パーソナライズされた推奨事項やリアルタイム翻訳、さらにはテキストや画像などのコンテンツの自動生成を実現しています。
ここでは、教師なし機械学習の基本、その仕組み、一般的な実際の適用について説明します。
新規のお客様には、Gemini Enterprise Agent Platform や他の Google Cloud プロダクトをお試しいただける無料クレジット最大 $300 分を差し上げます。
教師なし学習の仕組み
名前が示すように、教師なし学習では自己学習アルゴリズムを使用します。ラベルや事前トレーニングなしで学習します。代わりに、モデルには未処理のラベルなしデータが与えられ、各データの処理方法に関する明示的な指示なしに、類似性、相違点、パターンに基づいて独自のルールを推論し、情報を構造化する必要があります。
教師なし学習アルゴリズムは、大規模なデータセットをクラスタに整理するなど、より複雑な処理タスクに適しています。データ内のこれまで検出されなかったパターンの特定に役立ち、データの分類に有用な特徴の特定に役立ちます。
天気に関する大規模なデータセットがあるとします。教師なし学習アルゴリズムは、データを処理してデータポイントのパターンを特定します。たとえば、気温や類似した気象パターンでデータをグループ化できます。
アルゴリズム自体は、提供された過去の情報に基づいてこれらのパターンを理解していませんが、ユーザーがデータグループを調べて、データセットの理解に基づいて分類を試みることができます。たとえば、さまざまな温度グループが四季すべてを表していることや、気象パターンが雨、みぞれ、雪などのさまざまな種類の天気に分かれていることを認識できるかもしれません。
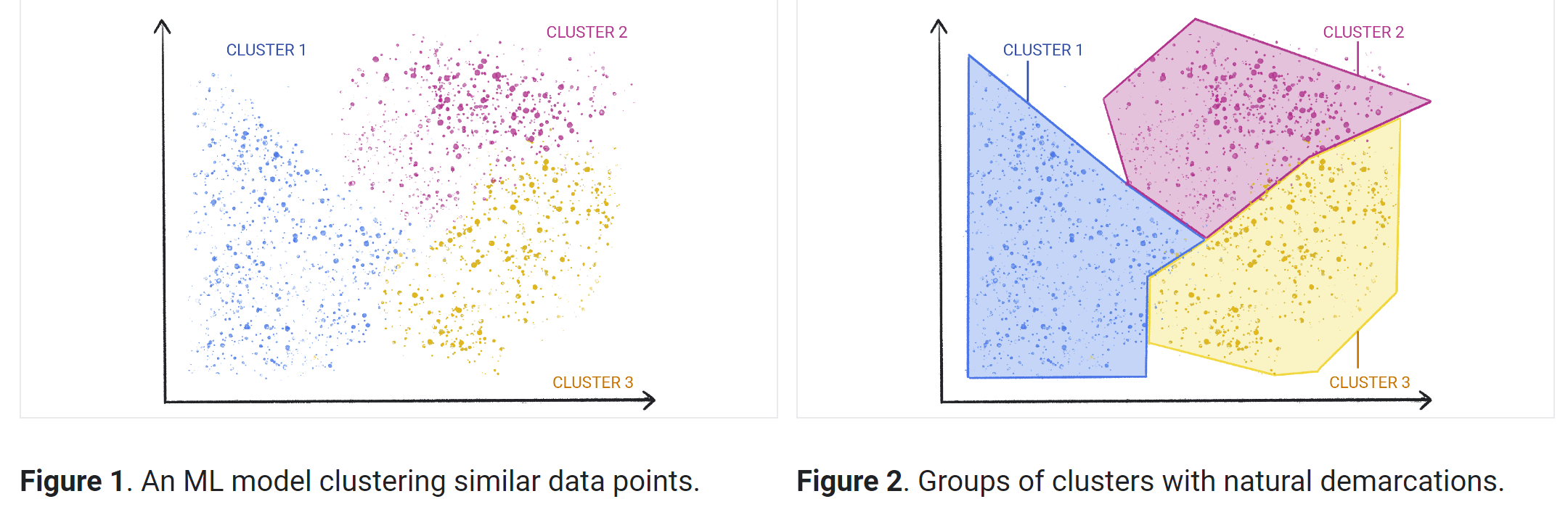
教師なし機械学習の手法
一般的に、教師なし学習タスクには、クラスタリング、アソシエーション ルール、項目削減の 3 つのタイプがあります。
以下では、教師なし学習手法の各タイプについて詳しく説明します。
クラスタリング
クラスタリングは、ラベルのない未加工のデータを探索し、類似点や相違点に基づいてグループ(またはクラスタ)に分割する手法です。顧客セグメンテーション、不正行為の検出、画像分析など、さまざまなアプリケーションで使用されています。クラスタリング アルゴリズムは、未分類のデータから類似した構造やパターンを見つけて、データを自然なグループに分割します。
クラスタリングは、最も一般的な教師なし機械学習アプローチの一つです。クラスタリングに使用される教師なし学習アルゴリズムには、排他的、重複、階層型、確率的など、いくつかの種類があります。
- 排他的クラスタリング: 1 つのデータポイントが 1 つのクラスタにのみ存在するようにデータをグループ化します。これは「ハード」クラスタリングとも呼ばれます。排他的クラスタリングの一般的な例は、K 平均法クラスタリング アルゴリズムです。このアルゴリズムは、データポイントをユーザー定義の K 個のクラスタに分割します。
- オーバーラップ クラスタリング: 1 つのデータポイントが、メンバーシップの程度が異なる 2 つ以上のクラスタに存在できる方法でデータがグループ化されます。これは「ソフト」クラスタリングとも呼ばれます。
- 階層型クラスタリング: 類似性に基づいてデータを個別のクラスタに分割し、階層関係に基づいて繰り返しマージして整理します。階層型クラスタリングには、主に凝集型クラスタリングと分割型クラスタリングの 2 種類があります。この手法は、HAC(階層的クラスタ分析)とも呼ばれます。
- 確率的クラスタリング: 各データポイントが各クラスタに属する確率に基づいて、データがクラスタにグループ化されます。このアプローチは、クラスタ内の他のデータポイントとの類似性に基づいてデータポイントをグループ化するほかの手法とは異なります。
関連付け
アソシエーション ルール マイニングは、ルールベースのアプローチで、大規模なデータセット内のデータポイント間の興味深い関係を明らかにします。教師なし学習アルゴリズムは、頻繁な「if-then」の関連付け(ルールとも呼ばれる)を検索して、データ内の相関関係と共起、およびデータオブジェクト間のさまざまな接続を検出します。
これは、特定のアイテムが一緒に購入される頻度を表すために、小売りのバスケットやトランザクションのデータセットを分析する際によく使用されます。これらのアルゴリズムは、顧客の購入パターンや以前は隠れていた商品間の関係を明らかにして、レコメンデーション エンジンやその他のクロスセルの機会の通知に活用できます。ルールについては、お気に入りのオンライン小売店の「よく一緒に購入されている商品」と「この商品を購入した人は他の人も買っている」のセクションに記載されていることでおなじみだと思います。
また、臨床診断のために医療データセットを整理する目的で、アソシエーション ルールが使用されることもよくあります。教師なし機械学習と関連付けルールを使用すると、医師は過去の患者の症状間の関係を比較することで、特定の診断の確率を特定できます。
通常、Apriori アルゴリズムが、関連するアイテムのコレクションまたはアイテムのセットを識別するための関連付けルール学習に最も広く使用されています。ただし、Eclat や FP-growth アルゴリズムなど、他のタイプも使用されます。
次元数の削減
次元削減は、データセット内の特徴(または次元)の数を減らす教師なし学習の手法です。一般的に、データが多いほど機械学習には役立ちますが、データの可視化はさらに難しくなります。
次元削減では、重要な特徴をデータセットから抽出して、無関係な特徴やランダムな特徴の数を減らします。この方法では、主成分分析(PCA)アルゴリズムと特異値分解(SVD)アルゴリズムを使用して、元データのプロパティの完全性を損なうことなく、データ入力の数を減らすことができます。
実際の教師なし学習の例
教師なし学習の仕組みの基本を理解したところで、企業が大量のデータを迅速に探索するのに役立つ、最も一般的なユースケースを見ていきましょう。
教師なし学習の実際の例をいくつかご紹介します。
- 異常検出: 教師なしクラスタリングは、大規模なデータセットを処理し、データセット内で異常なデータポイントを検出できます。
- レコメンデーション エンジン: 関連付けルールを使用すると、教師なし ML でトランザクション データを探索してパターンや傾向を発見し、オンライン小売店用のパーソナライズされたおすすめ情報を提供できるようになります。
- 顧客セグメンテーション: 教師なし学習は、顧客の共通の特徴や購入行動をクラスタ化することで、購入者のペルソナ プロファイルを生成する場合にもよく使用されます。これらのプロファイルは、マーケティングやその他のビジネス戦略の指針として使用できます。
- 不正行為の検出: 教師なし学習は異常検出に役立ち、データセット内の異常なデータポイントを明らかにします。これらの分析情報により、データ内の通常のパターンから逸脱したイベントや行動を明らかにし、不正なトランザクションやボット活動などの異常な行動を検出できます。
- 自然言語処理(NLP): 教師なし学習は、ニュース セクションの記事の分類、テキストの翻訳と分類、会話型インターフェースでの音声認識など、さまざまな NLP アプリケーションで一般的に使用されています。
- 遺伝子研究: 遺伝子クラスタリングも、教師なし学習の一般的な例です。階層型クラスタリング アルゴリズムは、DNA パターンを分析し、進化上の関係を明らかにするためによく使用されます。
教師なし学習は、大量のラベルなしデータを探索する必要があるタスクに適しています。このアプローチにより、企業はラベルが存在しない場合にデータから分析情報を簡単に得ることができ、人間が教えなくてもデータセットの基礎となる構造を理解し、データセット間のパターンと関係を特定できます。
教師あり学習と教師なし学習
教師あり学習と教師なし学習の主な違いは、使用する入力データの種類です。教師なし機械学習のアルゴリズムとは異なり、教師あり学習はラベル付きトレーニング データに基づいて、データセット内のパターン認識が正確かどうかを判断します。
教師あり学習モデルの目標も事前に決定されます。つまり、アルゴリズムを適用する前に、モデルの出力のタイプがすでにわかっています。つまり、トレーニング データに基づいて入力が出力にマッピングされます。
関連プロダクトとサービス
Google は、企業が機械学習のアルゴリズムやモデルを簡単に構築して実装できるように、革新的な AI と機械学習のプロダクト、ソリューション、アプリケーションを数多く提供しています。


開始にあたりサポートが必要な場合
お問い合わせ信頼できるパートナーと連携する
パートナーを探すもっと見る
すべてのプロダクトを見る


















