Datastream für BigQuery
Nahtlose Replikation von relationalen Datenbanken direkt in BigQuery, wodurch Informationen nahezu in Echtzeit über operative Daten gewonnen werden.
Replikation mit niedriger Latenz, um echtzeitnahe Informationen in BigQuery zu ermöglichen
Zugriff auf Streamingdaten aus MySQL-, PostgreSQL-, AlloyDB-, SQL Server- und Oracle-Datenbanken
Serverlose Plattform, die automatisch skaliert wird, ohne dass Ressourcen bereitgestellt oder verwaltet werden müssen
Einfache Einrichtung von ELT-Pipelines (Extrahieren, Laden, Transformieren) mit integrierter sicherer Konnektivität
Von Tausenden Kunden verwendet, um Betriebsdaten in BigQuery zu replizieren

Vorteile
Betriebsdaten mit minimaler Latenz replizieren
Replizieren Sie Daten aus MySQL-, PostgreSQL-, AlloyDB- und Oracle-Datenbanken direkt in BigQuery mit niedriger Latenz und ohne Auswirkungen auf die Quellleistung.
Mit einer serverlosen Architektur nach oben oder unten skalieren
Beseitigen Sie den operativen Aufwand mit einem serverlosen Ansatz, der automatisch skaliert wird, ohne dass Sie eine Infrastruktur verwalten müssen.
Innerhalb weniger Minuten einsatzbereit
Mit einer vereinfachten Einrichtung können Sie mit wenigen Schritten Daten aus Ihren operativen Datenbanken in BigQuery replizieren.
Wichtige Features
Wichtige Features
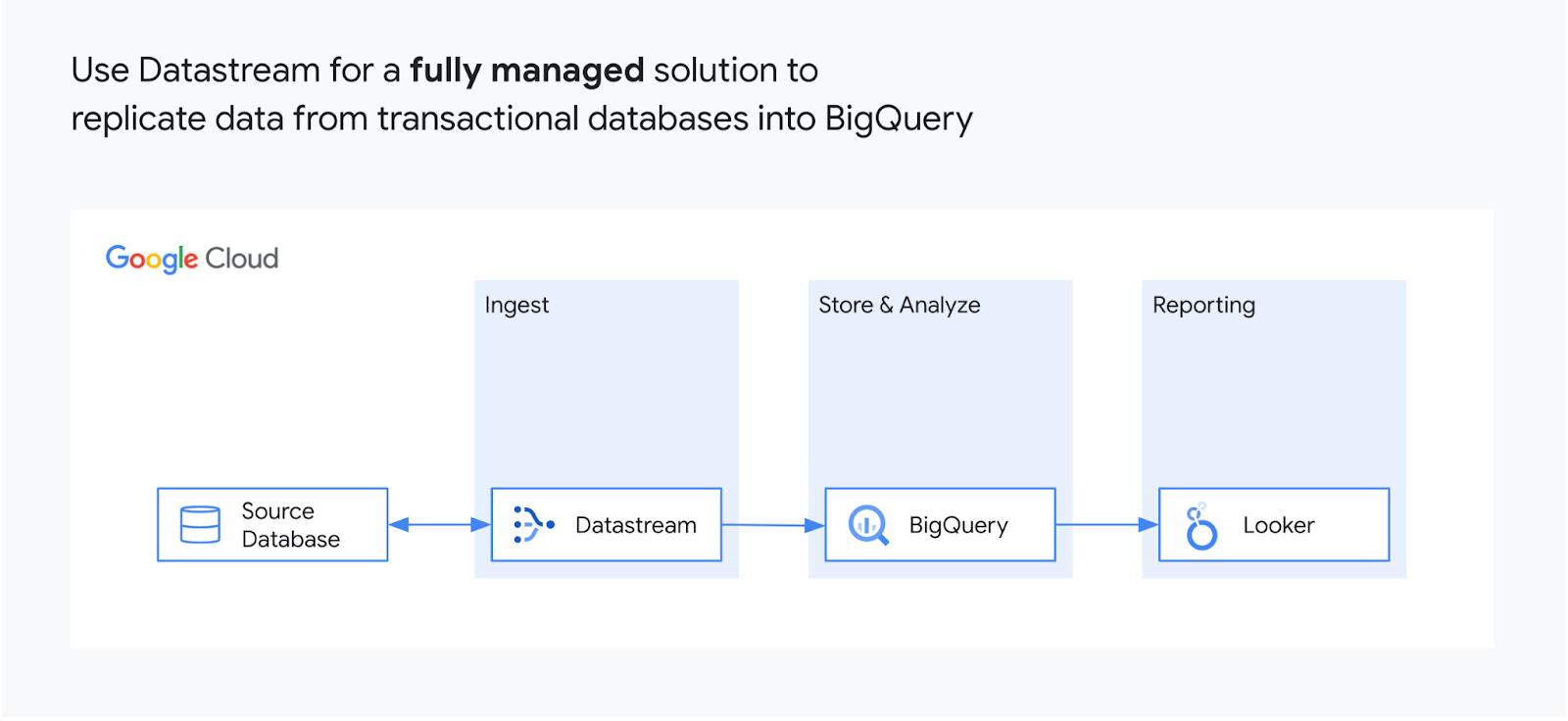
Betriebsdaten in BigQuery replizieren
Datastream nutzt die Change Data Capture (CDC)-Funktion von BigQuery und die Storage Write API, um Aktualisierungen nahezu in Echtzeit direkt aus Quellsystemen zu replizieren. Sie benötigen keine Replikationslösungen mehr, die wertvolle Ressourcen für komplexe Datenpipelines, selbstverwaltete Staging-Tabellen, knifflige Zusammenführungslogik oder manuelle Datentypkonvertierung verschwenden.
Vereinfachte Einrichtung
Mit Datastream können Sie in wenigen Schritten Daten in BigQuery replizieren. Konfigurieren Sie dazu einfach die Quelldatenbank, den Verbindungstyp und das Ziel in BigQuery. Datastream für BigQuery fügt Verlaufsdaten per Backfill hinzu und repliziert kontinuierlich neue Änderungen.
Daten aus relationalen Datenbanken streamen
Datastream liest und überträgt mit minimaler Latenz jede Änderung – eingefügt, aktualisiert oder gelöscht – aus Ihren MySQL-, PostgreSQL-, AlloyDB- und Oracle-Datenbanken. Die Quelldatenbank kann lokal in Google Cloud-Diensten wie Cloud SQL oder Bare-Metal-Lösung für Oracle oder an einem anderen Ort in einer Cloud gehostet werden. Ein Dienst ohne Agent und Google-eigener Dienst, der speziell für BigQuery entwickelt wurde, streamt jedes Ereignis zuverlässig.
Auflösung der Schemadrift
Wenn sich das Quellschema ändert, verarbeitet Datastream Schemaabweichungen und repliziert automatisch neue Spalten und Tabellen, die der Quelle in BigQuery hinzugefügt wurden.
Entwickelt für mehr Sicherheit
Datastream unterstützt mehrere sichere, private Verbindungsmethoden zum Schutz von Daten bei der Übertragung. Außerdem werden ruhende Daten verschlüsselt.

Kunden
Kunden nutzen Datastream und BigQuery, um Informationen in Echtzeit zu erhalten


Mit Datastream haben wir ein einziges Tool, mit dem wir unsere Betriebsdaten nahtlos und nahezu in Echtzeit in BigQuery replizieren können. Mit Datastream können wir unsere Betriebsdaten viel schneller auswerten, stabilere Datenprodukte bereitstellen und unsere Geschäftsanforderungen besser erfüllen.
René Delgado, Head of Data Solutions bei Falabella

Anwendungsfälle
Anwendungsfälle
Serverlose Replikation in BigQuery
Datastream liest Änderungsereignisse (Einfügen, Aktualisieren und Löschen) aus Quelldatenbanken und schreibt sie nahezu in Echtzeit in BigQuery-Tabellen. Dadurch können Sie vorhandene BigQuery-Data-Warehouses und ML-Modelle mit Transaktionsdaten wie Einzelhandelsgeschäften anreichern, um ein umfassenderes End-to-End-Bild von Daten zu erhalten. Datastream fügt Verlaufsdaten per Backfill hinzu, repliziert neue Änderungen kontinuierlich und verarbeitet Schemaänderungen nahtlos.
Optionen zum Streamen von Daten aus Betriebsdatenbanken in BigQuery vergleichen
Datastream für BigQuery
Datastream und Dataflow
Datastream und Data Fusion
Hauptvorteile
Hauptvorteile
Einfachste Option zum Replizieren von Betriebsdaten in BigQuery
Serverlose Architektur, die automatisch hoch- und herunterskaliert
Einzelne Schnittstelle für End-to-End-Sichtbarkeit und Monitoring von Replikationspipelines
Anpassbare Lösung mit zusätzlicher Flexibilität
Vorgefertigte Vorlagen, die von Google für eine Reihe von Zielen unterstützt werden
Einbindung zusätzlicher Features wie Datenqualität und Datenmaskierung
Einfache Oberfläche für ETL-Entwickler und Datenanalysten
Mögliche Probleme und Replikationslücken im Voraus erkennen
Nahezu Echtzeitinformationen zur Replikationsleistung
Datastream für BigQuery
Hauptvorteile
Einfachste Option zum Replizieren von Betriebsdaten in BigQuery
Serverlose Architektur, die automatisch hoch- und herunterskaliert
Einzelne Schnittstelle für End-to-End-Sichtbarkeit und Monitoring von Replikationspipelines
Datastream und Dataflow
Hauptvorteile
Anpassbare Lösung mit zusätzlicher Flexibilität
Vorgefertigte Vorlagen, die von Google für eine Reihe von Zielen unterstützt werden
Einbindung zusätzlicher Features wie Datenqualität und Datenmaskierung
Datastream und Data Fusion
Hauptvorteile
Einfache Oberfläche für ETL-Entwickler und Datenanalysten
Mögliche Probleme und Replikationslücken im Voraus erkennen
Nahezu Echtzeitinformationen zur Replikationsleistung
Preise
Datastream - Preise
Die Preise für Datastream basieren auf den tatsächlich verarbeiteten Daten. Es sind volumenbasierte Preisstufen verfügbar, die es erschwinglicher machen, wenn Sie größere Datenmengen verschieben. Weitere Preisdetails finden Sie auf der Seite „Datastream-Preise“.
Zusätzliche Ressourcen wie BigQuery, Cloud Storage und Dataflow werden nach den Preisen für diese Dienste abgerechnet.
Gleich loslegen
Profitieren Sie von einem Guthaben über 300 $, um Google Cloud und mehr als 20 „Immer kostenlos“ Produkte kennenzulernen.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partner arbeiten
Partner findenMehr ansehen
Alle Produkte ansehen


















