Ranking rapido e affidabile in Datastore
Classifica: un problema semplice, ma molto difficile
Tomoaki Suzuki (Figura 1), ingegnere capo di App Engine presso Applibot, sta cercando di risolvere il problema molto comune, ma molto difficile, che deve affrontare ogni grande servizio di gioco: il ranking.

Applibot è uno dei principali fornitori di applicazioni social in Giappone. La peculiarità dell'azienda è la sua vasta conoscenza ed esperienza nella creazione di servizi di giochi social super scalabili su Google App Engine, l'offerta Platform as a Service (PaaS) di Google. Sfruttando la potenza della piattaforma, Applibot ha avuto un buon successo nel cogliere opportunità commerciali nel mercato dei giochi social, non solo in Giappone, ma anche negli Stati Uniti. Applibot può certamente attestare il suo successo. Legend of the Cryptids (Figura 2), uno dei suoi titoli più importanti, ha raggiunto il primo posto nella categoria Giochi dell'App Store di Apple in Nord America a ottobre 2012. La serie The Legend ha registrato 4,7 milioni di download. Un altro titolo, Gang Road, ha raggiunto il primo posto nel ranking delle vendite totali dell'App Store Giappone a dicembre 2012.

Questi titoli sono stati in grado di scalare senza problemi e gestire il traffico in forte crescita. Applibot non ha dovuto faticare per creare cluster complessi di server virtuali o database sharded. Hanno sfruttato la potenza di App Engine e ottenuto scalabilità e disponibilità in modo efficiente.
Tuttavia, il ranking dei giocatori aggiornato non è un problema facile da risolvere, non per Tomoaki e probabilmente non per nessun altro sviluppatore, soprattutto su questa scala. I requisiti sono semplici:
- Il tuo gioco ha centinaia di migliaia (o più) di giocatori.
- Ogni volta che un giocatore combatte contro i nemici (o esegue altre attività), il suo punteggio cambia.
- Vuoi mostrare il ranking più recente del giocatore nella pagina di un portale web.
Come viene calcolato un ranking?

È facile ottenere un ranking, se non si prevede che sia anche scalabile e veloce. Ad esempio, puoi eseguire la seguente query:
SELECT count(key) FROM Players WHERE Score > YourScore
Questa query conteggia tutti i giocatori con un punteggio superiore al tuo (Figura 4). Vuoi eseguire questa query per ogni richiesta dalla pagina del portale? Quanto tempo ci vuole con un milione di giocatori?
Inizialmente Tomoaki ha implementato questo approccio, ma ogni risposta richiedeva alcuni secondi. Era troppo lento, troppo costoso e il rendimento peggiorava progressivamente con l'aumento della scala.

In seguito, Tomoaki ha provato a mantenere i dati del ranking in Memcache. Era veloce, ma non affidabile. Le voci Memcache potevano essere espulse in qualsiasi momento e, a volte, il servizio Memcache stesso non era disponibile. Con un servizio di ranking che dipendeva esclusivamente da chiavi e valori in memoria, era difficile mantenere la coerenza e la disponibilità.
Come soluzione temporanea, Tomoaki ha deciso di ridurre il livello di servizio. Invece di calcolare il ranking per ogni richiesta, ha configurato un'attività pianificata che scansionava e aggiornava il ranking di ogni giocatore una volta all'ora. In questo modo, le richieste dalla pagina del portale potrebbero ottenere il ranking del giocatore immediatamente, ma potrebbero essere vecchie fino a un'ora.
Alla fine, Tomoaki cercava un'implementazione del ranking persistente, transazionale, veloce e scalabile che potesse accettare 300 richieste di aggiornamento del punteggio al secondo e ottenere un ranking per ogni giocatore in centinaia di millisecondi. Per trovare una soluzione, Tomoaki si è rivolto a Kaz Sato, Solutions Architect (SA) e Technical Account Manager (TAM) del team della Google Cloud Platform, che è stato assegnato ad Applibot in base a un contratto di assistenza di livello premium.
Un modo rapido per risolvere i problemi
Molti clienti o partner di grandi dimensioni della Google Cloud Platform, come Applibot, sottoscrivono un contratto di assistenza di livello Premium. Con questo contratto di assistenza, oltre all'assistenza 24 ore su 24, 7 giorni su 7 del team di assistenza clienti di Cloud e all'assistenza aziendale del team di vendita di Cloud, Google assegna a ogni cliente un Technical Account Manager (TAM).
Un TAM rappresenta il cliente per il team di Google Engineering, che crea l'infrastruttura cloud effettiva. I TAM comprendono in dettaglio il sistema e l'architettura del cliente e, dopo aver segnalato una richiesta critica, utilizzano le loro conoscenze e la loro rete come rappresentanti dell'ingegneria di Google all'interno dell'azienda per risolvere il problema. I TAM possono riassegnazione i problemi ai Solutions Architect del team o ai Software Engineer del team della piattaforma cloud. L'assistenza di livello premium è la corsia preferenziale per trovare una soluzione con la piattaforma Google Cloud.
Kaz, il TAM che supporta Applibot, sapeva che il ranking era un problema classico, ma difficile da risolvere, per qualsiasi servizio distribuito scalabile. Ha iniziato a esaminare le implementazioni note per il ranking su Google Cloud Datastore e altri datastore NoSQL per trovare una soluzione che soddisfacesse i requisiti di Applibot.
Ricerca di un algoritmo O(log n)
La soluzione di query semplice richiede la scansione di tutti i giocatori con un punteggio più alto per conteggiare il ranking di un giocatore. La complessità temporale di questo algoritmo è O(n), ovvero il tempo necessario per l'esecuzione della query aumenta proporzionalmente al numero di giocatori. In pratica, ciò significa che l'algoritmo non è scalabile. Abbiamo invece bisogno di un algoritmo O(log n) o più veloce, in cui il tempo aumenterà solo in modo logaritmico con l'aumento del numero di giocatori.
Se hai mai frequentato un corso di informatica, potresti ricordare che gli algoritmi ad albero, come gli alberi binari, gli alberi rosso-neri o gli alberi B, possono avere una complessità temporale di O(log n) per trovare un elemento. Gli algoritmi ad albero possono essere utilizzati anche per calcolare un valore aggregato di un intervallo di elementi, ad esempio conteggio, massimo/minimo e media, memorizzando i valori aggregati in ogni nodo del ramo. Con questa tecnica è possibile implementare un algoritmo di ranking con prestazioni O(log n).
Kaz ha trovato un'implementazione open source di un algoritmo di ranking basato su albero per Datastore, scritto da un ingegnere di Google: la Google Code Jam Ranking Library.
Questa libreria basata su Python espone due metodi:
SetScoreper impostare il punteggio di un giocatore.FindRankper ottenere il ranking di un determinato punteggio.
Quando le coppie giocatore-punteggio vengono create e aggiornate con il metodo SetScore, la libreria di ranking di Code Jam crea un albero N-ario1. Ad esempio, prendiamo in considerazione un albero terziario che può conteggiare il numero di giocatori con punteggi compresi tra 0 e 80 (Figura 5). La libreria memorizza il nodo principale, che contiene tre numeri, come un'entità. Ogni numero corrisponde al numero di giocatori con punteggi rispettivamente negli intervalli 0-26, 27-53 e 54-80. Il nodo principale ha un nodo secondario per ogni intervallo, contenente a sua volta tre valori per i giocatori negli intervalli dell'intervallo secondario. La gerarchia richiede quattro livelli per memorizzare il numero di giocatori per 81 diversi valori del punteggio.
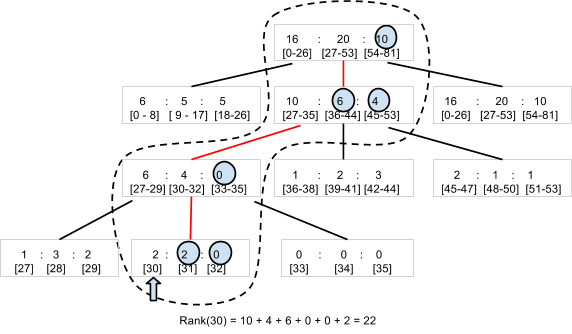
Per determinare il ranking di un giocatore con un punteggio di 30, la libreria deve leggere solo quattro entità, ovvero i nodi cerchiati dalla linea tratteggiata nel diagramma, per sommare il numero di giocatori con un punteggio superiore a 30. Con 22 giocatori "a destra" in quattro entità, il ranking del giocatore è 23°.
Allo stesso modo, una chiamata a SetScore deve aggiornare solo quattro entità. Anche se hai un numero elevato di punteggi diversi, l'accesso a Datastore aumenterà solo in O(log n) e non è influenzato dal numero di giocatori. In pratica, la libreria di ranking di Code Jam utilizza 100 (anziché 3) come numero predefinito di valori per nodo, quindi è necessario accedere solo a due (o tre, se l'intervallo di punteggi è superiore a 100.000) entità.
Kaz ha utilizzato il popolare strumento di test di carico Apache JMeter per eseguire un test di carico sulla libreria di ranking di Code Jam e ha confermato che la libreria risponde rapidamente. Sia SetScore che FindRank possono completare i loro job in centinaia di millisecondi utilizzando l'algoritmo ad albero N-ario che ha una complessità temporale di O(log n).
Gli aggiornamenti simultanei limitano la scalabilità
Tuttavia, durante i test di carico, Kaz ha rilevato una limitazione critica nella libreria di ranking di Code Jam. La sua scalabilità in termini di throughput degli aggiornamenti era piuttosto bassa. Quando ha aumentato il carico a tre aggiornamenti al secondo, la libreria ha iniziato a restituire errori di ripetizione della transazione. Era ovvio che la libreria non poteva soddisfare il requisito di Applibot di 300 aggiornamenti al secondo. Poteva gestire solo circa l'1% di questo throughput.
Perché? Il motivo è il costo per mantenere la coerenza dell'albero. In Datastore, devi utilizzare un gruppo di entità per garantire la elevata coerenza quando aggiorni più entità in una transazione. Consulta "Equilibrare la coerenza forte e quella eventuale con Google Cloud Datastore". La libreria di ranking di Code Jam utilizza un singolo gruppo di entità per contenere l'intero albero al fine di garantire la coerenza dei conteggi negli elementi dell'albero.
Tuttavia, un gruppo di entità in Datastore ha una limitazione delle prestazioni. Datastore supporta solo circa una transazione al secondo in un gruppo di entità. Inoltre, se lo stesso gruppo di entità viene modificato in transazioni concorrenti, è probabile che queste non vadano a buon fine e debbano essere ripetute. La libreria di ranking di Code Jam è fortemente coerente, transazionale e abbastanza veloce, ma non supporta un volume elevato di aggiornamenti simultanei.
Soluzione del team di Datastore: aggregazione dei job
Kaz ricordava che un ingegnere del software del team di Datastore aveva menzionato una tecnica per ottenere una velocità effettiva molto più elevata di un aggiornamento al secondo in un gruppo di entità. Ciò può essere ottenuto aggregando un batch di aggiornamenti in un'unica transazione anziché eseguire ogni aggiornamento come transazione separata. Tuttavia, poiché la transazione include un numero elevato di aggiornamenti, ogni transazione richiede più tempo, aumentando la possibilità di conflitti con le transazioni concorrenti.
In risposta alla richiesta di Kaz, il team di Datastore ha iniziato a discutere di questo problema e ci ha consigliato di prendere in considerazione l'utilizzo dell'aggregazione dei job, uno dei pattern di progettazione utilizzati con Megastore.
Megastore è il livello di archiviazione sottostante di Datastore e gestisce la coerenza e la transazionalità dei gruppi di entità. Il limite di un aggiornamento al secondo proviene da questo livello. Poiché Megastore è ampiamente utilizzato da vari servizi Google, gli ingegneri hanno raccolto e condiviso best practice e pattern di progettazione all'interno dell'azienda per creare un sistema scalabile e coerente con questo archivio dati NoSQL.
L'idea di base dell'aggregazione dei job è utilizzare un singolo thread per elaborare un batch di aggiornamenti. Poiché esiste un solo thread e una sola transazione aperta nel gruppo di entità, non si verificano errori di transazione dovuti ad aggiornamenti simultanei. Puoi trovare idee simili in altri prodotti di archiviazione come VoltDb e Redis.
Tuttavia, il pattern di aggregazione dei job presenta un svantaggio: utilizza un solo thread per aggregare tutti gli aggiornamenti e questo impone un limite alla velocità con cui può inviare gli aggiornamenti a Datastore. Pertanto, era importante determinare se l'aggregazione dei job poteva soddisfare il requisito di throughput di Applibot di 300 aggiornamenti al secondo.
Aggregazione dei job per coda pull
In base ai consigli del team di Datastore, Kaz ha scritto un codice di proof of concept (PoC) che combina il pattern di aggregazione dei job con la libreria di ranking di Code Jam. Il PoC è costituito dai seguenti componenti:
- Frontend: accetta le richieste
SetScoredegli utenti e le aggiunge come attività a una coda pull. - Coda pull: riceve e trattiene le richieste di aggiornamento
SetScoredal frontend. - Backend: esegue un ciclo infinito con un singolo thread che estrae le richieste di aggiornamento dalla coda ed esegue con la libreria di ranking di Code Jam.
Il PoC crea una coda pull, ovvero un tipo di coda di attività in App Engine che consente agli sviluppatori di implementare uno o più worker che utilizzano le attività aggiunte alla coda. L'istanza di backend ha un singolo thread in un loop infinito che continua a estrarre dalla coda il maggior numero possibile di attività (fino a 1000). Il thread passa ogni richiesta di aggiornamento alla libreria di ranking di Code Jam, che le esegue in blocco in una singola transazione. La transazione potrebbe essere aperta per un secondo o più, ma poiché esiste un singolo thread che gestisce la libreria e Datastore, non si verificano conflitti né problemi di modifica simultanea.
L'istanza di backend è definita come modulo, una funzionalità di App Engine che consente agli sviluppatori di definire un'istanza di applicazione con varie caratteristiche. In questo PoC, l'istanza di backend è definita come istanza con scalabilità manuale. È in esecuzione una sola istanza di questo tipo alla volta.
Kaz ha sottoposto il PoC a un test di carico utilizzando JMeter. Ha confermato che il PoC è stato in grado di elaborare 200 richieste SetScore al secondo, con batch di 500-600 aggiornamenti per transazione. L'aggregazione dei job funziona.
Suddivisione in parti della coda per prestazioni stabili
Ma presto Kaz ha trovato un altro problema. Mentre continuava a eseguire il test per diversi minuti, ha notato che il throughput della coda pull variava di volta in volta (Figura 6). Nello specifico, quando continuava ad aggiungere richieste alla coda con 200 attività al secondo per diversi minuti, la coda ha smesso improvvisamente di passare le attività al backend e la latenza di ogni attività è aumentata notevolmente.

Kaz ha consultato il team della coda di lavoro per scoprire il motivo. Secondo il team di Task Queue, si tratta di un comportamento noto per l'attuale implementazione della coda in modalità pull che dipende da Bigtable come livello di persistenza. Quando un tablet Bigtable diventa troppo grande, viene suddiviso in più tablet. Durante la suddivisione del tablet, le attività non vengono eseguite e ciò crea una fluttuazione delle prestazioni quando la coda riceve attività a una frequenza elevata. Il team di Task Queue si sta adoperando per migliorare queste caratteristiche di rendimento.
Michael Tang, un Solutions Architect, ha consigliato una soluzione alternativa che utilizza la suddivisione in parti della coda. Invece di utilizzare una sola coda, ha suggerito di distribuire il carico su più code. Ogni coda può essere archiviata su un server tablet Bigtable diverso per ridurre al minimo l'effetto di una suddivisione del tablet e mantenere un'elevata velocità di elaborazione delle attività. Mentre una coda sta elaborando una suddivisione, le altre code continuano a funzionare e lo sharding riduce il carico su ogni coda, quindi la suddivisione di un tablet avviene meno spesso.
Il ciclo di istanze di backend migliorato esegue il seguente algoritmo:
- Assegna in leasing
SetScoreattività da 10 code. - Chiama il metodo
SetScorescon le attività. - Elimina le attività in leasing dalle code.
Nel passaggio 1, ogni coda fornisce fino a 1000 attività, ognuna contenente il nome di un giocatore e un punteggio. Dopo aver aggregato tutte le coppie giocatore-punteggio in un dizionario, il passaggio 2 passa il batch di aggiornamenti al metodo SetScores della libreria di ranking di Code Jam, che apre una transazione per archiviarli in Datastore. Se non si è verificato alcun errore durante l'esecuzione del metodo, il passaggio 3 elimina le attività in leasing dalle code.
Se si verifica un errore o l'arresto anomalo del loop o dell'istanza di backend, le attività di aggiornamento rimangono nelle code delle attività, in modo che possano essere elaborate al riavvio dell'istanza. In un sistema di produzione, potresti avere un altro backend che agisce come watchdog in modalità di attesa, pronto a prendere il controllo in caso di guasto della prima istanza.
Soluzione proposta: esecuzione a 300 aggiornamenti al secondo in modo continuativo2
La Figura 7 mostra il risultato del test di carico dell'implementazione finale del PoC con lo sharding della coda. Riduce al minimo le fluttuazioni del rendimento nelle code e può supportare 300 aggiornamenti al secondo per diverse ore. In condizioni di carico normali, ogni aggiornamento viene applicato a Datastore entro pochi secondi dalla ricezione della richiesta.

Questa soluzione soddisfa tutti i requisiti originali di Applibot:
- Scalabile per gestire decine di migliaia di giocatori.
- Persistenti e coerenti in quanto tutti gli aggiornamenti vengono eseguiti nelle transazioni di Datastore.
- Abbastanza veloce da gestire 300 aggiornamenti al secondo.
Con i risultati dei test di carico e il codice PoC, Kaz ha presentato la soluzione a Tomoaki e ad altri ingegneri di Applibot. Tomoaki prevede di incorporare la soluzione nel proprio sistema di produzione, si aspetta di ridurre la latenza dell'aggiornamento delle informazioni sul ranking da un'ora a pochi secondi e spera di migliorare notevolmente l'esperienza utente.
Riepilogo dell'albero del ranking con aggregazione dei job
La soluzione proposta presenta diversi vantaggi e un solo svantaggio:
Vantaggi:
- Veloce: la chiamata
FindRankrichiede alcune centinaia di millisecondi o meno. - Veloce:
SetScoreinvia semplicemente un'attività, che viene elaborata dal backend in pochi secondi. - Coerenti e permanenti in Datastore.
- I ranking siano accurati.
- Scalabile per qualsiasi numero di giocatori.
Svantaggio:
- La velocità effettiva ha una limitazione (circa 300 aggiornamenti/sec con l'implementazione attuale).
Poiché questa soluzione utilizza il pattern Aggregazione di job, si basa su un singolo thread per aggregare tutti gli aggiornamenti. Sono necessari ulteriori interventi o complessità per raggiungere un throughput superiore a 300 aggiornamenti/sec con l'attuale potenza della CPU delle istanze App Engine e le prestazioni di Datastore.
Soluzione più scalabile con albero suddiviso
Se hai bisogno di una frequenza di aggiornamento ancora maggiore, potresti dover suddividere la struttura ad albero del ranking. Dovresti creare più implementazioni del sistema precedente: un insieme di code che gestiscono ciascuna un modulo di backend che aggiorna la propria struttura ad albero del ranking.
In generale, non è necessario né previsto il coordinamento degli alberi. Nel caso più semplice, ogni aggiornamento SetScore viene inviato in modo casuale a una coda. Con tre alberi di questo tipo, ciascuno con il proprio gruppo di entità Datastore e il proprio server di backend, il throughput di aggiornamento previsto sarebbe tre volte superiore. Il compromesso è che FindRank deve eseguire query su ogni albero di ranking per ottenere il ranking di un punteggio e poi sommare il ranking di ogni albero per trovare il ranking effettivo, il che richiederà un po' più di tempo. Il tempo di query per FindRank può essere ridotto notevolmente mantenendo le entità in Memcache.
Questo è simile al noto approccio che utilizza i contatori suddivisi in parti: ogni contatore viene incrementato in modo indipendente e la somma totale viene calcolata solo quando è necessaria al cliente.
Ad esempio, con tre alberi, FindRank(865) potrebbe trovare i tre ranking 124, 183 e 156, a indicare che ogni albero contiene il rispettivo numero di punteggi superiore a 865. Il numero totale di punteggi calcolati superiori a 865 è quindi 124 + 183 + 156 = 463.
Questo approccio non funziona per tutti i tipi di algoritmi distribuiti, ma poiché il ranking è fondamentalmente un problema di conteggio commutativo, dovrebbe funzionare per i problemi di ranking di grandi volumi.
Soluzioni più scalabili con approcci approssimativi
Se la tua applicazione richiede scalabilità più che precisione dei ranking e può tollerare un certo livello di imprecisione o approssimazione, puoi scegliere approcci stocastici come:
- Bucket con query globale
- Metodo di conteggio con perdita
- Streaming frugale
Questi approcci approssimativi sono tutte varianti di un'idea: come comprimere lo spazio di archiviazione per le informazioni sul ranking consentendo un certo degrado dell'accuratezza del ranking?
I bucket con query globali sono una soluzione alternativa proposta dal team di Datastore e da Alex Amies, un TAM. Alex ha implementato un PoC basato sull'idea del team di Datastore e ha condotto un'analisi approfondita delle prestazioni. Ha dimostrato che i bucket con query globali sono una soluzione di ranking scalabile con un degrado minimo dell'accuratezza del ranking e potrebbero essere adatti per applicazioni che richiedono un throughput superiore alla libreria di ranking di Code Jam. Per una descrizione dettagliata e i risultati dei test, consulta l'appendice.
Il metodo di conteggio con perdita e lo streaming parsimonioso sono i cosiddetti algoritmi online e algoritmi di streaming in cui puoi utilizzare uno spazio di archiviazione in memoria molto ridotto per calcolare una stima stocastica dei migliori giocatori da uno stream di coppie giocatore-punteggio. Questi algoritmi sono adatti ad applicazioni che richiedono latenza molto bassa e larghezza di banda molto elevata, ad esempio migliaia di aggiornamenti al secondo, con una precisione e una copertura dei risultati del ranking più limitate. Ad esempio, se vuoi avere una dashboard in tempo reale che mostri le 100 parole chiave più cercate in uno stream di social network, questi algoritmi possono aiutarti.
Conclusione
Il ranking è un problema classico, ma difficile da risolvere, se richiedi che l'algoritmo sia scalabile, coerente e veloce. In questo articolo abbiamo descritto in che modo i TAM di Google hanno collaborato a stretto contatto con il cliente e con i team di ingegneria di Google per affrontare la sfida e fornire una soluzione che potesse ridurre la latenza dell'aggiornamento del ranking da un'ora a pochi secondi. I pattern di progettazione scoperti durante il processo, ovvero l'aggregazione dei job e lo sharding delle code, potrebbero essere applicati anche a problemi comuni in altri design di sistema basati su Datastore che richiedono centinaia di aggiornamenti al secondo con una elevata coerenza.
Note
- La libreria di ranking di Code Jam accetta un parametro chiamato "fattore di ramificazione" che specifica il numero di punteggi che ogni entità conterrà. Per impostazione predefinita, la libreria utilizza 100 come parametro. In questo caso, i punteggi compresi tra 0 e 9999 verranno memorizzati in 100 entità come elementi secondari del nodo principale. Se devi gestire una gamma più ampia di punteggi, puoi modificare il fattore di ramificazione impostandolo su un valore più alto per ottimizzare il numero di accessi alle entità.
- Tutti i dati sul rendimento descritti in questo articolo sono valori campionati di riferimento e non garantiscono alcun rendimento assoluto di App Engine, Datastore o altri servizi.
Appendice: bucket con soluzione di query globale
Come accennato nella sezione Come ottenere un ranking, è costoso eseguire query sul database per ogni richiesta di ranking. Questo approccio alternativo ottiene periodicamente il conteggio di tutti i punteggi, calcola il ranking dei punteggi selezionati e fornisce questi punti dati da utilizzare per il calcolo dei ranking per determinati giocatori. L'intervallo totale dei punteggi è suddiviso in "bucket". Ogni bucket è caratterizzato da un sottointervallo di punteggi e dal numero di giocatori con punteggi in quell'intervallo. Da questi dati, è possibile trovare il ranking di qualsiasi punteggio con una buona approssimazione. Questi bucket sono simili al nodo di primo livello dell'albero del ranking, ma anziché scendere a nodi più dettagliati, questo algoritmo esegue semplicemente l'interpolazione all'interno di un bucket.
Il recupero del ranking da parte degli utenti dal frontend è disaccoppiato dal calcolo del ranking nei bucket nel backend per ridurre al minimo il tempo necessario per trovare un ranking. Quando viene richiesto il ranking di un giocatore, viene trovato il bucket appropriato in base al suo punteggio. Il bucket include un limite di ranking superiore e un conteggio dei giocatori al suo interno. L'interpolazione lineare all'interno dei bucket viene utilizzata per stimare il ranking dei giocatori all'interno dei bucket. Nei nostri test, siamo riusciti a ottenere il ranking di un giocatore in modo coerente in meno di 400 millisecondi per un round trip HTTP completo. Il costo del metodo FindRank non dipende dal numero di giocatori nella popolazione.
Calcolo del ranking per un determinato punteggio

Il conteggio e il ranking più alto (ovvero il ranking più alto possibile in questo bucket) vengono registrati per ogni bucket. Per i punteggi compresi tra i limiti di punteggio basso e alto in un bucket, utilizziamo l'interpolazione lineare per stimare il ranking. Ad esempio, se il giocatore ha un punteggio di 60, esaminiamo il bucket [50, 74], utilizzando il conteggio (numero di giocatori/punteggi nel bucket) (42) e il ranking più alto (5) per calcolare il ranking del giocatore con questa formula:
rank = 5 + (74 - 60)*42/(74 - 50) = 30
Calcolo del conteggio e dell'intervallo per ogni bucket
In background, utilizzando un job cron o una coda di attività, i conteggi per ogni bucket vengono calcolati e salvati iterando su tutti i bucket. La chiamiamo query globale perché calcola i parametri necessari per stimare i ranking esaminando i punteggi di tutti i giocatori. Di seguito è riportato un codice Python di esempio per eseguire questa operazione in base ai punteggi nell'intervallo [low_score, high_score] per ogni bucket.
next_upper_rank = 1 for b in buckets: count = GetCountInRange(b.low_score, b.high_score) b.count = count b.upper_rank = next_upper_rank b.put() next_upper_rank += count
Il metodo GetCountInRange() conteggia ogni giocatore con punteggi compresi nell'intervallo coperto dal bucket. Poiché Datastore gestisce un indice ordinato dei punteggi dei giocatori, questo conteggio può essere calcolato in modo efficiente.
Quando dobbiamo trovare il ranking di un determinato giocatore, possiamo utilizzare il codice mostrato di seguito.
b = GetBucketByScore(score) rank = RankInBucket(b, score) return rank + b.upper_rank - 1
Il metodo GetBucketByScore(score) recupera il bucket contenente il punteggio specificato. Il metodo RankInBucket() esegue una stima del ranking all'interno del bucket. Il ranking del giocatore è la somma del ranking più alto del bucket e del ranking all'interno del bucket specifico che racchiude il punteggio del giocatore. Dobbiamo sottrarre 1 dal risultato perché il ranking più alto del bucket principale sarà 1 e anche il ranking del giocatore migliore all'interno di un bucket specifico sarà 1.
I bucket vengono archiviati sia in Datastore che in Memcache. Per calcolare il ranking, leggi i bucket da Memcache (o da Datastore, se in Memcache mancano i dati). Nella nostra implementazione di questo algoritmo, abbiamo utilizzato la libreria client NDB di Python che utilizza Memcache per memorizzare nella cache i dati archiviati in Datastore.
Poiché i bucket (o altri metodi) vengono utilizzati per rappresentare i dati in modo compatto, i ranking prodotti non sono esatti. I ranking all'interno di un bucket vengono approssimati con interpolazione lineare. Per una migliore approssimazione all'interno del bucket, è possibile utilizzare altri metodi di interpolazione più precisi, ad esempio una formula di regressione.
Costo
Il costo per trovare un ranking e aggiornare il punteggio di un giocatore è O(1), ovvero indipendente dal numero di giocatori.
Il costo del job di query globale è O(Players) * frequenza di aggiornamento della cache.
Il costo del calcolo dei dati del bucket nel job di backend è correlato anche al numero di bucket, poiché viene eseguita una query di conteggio per ogni bucket. La query count è ottimizzata per l'utilizzo di una query solo con chiavi, ma anche così, l'elenco completo delle chiavi deve essere recuperato.
Vantaggi
Questo metodo è molto veloce sia per aggiornare il punteggio di un giocatore sia per trovare il ranking di un punteggio. Anche se i risultati si basano su un job in background, se il punteggio di un giocatore cambia, il ranking mostrerà immediatamente una variazione nella direzione appropriata. Questo è dovuto all'interpolazione utilizzata all'interno del bucket.
Poiché il calcolo del ranking più alto di un bucket viene eseguito in background con un job pianificato, i punteggi del giocatore possono essere aggiornati senza dover mantenere sincronizzati i dati del bucket. Pertanto, la produttività dell'aggiornamento dei punteggi dei giocatori non è limitata da questo approccio.
Svantaggi
È necessario tenere conto del tempo necessario per conteggiare tutti i punteggi dei giocatori, calcolare i ranking globali e aggiornare i bucket. Nei nostri test, con una popolazione di dieci milioni di giocatori, il tempo è stato di 8 minuti e 34 secondi per il nostro sistema di test su App Engine. Questo è più veloce delle ore necessarie per calcolare il ranking di ogni giocatore, ma il compromesso è l'approssimazione dei punteggi all'interno di ogni bucket. Al contrario, l'algoritmo ad albero calcola gli "intervalli dei bucket" (il nodo principale dell'albero) in modo incrementale ogni pochi secondi, ma ha una maggiore complessità di implementazione e un throughput limitato.
In tutti i casi, il tempo di FindRank dipende anche dal recupero rapido dei dati (bucket o nodi dell'albero) da Memcache. Se i dati vengono espulsi da Memcache, devono essere recuperati di nuovo da Datastore e memorizzati nuovamente nella cache per le richieste FindRank successive.
Accuratezza
L'accuratezza del metodo dei bucket dipende dal numero di bucket, dal ranking del giocatore e dalla distribuzione dei punteggi. La Figura 9 mostra i risultati del nostro studio sull'accuratezza delle stime del ranking con diversi numeri di bucket.

I test sono stati eseguiti su una popolazione di 10.000 giocatori con punteggi distribuiti uniformemente nell'intervallo [0-9999]. L'errore relativo è di circa l'1% anche per soli 5 bucket.
L'accuratezza diminuisce per i giocatori con un ranking elevato, soprattutto perché la legge dei grandi numeri non si applica quando si esaminano solo i punteggi migliori. In molti casi, potrebbe essere consigliabile utilizzare un algoritmo più preciso per mantenere i ranghi dei mille o duemila giocatori con il punteggio più alto. Il problema è notevolmente ridotto, poiché ci sono meno giocatori da monitorare e la frequenza aggregata degli aggiornamenti è di conseguenza inferiore.
Nel test precedente, l'utilizzo di numeri casuali distribuiti uniformemente, in cui la funzione di distribuzione cumulativa è lineare, favorisce l'utilizzo dell'interpolazione lineare all'interno del bucket, ma l'interpolazione all'interno dei bucket funziona bene per qualsiasi distribuzione densa di punteggi. La Figura 10 mostra il ranking stimato e quello effettivo per una distribuzione approssimativamente normale dei punteggi.

In questo esperimento è stata utilizzata una popolazione di 100 giocatori per testare l'accuratezza con un piccolo set di dati. Ogni punteggio è stato generato calcolando la media di 4 numeri casuali compresi tra 0 e 100, che approssima approssimativamente una distribuzione normale dei punteggi. Il ranking stimato è stato calcolato utilizzando il metodo di query globale con interpolazione lineare su 10 bucket. È possibile notare che anche per set di dati molto piccoli e distribuzioni non uniformi i risultati sono molto buoni.