Classement rapide et fiable dans Datastore
Le classement : un défi à la fois simple et compliqué
Tomoaki Suzuki (figure 1), ingénieur en chef d'App Engine chez Applibot, travaille à la résolution d'un problème aussi classique que compliqué, commun à tous les grands services de jeux : le classement des joueurs.

Applibot est l'un des principaux fournisseurs d'applications de réseau social au Japon. Le caractère unique de l'entreprise réside dans son expérience et ses connaissances poussées en matière de création de services de jeux sociaux extrêmement évolutifs sur Google App Engine, l'offre PaaS (Platform as a Service) de Google. En exploitant la puissance de la plate-forme, Applibot a pu saisir des opportunités commerciales sur le marché des jeux sociaux au Japon, mais aussi aux États-Unis. Applibot a rencontré un franc succès. Legend of the Cryptids (Figure 2), l'un de leurs plus gros titres, a été classé n° 1 en Amérique du Nord dans la catégorie jeux sur l'AppStore d'Apple en octobre 2012. La série Legend a enregistré 4,7 millions de téléchargements. Un autre de leurs jeux, Gang Road, a atteint la première place du classement des ventes totales de l'AppStore japonais en décembre 2012.

Ces jeux ont pu évoluer de manière fluide et gérer un trafic en forte croissance. Applibot a pu facilement créer des clusters complexes de serveurs virtuels ou de bases de données partitionnées. La puissance d'App Engine a été exploitée dans le but d'atteindre efficacement l'évolutivité et la disponibilité.
Toutefois, la mise à jour du classement des joueurs n'est pas un problème facile à résoudre, ni pour Tomoaki, ni probablement pour aucun développeur, en particulier à cette échelle. Les exigences sont simples :
- Votre jeu a des centaines de milliers (ou plus) de joueurs.
- Chaque fois qu'un joueur combat des ennemis (ou effectue d'autres activités), son score évolue.
- Vous souhaitez afficher le classement actuel du joueur sur une page de portail Web.
Comment classer un joueur ?
Il est facile d'obtenir un classement. La tâche se complique si on souhaite que ce classement soit également rapide et évolutif. Par exemple, vous pouvez exécuter la requête suivante :
SELECT count(key) FROM Players WHERE Score > YourScore
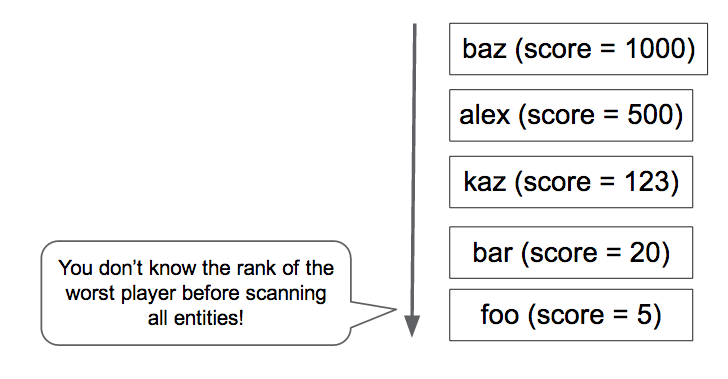
Cette requête décompte tous les joueurs avec un score plus élevé que le vôtre (Figure 4). Or, souhaitez-vous exécuter cette requête pour chaque requête de la page du portail ? Combien de temps cette opération prend-elle quand vous avez un million de joueurs ?
Tomoaki a commencé par mettre en œuvre cette approche, mais chaque réponse mettait quelques secondes à s'afficher. Cette opération était trop lente, trop coûteuse et de moins en moins efficace à mesure que le nombre de joueurs augmentait.
Ensuite, Tomoaki a tenté de conserver les données de classement dans Memcache. Une solution rapide, mais pas fiable. Les entrées Memcache peuvent être supprimées à tout moment et le service Memcache n'est parfois pas disponible. Avec un service de classement dépendant uniquement de valeurs de clé en mémoire, il était difficile de maintenir la cohérence et la disponibilité.
Afin de résoudre temporairement ce problème, Tomoaki a décidé de dégrader le niveau de service. Plutôt que de calculer le classement de chaque requête, il a défini une tâche planifiée permettant d'analyser et de mettre à jour le classement de chaque joueur une fois par heure. De cette manière, les requêtes de la page du portail pouvaient obtenir le classement du joueur instantanément, mais celui-ci pouvait rester identique pendant une heure.
Au final, Tomoaki souhaitait implémenter une solution de classement persistante, transactionnelle, rapide et évolutive pouvant accepter 300 requêtes de mise à jour de score par seconde et obtenir un classement de chaque joueur en centaines de millisecondes. Pour y arriver, Tomoaki a fait appel à Kaz Sato, architecte de solutions et responsable de compte technique au sein de l'équipe de Google Cloud Platform. Il a ensuite placé Applibot en vertu d'un contrat de support de niveau supérieur.
Un moyen rapide de résoudre les problèmes
Les clients ou partenaires importants de Google Cloud Platform, tels qu'Applibot, sont nombreux à souscrire à un contrat de support de niveau supérieur. Ce contrat offre un support 24 heures sur 24 et 7 jours sur 7, assuré par l'équipe du support client Cloud et un support commercial offert par l'équipe Cloud Sales. Google attribue également un responsable de compte technique à chaque client.
Les responsables de compte technique représentent le client auprès des ingénieurs de Google, ce qui permet de construire l'infrastructure cloud réelle. Les responsables de compte technique possèdent une connaissance approfondie du système et de l'architecture du client. Dès qu'ils repèrent un cas critique, ils tentent de résoudre le problème à l'aide de leurs connaissances et de leur réseau en tant que représentant des ingénieurs de Google dans l'entreprise. Les responsables de compte technique peuvent faire remonter les problèmes aux architectes de solutions de l'équipe ou aux ingénieurs logiciel de l'équipe Cloud Platform. Le support de niveau supérieur représente la voie rapide permettant de trouver une solution à l'aide de Google Cloud Platform.
Kaz, le responsable de compte technique pour Applibot, savait que le classement constituait un problème classique, mais difficile à résoudre, pour tout service distribué évolutif. Il a commencé par examiner les implémentations connues liées au classement sur Google Cloud Datastore et d'autres datastores NoSQL en vue de trouver une solution répondant aux exigences d'Applibot.
Recherche d'un algorithme O(log n)
La solution de requête simple nécessite d'analyser tous les joueurs avec un score élevé afin d'établir leur classement. La complexité temporelle de cet algorithme correspond à O(n). Cela signifie que le temps requis pour l'exécution de la requête augmente proportionnellement au nombre de joueurs. En pratique, cela signifie que l'algorithme n'est pas évolutif. À la place, nous avons besoin d'un algorithme O(log n) ou d'un algorithme plus rapide, dans lequel le temps n'augmentera que de manière logarithmique en fonction du nombre de joueurs.
Si vous avez des connaissances en informatique, n'oubliez pas que les algorithmes en arbre, tels que les arbres binaires, les arbres bicolores ou les arbres B, peuvent fonctionner avec une complexité de temps O(log n) pour la recherche d'un élément. Les algorithmes en arbre peuvent également servir à calculer la valeur cumulée d'une plage d'éléments, tels que le décompte, le maximum/minimum et la moyenne en conservant les valeurs cumulées sur chaque nœud de branche. Ainsi, cette technique vous permet de mettre en œuvre un algorithme de classement avec des performances O(log n).
Kaz a trouvé une mise en œuvre Open source d'un algorithme de classement basé sur des arbres pour Datastore, écrite par un ingénieur de Google : la bibliothèque de classement Google Code Jam.
Cette bibliothèque basée sur Python expose les deux méthodes suivantes :
SetScorepour définir le score d'un joueur.FindRankpour obtenir le classement d'un score donné.
À mesure que les paires joueur/score sont créées et mises à jour avec la méthode SetScore, la bibliothèque de classement Code Jam crée un arbre N-aire1. Prenons comme exemple un arbre tertiaire pouvant compter le nombre de joueurs avec des scores compris entre 0 et 80 (Figure 5). La bibliothèque stocke le nœud racine, qui contient trois nombres, en tant qu'une seule entité. Chaque nombre correspond au nombre de joueurs avec des scores correspondant respectivement aux sous-catégories 0 - 26, 27 - 53 et 54 - 80. Le nœud racine possède un nœud enfant pour chaque plage, contenant trois valeurs pour les joueurs dans les sous-plages de la sous-plage. La hiérarchie nécessite quatre niveaux pour stocker le nombre de joueurs pour 81 valeurs de score différentes.
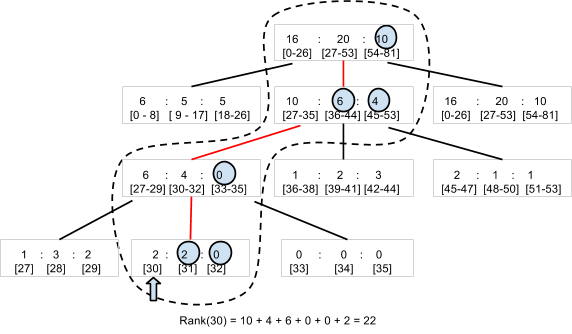
Pour déterminer le classement d'un joueur dont le score est égal à 30, la bibliothèque n'a besoin que de lire quatre entités (les nœuds entourés par la ligne pointillée dans le diagramme) pour totaliser le nombre de joueurs dont le score est supérieur à 30. Avec 22 joueurs "à droite" dans les quatre entités, le joueur est classé 23 ème.
De même, un appel SetScore n'a besoin que de mettre à jour quatre entités. Même si vous avez un grand nombre de scores différents, l'accès à Datascore n'augmentera qu'à O(log n) et n'est pas affecté par le nombre de joueurs. En pratique, la bibliothèque de classement Code Jam utilise 100 (au lieu de 3) comme nombre par défaut de valeurs par nœud. Par conséquent, seules deux (ou trois, si la plage de scores est supérieure à 100 000) entités doivent être accessibles.
Kaz a utilisé l'outil populaire Apache JMeter pour effectuer un test de charge sur la bibliothèque de classement Code Jam et a pu confirmer la rapidité de son taux de réponse. SetScore et FindRank peuvent terminer leurs tâches en quelques centaines de millisecondes à l'aide de l'algorithme en arbre N-aire, qui fonctionne avec une complexité de temps O(log n).
L'évolutivité est limitée par les mises à jour simultanées
Toutefois, lors de ces tests de charge, Kaz a découvert une limite critique liée à la bibliothèque de classement Code Jam. Son évolutivité en termes de débit de mise à jour s'est avérée assez faible. Lorsqu'il a augmenté la charge à trois mises à jour par seconde, la bibliothèque a commencé à renvoyer des erreurs de tentative de transaction. Il était évident que la bibliothèque n'était pas apte à satisfaire les exigences d'Applibot à raison de 300 mises à jour par seconde. Elle n'était capable de traiter qu'environ 1 % de ce débit.
Pourquoi ? En raison du coût de maintenance de la cohérence de l'arbre. Dans Datastore, vous devez utiliser un groupe d'entités pour garantir une cohérence élevée lors de la mise à jour de plusieurs entités dans une transaction. Pour en savoir plus, consultez la page Équilibrer la cohérence forte et la cohérence à terme avec Google Cloud Datastore. La bibliothèque de classement Code Jam exploite un seul groupe d'entités pour l'arbre entier afin de garantir la cohérence des décomptes dans les éléments de l'arbre.
Toutefois, un groupe d'entités dans Datastore est limité au niveau de ses performances. Datastore n'accepte qu'environ une transaction par seconde sur un groupe d'entités. De plus, si le même groupe d'entités est modifié dans des transactions simultanées, elles risquent d'échouer et doivent être relancées. La bibliothèque de classement Code Jam est très cohérente, transactionnelle et suffisamment rapide, mais elle n'est pas compatible avec un grand nombre de mises à jour simultanées.
Solution proposée par l'équipe Datastore : Job Aggregation
Kaz s'est souvenu d'une technique mentionnée par un ingénieur logiciel de l'équipe Datastore, qui permettrait d'obtenir un débit beaucoup plus élevé qu'une mise à jour par seconde sur un groupe d'entités. Pour arriver à ce résultat, il suffirait de cumuler un lot de mises à jour dans une transaction, plutôt que d'exécuter chaque mise à jour en tant que transaction séparée. Toutefois, comme la transaction comprend un grand nombre de mises à jour, chaque transaction prend plus de temps à s'effectuer, ce qui augmente le risque de conflit entre les transactions simultanées.
En réponse à la requête de Kaz, l'équipe Datastore a commencé à réfléchir au problème et nous a conseillé Job Aggregation (cumul des tâches), l'un des modèles de conception utilisés avec Megastore.
Megastore est la couche de stockage sous-jacente de Datastore et gère la cohérence et la transactionnalité des groupes d'entités. Cette couche est à l'origine de la limite d'une mise à jour par seconde. Megastore étant largement utilisée par divers services Google, les ingénieurs ont collecté et partagé les bonnes pratiques et modèles de conception au sein de l'entreprise afin de créer un système évolutif et cohérent avec ce datastore NoSQL.
L'idée de base de Job Aggregation consiste à utiliser un seul thread pour traiter un lot de mises à jour. Avec un seul thread et une seule transaction ouverte sur le groupe d'entités, il n'y a pas de risque d'échec de transaction causé par les mises à jour simultanées. Vous pouvez trouver des idées du même type dans d'autres produits de stockage tels que VoltDb et Redis.
Toutefois, le modèle Job Aggregation présente un inconvénient : il utilise un seul thread pour le cumul de toutes les mises à jour, ce qui impose une limite à la rapidité avec laquelle il peut envoyer les mises à jour à Datastore. Par conséquent, il était important de déterminer si Job Aggregation pouvait satisfaire les exigences de débit d'Applibot, à savoir 300 mises à jour par seconde.
Job Aggregation par file d'attente de retrait
Sur les conseils de l'équipe Datastore, Kaz a écrit un code de test de faisabilité, combinant le modèle Job Aggregation avec la bibliothèque de classement Code Jam. La démonstration de faisabilité comprend les composants suivants :
- Interface : accepte les requêtes
SetScoredes utilisateurs et les ajoute en tant que tâches à une file d'attente de retrait. - File d'attente de retrait : reçoit et conserve les requêtes de mise à jour
SetScoreprovenant de l'interface. - Backend : exécute une boucle infinie avec un seul thread qui retire les requêtes de mise à jour de la file d'attente et les exécute avec la bibliothèque de classement Code Jam.
La démonstration de faisabilité crée une file d'attente de retrait, qui consiste en une sorte de file d'attente de tâches dans App Engine, permettant aux développeurs d'implémenter un ou plusieurs nœuds de calcul qui consomment les tâches ajoutées à la file d'attente. L'instance backend comporte un seul thread dans une boucle infinie, qui extrait autant de tâches que possible (jusqu'à 1 000) de la file d'attente. Le thread transmet chaque demande de mise à jour à la bibliothèque de classement Code Jam, qui les exécute en tant que lot dans une transaction unique. La transaction peut être ouverte pendant une seconde ou plus. Toutefois, comme il n'y a qu'un seul thread qui gère la bibliothèque et Datastore, il n'y a pas de risque de conflit, ni de problème de modification simultanée.
L'instance backend est définie en tant que module, une fonctionnalité App Engine qui permet aux développeurs de définir une instance d'application avec des caractéristiques diverses. Dans ce test de faisabilité, l'instance backend est définie en tant qu'instance de scaling manuelle. Une seule instance de ce type est en cours d'exécution à un moment donné.
Kaz a testé la faisabilité en termes de charge à l'aide de JMeter. Il a confirmé que ce test était en mesure de traiter 200 requêtes SetScore par seconde, avec des lots de 500 à 600 mises à jour par transaction. La solution Job Aggregation semble fonctionner.
Partitionnement de la file d'attente pour des performances stables
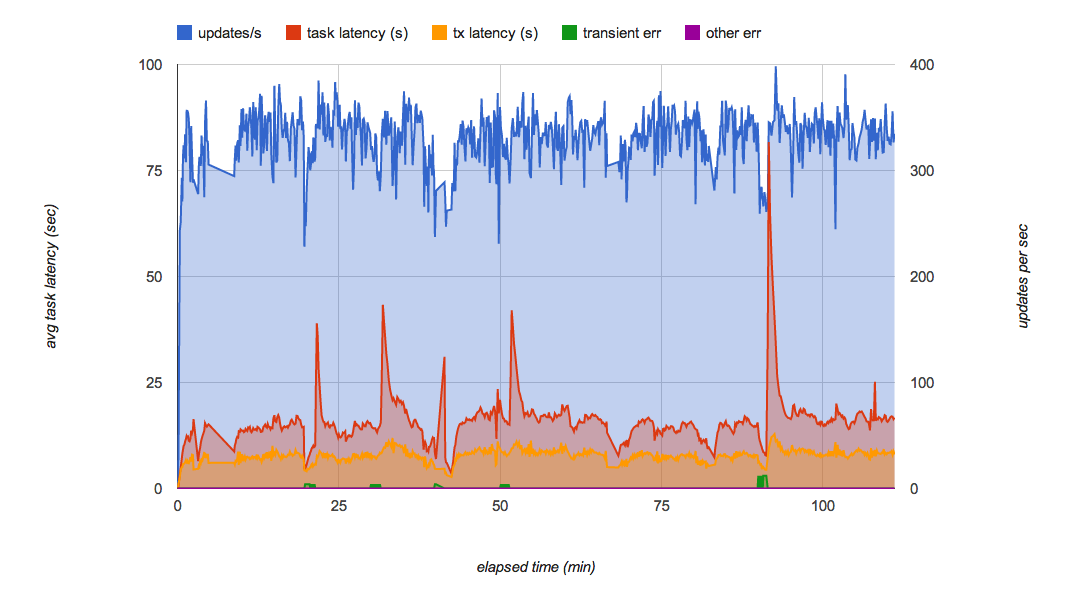
Très vite, Kaz a rencontré un nouveau problème. Alors que le test s'exécutait depuis plusieurs minutes, il a constaté des fluctuations intermittentes du débit de la file d'attente de retrait (Figure 6). Plus particulièrement, alors qu'il continuait à ajouter des requêtes dans la file d'attente (jusqu'à atteindre 200 tâches par seconde pendant plusieurs minutes), la file d'attente a soudainement cessé de transmettre des tâches au backend et la latence pour chaque tâche a considérablement augmenté.
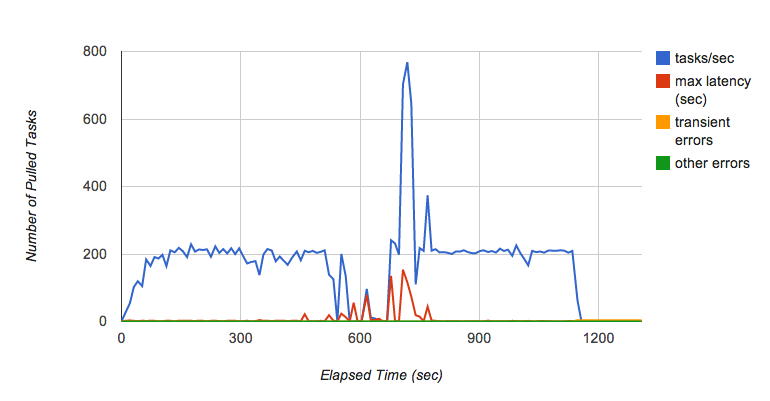
Kaz a contacté l'équipe de la file d'attente de tâches pour en savoir plus sur ce phénomène. Selon elle, il s'agit d'un comportement connu concernant la mise en œuvre actuelle de la file d'attente de retrait, qui dépend de Bigtable en tant que couche de persistance. Quand un tablet Bigtable devient trop gros, il est divisé en plusieurs tablets. Lors de la division du tablet, les tâches ne sont pas distribuées, ce qui crée une fluctuation des performances lorsque la file d'attente reçoit des tâches à un débit élevé. L'équipe de la file d'attente de tâches travaille à l'amélioration de ces performances.
L'architecte de solutions Michael Tang a recommandé d'utiliser le partitionnement de la file d'attente. Au lieu d'utiliser une seule file d'attente, il a suggéré de répartir la charge sur plusieurs files d'attente. Chaque file d'attente peut être stockée sur un serveur de tablet Bigtable différent afin de minimiser les effets du fractionnement des tablets et de maintenir un taux de traitement de tâches élevé. Lorsqu'une file d'attente est en train de traiter un fractionnement, d'autres files d'attente continuent de fonctionner et le partitionnement diminue la charge sur chaque file d'attente. Ainsi, l'opération de fractionnement d'un tablet est moins fréquente.
La boucle d'instance backend améliorée exécute l'algorithme suivant :
- Location des tâches
SetScoreà partir de 10 files d'attente (bail de tâches) - Appel de la méthode
SetScoresavec les tâches - Suppression des tâches louées des files d'attente
À l'étape 1, chaque file d'attente fournit jusqu'à 1 000 tâches, chacune contenant un nom de joueur et un score. Après l'agrégation de toutes les paires joueur-score dans un dictionnaire, l'étape 2 consiste à transmettre le lot de mises à jour à la méthode SetScores de la bibliothèque de classement Code Jam, qui ouvre une transaction permettant de les stocker dans Datastore. S'il n'y a pas eu d'erreur lors de l'exécution de la méthode, l'étape 3 supprime les tâches louées des files d'attente.
S'il n'y a pas eu d'erreur ou d'arrêt inattendus de la boucle ou de l'instance backend, les tâches de mise à jour restent dans les files d'attente afin qu'elles puissent être traitées lors du redémarrage de l'instance. Dans un système de production, il est possible d'avoir un autre backend en tant que backend watchdog de secours, prêt à prendre le relais en cas d'échec de la première instance.
La solution proposée permet d'exécuter 300 mises à jour par seconde de façon soutenue2.
La figure 7 illustre les résultats des tests de charge du test de faisabilité final avec le partitionnement de la file d'attente. Ce test minimise de manière efficace les fluctuations de performances dans les files d'attente et peut gérer 300 mises à jour par seconde pendant plusieurs heures. En situation de charge habituelle, chaque mise à jour est appliquée à Datastore dans les secondes suivant la réception de la requête.
Cette solution répond à toutes les exigences d'origine d'Applibot :
- évolutive, pour gérer des dizaines de milliers de joueurs ;
- persistante et cohérente, car toutes les mises à jour sont exécutées dans des transactions Datastore ;
- suffisamment rapide pour gérer 300 mises à jour par seconde.
Kaz a présenté cette solution à Tomoaki et à d'autres ingénieurs d'Applibot, accompagnée des tests de charge et du code des tests de faisabilité. Tomoaki envisage d'intégrer la solution dans son système de production, en espérant réduire le délai de mise à jour des informations de classement d'une heure à quelques secondes et améliorer considérablement l'expérience utilisateur.
Résumé de l'arbre de classement avec Job Aggregation
La solution proposée présente les avantages et l'inconvénient suivants :
Avantages :
- Rapide : l'appel
FindRanks'effectue en quelques centaines de millisecondes ou moins. - Rapide :
SetScorene fait qu'envoyer les tâches, qui sont traitées par le backend en quelques secondes. - Fortement cohérente et persistante dans Datastore.
- Exactitude des classements.
- Évolutive quel que soit le nombre de joueurs.
Inconvénient :
- Le débit a une limite (environ 300 mises à jour/s avec la mise en œuvre actuelle).
Comme cette solution utilise le modèle Job Aggregation, elle repose sur un seul thread pour le cumul de toutes les mises à jour. Une tâche ou une complexité supplémentaire est nécessaire pour atteindre un débit supérieur à 300 mises à jour/s avec la puissance de processeur actuelle des instances App Engine et des performances Datastore.
Une solution plus évolutive avec un arbre partitionné
Si vous avez besoin d'un taux de mise à jour encore plus élevé, vous devrez peut-être partager l'arbre de classement. Ainsi, vous pourrez créer plusieurs mises en œuvre du système ci-dessus : un ensemble de files d'attente, chacune gérant un module backend qui met à jour son propre arbre de classement.
En général, la coordination des arbres n'est ni requise, ni attendue. Dans le scénario le plus simple, chaque mise à jour SetScore est envoyée de manière aléatoire dans une file d'attente. Avec trois de ces arbres, chacun contenant son propre groupe d'entités Datastore et son serveur backend, le débit de mise à jour attendu serait trois fois plus élevé. En contrepartie, FindRank doit interroger chaque arbre de classement pour obtenir le classement d'un score, puis additionner le rang obtenu à partir de chaque arbre pour trouver le classement réel, ce qui prendra un peu plus de temps. La durée de la requête pour FindRank peut être considérablement réduite si les entités sont conservées dans Memcache.
Cette méthode est semblable à l'approche bien connue qui consiste à utiliser des compteurs partitionnés : chaque compteur est incrémenté indépendamment et la somme totale n'est calculée qu'en cas de besoin.
Par exemple, avec trois arbres, FindRank(865) peut trouver les trois rangs 124, 183 et 156, indiquant que chaque arbre contient le nombre respectif de scores supérieurs à 865. Le nombre total de scores supérieurs à 865 est alors 124 + 183 + 156 = 463.
Cette approche ne fonctionne pas pour tous les types d'algorithmes distribués. Toutefois, étant donné que le classement consiste en un problème reposant foncièrement sur le comptage commutatif, il devrait fonctionner pour les problèmes de classement des gros volumes.
Des solutions plus évolutives avec des approches approximatives
Si votre application privilégie l'évolutivité à l'exactitude des classements et peut tolérer un certain niveau d'inexactitude ou d'approximation, vous pouvez choisir une approche stochastique parmi celles indiquées ci-dessous :
- Buckets avec requête globale
- Méthode de comptage avec perte
- Diffusion en flux continu économique
Ces approches approximatives représentent toutes des variantes d'une même idée : comment compresser le stockage des informations de classement en permettant une certaine dégradation de la précision du classement ?
Buckets avec requête globale est une solution alternative proposée par l'équipe Datastore et Alex Amies, un responsable de compte technique. Alex a mis en œuvre une démonstration de faisabilité basée sur l'idée de l'équipe Datastore et a mené une analyse approfondie des performances. Il a prouvé que "Buckets avec requête globale" était une solution de classement évolutive permettant une dégradation minimale de la précision du classement, et qu'elle pouvait être adaptée aux applications nécessitant un débit supérieur à celui de la bibliothèque de classement Code Jam. Reportez-vous à l'annexe pour obtenir une description détaillée, ainsi que les résultats du test.
La méthode de comptage avec perte et la diffusion en flux continu économique sont considérées comme des algorithmes en ligne et des algorithmes de flux continu, dans lesquels vous pouvez utiliser un très petit stockage en mémoire pour calculer une estimation stochastique des joueurs les mieux classés depuis un flux de paires joueur/score. Ces algorithmes conviennent aux applications nécessitant une latence très faible et une bande passante extrêmement élevée, telles que des milliers de mises à jour par seconde, avec une précision et une couverture des résultats de classement plus limitées. Par exemple, ces algorithmes sont parfaitement adaptés si vous souhaitez afficher un tableau de bord en temps réel indiquant les 100 mots clés les plus renseignés dans des flux de réseaux sociaux.
Conclusion
Le classement est un problème classique, mais difficile à résoudre, en particulier si vous souhaitez que l'algorithme soit évolutif, cohérent et rapide. Dans cet article, nous avons décrit la manière dont les responsables de compte technique de Google ont travaillé en étroite collaboration avec le client et les équipes d'ingénieurs de Google afin de relever le défi et de proposer une solution permettant de réduire la latence de la mise à jour du classement en la faisant passer d'une heure à quelques secondes. Les modèles de conception découverts au cours du processus (Job Aggregation et le partitionnement de la file d'attente) pourraient également s'appliquer aux problèmes courants rencontrés dans d'autres conceptions système basées sur Datastore nécessitant des centaines de mises à jour par seconde avec une cohérence élevée.
Notes
- La bibliothèque de classement Code Jam utilise un paramètre appelé "facteur de ramifications", qui spécifie le nombre de scores que chaque entité détiendra. Le paramètre par défaut de la bibliothèque correspond à 100. Dans ce cas, les scores compris entre 0 à 9 999 seront stockés sur 100 entités en tant qu'enfants du nœud racine. Si vous devez gérer un plus grand nombre de scores, vous pouvez définir le facteur de ramifications sur une valeur plus élevée afin d'optimiser le nombre d'accès aux entités.
- Les niveaux de performances décrits dans cet article sont des exemples de valeurs à titre de référence et ne garantissent en aucun cas des performances absolues d'App Engine, de Datastore ou d'autres services.
Annexe : solution Buckets avec requête globale
Comme indiqué dans la section Comment obtenir un classement, interroger la base de données pour chaque requête de classement est une solution coûteuse. Cette approche alternative permet d'obtenir périodiquement le décompte de tous les scores, de calculer le classement de certains scores sélectionnés et de fournir ces points de données afin qu'ils soient utilisés dans le calcul des classements pour des joueurs spécifiques. La plage totale des scores est divisée en "buckets". Chaque bucket est caractérisé par une sous-plage de scores et par le nombre de joueurs dont les scores sont compris dans cette plage. À partir de ces données, il est possible d'établir un classement approximatif assez proche de la vérité pour l'ensemble des scores. Ces buckets sont semblables au nœud de premier niveau dans l'arbre de classement. Toutefois, au lieu de se sectionner en nœuds plus détaillés, cet algorithme s'interpole simplement dans un bucket.
La récupération du classement par les utilisateurs depuis le frontend est découplée du calcul du classement sur les buckets dans le frontend afin de réduire le temps nécessaire pour trouver un classement. Lorsque le classement d'un joueur est demandé, le bucket approprié est trouvé en fonction du score du joueur. Le bucket comprend une limite de classement supérieur et un décompte des joueurs dans le bucket. On utilise l'interpolation linéaire au sein des buckets pour estimer le classement des joueurs dans les buckets. Au cours de nos tests, nous avons réussi à obtenir le classement d'un joueur en moins de 400 millisecondes pour un aller-retour HTTP complet. Le coût de la méthode FindRank ne dépend pas du nombre de joueurs dans la population.
Établir le classement pour un score donné
Le décompte et le classement le plus élevé (c'est-à-dire le classement le plus élevé possible dans ce bucket) sont enregistrés pour chaque bucket. Pour les scores compris entre les limites des scores les plus bas et les plus élevés dans un bucket, on calcule une estimation du classement à l'aide de l'interpolation linéaire. Par exemple, si le score d'un joueur s'élève à 60, nous nous intéressons au bucket [50, 74], et nous nous servons du décompte (nombre de joueurs/scores dans le bucket) (42) et du classement le plus élevé (5) pour calculer le classement du joueur par le biais de cette formule :
rank = 5 + (74 - 60)*42/(74 - 50) = 30
Calculer le décompte et la plage pour chaque bucket
En arrière-plan, à l'aide d'une tâche Cron ou d'une file d'attente de tâches, les décomptes pour chaque bucket sont calculés et enregistrés à l'aide d'une itération sur tous les buckets. Nous appelons ce type de requête une requête globale, car il s'agit ici d'examiner les scores de tous les joueurs pour récupérer les éléments nécessaires à l'estimation des classements. Vous trouverez ci-dessous un exemple de code Python correspondant aux scores de la plage [low_score, high_score] pour chaque bucket.
next_upper_rank = 1 for b in buckets: count = GetCountInRange(b.low_score, b.high_score) b.count = count b.upper_rank = next_upper_rank b.put() next_upper_rank += count
La méthode GetCountInRange() comptabilise chaque joueur dont le score est compris dans la plage couverte par le bucket. Comme Datastore conserve un index trié des scores de tous les joueurs, ce décompte peut être effectué de manière efficace.
Pour trouver le classement d'un joueur spécifique, nous pouvons utiliser le code ci-dessous :
b = GetBucketByScore(score) rank = RankInBucket(b, score) return rank + b.upper_rank - 1
La méthode GetBucketByScore(score) récupère le bucket contenant le score donné. La méthode RankInBucket() effectue une estimation du classement dans le bucket. Le classement du joueur correspond à la somme du classement le plus élevé du bucket et du classement du joueur dans le bucket (le score du joueur étant indiqué entre crochets). Il faudra soustraire 1 au résultat, car le classement le plus élevé du bucket de premier niveau correspondra à 1 et que le classement du meilleur joueur dans un bucket spécifique correspondra également à cette valeur.
Les buckets sont stockés à la fois dans Datastore et dans Memcache. Pour calculer le classement, lisez les buckets à partir du Memcache (ou de Datastore, s'il manque les données à Memcache). Dans notre mise en œuvre de cet algorithme, nous avons utilisé la bibliothèque cliente NDB Python, qui se sert du Memcache pour mettre en cache les données stockées dans Datastore.
Comme les buckets (ou d'autres méthodes) permettent de représenter les données de manière compacte, les classements qui en résultent ne sont pas exacts. Les classements d'un bucket sont des valeurs approximatives obtenues par interpolation linéaire. D'autres méthodes d'interpolation plus précises pourraient être utilisées pour une meilleure approximation au sein du bucket, telles que la formule de régression.
Coût
Le coût de calcul d'un classement et de mise à jour du score d'un joueur est égal à O(1) dans les deux cas, indépendamment du nombre de joueurs.
Le coût de la tâche de requête globale est de O(joueurs), multiplié par la fréquence de mise à jour du cache.
Le coût de calcul des données de bucket dans la tâche backend est également lié au nombre de buckets, étant donné qu'une requête de comptage est effectuée pour chaque bucket. La requête de comptage est optimisée afin d'utiliser une requête "keys-only". Malgré cela, la liste des clés complète doit être récupérée.
Avantages
Cette méthode est très rapide, tant pour mettre à jour le score d'un joueur que pour calculer le classement d'un score. Même si les résultats sont basés sur une tâche en arrière-plan, si le score d'un joueur change, le classement indiquera immédiatement un changement dans la direction appropriée. Ce phénomène est dû à l'interpolation utilisée dans le bucket.
Comme le calcul du classement le plus élevé d'un bucket s'effectue en arrière-plan avec une tâche planifiée, les scores du joueur peuvent être mis à jour sans qu'il ne soit nécessaire de maintenir la synchronisation des données du bucket. Ainsi, le débit de mise à jour des scores des joueurs n'est pas limité par cette approche.
Inconvénients
Le temps nécessaire au décompte de tous les scores des joueurs, du calcul des classements globaux et de la mise à jour des buckets doit être pris en compte. Avec une population de dix millions de joueurs, le temps nécessaire calculé pour notre système de test sur App Engine était de 8 minutes et 34 secondes. Cette méthode est plus rapide que l'heure ou les heures qu'il faudrait pour calculer le classement de chaque joueur, mais il existe un compromis : l'approximation des scores dans chaque bucket. À l'inverse, l'algorithme en arbre calcule les "plages de bucket" (le nœud supérieur de l'arbre) de manière incrémentielle à intervalles de quelques secondes, mais sa mise en œuvre est plus complexe et son débit est limité.
Dans tous les cas, le temps de réalisation de la méthode FindRank dépend également de la rapidité de récupération des données (dans les buckets ou les nœuds d'arbre) à partir de Memcache. Si les données sont supprimées de Memcache, elles doivent être de nouveau extraites de Datastore et mises en cache pour les requêtes FindRank ultérieures.
Justesse
La précision de la méthode du bucket dépend du nombre de compartiments, du classement du joueur et de la distribution des scores. La figure 9 illustre les résultats de notre étude sur la précision des estimations de classements avec des nombres de buckets variés.
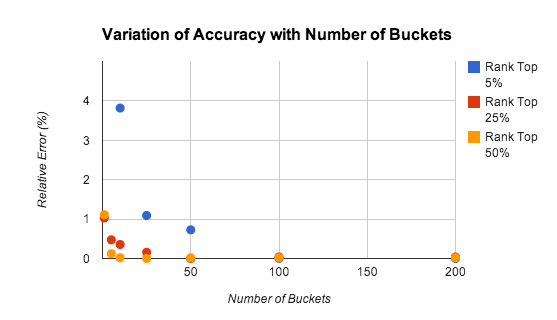
Les tests ont été effectués sur une population de 10 000 joueurs avec des scores uniformément répartis dans la plage [0-9999]. L'erreur relative est d'environ 1 %, même pour 5 compartiments seulement.
La précision diminue pour les joueurs les mieux classés, en particulier parce que la loi des grands nombres ne s'applique pas qu'aux meilleurs scores. Dans de nombreux cas, il peut être judicieux d'utiliser un algorithme plus précis pour maintenir les classements des 1 000 ou 2 000 meilleurs joueurs. Le problème est considérablement réduit, car il y a moins de joueurs à suivre et le taux cumulé de mises à jour est d'autant plus bas.
Dans le test ci-dessus, l'utilisation de nombres aléatoires uniformément distribués, où la fonction de distribution cumulée est linéaire, favorise l'utilisation de l'interpolation linéaire dans le bucket. Or, cette interpolation est parfaitement adaptée aux distributions de scores denses. La figure 10 illustre les classements estimés et réels pour une distribution des scores quasi normale.
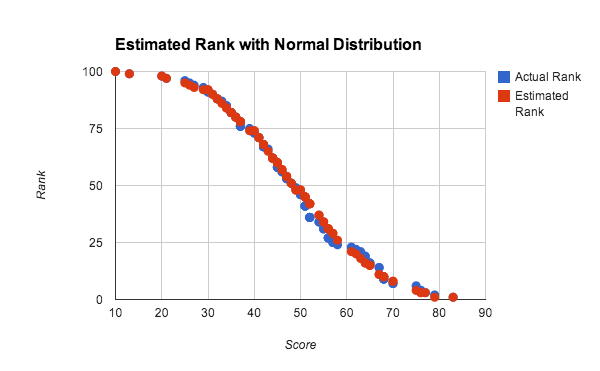
Pour cette expérimentation, nous avons utilisé une population de 100 joueurs afin d'effectuer le test de précision avec un ensemble de données de taille réduite. Chaque score a été généré en effectuant la moyenne de 4 nombres aléatoires compris entre 0 et 100, ce qui correspond approximativement à une distribution normale des scores. Le classement estimé a été calculé à l'aide de la méthode de requête globale avec interpolation linéaire sur 10 buckets. On peut constater que les résultats sont très bons, même avec des ensembles de données de petite taille et des distributions non uniformes.