Datastream for BigQuery
リレーショナル データベースから直接 BigQuery へシームレスな複製を行うことで、運用データに関するほぼリアルタイムの分析情報が得られます。

利点
最小限のレイテンシで運用データをレプリケートする
MySQL、PostgreSQL、AlloyDB、Oracle データベースのデータを直接 BigQuery にシームレスにレプリケートします。低レイテンシで、ソースのパフォーマンスに影響を与えません。
サーバーレス アーキテクチャのスケールアップとスケールダウンができます。
自動的にスケールするサーバーレスのアプローチにより、インフラストラクチャの管理なしで運用上のオーバーヘッドを解消します。
数分で利用を開始する
簡素化された設定エクスペリエンスにより、わずか数ステップでオペレーショナル データベースから BigQuery へのデータのレプリケーションを開始できます。
主な機能
主な機能
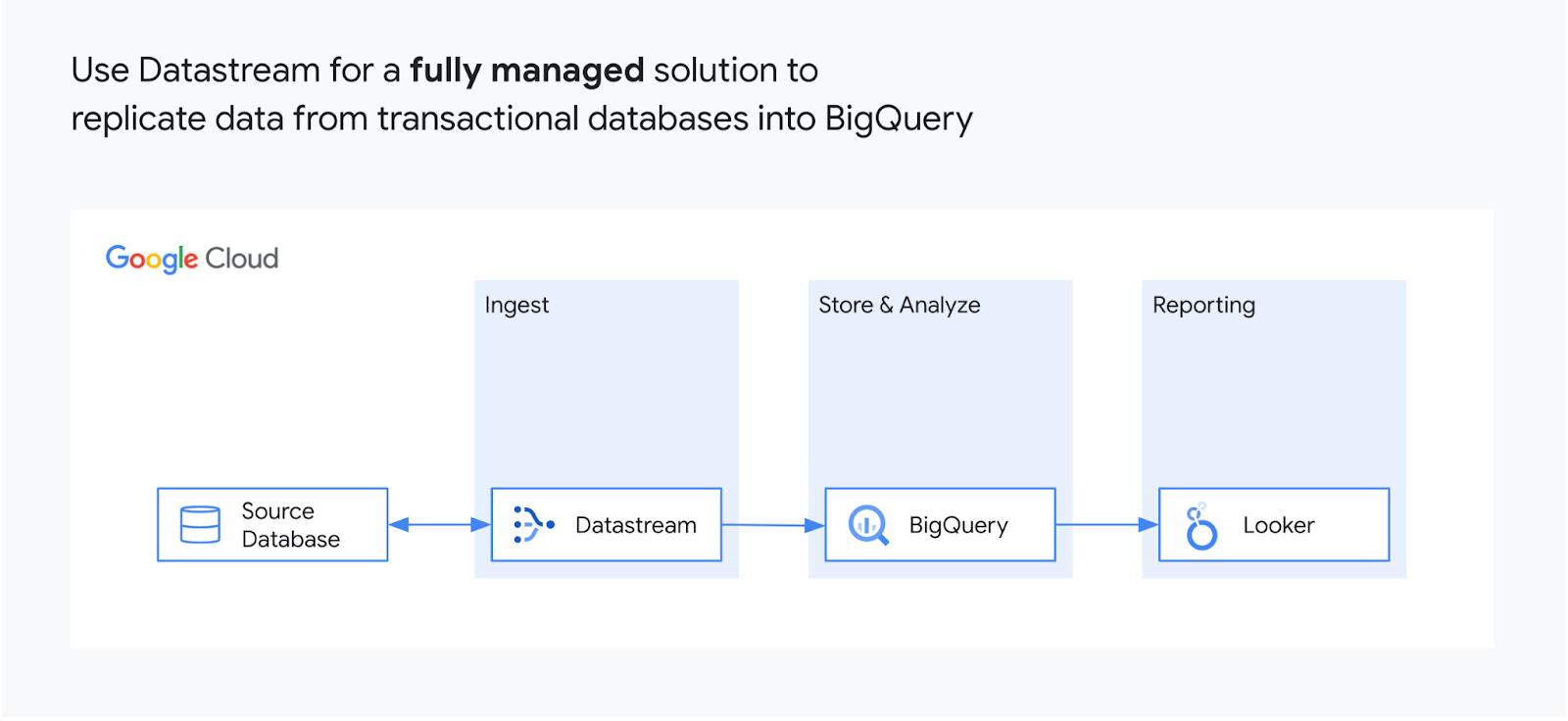
運用データの BigQuery へのレプリケーション
Datastream は、BigQuery の変更データ キャプチャ(CDC)機能と Storage Write API を使用して、ソースシステムから更新をほぼリアルタイムで効率的に複製します。複雑なデータ パイプライン、セルフマネージドのステージング テーブル、複雑なマージ ロジック、手動によるデータ型変換に貴重なリソースを浪費するレプリケーション ソリューションは不要になりました。
設定が簡単
Datastream では、わずか数ステップでデータを BigQuery にレプリケートできます。BigQuery でソース データベース、接続タイプ、宛先を構成するだけで、Datastream for BigQuery が過去のデータのバックフィルを開始し、以降は継続的に、新しい変更が発生すると同時に変更がレプリケートされます。
リレーショナル データベースからのストリーミング データ
Datastream は、MySQL、PostgreSQL、AlloyDB、Oracle の各種データベースから変更(挿入、更新、削除)をすべて読み取り、配信して、最小限のレイテンシで BigQuery にデータを読み込みます。ソース データベースは、オンプレミスや Cloud SQL、さらに Bare Metal Solution for Oracle などの Google Cloud サービス、または任意のクラウド上でホストすることができます。BigQuery のために構築されたエージェントレスの Google ネイティブ サービスであり、すあらゆるイベントを確実にストリーミングできます。
スキーマ ドリフトの解決
ソーススキーマが変更されると、Datastream はスキーマのドリフトをシームレスに処理し、ソースに追加された新しい列とテーブルを BigQuery に自動的に複製します。
設計から考えられたセキュリティ
Datastream は、転送中のデータを保護するための、複数の安全なプライベート接続方法をサポートしています。また、データは保存時に暗号化されます。

導入事例
顧客は Datastream と BigQuery を使用してリアルタイムの分析情報を実現する


Datastream という 1 つのツールで、オペレーション データを BigQuery に準リアルタイムかつシームレスにレプリケートできます。Datastream のおかげで、運用データについての分析情報の迅速な取得、より安定したデータ プロダクトの提供、ビジネスニーズへの適切な対処が可能になりました。
René Delgado 氏、Falabella 社データ ソリューション責任者

オペレーショナル データベースから BigQuery へデータをストリーミングするオプションを比較する
Datastream for BigQuery
Datastream と Dataflow
Datastream と Data Fusion
主な利点
主な利点
オペレーション データを BigQuery にレプリケートする最も簡単な方法
自動的にスケールアップとスケールダウンを行うサーバーレス アーキテクチャ
レプリケーション パイプラインのエンドツーエンドの可視性とモニタリングのための単一のインターフェース
柔軟性の高いカスタマイズ可能なソリューション
Google の幅広い掲載先に事前に構築されたテンプレート
データ品質やデータ マスキングなどの追加機能の統合
ETL デベロッパーとデータ アナリスト向けのシンプルなインターフェース
レプリケーションにおける潜在的な問題とギャップを事前に特定
レプリケーションのパフォーマンスに関するほぼリアルタイムの分析情報
Datastream for BigQuery
主な利点
オペレーション データを BigQuery にレプリケートする最も簡単な方法
自動的にスケールアップとスケールダウンを行うサーバーレス アーキテクチャ
レプリケーション パイプラインのエンドツーエンドの可視性とモニタリングのための単一のインターフェース
Datastream と Dataflow
主な利点
柔軟性の高いカスタマイズ可能なソリューション
Google の幅広い掲載先に事前に構築されたテンプレート
データ品質やデータ マスキングなどの追加機能の統合
Datastream と Data Fusion
主な利点
ETL デベロッパーとデータ アナリスト向けのシンプルなインターフェース
レプリケーションにおける潜在的な問題とギャップを事前に特定
レプリケーションのパフォーマンスに関するほぼリアルタイムの分析情報
開始にあたりサポートが必要な場合
お問い合わせ信頼できるパートナーと連携する
パートナーを探すもっと見る
すべてのプロダクトを見る


















