Equilibrar a consistência forte e eventual com o Datastore
Oferecer uma experiência do utilizador consistente e tirar partido do modelo de consistência eventual para dimensionar para grandes conjuntos de dados
Este documento aborda a obtenção de uma forte consistência para uma experiência do utilizador positiva, ao mesmo tempo que abrange o modelo de consistência eventual do Datastore para processar grandes quantidades de dados e utilizadores.
Este documento destina-se a arquitetos e engenheiros de software que pretendem criar soluções no Datastore. Para ajudar os leitores mais familiarizados com bases de dados relacionais do que com sistemas não relacionais, como o Datastore, este documento aponta conceitos análogos em bases de dados relacionais. O documento pressupõe que tem um conhecimento básico do Datastore. A forma mais fácil de começar a usar o Datastore é no Google App Engine, usando um dos idiomas suportados. Se ainda não usou o App Engine, sugerimos que leia primeiro o guia de introdução e a secção Armazenar dados para um desses idiomas. Embora o Python seja usado para fragmentos de código de exemplo, não é necessária experiência em Python para acompanhar este documento.
Nota: Os fragmentos de código neste artigo usam a biblioteca cliente Python DB para o Datastore, que já não é recomendada. Os programadores que criam novas aplicações são fortemente aconselhados a usar a biblioteca de cliente NDB, que tem várias vantagens em comparação com esta biblioteca de cliente, como o armazenamento em cache automático de entidades através da API Memcache. Se estiver a usar a biblioteca cliente DB mais antiga, leia o guia de migração de DB para NDB
Índice
NoSQL e consistência eventual
Consistência eventual no Datastore
Consulta de antepassados e grupo de entidades
Limitações do grupo de entidades e da consulta de antepassados
Alternativas às consultas de antepassados
Minimizar o tempo para alcançar a consistência total
Conclusão
Recursos adicionais
NoSQL e consistência eventual
As bases de dados não relacionais, também conhecidas como bases de dados NoSQL, surgiram nos últimos anos como uma alternativa às bases de dados relacionais. O Datastore é uma das bases de dados não relacionais mais usadas na indústria. Em 2013, o Datastore processou 4,5 biliões de transações por mês (publicação no blogue da Google Cloud Platform). Oferece uma forma simplificada de os programadores armazenarem e acederem a dados. O esquema flexível mapeia naturalmente para linguagens de programação orientada para objetos e de scripts. O Datastore também oferece várias funcionalidades para as quais as bases de dados relacionais não são adequadas, incluindo um elevado desempenho a uma escala muito grande e uma elevada fiabilidade.
Para os programadores mais habituados a bases de dados relacionais, pode ser difícil criar um sistema que tire partido de bases de dados não relacionais, uma vez que algumas características e práticas das bases de dados não relacionais podem ser relativamente desconhecidas para eles. Embora o modelo de programação do Datastore seja simples, é importante ter em atenção estas caraterísticas. A consistência eventual é uma destas caraterísticas e a programação para a consistência eventual é o principal assunto deste documento.
O que é a consistência eventual?
A consistência eventual é uma garantia teórica de que, desde que não sejam feitas novas atualizações a uma entidade, todas as leituras da entidade devolvem eventualmente o último valor atualizado. O Sistema de Nomes de Domínio (DNS) da Internet é um exemplo conhecido de um sistema com um modelo de consistência eventual. Os servidores DNS não refletem necessariamente os valores mais recentes, mas sim os valores são colocados em cache e replicados em muitos diretórios na Internet. Demora algum tempo a replicar os valores modificados para todos os clientes e servidores DNS. No entanto, o sistema DNS é um sistema muito bem-sucedido que se tornou um dos fundamentos da Internet. É altamente disponível e demonstrou ser extremamente escalável, permitindo pesquisas de nomes em mais de cem milhões de dispositivos em toda a Internet.
A Figura 1 ilustra o conceito de replicação com consistência eventual. O diagrama ilustra que, embora as réplicas estejam sempre disponíveis para leitura, algumas réplicas podem ser inconsistentes com a gravação mais recente no nó de origem, num determinado momento. No diagrama, o nó A é o nó de origem e os nós B e C são as réplicas.
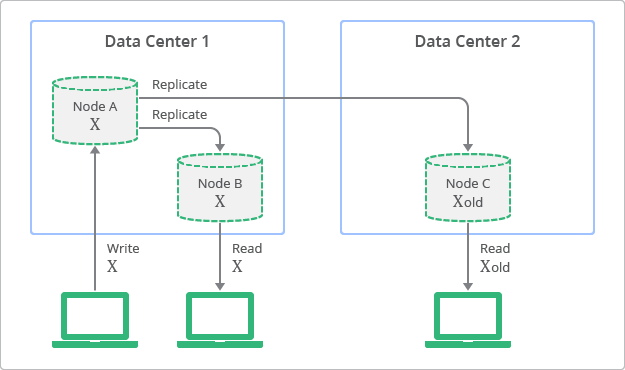
Por outro lado, as bases de dados relacionais tradicionais foram concebidas com base no conceito de consistência forte, também denominada consistência imediata. Isto significa que os dados vistos imediatamente após uma atualização são consistentes para todos os observadores da entidade. Esta característica tem sido uma suposição fundamental para muitos programadores que usam bases de dados relacionais. No entanto, para ter uma forte consistência, os programadores têm de comprometer a escalabilidade e o desempenho da respetiva aplicação. Simplificando, os dados têm de ser bloqueados durante o período de atualização ou processo de replicação para garantir que nenhum outro processo está a atualizar os mesmos dados.
A Figura 2 mostra uma vista conceptual da topologia de implementação e do processo de replicação com consistência forte. Neste diagrama, pode ver como as réplicas têm sempre valores consistentes com o nó de origem, mas não são acessíveis até a atualização terminar.

Equilibrar a consistência forte e a consistência eventual
As bases de dados não relacionais tornaram-se populares recentemente, especialmente para aplicações Web que requerem elevada escalabilidade e desempenho com elevada disponibilidade. As bases de dados não relacionais permitem que os programadores escolham um equilíbrio ideal entre a consistência forte e a consistência eventual para cada aplicação. Isto permite aos programadores combinar as vantagens de ambos os mundos. Por exemplo, informações como "saber quem na sua lista de amigos está online num determinado momento" ou "saber quantos utilizadores deram +1 à sua publicação" são exemplos de utilização em que não é necessária uma forte consistência. A escalabilidade e o desempenho podem ser fornecidos para estes exemplos de utilização através da consistência eventual. Os exemplos de utilização que requerem uma forte consistência incluem informações como "se um utilizador concluiu ou não o processo de faturação" ou "o número de pontos que um jogador ganhou durante uma sessão de batalha".
Para generalizar os exemplos que acabámos de dar, os exemplos de utilização com um número muito elevado de entidades sugerem frequentemente que a consistência eventual é o melhor modelo. Se houver um número muito elevado de resultados numa consulta, a experiência do utilizador pode não ser afetada pela inclusão ou exclusão de entidades específicas. Por outro lado, os exemplos de utilização com um pequeno número de entidades e um contexto restrito sugerem que é necessária uma forte consistência. A experiência do utilizador é afetada porque o contexto informa os utilizadores sobre que entidades devem ser incluídas ou excluídas.
Por estes motivos, é importante que os programadores compreendam as caraterísticas não relacionais do Datastore. As secções seguintes abordam a forma como os modelos de consistência eventual e consistência forte podem ser combinados para criar uma aplicação escalável, altamente disponível e com um desempenho elevado. Ao fazê-lo, os requisitos de consistência para uma experiência do utilizador positiva continuam a ser cumpridos.
Consistência eventual no armazenamento de dados
A API correta tem de ser selecionada quando é necessária uma vista dos dados fortemente consistente. As diferentes variedades de APIs de consulta do Datastore e os respetivos modelos de consistência são apresentados na Tabela 1.
|
API Datastore |
Leitura do valor da entidade |
Leitura do índice |
|---|---|---|
|
Consistência eventual |
Consistência eventual |
|
|
N/A |
Consistência eventual |
|
|
Consistência forte |
Consistência forte |
|
|
Pesquisa por chave (get()) |
Consistência forte |
N/A |
As consultas do Datastore sem um antepassado são conhecidas como consultas globais e foram concebidas para funcionar com um modelo de consistência eventual. Isto não garante uma consistência forte. Uma consulta global apenas com chaves é uma consulta global que devolve apenas as chaves das entidades que correspondem à consulta e não os valores dos atributos das entidades. Uma consulta predecessora restringe a consulta com base numa entidade predecessora. As secções seguintes abordam cada comportamento de consistência mais detalhadamente.
Consistência eventual ao ler valores de entidades
Com exceção das consultas de antecessores, um valor de entidade atualizado pode não estar imediatamente visível quando executa uma consulta. Para compreender o impacto da consistência eventual ao ler valores de entidades, considere um cenário em que uma entidade, Player, tem uma propriedade, Score. Considere, por exemplo, que a pontuação inicial tem um valor de 100. Após algum tempo, o valor da pontuação é atualizado para 200. Se for executada uma consulta global e incluir a mesma entidade Player no resultado, é possível que o valor da propriedade Score da entidade devolvida apareça inalterado, em 100.
Este comportamento é causado pela replicação entre servidores do Datastore. A replicação é gerida pelo Bigtable e pelo Megastore, as tecnologias subjacentes do Datastore (consulte os Recursos adicionais para mais detalhes sobre o Bigtable e o Megastore). A replicação é executada com o algoritmo Paxos, que aguarda sincronamente até que a maioria das réplicas tenha confirmado o pedido de atualização. A réplica é atualizada com dados do pedido após um período. Este período é normalmente curto, mas não existe garantia da sua duração real. Uma consulta pode ler os dados desatualizados se for executada antes de a atualização terminar.
Em muitos casos, a atualização chega a todas as réplicas muito rapidamente. No entanto, existem vários fatores que, quando combinados, podem aumentar o tempo necessário para alcançar a consistência. Estes fatores incluem incidentes ao nível do centro de dados que envolvem a comutação de um grande número de servidores entre centros de dados. Dada a variação destes fatores, é impossível fornecer requisitos de tempo definitivos para estabelecer uma consistência total.
O tempo necessário para uma consulta devolver o valor mais recente é normalmente muito curto. No entanto, em situações raras em que a latência de replicação aumenta, o tempo pode ser muito maior. As aplicações que usam consultas globais do Datastore devem ser cuidadosamente concebidas para processar estes casos de forma elegante.
Pode evitar a consistência eventual na leitura de valores de entidades através de uma consulta apenas de chaves, uma consulta de antepassados ou uma pesquisa por chave (o método get()). Vamos abordar estes diferentes tipos de consultas mais detalhadamente abaixo.
Consistência eventual na leitura de um índice
Um índice pode ainda não estar atualizado quando uma consulta global é executada. Isto significa que, embora possa ler os valores das propriedades mais recentes das entidades, a "lista de entidades" incluída no resultado da consulta pode ser filtrada com base nos valores de índice antigos.
Para compreender o impacto da consistência eventual na leitura de um índice, imagine um cenário em que uma nova entidade, Player, é inserida no Datastore. A entidade tem uma propriedade, Score, que tem um valor inicial de 300. Imediatamente após a inserção, executa uma consulta apenas de chaves para obter todas as entidades com um valor de Score superior a 0. Em seguida, espera que a entidade Player, inserida recentemente, apareça nos resultados da consulta. Talvez inesperadamente, em vez disso, possa verificar que a entidade Player não aparece nos resultados. Esta situação pode ocorrer quando a tabela de índice da propriedade Score não é atualizada com o valor recém-inserido no momento da execução da consulta.
Lembre-se de que todas as consultas no Datastore são executadas em tabelas de índice, mas as atualizações às tabelas de índice são assíncronas. Essencialmente, cada atualização de entidade é composta por duas fases. Na primeira fase, a fase de confirmação, é feita uma gravação no registo de transações. Na segunda fase, os dados são escritos e os índices são atualizados. Se a fase de confirmação for bem-sucedida, a fase de gravação tem a garantia de ser bem-sucedida, embora possa não acontecer imediatamente. Se consultar uma entidade antes de os índices serem atualizados, pode acabar por ver dados que ainda não são consistentes.
Como resultado deste processo de duas fases, existe um atraso antes de as atualizações mais recentes às entidades ficarem visíveis nas consultas globais. Tal como acontece com a consistência eventual do valor da entidade, o atraso é normalmente pequeno, mas pode ser maior (mesmo minutos ou mais em circunstâncias excecionais).
O mesmo pode acontecer após atualizações. Por exemplo, suponha que atualiza uma entidade existente, Player, com um novo valor da propriedade Score de 0 e executa a mesma consulta imediatamente a seguir. Esperaria que a entidade não aparecesse nos resultados da consulta, porque o novo valor de pontuação de 0 a excluiria. No entanto, devido ao mesmo comportamento de atualização do índice assíncrono, ainda é possível que a entidade seja incluída no resultado.
A consistência eventual na leitura de um índice só pode ser evitada através da utilização de uma consulta de antepassados ou de um método de pesquisa por chave. Uma consulta apenas de chaves não pode evitar este comportamento.
Consistência forte na leitura de valores e índices de entidades
No Datastore, existem apenas duas APIs que fornecem uma vista fortemente consistente para ler valores de entidades e índices: (1) o método de pesquisa por chave e (2) a consulta de antepassados. Se a lógica da aplicação exigir uma forte consistência, o programador deve usar um destes métodos para ler entidades do Datastore.
O Datastore foi especificamente concebido para oferecer uma forte consistência nestas APIs. Quando chama qualquer um deles, o Datastore atualiza todas as atualizações pendentes numa das réplicas e tabelas de índice e, em seguida, executa a consulta de procura ou de antepassados. Assim, o valor da entidade mais recente, com base na tabela de índice atualizada, é sempre devolvido com valores baseados nas atualizações mais recentes.
A chamada de pesquisa por chave, ao contrário das consultas, devolve apenas uma entidade ou um conjunto de entidades especificado por uma chave ou um conjunto de chaves. Isto significa que uma consulta de antepassados é a única forma no Datastore de satisfazer o requisito de consistência forte juntamente com um requisito de filtragem. No entanto, as consultas de antepassados não funcionam sem especificar um grupo de entidades.
Consulta predecessora e grupo de entidades
Conforme abordado no início deste documento, uma das vantagens do Datastore é que os programadores podem encontrar um equilíbrio ideal entre a consistência forte e a consistência eventual. No Datastore, um grupo de entidades é uma unidade com consistência forte, transacionalidade e localidade. Ao usar grupos de entidades, os programadores podem definir o âmbito da consistência forte entre as entidades numa aplicação. Desta forma, a aplicação pode manter a consistência no grupo de entidades e, ao mesmo tempo, alcançar uma elevada escalabilidade, disponibilidade e desempenho como um sistema completo.
Um grupo de entidades é uma hierarquia formada por uma entidade raiz e os respetivos elementos secundários ou sucessores.[1] Para criar um grupo de entidades, um programador especifica um caminho de antepassados, que é, essencialmente, uma série de chaves principais que precedem a chave secundária. O conceito de grupo de entidades é ilustrado na Figura 3. Neste caso, a entidade raiz com a chave "ateam" tem dois elementos secundários com as chaves "ateam/098745" e "ateam/098746".
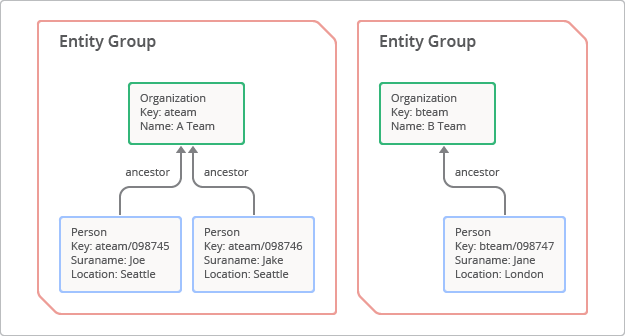
Dentro do grupo de entidades, as seguintes caraterísticas são garantidas:
-
Consistência forte
- Uma consulta de antepassados no grupo de entidades devolve um resultado fortemente consistente. Desta forma, reflete os valores de entidades mais recentes filtrados pelo estado do índice mais recente.
-
Transacionalidade
- Ao demarcar uma transação de forma programática, o grupo de entidades fornece características ACID (atomicidade, consistência, isolamento e durabilidade) na transação.
-
Localidade
- As entidades num grupo de entidades são armazenadas em locais fisicamente próximos nos servidores do Datastore, porque todas as entidades são ordenadas e armazenadas pela ordem lexicográfica das chaves. Isto permite que uma consulta de antepassados analise rapidamente o grupo de entidades com um mínimo de E/S.
Uma consulta predecessora é uma forma especial de consulta que só é executada em relação a um grupo de entidades especificado. É executado com uma forte consistência. Nos bastidores, o Datastore garante que todas as replicações pendentes e atualizações de índice são aplicadas antes de executar a consulta.
Exemplo de consulta predecessora
Esta secção descreve como usar grupos de entidades e consultas de antecessores na prática. No exemplo seguinte, consideramos o problema da gestão de registos de dados de pessoas. Suponhamos que temos código que adiciona uma entidade de um tipo específico, seguida imediatamente por uma consulta sobre esse tipo. Este conceito é demonstrado pelo exemplo de código Python abaixo.
# Define the Person entity
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
organization = db.StringProperty()
# Add a person and retrieve the list of all people
class MainPage(webapp2.RequestHandler):
def post(self):
person = Person(given_name='GI', surname='Joe', organization='ATeam')
person.put()
q = db.GqlQuery("SELECT * FROM Person")
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname,
'organization': p.organization})
O problema com este código é que, na maioria dos casos, a consulta não devolve a entidade adicionada na declaração acima. Uma vez que a consulta segue na linha imediatamente após a inserção, o índice não é atualizado quando a consulta é executada. No entanto, também existe um problema com a validade deste exemplo de utilização: existe realmente a necessidade de devolver uma lista de todas as pessoas numa página sem contexto? E se houver um milhão de pessoas? A página demoraria demasiado tempo a ser devolvida.
A natureza do exemplo de utilização sugere que devemos fornecer algum contexto para restringir a consulta. Neste exemplo, o contexto que vamos usar é a organização. Se o fizermos, podemos usar a organização como um grupo de entidades e executar uma consulta de antepassados, o que resolve o nosso problema de consistência. Isto é demonstrado com o código Python abaixo.
class Organization(db.Model):
name = db.StringProperty()
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
class MainPage(webapp2.RequestHandler):
def post(self):
org = Organization.get_or_insert('ateam', name='ATeam')
person = Person(parent=org)
person.given_name='GI'
person.surname='Joe'
person.put()
q = db.GqlQuery("SELECT * FROM Person WHERE ANCESTOR IS :1 ", org)
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname})
Desta vez, com a org principal especificada no GqlQuery, a consulta devolve a entidade acabada de inserir. O exemplo pode ser expandido para detalhar uma pessoa individual consultando o nome da pessoa com o antepassado como parte da consulta. Em alternativa, também pode guardar a chave da entidade e, em seguida, usá-la para analisar detalhadamente com uma pesquisa por chave.
Manter a consistência entre o Memcache e o Datastore
Os grupos de entidades também podem ser usados como uma unidade para manter a consistência entre as entradas da Memcache e as entidades da Datastore. Por exemplo, considere um cenário em que conta o número de pessoas em cada equipa e as armazena no Memcache. Para garantir que os dados em cache são consistentes com os valores mais recentes no Datastore, pode usar metadados do grupo de entidades. Os metadados devolvem o número da versão mais recente do grupo de entidades especificado. Pode comparar o número da versão com o número armazenado na Memcache. Ao usar este método, pode detetar uma alteração em qualquer uma das entidades em todo o grupo de entidades lendo a partir de um conjunto de metadados, em vez de analisar todas as entidades individuais no grupo.
Limitações da consulta de grupo de entidades e antecessores
A abordagem de usar grupos de entidades e consultas de antecessores não é uma solução universal. Na prática, existem dois desafios que dificultam a aplicação da técnica em geral, conforme indicado abaixo.
- Existe um limite de uma gravação de atualização por segundo para cada grupo de entidades.
- Não é possível alterar a relação do grupo de entidades após a criação da entidade.
Limite de escrita
Um desafio importante é que o sistema tem de ser concebido para conter o número de atualizações (ou transações) em cada grupo de entidades. O limite suportado é de uma atualização por segundo por grupo de entidades.[2] Se o número de atualizações tiver de exceder esse limite, o grupo de entidades pode ser um obstáculo ao desempenho.
No exemplo acima, cada organização pode ter de atualizar o registo de qualquer pessoa na organização. Considere um cenário em que existem 1000 pessoas na "equipa A" e cada pessoa pode ter uma atualização por segundo em qualquer uma das propriedades. Como resultado, pode haver até 1000 atualizações por segundo no grupo de entidades, um resultado que não seria alcançável devido ao limite de atualizações. Isto ilustra que é importante escolher um design de grupo de entidades adequado que tenha em conta os requisitos de desempenho. Este é um dos desafios de encontrar o equilíbrio ideal entre a consistência eventual e a consistência forte.
Imutabilidade das relações do grupo de entidades
Um segundo desafio é a imutabilidade das relações entre grupos de entidades. A relação do grupo de entidades é formada estaticamente com base na nomenclatura das chaves. Não pode ser alterado após a criação da entidade. A única opção disponível para alterar a relação é eliminar as entidades num grupo de entidades e recriá-las. Este desafio impede-nos de usar grupos de entidades para definir âmbitos ad hoc para consistência ou transacionalidade de forma dinâmica. Em alternativa, o âmbito da consistência e da transacionalidade está estreitamente ligado ao grupo de entidades estático definido no momento da conceção.
Por exemplo, considere um cenário em que quer implementar uma transferência bancária entre duas contas bancárias. Este cenário empresarial requer uma forte consistência e transacionalidade. No entanto, não é possível agrupar as duas contas num grupo de entidades de última hora nem baseá-las num elemento principal global. Esse grupo de entidades criaria um gargalo para todo o sistema que impediria a execução de outros pedidos de transferência bancária. Assim, não é possível usar grupos de entidades desta forma.
Existe uma forma alternativa de implementar uma transferência bancária de forma altamente escalável e disponível. Em vez de colocar todas as contas num único grupo de entidades, pode criar um grupo de entidades para cada conta. Ao fazê-lo, pode usar transações para garantir atualizações ACID a ambas as contas bancárias. As transações são uma funcionalidade do Datastore que lhe permite criar conjuntos de operações com caraterísticas ACID para até vinte e cinco grupos de entidades. Tenha em atenção que, numa transação, tem de usar consultas fortemente consistentes, como pesquisas por chave e consultas de antepassados. Para mais informações sobre as restrições de transações, consulte o artigo Transações e grupos de entidades.
Alternativas às consultas predecessoras
Se já tiver uma aplicação existente com um grande número de entidades armazenadas no Datastore, pode ser difícil incorporar grupos de entidades posteriormente num exercício de refatorização. Terá de eliminar todas as entidades e adicioná-las numa relação de grupo de entidades. Assim, na modelagem de dados para o Datastore, é importante tomar uma decisão sobre a estrutura do grupo de entidades na fase inicial da estrutura da aplicação. Caso contrário, pode ter limitações na refatoração para outras alternativas de modo a alcançar um determinado nível de consistência, como uma consulta apenas de chaves seguida de uma pesquisa por chave ou através da utilização da Memcache.
Consulta global apenas com chaves seguida de pesquisa por chave
Uma consulta global apenas de chaves é um tipo especial de consulta global que devolve apenas chaves sem os valores das propriedades das entidades. Uma vez que os valores de retorno são apenas chaves, a consulta não envolve um valor de entidade com um possível problema de consistência. Uma combinação da consulta global apenas com chaves e um método de pesquisa lê os valores das entidades mais recentes. No entanto, deve ter em atenção que uma consulta global apenas com chaves não pode excluir a possibilidade de um índice ainda não ser consistente no momento da consulta, o que pode resultar na não obtenção de uma entidade. O resultado da consulta pode ser gerado com base na filtragem de valores de índice antigos. Em resumo, um programador pode usar uma consulta global apenas com chaves seguida de uma pesquisa por chave apenas quando um requisito da aplicação permite que o valor do índice ainda não seja consistente no momento de uma consulta.
Usar a cache de memória
O serviço Memcache é volátil, mas fortemente consistente. Assim, ao combinar as pesquisas da Memcache e as consultas da Datastore, é possível criar um sistema que minimize os problemas de consistência na maioria das vezes.
Por exemplo, considere o cenário de uma aplicação de jogos que mantém uma lista de entidades de jogador, cada uma com uma pontuação superior a zero.
- Para pedidos de inserção ou atualização, aplique-os à lista de entidades do leitor no Memcache, bem como no Datastore.
- Para pedidos de consultas, leia a lista de entidades de jogadores a partir da Memcache e execute uma consulta apenas de chaves no Datastore quando a lista não estiver presente na Memcache.
A lista devolvida é consistente sempre que a lista em cache está presente na Memcache. Se a entrada tiver sido removida ou o serviço Memcache não estiver disponível temporariamente, o sistema pode ter de ler o valor de uma consulta Datastore que pode devolver um resultado inconsistente. Esta técnica pode ser aplicada a qualquer aplicação que tolere uma pequena quantidade de inconsistência.
Existem algumas práticas recomendadas quando usa o Memcache como uma camada de cache para o Datastore:
- Captar exceções e erros do Memcache para manter a consistência entre o valor do Memcache e o valor do Datastore. Se receber uma exceção ao atualizar a entrada no Memcache, certifique-se de que invalida a entrada antiga no Memcache. Caso contrário, podem existir valores diferentes para uma entidade (um valor antigo na Memcache e um novo valor no Datastore).
- Defina um período de validade nas entradas da Memcache. Recomendamos que defina períodos curtos para o prazo de validade de cada entrada, de modo a minimizar a possibilidade de inconsistência no caso de exceções do Memcache.
- Use a funcionalidade compare-and-set quando atualizar as entradas para o controlo de simultaneidade. Isto ajuda a garantir que as atualizações simultâneas na mesma entrada não interferem umas com as outras.
Migração gradual para grupos de entidades
As sugestões feitas na secção anterior apenas diminuem a possibilidade de um comportamento inconsistente. É melhor criar a aplicação com base em grupos de entidades e consultas de antecessores quando é necessária uma consistência forte. No entanto, pode não ser viável migrar uma aplicação existente, o que pode incluir a alteração de um modelo de dados e de uma lógica de aplicação existentes de consultas globais para consultas de antepassados. Uma forma de o fazer é ter um processo de transição gradual, como o seguinte:
- Identifique e dê prioridade às funções na aplicação que requerem uma forte consistência.
- Escreva uma nova lógica para as funções insert() ou update() usando grupos de entidades, além da lógica existente (em vez de a substituir). Desta forma, quaisquer novas inserções ou atualizações nos novos grupos de entidades e nas entidades antigas podem ser processadas por uma função adequada.
- Modifique a lógica existente para que as consultas de leitura ou de funções sejam executadas primeiro se existir um novo grupo de entidades para o pedido. Execute a consulta global antiga como lógica alternativa se o grupo de entidades não existir.
Esta estratégia permite uma migração gradual de um modelo de dados existente para um novo modelo de dados baseado em grupos de entidades que minimiza o risco de problemas causados pela consistência eventual. Na prática, esta abordagem depende de exemplos de utilização e requisitos específicos para a sua aplicação a um sistema real.
Recorra ao modo degradado
Atualmente, é difícil detetar uma situação de forma programática quando uma aplicação tem uma consistência deteriorada. No entanto, se determinar por outros meios que uma aplicação perdeu consistência, pode ser possível implementar um modo degradado que pode ser ativado ou desativado para desativar algumas áreas da lógica da aplicação que requerem uma forte consistência. Por exemplo, em vez de mostrar um resultado de consulta inconsistente num ecrã de relatório de faturação, pode ser apresentada uma mensagem de manutenção para esse ecrã específico. Desta forma, os outros serviços na aplicação podem continuar a ser publicados e, por sua vez, reduzir o impacto na experiência do utilizador.
Minimizar o tempo necessário para alcançar a consistência total
Numa aplicação grande com milhões de utilizadores ou terabytes de entidades do Datastore, é possível que a utilização inadequada do Datastore leve a uma consistência deteriorada. Essas práticas incluem:
- Numeração sequencial nas chaves de entidades
- Demasiados índices
Estas práticas não afetam as aplicações pequenas. No entanto, quando a aplicação cresce muito, estas práticas aumentam a possibilidade de serem necessários mais tempo para garantir a consistência. Por isso, é melhor evitá-los nas fases iniciais do design da aplicação.
Antipadrão n.º 1: numeração sequencial das chaves de entidades
Antes do lançamento do SDK do App Engine 1.8.1, o Datastore usava uma sequência de IDs de números inteiros pequenos com padrões geralmente consecutivos como os nomes das chaves gerados automaticamente predefinidos. Em alguns documentos, isto é referido como uma "política antiga" para criar quaisquer entidades que não tenham um nome de chave especificado da aplicação. Esta política antiga gerava nomes de chaves de entidades com numeração sequencial, como 1000, 1001 e 1002, por exemplo. No entanto, como abordámos anteriormente, o Datastore armazena entidades pela ordem lexicográfica dos nomes das chaves, pelo que é muito provável que essas entidades sejam armazenadas nos mesmos servidores do Datastore. Se uma aplicação atrair um tráfego muito elevado, esta numeração sequencial pode causar uma concentração de operações num servidor específico, o que pode resultar numa latência mais longa para a consistência.
No App Engine SDK 1.8.1, o Datastore introduziu um novo método de numeração de IDs com uma política predefinida que usa IDs dispersos (consulte a documentação de referência). Esta política predefinida gera uma sequência aleatória de IDs com um máximo de 16 dígitos que são distribuídos de forma aproximadamente uniforme. Com esta política, é provável que o tráfego da aplicação grande seja melhor distribuído por um conjunto de servidores do Datastore com um tempo reduzido para a consistência. A política predefinida é recomendada, a menos que a sua aplicação exija especificamente a compatibilidade com a política antiga.
Se definir explicitamente nomes de chaves em entidades, o esquema de nomenclatura deve ser concebido para aceder às entidades de forma uniforme em todo o espaço de nomes de chaves. Por outras palavras, não concentre o acesso num intervalo específico, uma vez que são ordenados pela ordem lexicográfica dos nomes das chaves. Caso contrário, pode surgir o mesmo problema que com a numeração sequencial.
Para compreender a distribuição desigual do acesso no espaço de chaves, considere um exemplo em que as entidades são criadas com os nomes de chaves sequenciais, conforme mostrado no código seguinte:
p1 = Person(key_name='0001') p2 = Person(key_name='0002') p3 = Person(key_name='0003') ...
O padrão de acesso da aplicação pode criar um "ponto crítico" num determinado intervalo dos nomes das chaves, como ter acesso concentrado a entidades de pessoas criadas recentemente. Neste caso, as chaves acedidas com frequência têm todas IDs mais elevados. O carregamento pode então concentrar-se num servidor do Datastore específico.
Em alternativa, para compreender a distribuição uniforme no espaço de chaves, considere usar strings aleatórias longas para os nomes das chaves. Isto é ilustrado no exemplo seguinte:
p1 = Person(key_name='t9P776g5kAecChuKW4JKCnh44uRvBDhU') p2 = Person(key_name='hCdVjL2jCzLqRnPdNNcPCAN8Rinug9kq') p3 = Person(key_name='PaV9fsXCdra7zCMkt7UX3THvFmu6xsUd') ...
Agora, as entidades Person criadas recentemente vão estar dispersas pelo espaço de chaves e em vários servidores. Isto pressupõe que existe um número suficientemente grande de entidades Person.
Antipadrão n.º 2: demasiados índices
No Datastore, uma atualização numa entidade leva à atualização de todos os índices definidos para esse tipo de entidade. Se uma aplicação usar muitos índices personalizados, uma atualização pode envolver dezenas, centenas ou até milhares de atualizações em tabelas de índices. Numa aplicação grande, uma utilização excessiva de índices personalizados pode resultar num aumento da carga no servidor e pode aumentar a latência para alcançar a consistência.
Na maioria dos casos, os índices personalizados são adicionados para suportar requisitos como o apoio ao cliente, a resolução de problemas ou as tarefas de análise de dados. O BigQuery é um motor de consultas extremamente escalável capaz de executar consultas ad hoc em grandes conjuntos de dados sem índices pré-criados. É mais adequado para exemplos de utilização, como apoio ao cliente, resolução de problemas ou análise de dados que requerem consultas complexas do que o Datastore.
Uma prática consiste em combinar o Datastore e o BigQuery para cumprir diferentes requisitos empresariais. Use o Datastore para o processamento de transações online (OLTP) necessário para a lógica da aplicação principal e use o BigQuery para o processamento analítico online (OLAP) para operações de back-end. Pode ser necessário implementar um fluxo de exportação de dados contínuo do Datastore para o BigQuery para mover os dados necessários para essas consultas.
Além de uma implementação alternativa para índices personalizados, outra recomendação é especificar explicitamente propriedades não indexadas (consulte Propriedades e tipos de valores). Por predefinição, o Datastore cria uma tabela de índice diferente para cada propriedade indexável de um tipo de entidade. Se tiver 100 propriedades num tipo, existem 100 tabelas de índice para esse tipo e 100 atualizações adicionais em cada atualização a uma entidade. Assim, uma prática recomendada é definir propriedades não indexadas sempre que possível, se não forem necessárias para uma condição de consulta.
Além de reduzir a possibilidade de ter tempos de consistência aumentados, estas otimizações de índice podem resultar numa redução bastante grande dos custos de armazenamento do Datastore numa aplicação grande que usa muito os índices.
Conclusão
A consistência eventual é um elemento essencial das bases de dados não relacionais que permite aos programadores encontrar um equilíbrio ideal entre escalabilidade, desempenho e consistência. É importante compreender como gerir o equilíbrio entre a consistência eventual e a forte para criar um modelo de dados ideal para a sua aplicação. No Datastore, a utilização de grupos de entidades e consultas de antecessores é a melhor forma de garantir uma consistência forte num âmbito de entidades. Se a sua aplicação não conseguir incorporar grupos de entidades devido às limitações descritas anteriormente, pode considerar outras opções, como usar consultas apenas de chaves ou o Memcache. Para aplicações grandes, aplique práticas recomendadas, como a utilização de IDs dispersos e a indexação reduzida, para diminuir o tempo necessário para a consistência. Também pode ser importante combinar o Datastore com o BigQuery para cumprir os requisitos empresariais de consultas complexas e reduzir a utilização de índices do Datastore na medida do possível.
Recursos adicionais
Os seguintes recursos fornecem mais informações sobre os tópicos abordados neste documento:
- Google App Engine: armazenar dados
- Vista geral do Datastore
- Blogue da Google Cloud Platform
- Cloud SQL
- Usar o App Engine Python com o Cloud SQL
- Bigtable: um sistema de armazenamento distribuído para dados estruturados
- Lançamento do SDK do App Engine 1.5.2
- Megastore: Providing Scalable, Highly Available Storage for Interactive Services
[1] Um grupo de entidades pode até ser formado especificando apenas uma chave da entidade raiz ou principal, sem armazenar as entidades reais da raiz ou principal, porque as funções do grupo de entidades são todas implementadas com base nas relações entre chaves.
[2] O limite suportado é uma atualização por segundo por grupo de entidades fora das transações ou uma transação por segundo por grupo de entidades. Se agregar várias atualizações numa transação, fica limitado a um tamanho máximo de transação de 10 MB e à taxa de gravação máxima do servidor do Datastore.