Classificação rápida e fiável no Datastore
Classificação: um problema simples, mas muito difícil
Tomoaki Suzuki (Figura 1), um engenheiro principal do App Engine na Applibot, tem tentado resolver o problema muito comum, mas muito difícil, enfrentado por todos os grandes serviços de jogos: classificação.

A Applibot é um dos principais fornecedores de aplicações sociais no Japão. A singularidade da empresa reside no seu vasto conhecimento e experiência na criação de serviços de jogos sociais altamente escaláveis no Google App Engine, a oferta de plataforma como serviço (PaaS) da Google. Tirando partido do poder da plataforma, a Applibot tem tido bastante sucesso na captação de oportunidades de negócio no mercado de jogos sociais, não só no Japão, mas também nos Estados Unidos. O Applibot pode certamente atestar o seu sucesso. Legend of the Cryptids (Figura 2), um dos seus maiores títulos, alcançou o 1.º lugar na categoria de jogos da App Store da Apple na América do Norte em outubro de 2012. A série Legend registou 4,7 milhões de transferências. Outro título, Gang Road, atingiu o 1.º lugar no ranking de vendas totais da App Store do Japão em dezembro de 2012.

Estes títulos conseguiram ser dimensionados sem problemas e processar o tráfego em grande crescimento. O Applibot não teve de se esforçar para criar clusters complexos de servidores virtuais ou bases de dados divididas. A empresa tirou partido do poder do App Engine e alcançou de forma eficiente a escalabilidade e a disponibilidade.
No entanto, a classificação atualizada dos jogadores não é um problema fácil de resolver, nem para Tomoaki, e provavelmente para nenhum programador, especialmente a esta escala. Os requisitos são simples:
- O seu jogo tem centenas de milhares (ou mais!) de jogadores.
- Sempre que um jogador luta contra inimigos (ou realiza outras atividades), a respetiva pontuação muda.
- Quer mostrar a classificação mais recente do jogador numa página do portal Web.
Como é calculado um ranking?
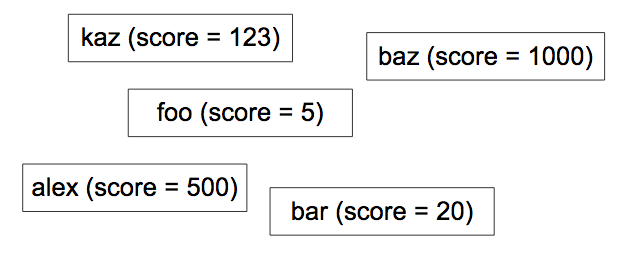
É fácil obter uma classificação se não se esperar que seja também escalável e rápida. Por exemplo, pode executar a seguinte consulta:
SELECT count(key) FROM Players WHERE Score > YourScore
Esta consulta conta todos os jogadores que têm uma pontuação superior à sua (Figura 4). Mas quer executar esta consulta para cada pedido da página do portal? Quanto tempo demoraria se tivesse um milhão de jogadores?
Tomoaki implementou inicialmente esta abordagem, mas demorava alguns segundos a receber cada resposta. Este processo era demasiado lento, demasiado caro e tinha um desempenho progressivamente pior à medida que a escala aumentava.
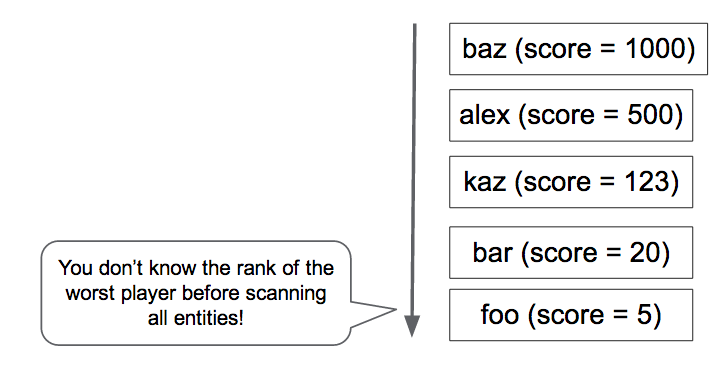
Em seguida, o Tomoaki tentou manter os dados de classificação no Memcache. Foi rápido, mas não fiável. As entradas da Memcache podiam ser removidas em qualquer altura e, por vezes, o próprio serviço Memcache não estava disponível. Com um serviço de classificação que dependia exclusivamente de chaves-valores na memória, era difícil manter a consistência e a disponibilidade.
Como solução temporária, o Tomoaki decidiu diminuir o nível de serviço. Em vez de calcular a classificação para cada pedido, configurou uma tarefa agendada que analisava e atualizava a classificação de cada jogador uma vez por hora. Desta forma, os pedidos da página do portal podem obter a classificação do leitor instantaneamente, mas pode ter até uma hora.
Em última análise, Tomoaki procurava uma implementação de classificação persistente, transacional, rápida e escalável que pudesse aceitar 300 pedidos de atualização de pontuação por segundo e obter uma classificação para cada jogador em centenas de milissegundos. Para encontrar uma solução, o Tomoaki recorreu ao Kaz Sato, um Solutions Architect (SA), bem como um Technical Account Manager (TAM) na equipa da Google Cloud Platform e atribuído à Applibot ao abrigo de um contrato de apoio técnico de nível premium.
Uma forma rápida de resolver problemas
Muitos clientes ou parceiros de grande dimensão da Google Cloud Platform, como a Applibot, subscrevem um contrato de apoio técnico de nível premium. Com esse contrato de apoio técnico, além do apoio técnico 24 horas por dia, 7 dias por semana da equipa de apoio ao cliente do Google Cloud e do apoio técnico empresarial da equipa de vendas do Google Cloud, a Google atribui um gestor técnico de conta (TAM) a cada cliente.
Um GAT representa o cliente junto da equipa de engenharia da Google, que cria a infraestrutura de nuvem real. Os GATs compreendem detalhadamente o sistema e a arquitetura do cliente e, quando apresentam um caso crítico, usam os seus conhecimentos e rede como representante de engenharia da Google na empresa para resolver o problema. Os TAMs podem encaminhar problemas para os arquitetos de soluções na equipa ou para os engenheiros de software na equipa da Cloud Platform. O apoio técnico de nível premium é a via rápida para encontrar uma solução com a Google Cloud Platform.
O Kaz, o GAT que presta apoio técnico ao Applibot, sabia que a classificação era um problema clássico e, no entanto, difícil de resolver para qualquer serviço distribuído escalável. Começou a rever as implementações conhecidas para a classificação no Google Cloud Datastore e noutras bases de dados NoSQL para encontrar uma solução que cumprisse os requisitos do Applibot.
Procura um algoritmo O(log n)
A solução de consulta simples requer a análise de todos os jogadores com uma pontuação mais elevada para contabilizar a classificação de um jogador. A complexidade temporal deste algoritmo é O(n), ou seja, o tempo necessário para a execução da consulta aumenta proporcionalmente ao número de jogadores. Na prática, isto significa que o algoritmo não é escalável. Em alternativa, precisamos de um algoritmo O(log n) ou mais rápido, em que o tempo só aumenta logaritmicamente à medida que o número de jogadores aumenta.
Se alguma vez fez um curso de informática, pode lembrar-se de que os algoritmos de árvore, como árvores binárias, árvores vermelho-pretas ou árvores B, podem ter um desempenho com uma complexidade de tempo O(log n) para encontrar um elemento. Os algoritmos de árvore também podem ser usados para calcular um valor agregado de um intervalo de elementos, como a contagem, o máximo/mínimo e a média, mantendo os valores agregados em cada nó de ramificação. Com esta técnica, é possível implementar um algoritmo de classificação com um desempenho de O(log n).
O Kaz encontrou uma implementação de código aberto de um algoritmo de classificação baseado em árvores para o Datastore, escrito por um engenheiro da Google: a Google Code Jam Ranking Library.
Esta biblioteca baseada em Python expõe dois métodos:
SetScorepara definir a pontuação de um jogador.FindRankpara obter a classificação de uma determinada pontuação.
À medida que os pares de pontuação do jogador são criados e atualizados com o método SetScore, a biblioteca de classificação do Code Jam cria uma árvore N-ária1. Por exemplo, vamos considerar uma árvore terciária que pode contar o número de jogadores com pontuações no intervalo de 0 a 80 (Figura 5). A biblioteca armazena o nó raiz, que contém três números, como uma entidade. Cada número corresponde ao número de jogadores com pontuações nos subintervalos 0 a 26, 27 a 53 e 54 a 80, respetivamente. O nó raiz tem um nó filho para cada intervalo, que, por sua vez, contém três valores para jogadores nos subintervalos do subintervalo. A hierarquia precisa de quatro níveis para armazenar o número de jogadores para 81 valores de pontuação diferentes.
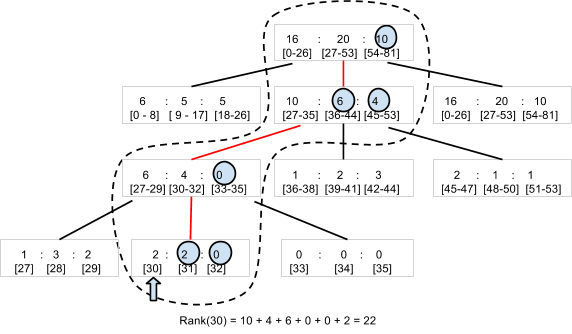
Para determinar a classificação de um jogador com uma pontuação de 30, a biblioteca só precisa de ler quatro entidades (os nós assinalados com um círculo a tracejado no diagrama) para somar o número de jogadores com uma pontuação superior a 30. Com 22 jogadores à "direita" em quatro entidades, a classificação do jogador é 23.ª.
Da mesma forma, uma chamada para SetScore só precisa de atualizar quatro entidades. Mesmo que tenha um grande número de pontuações diferentes, o acesso ao Datastore só aumenta a O(log n) e não é afetado pelo número de jogadores. Na prática, a biblioteca de classificação do Code Jam usa 100 (em vez de 3) como o número predefinido de valores por nó, pelo que só é necessário aceder a duas (ou três, se o intervalo de pontuação for superior a 100 000) entidades.
O Kaz usou a popular ferramenta de teste de carga Apache JMeter para realizar um teste de carga na biblioteca de classificações do Code Jam e confirmou que a biblioteca responde rapidamente. Tanto o SetScore como o FindRank podem concluir as respetivas tarefas em centenas de milissegundos através do algoritmo de árvore N-ária que funciona com uma complexidade de tempo de O(log n).
O limite de atualizações em simultâneo limita a escalabilidade
No entanto, durante os testes de carga, o Kaz encontrou uma limitação crítica na biblioteca de classificações do Code Jam. A sua escalabilidade em termos de taxa de transferência de atualizações era bastante baixa. Quando aumentou o carregamento para três atualizações por segundo, a biblioteca começou a devolver erros de nova tentativa de transação. Era óbvio que a biblioteca não podia satisfazer o requisito do Applibot de 300 atualizações por segundo. Só conseguia processar cerca de 1% desse débito.
Porquê? O motivo é o custo de manter a consistência da estrutura em árvore. No Datastore, tem de usar um grupo de entidades para garantir uma consistência forte quando atualiza várias entidades numa transação. Consulte o artigo "Equilibrar a consistência forte e eventual com o Google Cloud Datastore". A biblioteca de classificação do Code Jam usa um único grupo de entidades para conter toda a árvore, de modo a garantir a consistência das contagens nos elementos da árvore.
No entanto, um grupo de entidades no Datastore tem uma limitação de desempenho. O Datastore só suporta cerca de uma transação por segundo num grupo de entidades. Além disso, se o mesmo grupo de entidades for modificado em transações simultâneas, é provável que falhem e tenham de ser repetidas. A biblioteca de classificações do Code Jam é fortemente consistente, transacional e relativamente rápida, mas não suporta um volume elevado de atualizações simultâneas.
Solução da equipa do Datastore: agregação de empregos
Kaz lembrou-se de que um engenheiro de software na equipa do Datastore tinha mencionado uma técnica para obter um débito muito superior a uma atualização por segundo num grupo de entidades. Isto pode ser conseguido agregando um lote de atualizações numa transação, em vez de executar cada atualização como uma transação separada. No entanto, como a transação inclui um grande número de atualizações, cada transação demora mais tempo, o que aumenta a possibilidade de conflitos de transações simultâneas.
Em resposta ao pedido de Kaz, a equipa do Datastore começou a debater este problema e aconselhou-nos a considerar a utilização da agregação de tarefas, um dos padrões de design usados com o Megastore.
O Megastore é a camada de armazenamento subjacente do Datastore e gere a consistência e a transacionalidade dos grupos de entidades. O limite de uma atualização por segundo tem origem nessa camada. Uma vez que o Megastore é amplamente usado por vários serviços Google, os engenheiros têm recolhido e partilhado práticas recomendadas e padrões de design na empresa para criar um sistema escalável e consistente com este armazenamento de dados NoSQL.
A ideia básica da agregação de tarefas é usar uma única thread para processar um lote de atualizações. Como existe apenas uma união e apenas uma transação aberta no grupo de entidades, não existem falhas de transação devido a atualizações simultâneas. Pode encontrar ideias semelhantes noutros produtos de armazenamento, como o VoltDb e o Redis.
No entanto, existe uma desvantagem no padrão de agregação de tarefas: usa apenas uma thread para agregar todas as atualizações, o que impõe um limite à rapidez com que pode enviar as atualizações para o Datastore. Por conseguinte, era importante determinar se a agregação de tarefas podia satisfazer o requisito de débito do Applibot de 300 atualizações por segundo.
Agregação de tarefas por fila de obtenção
Com base no aconselhamento da equipa do Datastore, Kaz escreveu um código de prova de conceito (PoC) que combina o padrão de agregação de tarefas com a biblioteca de classificação do Code Jam. A PoC tem os seguintes componentes:
- Frontend: aceita pedidos
SetScoredos utilizadores e adiciona-os como tarefas a uma fila de obtenção. - Fila de obtenção: recebe e retém os pedidos de atualização do front-end.
SetScore - Backend: executa um ciclo infinito com um único segmento que extrai os pedidos de atualização da fila e executa-os com a biblioteca de classificação do Code Jam.
A PoC cria uma fila de obtenção, que é um tipo de fila de tarefas no App Engine que permite aos programadores implementar um ou vários trabalhadores que consomem as tarefas adicionadas à fila. A instância de back-end tem uma única thread num ciclo infinito que continua a extrair o maior número possível de tarefas (até 1000) da fila. A thread passa cada pedido de atualização para a biblioteca de classificações do Code Jam, que os executa como um lote numa única transação. A transação pode estar aberta durante um segundo ou mais, mas, como existe um único segmento a controlar a biblioteca e o Datastore, não existe contenção nem problema de modificação simultânea.
A instância de back-end é definida como um módulo, uma funcionalidade do App Engine que permite aos programadores definir uma instância de aplicação com várias caraterísticas. Nesta PoC, a instância de back-end é definida como uma instância de escalabilidade manual. Apenas uma instância deste tipo está em execução num determinado momento.
A Kaz testou a carga da validação de conceito com o JMeter. Confirmou que a PoC conseguiu processar 200 pedidos SetScore por segundo, com lotes de 500 a 600 atualizações por transação. A agregação de trabalhos funciona!
Queue Sharding para um desempenho estável
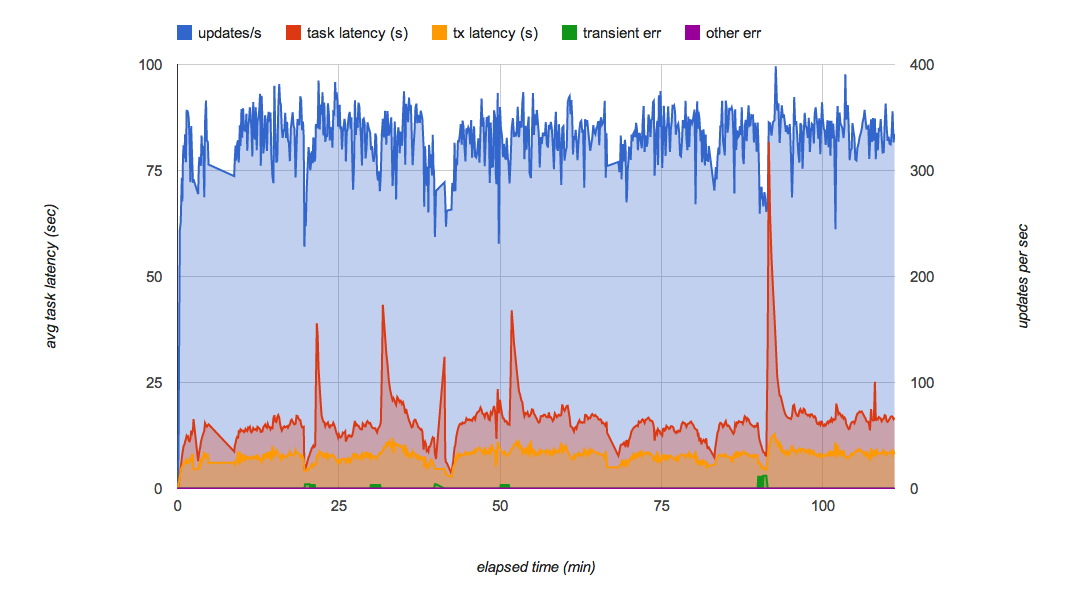
No entanto, Kaz encontrou rapidamente outro problema. À medida que continuava a executar o teste durante vários minutos, viu o débito da fila de obtenção flutuar ocasionalmente (Figura 6). Especificamente, quando continuou a adicionar pedidos à fila com 200 tarefas por segundo durante vários minutos, a fila deixou subitamente de passar tarefas para o back-end e a latência de cada tarefa aumentou drasticamente.
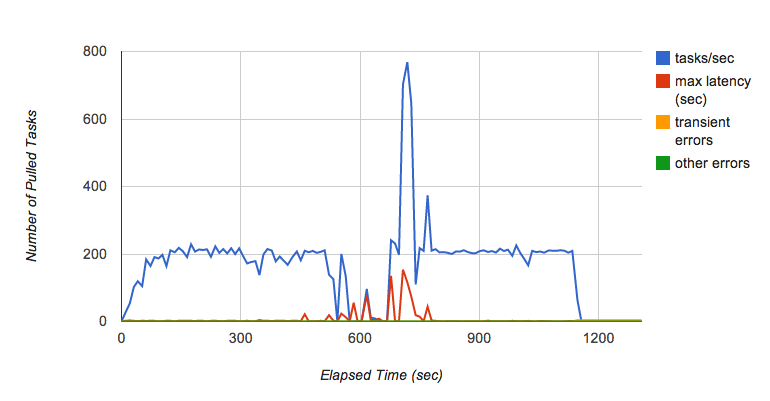
Kaz consultou a equipa da fila de tarefas para saber por que motivo isto estava a acontecer. De acordo com a equipa da fila de tarefas, este é um comportamento conhecido da implementação atual da fila de obtenção, que depende do Bigtable como camada de persistência. Quando um tablet do Bigtable cresce demasiado, é dividido em vários tablets. Enquanto o tablet está a ser dividido, as tarefas não são entregues, o que cria a flutuação do desempenho quando a fila está a receber tarefas a uma taxa elevada. A equipa da fila de tarefas está a trabalhar para melhorar estas caraterísticas de desempenho.
Michael Tang, um arquiteto de soluções, recomendou uma solução alternativa que usa a divisão de filas. Em vez de usar apenas uma fila, sugeriu distribuir a carga por várias filas. Cada fila pode ser armazenada num servidor de tablets do Bigtable diferente para minimizar o efeito de uma divisão de tablets e manter uma taxa de processamento de tarefas elevada. Enquanto uma fila está a processar uma divisão, as outras filas continuam a funcionar e a divisão em fragmentos diminui a carga em cada fila, pelo que a divisão de uma tabela ocorre com menos frequência.
O loop de instância de back-end melhorado executa o seguinte algoritmo:
- Arrendar
SetScoretarefas de 10 filas. - Chame o método
SetScorescom as tarefas. - Eliminar as tarefas alugadas das filas.
No passo 1, cada fila fornece até 1000 tarefas, cada uma com o nome de um jogador e uma pontuação. Depois de agregar todos os pares de pontuações dos jogadores num dicionário, o passo 2 passa o lote de atualizações para o método SetScores da biblioteca de classificações do Code Jam, que abre uma transação para os armazenar no Datastore. Se não tiver ocorrido nenhum erro na execução do método, o passo 3 elimina as tarefas alugadas das filas.
Se ocorrer um erro ou um encerramento inesperado do ciclo ou da instância de back-end, as tarefas de atualização permanecem nas filas de tarefas para que possam ser processadas quando a instância for reiniciada. Num sistema de produção, pode ter outro back-end a funcionar como um watchdog no modo de espera, pronto a assumir o controlo se a primeira instância falhar.
A solução proposta: funciona a 300 atualizações por segundo de forma sustentada2
A Figura 7 mostra o resultado do teste de carga da implementação final da PoC com a divisão em partições da fila. Minimiza eficazmente as flutuações de desempenho nas filas e pode suportar 300 atualizações por segundo durante várias horas. Com a carga normal, cada atualização é aplicada ao Datastore alguns segundos após a receção do pedido.
Esta solução cumpre todos os requisitos originais da Applibot:
- Escalável para processar dezenas de milhares de jogadores.
- Persistente e consistente, uma vez que todas as atualizações são executadas em transações do Datastore.
- Rápido o suficiente para processar 300 atualizações por segundo.
Com os resultados dos testes de carga e o código da validação de conceito, Kaz apresentou a solução a Tomoaki e a outros engenheiros da Applibot. Tomoaki planeia incorporar a solução no respetivo sistema de produção, espera reduzir a latência da atualização das informações de classificação de uma hora para alguns segundos e espera melhorar drasticamente a experiência do utilizador.
Resumo da árvore de classificação com agregação de empregos
A solução proposta tem várias vantagens e uma desvantagem:
Vantagens:
- Rápido: a chamada
FindRankdemora algumas centenas de milissegundos ou menos. - Rápido:
SetScoreenvia apenas uma tarefa, que é processada pelo back-end em poucos segundos. - Fortemente consistente e persistente no Datastore.
- As classificações estão corretas.
- Escalável para qualquer número de jogadores.
Desvantagem:
- A taxa de transferência tem uma limitação (cerca de 300 atualizações/segundo com a implementação atual).
Como esta solução usa o padrão de agregação de tarefas, depende de uma única thread para agregar todas as atualizações. É necessário trabalho ou complexidade adicionais para alcançar um débito superior a 300 atualizações/segundo com a potência da CPU atual das instâncias do App Engine e o desempenho do Datastore.
Solução mais escalável com árvore fragmentada
Se precisar de uma taxa de atualização ainda maior, pode ter de dividir a árvore de classificação. Criaria várias implementações do sistema acima, um conjunto de filas que acionam cada uma um módulo de back-end que atualiza a sua própria árvore de classificação.
Em geral, não é necessário nem esperado coordenar as árvores. No caso mais simples, cada atualização SetScore é enviada aleatoriamente para uma fila. Com três árvores deste tipo, cada uma com o seu próprio grupo de entidades do Datastore e servidor de back-end, o débito de atualização esperado seria três vezes superior. A desvantagem é que o FindRank tem de consultar cada árvore de classificação para obter a classificação de uma pontuação e, em seguida, somar a classificação de cada árvore para encontrar a classificação real, o que demora um pouco mais. O tempo de consulta para FindRank pode ser substancialmente reduzido se mantiver as entidades na Memcache.
Isto é semelhante à abordagem bem conhecida de usar contadores fragmentados: cada contador é incrementado de forma independente e a soma total é calculada apenas quando o cliente precisa.
Por exemplo, com três árvores, FindRank(865) pode encontrar as três classificações 124, 183 e 156, o que indica que cada árvore contém o respetivo número de pontuações superiores a 865. O número total calculado de pontuações superiores a 865 é, então, 124 + 183 + 156 = 463.
Esta abordagem não funciona para todos os tipos de algoritmos distribuídos, mas, como a classificação é fundamentalmente um problema de contagem comutativa, deve funcionar para problemas de classificação de grande volume.
Soluções mais escaláveis com abordagens aproximadas
Se a sua aplicação exigir escalabilidade mais do que precisão das classificações e puder tolerar um determinado nível de imprecisão ou aproximação, pode escolher abordagens estocásticas, como:
- Recipientes com consulta global
- Método de contagem com perdas
- Frugal Streaming
Estas abordagens aproximadas são todas variantes de uma ideia: como comprimir o armazenamento de informações de classificação permitindo uma determinada degradação da precisão da classificação?
Os contentores com consulta global são uma solução alternativa proposta pela equipa do Datastore e por Alex Amies, um TAM. O Alex implementou uma PoC com base na ideia da equipa do Datastore e realizou uma análise de desempenho exaustiva. Provou que os contentores com consultas globais são uma solução de classificação escalável com uma degradação mínima na precisão da classificação e podem ser adequados para aplicações que requerem um débito mais elevado do que a biblioteca de classificação do Code Jam. Consulte o Anexo para ver uma descrição detalhada e os resultados dos testes.
O método de contagem com perdas e o streaming frugal são os chamados algoritmos online e algoritmos de streaming, nos quais pode usar um armazenamento na memória muito pequeno para calcular uma estimativa estocástica dos principais classificadores a partir de um fluxo de pares de pontuações de jogadores. Estes algoritmos seriam adequados para aplicações que requerem uma latência muito baixa e uma largura de banda muito elevada, como milhares de atualizações por segundo, com uma precisão e uma cobertura mais limitadas dos resultados de classificação. Por exemplo, se quiser ter um painel de controlo em tempo real que mostre as 100 principais palavras-chave introduzidas numa stream de redes sociais, estes algoritmos ajudam.
Conclusão
A classificação é um problema clássico, mas difícil de resolver, se exigir que o algoritmo seja escalável, consistente e rápido. Neste artigo, descrevemos como os TAMs da Google trabalharam em estreita colaboração com o cliente e as equipas de engenharia da Google para enfrentar o desafio e fornecer uma solução que pudesse reduzir a latência da atualização da classificação de uma hora para alguns segundos. Os padrões de design descobertos no processo (agregação de tarefas e divisão de filas) também podem ser aplicados a problemas comuns noutros designs de sistemas baseados no Datastore que requerem centenas de atualizações por segundo com uma forte consistência.
Notas
- A biblioteca de classificações do Code Jam usa um parâmetro denominado "fator de ramificação" que especifica quantas pontuações cada entidade vai ter. Por predefinição, a biblioteca usa 100 como parâmetro. Neste caso, as pontuações entre 0 e 9999 são armazenadas em 100 entidades como elementos subordinados do nó raiz. Se precisar de processar uma gama mais ampla de pontuações, pode alterar o fator de ramificação para um valor mais elevado para otimizar o número de acessos de entidades.
- Quaisquer valores de desempenho descritos neste artigo são valores de amostra para referência e não garantem o desempenho absoluto do App Engine, do Datastore ou de outros serviços.
Apêndice: contentores com solução de consulta global
Conforme mencionado na secção Como obter uma classificação, é dispendioso consultar a base de dados para cada pedido de classificação. Esta abordagem alternativa obtém periodicamente a contagem de todas as pontuações, calcula a classificação das pontuações selecionadas e fornece esses pontos de dados para utilização no cálculo das classificações de jogadores específicos. O intervalo total de pontuações é dividido em "segmentos". Cada segmento é caraterizado por um subintervalo de pontuações e o número de jogadores com pontuações nesse intervalo. A partir desses dados, é possível encontrar a classificação de qualquer pontuação com uma aproximação precisa. Estes contentores são semelhantes ao nó de nível superior na árvore de classificação, mas, em vez de descer para nós mais detalhados, este algoritmo apenas interpola num contentor.
A obtenção da classificação pelos utilizadores a partir do front-end está separada do cálculo da classificação em contentores no back-end para minimizar o tempo necessário para encontrar uma classificação. Quando é pedida a classificação de um jogador, é encontrado o grupo adequado com base na pontuação do jogador. O grupo inclui um limite superior de classificação e uma contagem de jogadores no grupo. A interpolação linear nos intervalos é usada para estimar a classificação dos jogadores nos intervalos. Nos nossos testes, conseguimos obter a classificação de um jogador de forma consistente em menos de 400 milissegundos para uma viagem de ida e volta HTTP completa. O custo do método FindRank não depende do número de jogadores na população.
Calcular a classificação para uma determinada pontuação
A contagem e a classificação mais elevada (ou seja, a classificação mais elevada possível neste segmento) são registadas para cada segmento. Para pontuações entre os limites de pontuação baixa e alta num grupo, usamos a interpolação linear para estimar a classificação. Por exemplo, se o jogador tiver uma pontuação de 60, analisamos o grupo [50, 74], usando a contagem (número de jogadores/pontuações no grupo) (42) e a classificação mais alta (5) para calcular a classificação do jogador com esta fórmula:
rank = 5 + (74 - 60)*42/(74 - 50) = 30
Calcular a contagem e o intervalo de cada grupo
Em segundo plano, através de uma tarefa cron ou de uma fila de tarefas, as contagens de cada segmento são calculadas e guardadas através da iteração de todos os segmentos. Chamamos a isto uma consulta global, porque calcula os parâmetros necessários para estimar as classificações examinando as pontuações de todos os jogadores. Segue-se um exemplo de código Python para o fazer através das classificações no intervalo [low_score, high_score] para cada grupo.
next_upper_rank = 1 for b in buckets: count = GetCountInRange(b.low_score, b.high_score) b.count = count b.upper_rank = next_upper_rank b.put() next_upper_rank += count
O método GetCountInRange() conta cada jogador com pontuações no intervalo abrangido pelo segmento. Uma vez que o Datastore mantém um índice ordenado das pontuações dos jogadores, esta contagem pode ser calculada de forma eficiente.
Quando precisamos de encontrar a classificação de um jogador específico, podemos usar o código apresentado abaixo.
b = GetBucketByScore(score) rank = RankInBucket(b, score) return rank + b.upper_rank - 1
O método GetBucketByScore(score) obtém o intervalo que contém a pontuação especificada. O método RankInBucket() faz uma estimativa da classificação no grupo. A classificação do jogador é a soma da classificação mais alta do grupo e da classificação no grupo específico que inclui a pontuação do jogador. Temos de subtrair 1 ao resultado porque a classificação mais alta do grupo superior é 1 e a classificação do jogador principal num grupo específico também é 1.
Os contentores são armazenados no Datastore e no Memcache. Para calcular a classificação, leia os contentores do Memcache (ou do Datastore, se o Memcache não tiver os dados). Na nossa própria implementação deste algoritmo, usámos a biblioteca cliente NDB do Python que usa o Memcache para colocar em cache os dados armazenados no Datastore.
Uma vez que os intervalos (ou outros métodos) são usados para representar os dados de forma compacta, as classificações produzidas não são exatas. As classificações num grupo são aproximadas com interpolação linear. Podem ser usados outros métodos de interpolação mais precisos para uma melhor aproximação no intervalo, como uma fórmula de regressão.
Custo
O custo de encontrar uma classificação e atualizar a pontuação de um jogador é O(1), ou seja, independente do número de jogadores.
O custo da tarefa de consulta global é O(Jogadores) * frequência de atualização da cache.
O custo de computação dos dados dos segmentos na tarefa de back-end também está relacionado com o número de segmentos, uma vez que é realizada uma consulta de contagem para cada segmento. A consulta count está otimizada para usar uma consulta apenas de chaves, mas, mesmo assim, tem de ser obtida a lista de chaves completa.
Vantagens
Este método é muito rápido para atualizar a pontuação de um jogador e encontrar a classificação de uma pontuação. Embora os resultados se baseiem numa tarefa em segundo plano, se a pontuação de um jogador mudar, a classificação mostra imediatamente uma alteração na direção adequada. Isto deve-se à interpolação usada no grupo.
Uma vez que o cálculo da classificação mais alta de um grupo é feito em segundo plano com uma tarefa agendada, as pontuações do jogador podem ser atualizadas sem necessidade de manter os dados do grupo sincronizados. Assim, o débito da atualização das pontuações dos jogadores não é limitado por esta abordagem.
Desvantagens
Tem de ter em conta o tempo necessário para contar as pontuações de todos os jogadores, calcular as classificações globais e atualizar os grupos. Nos nossos testes, com uma população de dez milhões de jogadores, o tempo foi de 8 minutos e 34 segundos para o nosso sistema de teste no App Engine. Isto é mais rápido do que as horas que demoraria a calcular a classificação de cada jogador, mas a desvantagem é a aproximação das pontuações em cada categoria. Por outro lado, o algoritmo de árvore calcula os "intervalos de agrupamento" (o nó superior da árvore) de forma incremental a cada poucos segundos, mas tem uma maior complexidade de implementação e um débito limitado.
Em todos os casos, o tempo de FindRank também depende da obtenção rápida de dados (nós de contentores ou árvores) do Memcache. Se os dados forem removidos do Memcache, têm de ser obtidos novamente do Datastore e colocados novamente em cache para pedidos FindRank subsequentes.
Precisão
A precisão do método de agrupamento depende do número de grupos, da classificação do jogador e da distribuição das pontuações. A Figura 9 mostra os resultados do nosso estudo sobre a precisão das estimativas de classificação com diferentes números de grupos.
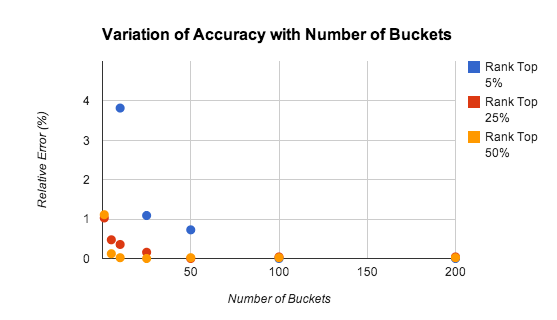
Os testes foram realizados para uma população de 10 000 jogadores com pontuações distribuídas uniformemente no intervalo [0-9999]. O erro relativo é de cerca de 1% mesmo para apenas 5 grupos.
A precisão diminui para jogadores com classificações elevadas, principalmente porque a lei dos grandes números não se aplica quando se analisam apenas as pontuações mais altas. Em muitos casos, pode ser aconselhável usar um algoritmo mais preciso para manter as classificações dos mil ou dois mil jogadores com pontuações mais altas. O problema é consideravelmente reduzido, uma vez que existem menos jogadores para monitorizar e a taxa agregada de atualizações é correspondentemente inferior.
No teste acima, a utilização de números aleatórios distribuídos uniformemente, em que a função de distribuição cumulativa é linear, favorece a utilização da interpolação linear no intervalo, mas a interpolação nos intervalos funciona bem para qualquer distribuição densa de classificações. A Figura 10 mostra a classificação estimada e real para uma distribuição aproximadamente normal das pontuações.
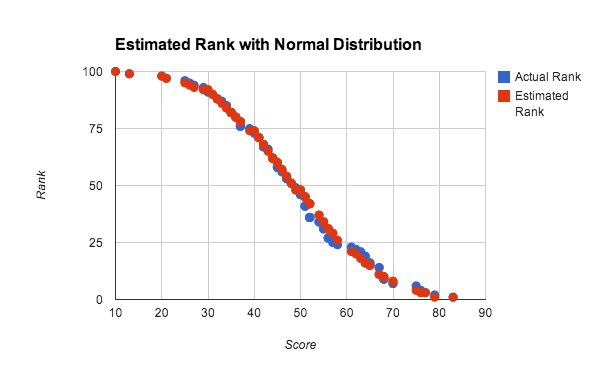
Nesta experiência, foi usada uma população de 100 jogadores para testar a precisão com um pequeno conjunto de dados. Cada pontuação foi gerada através da média de 4 números aleatórios entre 0 e 100, o que se aproxima de uma distribuição normal de pontuações. A classificação estimada foi calculada através do método de consulta global com interpolação linear em 10 grupos. Pode ver que, mesmo para conjuntos de dados muito pequenos e distribuições não uniformes, os resultados são muito bons.