Datastream unterstützt das Streamen von Daten aus Oracle-, MySQL- und PostgreSQL-Datenbanken direkt in BigQuery-Datasets. Wenn Sie jedoch mehr Kontrolle über die Streamverarbeitungslogik benötigen, z. B. für die Datentransformation oder die manuelle Festlegung logischer Primärschlüssel, können Sie Datastream in Dataflow-Jobvorlagen einbinden.
In dieser Anleitung erfahren Sie, wie Datastream in Dataflow eingebunden wird. Dazu werden Dataflow-Jobvorlagen verwendet, um aktuelle materialisierte Ansichten in BigQuery für Analysen zu streamen.
Für Unternehmen mit vielen isolierten Datenquellen kann der Zugriff auf Unternehmensdaten im gesamten Unternehmen, insbesondere in Echtzeit, eingeschränkt und langsam sein. Dies schränkt die Fähigkeit der Organisation zur Selbstbeobachtung ein.
Datastream bietet nahezu in Echtzeit Zugriff auf Änderungsdaten aus verschiedenen lokalen und cloudbasierten Datenquellen. Datastream bietet eine Einrichtung, bei der Sie nicht viel für das Streamen von Daten konfigurieren müssen. Das übernimmt Datastream für Sie. Datastream bietet außerdem eine einheitliche Nutzungs-API, die den Zugriff auf die aktuellsten Daten im gesamten Unternehmen demokratisiert und integrierte Szenarien ermöglicht.
Ein solches Szenario ist die Übertragung von Daten aus einer Quelldatenbank in einen cloudbasierten Speicherdienst oder eine Messaging-Warteschlange. Nachdem Datastream die Daten gestreamt hat, werden sie in ein Format umgewandelt, das von anderen Anwendungen und Diensten gelesen werden kann. In dieser Anleitung ist Dataflow der Webdienst, der mit dem Speicherdienst oder der Messaging-Warteschlange kommuniziert, um Daten auf Google Cloudzu erfassen und zu verarbeiten.
Sie lernen, wie Sie mit Datastream Änderungen (eingefügte, aktualisierte oder gelöschte Daten) aus einer MySQL-Quelldatenbank in einen Ordner in einem Cloud Storage-Bucket streamen können. Anschließend konfigurieren Sie den Cloud Storage-Bucket so, dass er Benachrichtigungen sendet, mit denen Dataflow über neue Dateien mit Datenänderungen informiert wird, die Datastream aus der Quelldatenbank streamt. Ein Dataflow-Job verarbeitet dann die Dateien und überträgt die Änderungen in BigQuery.
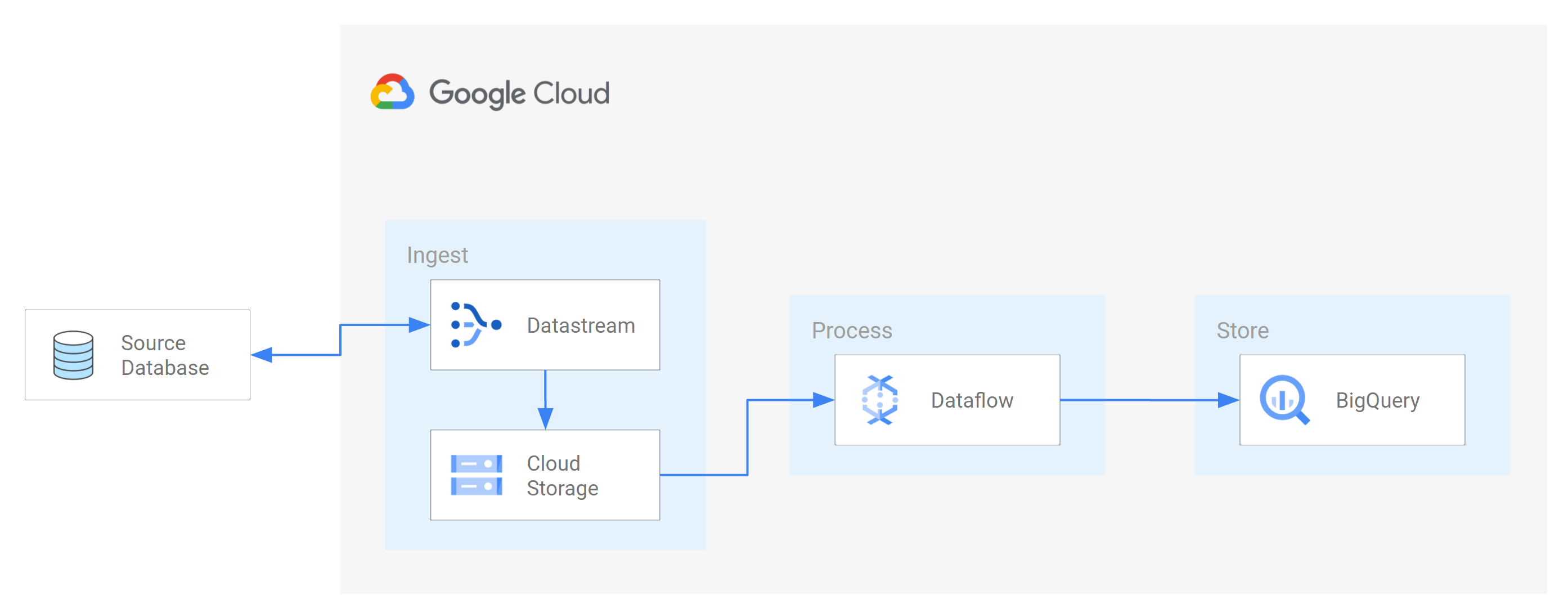
Ziele
In dieser Anleitung lernen Sie, wie Sie:- Erstellen Sie einen Bucket in Cloud Storage. Dies ist der Ziel-Bucket, in den Datastream Schemas, Tabellen und Daten aus einer MySQL-Quelldatenbank streamt.
- Pub/Sub-Benachrichtigungen für den Cloud Storage-Bucket aktivieren. Auf diese Weise konfigurieren Sie den Bucket so, dass er Benachrichtigungen sendet, mit denen Dataflow über neue Dateien informiert wird, die zur Verarbeitung bereitstehen. Diese Dateien enthalten Änderungen an Daten, die Datastream aus der Quelldatenbank in den Bucket streamt.
- Erstellen Sie Datasets in BigQuery. BigQuery verwendet Datasets, um die von Dataflow erhaltenen Daten zu speichern. Diese Daten stellen die Änderungen in der Quelldatenbank dar, die Datastream in den Cloud Storage-Bucket streamt.
- Erstellen und verwalten Sie Verbindungsprofile für eine Quelldatenbank und einen Ziel-Bucket in Cloud Storage. Ein Stream in Datastream verwendet die Informationen in den Verbindungsprofilen, um Daten aus der Quelldatenbank in den Bucket zu übertragen.
- Stream erstellen und starten. Dieser Stream überträgt Daten, Schemas und Tabellen aus der Quelldatenbank in den Bucket.
- Prüfen Sie, ob Datastream die mit einem Schema der Quelldatenbank verknüpften Daten und Tabellen in den Bucket überträgt.
- Job in Dataflow erstellen. Nachdem Datastream Datenänderungen aus der Quelldatenbank in den Cloud Storage-Bucket gestreamt hat, werden Benachrichtigungen über neue Dateien mit den Änderungen an Dataflow gesendet. Der Dataflow-Job verarbeitet die Dateien und überträgt die Änderungen in BigQuery.
- Dataflow muss die Dateien verarbeitet, die die mit diesen Daten verbundenen Änderungen enthalten, und die Änderungen in BigQuery übertragen. Deshalb haben Sie eine durchgängige Integration zwischen Datastream und BigQuery.
- Bereinigen Sie die Ressourcen, die Sie in Datastream, Cloud Storage, Pub/Sub, Dataflow und BigQuery erstellt haben, damit sie keine kostenpflichtigen Kontingente verbrauchen.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Datastream
- Cloud Storage
- Pub/Sub
- Dataflow
- BigQuery
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- Aktivieren Sie die Datastream API.
- Achten Sie darauf, dass Ihrem Nutzerkonto die Rolle „Datastream-Administrator“ zugewiesen ist.
- Sorgen Sie dafür, dass Sie eine MySQL-Quelldatenbank haben, auf die Datastream zugreifen kann. Prüfen Sie außerdem, ob die Datenbank Daten, Tabellen und Schemas enthält.
- Konfigurieren Sie Ihre MySQL-Datenbank so, dass eingehende Verbindungen von öffentlichen Datastream-IP-Adressen zugelassen werden. Eine Liste aller Datastream-Regionen und der zugehörigen öffentlichen IP-Adressen finden Sie unter IP-Zulassungslisten und Regionen.
- Richten Sie Change Data Capture (CDC) für die Quelldatenbank ein. Weitere Informationen finden Sie unter MySQL-Quelldatenbank konfigurieren.
Achten Sie darauf, dass alle Voraussetzungen erfüllt sind, um Pub/Sub-Benachrichtigungen für Cloud Storage zu aktivieren.
In dieser Anleitung erstellen Sie einen Ziel-Bucket in Cloud Storage und aktivieren Pub/Sub-Benachrichtigungen für den Bucket. Auf diese Weise kann Dataflow Benachrichtigungen über neue Dateien erhalten, die Datastream in den Bucket schreibt. Diese Dateien enthalten Änderungen an Daten, die Datastream aus der Quelldatenbank in den Bucket streamt.
Voraussetzungen
Datastream bietet eine Vielzahl von Quelloptionen, Zieloptionen und Netzwerkverbindungsmethoden.
Für diese Anleitung gehen wir davon aus, dass Sie eine eigenständige MySQL-Datenbank und einen Cloud Storage-Zieldienst verwenden. Für die Quelldatenbank sollten Sie Ihr Netzwerk so konfigurieren können, dass eine eingehende Firewallregel hinzugefügt wird. Die Quelldatenbank kann lokal oder bei einem Cloudanbieter bereitgestellt werden. Für das Cloud Storage-Ziel ist keine Verbindungskonfiguration erforderlich.
Da wir die Besonderheiten Ihrer Umgebung nicht kennen, können wir keine detaillierten Schritte in Bezug auf Ihre Netzwerkkonfiguration anbieten.
In dieser Anleitung wählen Sie als Methode zur Netzwerkverbindung die Option Zulassungsliste für IP-Adressen aus. IP-Zulassungslisten sind eine Sicherheitsfunktion, mit der der Zugriff auf die Daten in Ihrer Quelldatenbank häufig auf vertrauenswürdige Nutzer beschränkt und gesteuert wird. Sie können IP-Zulassungslisten verwenden, um Listen mit vertrauenswürdigen IP-Adressen oder IP-Bereichen zu erstellen, von denen Ihre Nutzer und andere Google Cloud -Dienste wie Datastream auf diese Daten zugreifen können. Damit Sie IP-Zulassungslisten verwenden können, müssen Sie die Quelldatenbank oder Firewall für eingehende Verbindungen von Datastream öffnen.
Erstellen Sie einen Bucket in Cloud Storage
Erstellen Sie einen Ziel-Bucket in Cloud Storage, in den Datastream Schemas, Tabellen und Daten aus einer MySQL-Quelldatenbank streamt.
Wechseln Sie in der Google Cloud Console zur Seite Browser für Cloud Storage.
Klicken Sie auf Bucket erstellen. Die Seite Bucket erstellen wird angezeigt.
Geben Sie im Textfeld des Bereichs Bucket benennen einen eindeutigen Namen für Ihren Bucket ein und klicken Sie dann auf Weiter.
Übernehmen Sie für jede verbleibende Region der Seite die Standardeinstellungen. Klicken Sie am Ende jeder Region auf Weiter.
Klicken Sie auf Erstellen.
Pub/Sub-Benachrichtigungen für den Cloud Storage-Bucket aktivieren
In diesem Abschnitt aktivieren Sie Pub/Sub-Benachrichtigungen für den von Ihnen erstellten Cloud Storage-Bucket. Auf diese Weise konfigurieren Sie den Bucket so, dass Dataflow über alle neuen Dateien informiert wird, die Datastream in den Bucket schreibt. Diese Dateien enthalten Änderungen an Daten, die Datastream aus einer MySQL-Quelldatenbank in den Bucket streamt.
Rufen Sie den von Ihnen erstellten Cloud Storage-Bucket auf. Die Seite Bucket-Details wird angezeigt.
Klicken Sie auf Cloud Shell aktivieren.
Geben Sie bei der Eingabeaufforderung folgenden Befehl ein:
gcloud storage buckets notifications create gs://bucket-name --topic=my_integration_notifs --payload-format=json --object-prefix=integration/tutorial/Optional: Wenn das Fenster Cloud Shell autorisieren angezeigt wird, klicken Sie auf Autorisieren.
Prüfen Sie, ob die folgenden Codezeilen angezeigt werden:
Created Cloud Pub/Sub topic projects/project-name/topics/my_integration_notifs Created notification config projects/_/buckets/bucket-name/notificationConfigs/1
Rufen Sie in der Google Cloud Console die Seite Themen für Pub/Sub auf.
Klicken Sie auf das Thema my_integration_notifs, das Sie erstellt haben.
Scrollen Sie auf der Seite my_integration_notifs nach unten. Prüfe, ob der Tab Abos aktiv ist und die Meldung Keine Abos vorhanden angezeigt wird.
Klicken Sie auf Abo erstellen.
Wählen Sie im angezeigten Menü Abo erstellen aus.
Führen Sie auf der Seite Abo zum Thema hinzufügen die folgenden Schritte aus:
- Geben Sie im Feld Abo-ID den Wert
my_integration_notifs_subein. - Legen Sie den Wert für Bestätigungsfrist auf
120Sekunden fest. So hat Dataflow genügend Zeit, die verarbeiteten Dateien zu bestätigen, und die Gesamtleistung des Dataflow-Jobs wird verbessert. Weitere Informationen zu Pub/Sub-Abo-Attributen finden Sie unter Abo-Attribute. - Übernehmen Sie alle anderen Standardwerte auf der Seite.
- Klicken Sie auf Erstellen.
- Geben Sie im Feld Abo-ID den Wert
Später in dieser Anleitung erstellen Sie einen Dataflow-Job. Bei der Erstellung dieses Jobs weisen Sie Dataflow zu, Abonnent des Abos my_integration_notifs_sub zu sein. Auf diese Weise kann Dataflow Benachrichtigungen über neue Dateien erhalten, die Datastream in den Cloud Storage schreibt, die Dateien verarbeiten und die Datenänderungen in BigQuery übertragen.
Datasets in BigQuery erstellen
In diesem Abschnitt erstellen Sie Datasets in BigQuery. BigQuery verwendet Datasets, um die von Dataflow erhaltenen Daten zu speichern. Diese Daten stellen die Änderungen in der MySQL-Quelldatenbank dar, die Datastream in Ihren Cloud Storage-Bucket streamt.
Rufen Sie in der Google Cloud -Console die Seite SQL-Arbeitsbereich für BigQuery auf.
Klicken Sie im Bereich Explorer neben dem Namen Ihres Google Cloud Projekts auf Aktionen ansehen.
Wählen Sie im angezeigten Menü Dataset erstellen aus.
Gehen Sie im Fenster Dataset erstellen so vor:
- Geben Sie im Feld Dataset-ID eine ID für das Dataset ein. Geben Sie für diese Anleitung
My_integration_dataset_login das Feld ein. - Lassen Sie alle anderen Standardwerte im Fenster stehen.
- Klicken Sie auf Dataset erstellen.
- Geben Sie im Feld Dataset-ID eine ID für das Dataset ein. Geben Sie für diese Anleitung
Klicken Sie im Bereich Explorer neben Ihrem Projektnamen Google Cloud auf Knoten maximieren und prüfen Sie, ob das von Ihnen erstellte Dataset angezeigt wird.
Führen Sie die Schritte in dieser Anleitung aus, um ein zweites Dataset zu erstellen: My_integration_dataset_final.
Maximieren Sie neben jedem Dataset Knoten maximieren.
Prüfen Sie, ob jedes Dataset leer ist.
Nachdem Datastream Datenänderungen aus der Quelldatenbank in Ihren Cloud Storage-Bucket gestreamt hat, verarbeitet ein Dataflow-Job die Dateien mit den Änderungen und überträgt sie in die BigQuery-Datasets.
Verbindungsprofile in Datastream erstellen
In diesem Abschnitt erstellen Sie in Datastream Verbindungsprofile für eine Quelldatenbank und ein Ziel. Bei der Erstellung der Verbindungsprofile wählen Sie MySQL als Profiltyp für Ihr Quellverbindungsprofil und Cloud Storage als Profiltyp für Ihr Zielverbindungsprofil.
Datastream verwendet die in den Verbindungsprofilen definierten Informationen, um eine Verbindung sowohl zur Quelle als auch zum Ziel herzustellen, damit Daten aus der Quelldatenbank in Ihren Ziel-Bucket in Cloud Storage gestreamt werden können.
Quellverbindungsprofil für Ihre MySQL-Datenbank erstellen
Rufen Sie in der Google Cloud Console die Seite Verbindungsprofile für Datastream auf.
Klicken Sie auf Profil erstellen.
Wenn Sie ein Quellverbindungsprofil für Ihre MySQL-Datenbank erstellen möchten, klicken Sie auf der Seite Verbindungsprofil erstellen auf den Profiltyp MySQL.
Geben Sie auf der Seite MySQL-Profil erstellen im Abschnitt Verbindungseinstellungen definieren die folgenden Informationen an:
- Geben Sie im Feld Name des Verbindungsprofils
My Source Connection Profileein. - Behalten Sie die automatisch generierte Verbindungsprofil-ID bei.
Wählen Sie die Region aus, in der Sie das Verbindungsprofil speichern möchten.
Geben Sie Verbindungsdetails ein:
- Geben Sie im Feld Hostname oder IP-Adresse einen Hostnamen oder eine öffentliche IP-Adresse ein, mit dem Datastream eine Verbindung zur Quelldatenbank herstellen kann. Sie stellen eine öffentliche IP-Adresse bereit, da Sie die IP-Zulassungsliste als Methode zur Netzwerkverbindung für diese Anleitung verwenden.
- Geben Sie in das Feld Port die Portnummer ein, die für die Quelldatenbank reserviert ist. Bei einer MySQL-Datenbank ist der Standardport normalerweise
3306. - Geben Sie einen Nutzernamen und ein Passwort ein, um sich bei Ihrer Quelldatenbank zu authentifizieren.
- Geben Sie im Feld Name des Verbindungsprofils
Klicken Sie im Abschnitt Verbindungseinstellungen definieren auf Weiter. Der Abschnitt Verbindung mit Ihrer Quelle sichern auf der Seite MySQL-Profil erstellen ist aktiv.
Wählen Sie im Menü Verschlüsselungstyp die Option Keine aus. Weitere Informationen zu diesem Menü finden Sie unter Verbindungsprofil für MySQL-Datenbank erstellen.
Klicken Sie im Abschnitt Verbindung mit der Quelle sichern auf Weiter. Der Abschnitt Verbindungsmethode festlegen auf der Seite MySQL-Profil erstellen ist aktiv.
Wählen Sie im Drop-down-Menü Verbindungsmethode die Netzwerkmethode aus, die Sie zum Herstellen einer Verbindung zwischen Datastream und der Quelldatenbank verwenden möchten. Wählen Sie für diese Anleitung IP-Zulassungsliste als Verbindungsmethode aus.
Konfigurieren Sie die Quelldatenbank so, dass eingehende Verbindungen von den öffentlichen Datastream-IP-Adressen zugelassen werden.
Klicken Sie im Abschnitt Verbindungsmethode festlegen auf Weiter. Der Abschnitt Verbindungsprofil testen auf der Seite MySQL-Profil erstellen ist aktiv.
Klicken Sie auf Testen, um zu prüfen, ob die Quelldatenbank und Datastream miteinander kommunizieren können.
Prüfen Sie, ob der Status Test bestanden angezeigt wird.
Klicken Sie auf Erstellen.
Zielverbindungsprofil für Cloud Storage erstellen
Rufen Sie in der Google Cloud Console die Seite Verbindungsprofile für Datastream auf.
Klicken Sie auf Profil erstellen.
Wenn Sie ein Zielverbindungsprofil für Cloud Storage erstellen möchten, klicken Sie auf der Seite Verbindungsprofil erstellen auf den Profiltyp Cloud Storage.
Geben Sie auf der Seite Cloud Storage-Profil erstellen die folgenden Informationen an:
- Geben Sie im Feld Name des Verbindungsprofils
My Destination Connection Profileein. - Behalten Sie die automatisch generierte Verbindungsprofil-ID bei.
- Wählen Sie die Region aus, in der Sie das Verbindungsprofil speichern möchten.
Klicken Sie im Bereich Verbindungsdetails auf Durchsuchen, um den Cloud Storage-Bucket auszuwählen, den Sie zuvor in dieser Anleitung erstellt haben. Dies ist der Bucket, in den Datastream Daten aus der Quelldatenbank überträgt. Klicken Sie nach der Auswahl auf Auswählen.
Ihr Bucket wird im Feld Bucket-Name des Bereichs Verbindungsdetails angezeigt.
Geben Sie im Feld Pfadpräfix für das Verbindungsprofil ein Präfix für den Pfad an, der an den Bucket-Namen angehängt werden soll, wenn Datastream Daten an das Ziel streamt. Achten Sie darauf, dass Datastream Daten in einen Pfad innerhalb des Buckets und nicht in den Bucket-Stammordner schreibt. Verwenden Sie für diese Anleitung den Pfad, den Sie beim Konfigurieren Ihrer Pub/Sub-Benachrichtigung definiert haben. Geben Sie
/integration/tutorialin das Feld ein.
- Geben Sie im Feld Name des Verbindungsprofils
Klicken Sie auf Erstellen.
Nachdem Sie ein Quellverbindungsprofil für Ihre MySQL-Datenbank und ein Zielverbindungsprofil für Cloud Storage erstellt haben, können Sie damit einen Stream erstellen.
Stream in Datastream erstellen
In diesem Abschnitt erstellen Sie einen Stream. Dieser Stream verwendet die Informationen in den Verbindungsprofilen, um Daten aus einer MySQL-Quelldatenbank in einen Ziel-Bucket in Cloud Storage zu übertragen.
Einstellungen für den Stream festlegen
Rufen Sie in der Google Cloud Console die Seite Streams für Datastream auf.
Klicken Sie auf Stream erstellen.
Geben Sie auf der Seite Stream erstellen im Bereich Streamdetails definieren die folgenden Informationen an:
- Geben Sie im Feld Streamname
My Streamein. - Behalten Sie die automatisch generierte Stream-ID bei.
- Wählen Sie im Menü Region die Region aus, in der Sie Ihre Quell- und Zielverbindungsprofile erstellt haben.
- Wählen Sie im Menü Quelltyp den Profiltyp MySQL aus.
- Wählen Sie im Menü Zieltyp den Profiltyp Cloud Storage aus.
- Geben Sie im Feld Streamname
Prüfen Sie die erforderlichen Voraussetzungen, die automatisch generiert werden, um widerzuspiegeln, wie Ihre Umgebung für einen Stream vorbereitet sein muss. Diese Voraussetzungen können beispielsweise das Konfigurieren der Quelldatenbank und das Verbinden von Datastream mit dem Ziel-Bucket in Cloud Storage umfassen.
Klicken Sie auf Weiter. Der Bereich MySQL-Verbindungsprofil definieren der Seite Stream erstellen wird angezeigt.
Informationen zum Quellverbindungsprofil angeben
In diesem Abschnitt wählen Sie das Verbindungsprofil aus, das Sie für Ihre Quelldatenbank erstellt haben (das Quellverbindungsprofil). In dieser Anleitung ist das Mein Quellverbindungsprofil.
Wählen Sie im Menü Quellverbindungsprofil Ihr Quellverbindungsprofil für die MySQL-Datenbank aus.
Klicken Sie auf Testen, um zu prüfen, ob die Quelldatenbank und Datastream miteinander kommunizieren können.
Wenn der Test fehlschlägt, wird das mit dem Verbindungsprofil verknüpfte Problem angezeigt. Informationen zur Fehlerbehebung finden Sie auf der Seite Probleme diagnostizieren. Nehmen Sie die erforderlichen Änderungen vor, um das Problem zu beheben, und führen Sie den Test noch einmal durch.
Klicken Sie auf Weiter. Der Bereich Stream-Quelle konfigurieren der Seite Stream erstellen wird angezeigt.
Informationen zur Quelldatenbank für den Stream konfigurieren
In diesem Abschnitt konfigurieren Sie Informationen zur Quelldatenbank für den Stream, indem Sie die Tabellen und Schemas in der Quelldatenbank angeben, die Datastream:
- In das Ziel übertragen kann.
- Nicht in das Ziel übertragen darf.
Sie legen auch fest, ob Datastream Verlaufsdaten per Backfill auffüllt, laufende Änderungen in das Ziel streamt oder nur Änderungen an den Daten streamt.
Verwenden Sie das Menü Aufzunehmende Objekte, um die Tabellen und Schemata in Ihrer Quelldatenbank anzugeben, die Datastream in einen Ordner im Ziel-Bucket in Cloud Storage übertragen kann. Das Menü wird nur geladen,wenn Ihre Datenbank bis zu 5.000 Objekte enthält.
In dieser Anleitung soll Datastream alle Tabellen und Schemas übertragen. Wählen Sie daher im Menü die Option Alle Tabellen aus allen Schemas aus.
Prüfen Sie, ob der Bereich Auszuschließende Objekte auswählen auf Keine festgelegt ist. Sie möchten Datastream nicht daran hindern, Tabellen und Schemata aus Ihrer Quelldatenbank nach Cloud Storage zu übertragen.
Prüfen Sie, ob der Bereich Backfill-Modus für Verlaufsdaten auswählen auf Automatisch eingestellt ist. Datastream streamt alle vorhandenen Daten sowie Änderungen an den Daten von der Quelle in das Ziel.
Klicken Sie auf Weiter. Der Bereich Cloud Storage-Verbindungsprofil definieren der Seite Stream erstellen wird angezeigt.
Zielverbindungsprofil auswählen
In diesem Abschnitt wählen Sie das Verbindungsprofil aus, das Sie für Cloud Storage erstellt haben (das Zielverbindungsprofil). In dieser Anleitung ist das Mein Zielverbindungsprofil.
Wählen Sie im Menü Zielverbindungsprofil Ihr Zielverbindungsprofil für Cloud Storage aus.
Klicken Sie auf Weiter. Der Bereich Stream-Ziel konfigurieren der Seite Stream erstellen wird angezeigt.
Informationen zum Ziel für den Stream konfigurieren
In diesem Abschnitt konfigurieren Sie Informationen zum Ziel-Bucket für den Stream. Zu diesen Daten gehören:
- Das Ausgabeformat der in Cloud Storage geschriebenen Dateien.
- Der Ordner des Ziel-Buckets, in den Datastream Schemas, Tabellen und Daten aus der Quelldatenbank überträgt.
Wählen Sie im Feld Ausgabeformat das Format der in Cloud Storage geschriebenen Dateien aus. Datastream unterstützt zwei Ausgabeformate: Avro und JSON. In dieser Anleitung ist Avro das Dateiformat.
Klicken Sie auf Weiter. Der Bereich Stream-Details prüfen und erstellen der Seite Stream erstellen wird angezeigt.
Stream erstellen
Prüfen Sie Details zum Stream sowie die Quell- und Zielverbindungsprofile, die der Stream zur Übertragung von Daten von einer MySQL-Quelldatenbank zu einem Ziel-Bucket in Cloud Storage verwendet.
Klicken Sie auf Validierung ausführen, um den Stream zu validieren. Bei der Validierung eines Streams prüft Datastream, ob die Quelle richtig konfiguriert ist, ob der Stream eine Verbindung zur Quelle und zum Ziel herstellen kann und ob die End-to-End-Konfiguration des Streams stimmt.
Wenn alle Validierungsprüfungen erfolgreich waren, klicken Sie auf Erstellen.
Klicken Sie im Dialogfeld Stream erstellen? auf Erstellen.
Stream starten
In dieser Anleitung erstellen und starten Sie einen Stream separat, für den Fall, dass der Stream-Erstellungsprozess eine erhöhte Belastung Ihrer Quelldatenbank verursacht. Um diesen Ladevorgang auszugleichen, erstellen Sie den Stream, ohne ihn zu starten. Dann starten Sie den Stream, wenn Ihre Datenbank die Last verarbeiten kann.
Durch das Starten des Streams kann Datastream Daten, Schemas und Tabellen von der Quelldatenbank zum Ziel übertragen.
Rufen Sie in der Google Cloud Console die Seite Streams für Datastream auf.
Klicken Sie das Kästchen neben dem Stream an, den Sie starten möchten. In dieser Anleitung ist dies Mein Stream.
Klicken Sie auf Start.
Klicken Sie im Dialogfeld auf Starten. Der Status des Streams ändert sich von
Not startedinStartinginRunning.
Nachdem Sie einen Stream gestartet haben, können Sie überprüfen, ob Datastream Daten aus der Quelldatenbank zum Ziel übertragen hat.
Stream prüfen
In diesem Abschnitt bestätigen Sie, dass Datastream die Daten aus allen Tabellen einer MySQL-Quelldatenbank in den Ordner /integration/tutorial Ihres Cloud Storage-Ziel-Buckets überträgt.
Rufen Sie in der Google Cloud Console die Seite Streams für Datastream auf.
Klicken Sie auf den Stream, den Sie erstellt haben. In dieser Anleitung ist dies Mein Stream.
Klicken Sie auf der Seite Stream-Details auf den Link bucket-name/integration/tutorial, wobei bucket-name der Name ist, den Sie Ihrem Cloud Storage-Bucket gegeben haben. Dieser Link wird nach dem Feld Zielschreibpfad angezeigt. Die Seite Bucket-Details von Cloud Storage wird in einem separaten Tab geöffnet.
Prüfen Sie, ob die Ordner angezeigt werden, die Tabellen der Quelldatenbank darstellen.
Klicken Sie auf einen der Tabellenordner und dann auf jeden Unterordner, bis Sie Daten sehen, die mit der Tabelle verknüpft sind.
Dataflow-Job erstellen
In diesem Abschnitt erstellen Sie einen Job in Dataflow. Nachdem Datastream Datenänderungen aus einer MySQL-Quelldatenbank in Ihren Cloud Storage-Bucket gestreamt hat, sendet Pub/Sub Benachrichtigungen über neue Dateien mit den Änderungen an Dataflow. Der Dataflow-Job verarbeitet die Dateien und überträgt die Änderungen in BigQuery.
Rufen Sie in der Google Cloud Console die Seite Jobs für Dataflow auf.
Klicken Sie auf Job aus Vorlage erstellen.
Geben Sie auf der Seite Job aus Vorlage erstellen im Feld Jobname einen Namen für den Dataflow-Job ein, den Sie erstellen. Geben Sie für diese Anleitung
my-dataflow-integration-jobin das Feld ein.Wählen Sie im Menü Regionaler Endpunkt die Region aus, in der Sie den Job speichern möchten. Dies ist dieselbe Region, die Sie für das Quellverbindungsprofil, das Zielverbindungsprofil und den Stream, den Sie erstellt haben, ausgewählt haben.
Wählen Sie im Menü Dataflow-Vorlage die Vorlage aus, die Sie zum Erstellen des Jobs verwenden. Wählen Sie für diese Anleitung Datastream zu BigQuery aus.
Nachdem Sie diese Auswahl getroffen haben, werden zusätzliche Felder angezeigt, die sich auf diese Vorlage beziehen.
Geben Sie im Feld Dateispeicherort für Datastream-Dateiausgabe in Cloud Storage den Namen Ihres Cloud Storage-Bucket im folgenden Format ein:
gs://bucket-name.Geben Sie in das Feld Pub/Sub-Abo, das in einer Cloud Storage-Benachrichtigungsrichtlinie verwendet wird den Pfad ein, der den Namen Ihres Pub/Sub-Abos enthält. Geben Sie für diese Anleitung
projects/project-name/subscriptions/my_integration_notifs_subein.Geben Sie
avroin das Feld Ausgabedateiformat von Datastream (avro/json). ein, da Avro in dieser Anleitung das Dateiformat der Dateien ist, die Datastream in Cloud Storage schreibt.Geben Sie in das Feld Name oder Vorlage für das Dataset, das Staging-Tabellen enthalten soll,
My_integration_dataset_logein, da Dataflow dieses Dataset für die Bereitstellung der Datenänderungen verwendet, die es von Datastream erhält.Geben Sie im Feld Vorlage für das Dataset mit Replikattabellen
My_integration_dataset_finalein, da dies das Dataset ist, in dem die Änderungen, die im Dataset My_integration_dataset_log bereitgestellt werden, zusammengeführt werden, um ein 1:1-Replikat der Tabellen in der Quelldatenbank zu erstellen.Geben Sie im Feld Verzeichnis für Warteschlange für unzustellbare Nachrichten den Pfad ein, der den Namen Ihres Cloud Storage-Bucket und einen Ordner für eine Warteschlange für unzustellbare Nachrichten enthält. Achten Sie darauf, dass Sie keinen Pfad im Stammordner verwenden und dass sich der Pfad von dem unterscheidet, in den Datastream Daten schreibt. Alle Datenänderungen, die Dataflow nicht in BigQuery übertragen kann, werden in der Warteschlange gespeichert. Sie können den Inhalt der Warteschlange korrigieren, damit Dataflow ihn noch einmal verarbeiten kann.
Geben Sie für diese Anleitung
gs://bucket-name/dlqin das Feld Warteschlange für unzustellbare Nachrichten ein.Dabei ist bucket-name der Name Ihres Buckets und dlq der Ordner für die Warteschlange für unzustellbare Nachrichten.Klicken Sie auf Job ausführen.
Integration prüfen
Im Abschnitt Stream prüfen dieser Anleitung haben Sie bestätigt, dass Datastream die Daten aus allen Tabellen einer MySQL-Quelldatenbank in den Ordner /integration/tutorial Ihres Cloud Storage-Ziel-Buckets übertragen hat.
In diesem Abschnitt überprüfen Sie, ob Dataflow die Dateien verarbeitet, die die mit diesen Daten verbundenen Änderungen enthalten, und die Änderungen in BigQuery überträgt. Deshalb haben Sie eine durchgängige Integration zwischen Datastream und BigQuery.
Rufen Sie in der Google Cloud Console die Seite SQL-Arbeitsbereich für BigQuery auf.
Maximieren Sie im Bereich Explorer den Knoten neben dem Namen Ihres Google Cloud -Projekts.
Maximieren Sie die Knoten neben den Datasets My_integration_dataset_log und My_integration_dataset_final.
Prüfen Sie, ob jedes Dataset nun Daten enthält. Dies bestätigt, dass Dataflow die Dateien mit den Änderungen, die mit den von Datastream in Cloud Storage gestreamten Daten verbunden sind, verarbeitet und diese Änderungen in BigQuery übertragen hat.
Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden: Google Cloud
- Löschen Sie Ihr Projekt, Ihren Datastream-Stream und Ihre Datastream-Verbindungsprofile.
- Beenden Sie den Dataflow-Job.
- Löschen Sie die BigQuery-Datasets, das Pub/Sub-Thema und -Abo sowie den Cloud Storage-Bucket.
Durch das Bereinigen der Ressourcen, die Sie in Datastream, Dataflow, BigQuery, Pub/Sub und Cloud Storage erstellt haben, werden diese keine Kontingente mehr beanspruchen und Ihnen in Zukunft nicht in Rechnung gestellt werden.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten durch Löschen des für diese Anleitung erstellten Projekts.
Wechseln Sie in der Google Cloud -Console zur Seite Ressourcen verwalten.
Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
Stream löschen
Rufen Sie in der Google Cloud Console die Seite Streams für Datastream auf.
Klicken Sie auf den Stream, den Sie löschen möchten. In dieser Anleitung ist dies Mein Stream.
Klicken Sie auf Pausieren.
Klicken Sie im Dialogfeld auf Pausieren.
Prüfen Sie im Bereich Streamstatus der Seite Stream-Details, ob der Status des Streams
Pausedist.Klicken Sie auf Löschen.
Geben Sie im Dialogfeld
Deletein das Textfeld ein und klicken Sie dann auf Löschen.
Verbindungsprofile löschen
Rufen Sie in der Google Cloud Console die Seite Verbindungsprofile für Datastream auf.
Aktivieren Sie das Kästchen für jedes Verbindungsprofil, das Sie löschen möchten: Mein Quellverbindungsprofil und Mein Zielverbindungsprofil.
Klicken Sie auf Löschen.
Klicken Sie im Dialogfeld auf Löschen.
Dataflow-Job beenden
Rufen Sie in der Google Cloud Console die Seite Jobs für Dataflow auf.
Klicken Sie auf den Job, den Sie beenden möchten. In dieser Anleitung ist dies my-dataflow-integration-job.
Klicken Sie auf Beenden.
Wählen Sie im Dialogfeld Job beenden die Option Per Drain beenden aus und klicken Sie dann auf Job beenden.
BigQuery-Datasets löschen
Rufen Sie in der Google Cloud Console die Seite SQL-Arbeitsbereich für BigQuery auf.
Maximieren Sie im Bereich Explorer den Knoten neben dem Namen Ihres Google Cloud -Projekts.
Klicken Sie rechts neben einem der Datasets, die Sie unter Datasets in BigQuery erstellen erstellt haben, auf die Schaltfläche Aktionen aufrufen. Diese Schaltfläche sieht wie eine vertikale Ellipse aus.
Klicken Sie für diese Anleitung rechts neben My_integration_dataset_log auf die Schaltfläche Aktionen aufrufen.
Wählen Sie aus dem Drop-down-Menü Löschen aus.
Geben Sie im Dialogfeld Dataset löschen? den Wert
deletein das Textfeld ein und klicken Sie auf Löschen.Wiederholen Sie die Schritte in dieser Anleitung, um das zweite von Ihnen erstellte Dataset zu löschen: My_integration_dataset_final.
Pub/Sub-Abo und -Thema löschen
Rufen Sie in der Google Cloud Console die Seite Abos für Pub/Sub auf.
Klicken Sie auf das Kästchen neben dem Abo, das Sie löschen möchten. Klicken Sie für diese Anleitung auf das Kästchen neben dem Abo my_integration_notifs_sub.
Klicken Sie auf Löschen.
Klicken Sie im Dialogfeld Abo löschen auf Löschen.
Rufen Sie in der Google Cloud Console die Seite Themen für Pub/Sub auf.
Klicken Sie auf das Kästchen neben dem Thema my_integration_notifs.
Klicken Sie auf Löschen.
Geben Sie im Dialogfeld Thema löschen den Wert
deletein das Textfeld ein und klicken Sie auf Löschen.
Cloud Storage-Bucket löschen
Wechseln Sie in der Google Cloud Console zur Seite Browser für Cloud Storage.
Klicken Sie das Kästchen neben Ihrem Bucket an.
Klicken Sie auf Löschen.
Geben Sie im Dialogfeld
Deletein das Textfeld ein und klicken Sie dann auf Löschen.
Nächste Schritte
- Weitere Informationen zu Datastream
- Legacy-Streaming-API verwenden, um erweiterte Funktionen mit Streamingdaten in BigQuery auszuführen.
- Weitere Google Cloud Funktionen ausprobieren Anleitungen