Bilanciare la coerenza elevata e finale con Datastore
Offrire un'esperienza utente coerente e sfruttare il modello di coerenza eventuale per scalare fino a set di dati di grandi dimensioni
Questo documento illustra come ottenere una coerenza forte per un'esperienza utente positiva, adottando al contempo il modello di coerenza finale di Datastore per la gestione di grandi quantità di dati e utenti.
Questo documento è rivolto ad architetti e ingegneri software che vogliono creare soluzioni su Datastore. Per aiutare i lettori che hanno più familiarità con i database relazionali rispetto ai sistemi non relazionali come Datastore, questo documento illustra concetti analoghi nei database relazionali. Il documento presuppone che tu abbia una conoscenza di base di Datastore. Il modo più semplice per iniziare a utilizzare Datastore è in Google App Engine utilizzando una delle lingue supportate. Se non hai ancora utilizzato App Engine, ti consigliamo di leggere prima la Guida introduttiva e la sezione Archiviazione dei dati per una di queste lingue. Sebbene Python venga utilizzato per i frammenti di codice di esempio, non è necessaria alcuna competenza in Python per seguire questo documento.
Nota: gli snippet di codice in questo articolo utilizzano la libreria client DB Python per Datastore, che non è più consigliata. Gli sviluppatori che creano nuove applicazioni sono vivamente incoraggiati a utilizzare la libreria client NDB, che offre diversi vantaggi rispetto a questa libreria client, ad esempio la memorizzazione nella cache automatica delle entità tramite l'API Memcache. Se al momento utilizzi la libreria client DB precedente, leggi la guida alla migrazione da DB a NDB
Sommario
NoSQL e coerenza finale
Coerenza finale nel datastore
Query ancestrali e gruppo di entità
Limiti del gruppo di entità e delle query ancestrali
Alternative alle query ancestrali
Riduzione al minimo del tempo per raggiungere la coerenza completa
Conclusione
Risorse aggiuntive
NoSQL e coerenza finale
I database non relazionali, noti anche come database NoSQL, sono emersi negli ultimi anni come alternativa ai database relazionali. Datastore è uno dei database non relazionali più utilizzati nel settore. Nel 2013 Datastore ha elaborato 4,5 trilioni di transazioni al mese (post del blog della piattaforma Google Cloud). Offre agli sviluppatori un modo semplificato per archiviare e accedere ai dati. Lo schema flessibile si mappa in modo naturale ai linguaggi di scripting e object-oriented. Datastore offre anche una serie di funzionalità che i database relazionali non sono in grado di fornire in modo ottimale, tra cui alte prestazioni su larga scala e alta affidabilità.
Per gli sviluppatori più abituati ai database relazionali, può essere difficile progettare un sistema che utilizza database non relazionali, poiché potrebbero avere relativamente poca familiarità con alcune caratteristiche e pratiche di questi database. Anche se il modello di programmazione di Datastore è semplice, è importante conoscere queste caratteristiche. La coerenza finale è una di queste caratteristiche e la programmazione per la coerenza finale è l'argomento principale di questo documento.
Che cos'è la coerenza finale?
La coerenza finale garantisce a livello teorico che, a condizione che non vengano effettuati altri aggiornamenti di un'entità, tutte le operazioni di lettura dell'entità alla fine restituiranno l'ultimo valore aggiornato. Il DNS (Domain Name System) di internet è un noto esempio di sistema con un modello a coerenza finale. I server DNS non riflettono necessariamente i valori più recenti, ma, piuttosto, i valori vengono memorizzati nella cache e replicati in numerose directory tramite internet. È necessario un certo periodo di tempo per replicare i valori modificati in tutti i client e i server DNS. Tuttavia, il sistema DNS è un sistema molto efficace che è diventato una delle basi di internet. È altamente disponibile e si è dimostrato estremamente scalabile, consentendo la ricerca dei nomi su oltre cento milioni di dispositivi su internet.
La figura 1 illustra il concetto di replica con coerenza finale. Il diagramma mostra che, anche se le repliche sono sempre disponibili per la lettura, alcune potrebbero non essere coerenti con l'ultima scrittura sul nodo di origine, in un determinato momento. Nel diagramma, il nodo A è il nodo di origine e i nodi B e C sono le repliche.

Al contrario, i tradizionali database relazionali sono stati progettati in base al concetto dell'elevata coerenza, chiamata anche coerenza immediata. Ciò vuol dire che i dati visualizzati subito dopo un aggiornamento saranno coerenti per tutti coloro che osservano l'entità. Questa caratteristica è un presupposto fondamentale per molti sviluppatori che usano i database relazionali. Tuttavia, per ottenere elevata coerenza, gli sviluppatori devono trovare un compromesso sulla scalabilità e sulle prestazioni dell'applicazione. Detto in maniera più semplice, i dati devono essere bloccati durante il periodo di aggiornamento o il processo di replica per garantire che nessun altro processo stia aggiornando gli stessi dati.
La Figura 2 mostra una visione concettuale della topologia di deployment e del processo di replica con coerenza forte. In questo diagramma puoi vedere come le repliche abbiano sempre valori coerenti con il nodo di origine, ma non siano accessibili fino al termine dell'aggiornamento.

Bilanciamento per coerenza elevata e finale
I database non relazionali sono diventati popolari di recente, in particolare per le applicazioni web che richiedono elevata scalabilità e prestazioni con alta disponibilità. I database non relazionali consentono agli sviluppatori di scegliere un equilibrio ottimale tra elevata coerenza e coerenza finale per ogni applicazione. In questo modo, gli sviluppatori possono combinare i vantaggi di entrambi i mondi. Ad esempio, informazioni quali "sapere chi è online nella tua lista di contatti in un determinato momento" o "sapere quanti utenti hanno aggiunto un Mi piace al tuo post" sono casi d'uso in cui non è richiesta una forte coerenza. La scalabilità e le prestazioni possono essere fornite per questi casi d'uso sfruttando la coerenza finale. I casi d'uso che richiedono elevata coerenza includono informazioni quali "se un utente ha completato o meno la procedura di fatturazione" o "il numero di punti guadagnati da un giocatore durante una sessione di battaglia".
Per generalizzare gli esempi appena forniti, i casi d'uso con un numero molto elevato di entità spesso suggeriscono che la coerenza finale è il modello migliore. Se una query genera un numero molto elevato di risultati, l'esperienza utente potrebbe non essere interessata dall'inclusione o dall'esclusione di entità specifiche. D'altra parte, i casi d'uso con un numero ridotto di entità e un contesto ristretto suggeriscono che è necessaria una elevata coerenza. L'esperienza utente sarà interessata perché il contesto renderà gli utenti consapevoli di quali entità devono essere incluse o escluse.
Per questi motivi, è importante che gli sviluppatori comprendano le caratteristiche non relazionali di Datastore. Le sezioni seguenti illustrano come combinare i modelli di coerenza finale e di coerenza forte per creare un'applicazione scalabile, ad alta disponibilità e ad alte prestazioni. In questo modo, i requisiti di coerenza per un'esperienza utente positiva continueranno a essere soddisfatti.
Coerenza finale in Datastore
L'API corretta deve essere selezionata quando è richiesta una visualizzazione dei dati fortemente coerente. Le diverse varianti delle API di query di Datastore e i relativi modelli di coerenza sono riportati nella Tabella 1.
|
API Datastore |
Lettura del valore dell'entità |
Lettura dell'indice |
|---|---|---|
|
Coerenza finale |
Coerenza finale |
|
|
N/D |
Coerenza finale |
|
|
Elevata coerenza |
Elevata coerenza |
|
|
Ricerca per chiave (get()) |
Elevata coerenza |
N/D |
Le query del datastore senza un elemento antecedente sono chiamate query globali e sono progettate per funzionare con un modello di coerenza finale. Ciò non garantisce la elevata coerenza. Una query globale solo chiavi è una query globale che restituisce solo le chiavi delle entità corrispondenti alla query, non i valori degli attributi delle entità. Una query da predecessore definisce l'ambito della query in base a un'entità da predecessore. Le sezioni seguenti descrivono in modo più dettagliato ogni comportamento di coerenza.
Coerenza finale durante la lettura dei valori delle entità
Ad eccezione delle query sugli antenati, un valore dell'entità aggiornato potrebbe non essere immediatamente visibile durante l'esecuzione di una query. Per comprendere l'impatto della coerenza finale durante la lettura dei valori delle entità, prendi in considerazione uno scenario in cui un'entità, Giocatore, ha una proprietà, Punteggio. Supponiamo, ad esempio, che il punteggio iniziale abbia un valore pari a 100. Dopo un po' di tempo, il valore del punteggio viene aggiornato a 200. Se viene eseguita una query globale che include la stessa entità Player nel risultato, è possibile che il valore della proprietà Punteggio dell'entità restituita appaia invariato, pari a 100.
Questo comportamento è causato dalla replica tra i server Datastore. La replica è gestita da Bigtable e Megastore, le tecnologie di base di Datastore (consulta le risorse aggiuntive per ulteriori dettagli su Bigtable e Megastore). La replica viene eseguita con l'algoritmo Paxos, che attende in modo sincrono fino a quando la maggior parte delle repliche non ha confermato la richiesta di aggiornamento. La replica viene aggiornata con i dati della richiesta dopo un determinato periodo di tempo. Questo periodo di tempo è in genere breve, ma non è garantita la sua durata effettiva. Una query potrebbe leggere i dati inattivi se viene eseguita prima del completamento dell'aggiornamento.
In molti casi, l'aggiornamento avrà raggiunto tutte le repliche molto rapidamente. Tuttavia, diversi fattori possono, se combinati, aumentare il tempo necessario per raggiungere la coerenza. Questi fattori includono eventuali incidenti a livello di data center che comportano il trasferimento di un numero elevato di server tra data center. Data la variabilità di questi fattori, è impossibile fornire requisiti temporali definitivi per stabilire una coerenza completa.
Il tempo necessario per una query per restituire il valore più recente è in genere molto breve. Tuttavia, in rari casi in cui la latenza della replica aumenta, il tempo può essere molto più lungo. Le applicazioni che utilizzano query globali di Datastore devono essere progettate con attenzione per gestire questi casi in modo elegante.
La coerenza finale nella lettura dei valori delle entità può essere evitata utilizzando una query solo per chiavi, una query da predecessore;antenato o la ricerca per chiave (metodo get()). Analizzeremo questi diversi tipi di query più in dettaglio di seguito.
Coerenza finale durante la lettura di un indice
Un indice potrebbe non essere ancora aggiornato quando viene eseguita una query globale. Ciò significa che, anche se potresti essere in grado di leggere i valori delle proprietà più recenti delle entità, l'elenco di entità incluso nel risultato della query potrebbe essere filtrato in base ai valori degli indici precedenti.
Per comprendere l'impatto della coerenza finale sulla lettura di un indice, immagina uno scenario in cui una nuova entità, Player, viene inserita in Datastore. L'entità ha una proprietà, Punteggio, con un valore iniziale di 300. Immediatamente dopo l'inserimento, esegui una query solo sulle chiavi per recuperare tutte le entità con un valore di punteggio maggiore di 0. Dovresti quindi aspettarti che l'entità Player, inserita di recente, venga visualizzata nei risultati della query. Forse inaspettatamente, potresti scoprire che l'entità Player non viene visualizzata nei risultati. Questa situazione può verificarsi quando la tabella di indice per la proprietà Punteggio non viene aggiornata con il valore appena inserito al momento dell'esecuzione della query.
Ricorda che tutte le query in Datastore vengono eseguite sulle tabelle di indice, ma gli aggiornamenti delle tabelle di indice sono asincroni. Ogni aggiornamento delle entità è costituito essenzialmente da due fasi. Nella prima fase, la fase di commit, viene eseguita una scrittura nel log delle transazioni. Nella seconda fase, i dati vengono scritti e gli indici vengono aggiornati. Se la fase di commit va a buon fine, la fase di scrittura è garantita, anche se potrebbe non avvenire immediatamente. Se esegui una query su un'entità prima che gli indici vengano aggiornati, potresti visualizzare dati non ancora coerenti.
A causa di questa procedura in due fasi, esiste un ritardo prima che gli aggiornamenti più recenti delle entità siano visibili nelle query globali. Come per la coerenza finale del valore dell'entità, il ritardo temporale è in genere ridotto, ma può essere più lungo (anche minuti o più in circostanze eccezionali).
Lo stesso può accadere anche dopo gli aggiornamenti. Ad esempio, supponiamo di aggiornare un'entità esistente, Giocatore, con un nuovo valore della proprietà Punteggio pari a 0 ed eseguire immediatamente la stessa query. Dovresti aspettarti che l'entità non venga visualizzata nei risultati della query perché il nuovo valore del punteggio pari a 0 la escluderebbe. Tuttavia, a causa dello stesso comportamento di aggiornamento dell'indice asincrono, è comunque possibile che l'entità venga inclusa nel risultato.
La coerenza finale nella lettura di un indice può essere evitata solo utilizzando una query da predecessore#39;antenato o un metodo di ricerca per chiave. Una query solo chiavi non può evitare questo comportamento.
Coherenza elevata per la lettura di valori e indici delle entità
In Datastore esistono solo due API che forniscono una visualizzazione fortemente coerente per la lettura degli indici e dei valori delle entità: (1) il metodo di ricerca per chiave e (2) la query da predecessore. Se la logica dell'applicazione richiede una coerenza forte, lo sviluppatore deve utilizzare uno di questi metodi per leggere le entità da Datastore.
Datastore è progettato specificamente per garantire una elevata coerenza su queste API. Quando chiami una delle due, Datastore eseguirà l'eliminazione di tutti gli aggiornamenti in attesa in una delle tabelle di replica e di indice, quindi eseguirà la ricerca o la query da predecessore sull'antenato. Pertanto, il valore dell'entità più recente, in base alla tabella di indice aggiornata, verrà sempre restituito con i valori basati sugli ultimi aggiornamenti.
A differenza delle query, la chiamata di ricerca per chiave restituisce una sola entità o un insieme di entità specificate da una chiave o da un insieme di chiavi. Ciò significa che una query da predecessore sull'antenato è l'unico modo in Datastore per soddisfare il requisito di elevata coerenza insieme a un requisito di filtro. Tuttavia, le query sugli antenati non funzionano senza specificare un gruppo di entità.
Query da predecessore e gruppo di entità
Come discusso all'inizio di questo documento, uno dei vantaggi di Datastore è che gli sviluppatori possono trovare un equilibrio ottimale tra coerenza forte e coerenza finale. In Datastore, un gruppo di entità è un'unità con elevata coerenza, transazionalità e località. Utilizzando i gruppi di entità, gli sviluppatori possono definire l'ambito della elevata coerenza tra le entità di un'applicazione. In questo modo, l'applicazione può mantenere la coerenza all'interno del gruppo di entità e, al contempo, ottenere elevata scalabilità, disponibilità e prestazioni come sistema completo.
Un gruppo di entità è una gerarchia formata da un'entità base e dai relativi elementi secondari o successori.[1] Per creare un gruppo di entità, uno sviluppatore specifica un percorso di antenato, che è essenzialmente una serie di chiavi principali che precedono la chiave secondaria. Il concetto di gruppo di entità è illustrato nella Figura 3. In questo caso, l'entità base con la chiave "ateam" ha due elementi secondari con le chiavi "ateam/098745" e "ateam/098746".
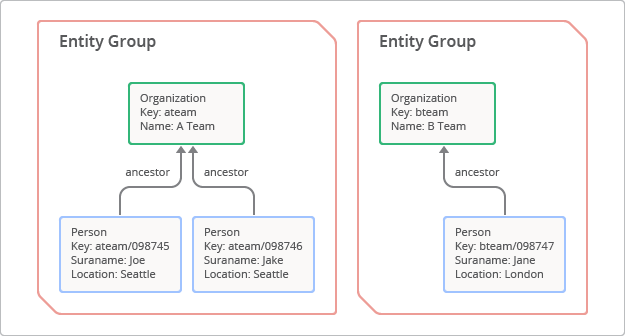
All'interno del gruppo di entità sono garantite le seguenti caratteristiche:
-
Elevata coerenza
- Una query sull'antenato del gruppo di entità restituirà un risultato fortemente coerente. In questo modo, riflette gli ultimi valori delle entità filtrati dallo stato dell'indice più recente.
-
Transazionalità
- Se delimiti una transazione in modo programmatico, il gruppo di entità fornisce le caratteristiche ACID (atomicità, coerenza, isolamento e durabilità) nella transazione.
-
Località
- Le entità di un gruppo di entità verranno archiviate in posizioni fisicamente vicine sui server Datastore, perché tutte le entità vengono ordinate e archiviate in base all'ordine lessicografico delle chiavi. In questo modo, una query da predecessore può eseguire rapidamente la scansione del gruppo di entità con una quantità minima di I/O.
Una query da predecessore è una forma speciale di query che viene eseguita solo su un gruppo di entità specificato. Viene eseguito con elevata coerenza. Dietro le quinte, Datastore assicura che tutte le repliche e gli aggiornamenti degli indici in attesa vengano applicati prima dell'esecuzione della query.
Esempio di query da predecessore
Questa sezione descrive come utilizzare i gruppi di entità e le query sugli antenati nella pratica. Nell'esempio seguente, prendiamo in considerazione il problema della gestione dei record di dati relativi alle persone. Supponiamo di avere un codice che aggiunge un'entità di un tipo specifico seguita immediatamente da una query su quel tipo. Questo concetto è dimostrato dal codice Python di esempio riportato di seguito.
# Define the Person entity
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
organization = db.StringProperty()
# Add a person and retrieve the list of all people
class MainPage(webapp2.RequestHandler):
def post(self):
person = Person(given_name='GI', surname='Joe', organization='ATeam')
person.put()
q = db.GqlQuery("SELECT * FROM Person")
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname,
'organization': p.organization})
Il problema con questo codice è che, nella maggior parte dei casi, la query non restituirà l'entità aggiunta nell'istruzione precedente. Poiché la query segue la riga immediatamente successiva all'inserimento, l'indice non verrà aggiornato quando viene eseguita la query. Tuttavia, esiste anche un problema di validità di questo caso d'uso: è davvero necessario restituire un elenco di tutte le persone in una pagina senza contesto? E se ci fossero un milione di persone? La pagina impiegherebbe troppo tempo per essere restituita.
La natura del caso d'uso suggerisce che dovremmo fornire un po' di contesto per restringere la query. In questo esempio, il contesto che utilizzeremo sarà l'organizzazione. In questo modo, possiamo utilizzare l'organizzazione come gruppo di entità ed eseguire una query da predecessore, che risolve il problema di coerenza. Questo è dimostrato dal codice Python riportato di seguito.
class Organization(db.Model):
name = db.StringProperty()
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
class MainPage(webapp2.RequestHandler):
def post(self):
org = Organization.get_or_insert('ateam', name='ATeam')
person = Person(parent=org)
person.given_name='GI'
person.surname='Joe'
person.put()
q = db.GqlQuery("SELECT * FROM Person WHERE ANCESTOR IS :1 ", org)
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname})
Questa volta, con l'organizzazione principale specificata in GqlQuery, la query restituisce l'entità appena inserita. L'esempio potrebbe essere esteso per visualizzare i dettagli di una singola persona eseguendo una query sul nome della persona con l'antenato all'interno della query. In alternativa, questa operazione può essere eseguita anche salvando la chiave dell'entità e utilizzandola per visualizzare in dettaglio con una ricerca per chiave.
Mantenimento della coerenza tra Memcache e Datastore
I gruppi di entità possono essere utilizzati anche come unità per mantenere la coerenza tra le voci Memcache e le entità Datastore. Ad esempio, considera uno scenario in cui conteggi il numero di persone in ogni team e le memorizzi in Memcache. Per assicurarti che i dati memorizzati nella cache siano coerenti con i valori più recenti in Datastore, puoi utilizzare i metadati del gruppo di entità. I metadati restituiscono il numero della versione più recente del gruppo di entità specificato. Puoi confrontare il numero di versione con quello memorizzato in Memcache. Con questo metodo puoi rilevare una modifica in una qualsiasi delle entità dell'intero gruppo di entità leggendo da un insieme di metadati, anziché eseguire la scansione di tutte le singole entità del gruppo.
Limiti del gruppo di entità e della query sull'antenato
L'approccio che prevede l'utilizzo di gruppi di entità e query sugli antenati non è una soluzione definitiva. In pratica, esistono due problemi che rendono difficile applicare la tecnica in generale, come elencato di seguito.
- Esiste un limite di un aggiornamento al secondo per ogni gruppo di entità.
- La relazione del gruppo di entità non può essere modificata dopo la creazione dell'entità.
Limite di scrittura
Una sfida importante è che il sistema deve essere progettato per contenere il numero di aggiornamenti (o transazioni) in ogni gruppo di entità. Il limite supportato è un aggiornamento al secondo per gruppo di entità.[2] Se il numero di aggiornamenti deve superare questo limite, il gruppo di entità potrebbe rappresentare un collo di bottiglia per il rendimento.
Nell'esempio riportato sopra, ogni organizzazione potrebbe dover aggiornare il record di qualsiasi persona all'interno dell'organizzazione. Considera uno scenario in cui il team "ateam" è composto da 1000 persone e ogni persona può ricevere un aggiornamento al secondo su una delle proprietà. Di conseguenza, nel gruppo di entità potrebbero essere presenti fino a 1000 aggiornamenti al secondo, un risultato che non sarebbe possibile ottenere a causa del limite di aggiornamento. Ciò dimostra che è importante scegliere un design del gruppo di entità appropriato che tenga conto dei requisiti di rendimento. Questa è una delle difficoltà nel trovare l'equilibrio ottimale tra coerenza finale e elevata coerenza.
Immutabilità delle relazioni tra gruppi di entità
Un'altra sfida è l'immutabilità delle relazioni tra gruppi di entità. La relazione del gruppo di entità viene formata in modo statico in base alla denominazione delle chiavi. Non può essere modificato dopo aver creato l'entità. L'unica opzione disponibile per modificare la relazione è eliminare le entità in un gruppo di entità e ricrearle. Questo problema ci impedisce di utilizzare i gruppi di entità per definire dinamicamente ambiti ad hoc per la coerenza o la transazionalità. Lo scopo della coerenza e della transazionalità è invece strettamente correlato al gruppo di entità statiche definito in fase di progettazione.
Ad esempio, prendi in considerazione uno scenario in cui vuoi implementare un bonifico bancario tra due conti bancari. Questo scenario aziendale richiede elevata coerenza e transazionalità. Tuttavia, i due account non possono essere raggruppati in un gruppo di entità all'ultimo minuto o essere basati su un account principale globale. Questo gruppo di entità creerebbe un collo di bottiglia per l'intero sistema che ostacolerebbe l'esecuzione di altre richieste di bonifico bancario. Pertanto, i gruppi di entità non possono essere utilizzati in questo modo.
Esiste un modo alternativo per implementare un bonifico bancario in modo altamente scalabile e disponibile. Anziché inserire tutti gli account in un unico gruppo di entità, puoi creare un gruppo di entità per ogni account. In questo modo, puoi utilizzare le transazioni per garantire gli aggiornamenti ACID su entrambi i conti bancari. Le transazioni sono una funzionalità di Datastore che ti consente di creare insiemi di operazioni con caratteristiche ACID per un massimo di venticinque gruppi di entità. Tieni presente che all'interno di una transazione devi utilizzare query fortemente coerenti, come le ricerche per chiave e le query sugli antenati. Per saperne di più sulle limitazioni delle transazioni, vedi Transazioni e gruppi di entità.
Alternative alle query da predecessore
Se hai già un'applicazione con un numero elevato di entità archiviate in Datastore, potrebbe essere difficile incorporare successivamente i gruppi di entità in un'operazione di refactoring. Dovresti eliminare tutte le entità e aggiungerle all'interno di una relazione di gruppo di entità. Pertanto, nella definizione del modello di dati per Datastore, è importante prendere una decisione sul design del gruppo di entità nella fase iniziale della progettazione dell'applicazione. In caso contrario, il refactoring potrebbe essere limitato ad altre alternative per raggiungere un determinato livello di coerenza, ad esempio una query solo per chiavi seguita da una ricerca per chiave o l'utilizzo di Memcache.
Query globale solo chiavi seguita da ricerca per chiave
Una query globale solo chiavi è un tipo speciale di query globale che restituisce solo le chiavi senza i valori delle proprietà delle entità. Poiché i valori restituiti sono solo chiavi, la query non coinvolge un valore dell'entità con un possibile problema di coerenza. Una combinazione della query globale solo chiavi con un metodo di ricerca consente di leggere gli ultimi valori delle entità. Tuttavia, è necessario tenere presente che una query globale basata solo su chiavi non può escludere la possibilità che un indice non sia ancora coerente al momento della query, il che potrebbe comportare il mancato recupero di un'entità. Il risultato della query potrebbe essere generato in base al filtro dei vecchi valori dell'indice. In sintesi, uno sviluppatore può utilizzare una query globale solo per le chiavi seguita da una ricerca per chiave solo quando un requisito dell'applicazione consente che il valore dell'indice non sia ancora coerente al momento di una query.
Utilizzare Memcache
Il servizio Memcache è volatile, ma molto coerente. Pertanto, combinando le ricerche Memcache e le query Datastore, è possibile creare un sistema che riduca al minimo i problemi di coerenza nella maggior parte dei casi.
Ad esempio, prendiamo lo scenario di un'applicazione di gioco che gestisce un elenco di entità Player, ciascuna con un punteggio maggiore di zero.
- Per le richieste di inserimento o aggiornamento, applicale all'elenco di entità Player in Memcache e Datastore.
- Per le richieste di query, leggi l'elenco delle entità Player da Memcache ed esegui una query solo sulle chiavi su Datastore quando l'elenco non è presente in Memcache.
L'elenco restituito sarà coerente ogni volta che l'elenco memorizzato nella cache è presente in Memcache. Se la voce è stata espulsa o se il servizio Memcache non è temporaneamente disponibile, il sistema potrebbe dover leggere il valore da una query Datastore che potrebbe restituire un risultato incoerente. Questa tecnica può essere applicata a qualsiasi applicazione che tollera una piccola quantità di incoerenza.
Esistono alcune best practice per l'utilizzo di Memcache come livello di memorizzazione nella cache per Datastore:
- Cattura le eccezioni e gli errori di Memcache per mantenere la coerenza tra il valore Memcache e il valore Datastore. Se ricevi un'eccezione durante l'aggiornamento della voce in Memcache, assicurati di invalidare la vecchia voce in Memcache. In caso contrario, potrebbero esserci valori diversi per un'entità (un valore precedente in Memcache e un valore nuovo in Datastore).
- Imposta un periodo di scadenza per le voci Memcache. Ti consigliamo di impostare periodi di tempo brevi per la scadenza di ogni voce per ridurre al minimo la possibilità di incoerenza in caso di eccezioni Memcache.
- Utilizza la funzionalità compare-and-set quando aggiorni le voci per controllo della contemporaneità. In questo modo, puoi assicurarti che gli aggiornamenti simultanei nella stessa voce non interferiscano tra loro.
Migrazione graduale ai gruppi di entità
I suggerimenti forniti nella sezione precedente riducono solo la possibilità di comportamenti incoerenti. È preferibile progettare l'applicazione in base a gruppi di entità e query sugli antenati quando è richiesta una elevata coerenza. Tuttavia, potrebbe non essere possibile eseguire la migrazione di un'applicazione esistente, il che potrebbe includere la modifica di un modello di dati e della logica di applicazione esistenti dalle query globali alle query sugli antenati. Un modo per farlo è avere una procedura di transizione graduale, ad esempio la seguente:
- Identifica e assegna la priorità alle funzioni dell'applicazione che richiedono una elevata coerenza.
- Scrivi nuova logica per le funzioni insert() o update() utilizzando i gruppi di entità oltre a (anziché sostituire) la logica esistente. In questo modo, eventuali nuovi inserimenti o aggiornamenti sia nei nuovi gruppi di entità sia nelle entità precedenti possono essere gestiti da una funzione appropriata.
- Modifica la logica esistente per le funzioni di lettura o query: le query degli antenati vengono eseguite per prime se esiste un nuovo gruppo di entità per la richiesta. Esegui la vecchia query globale come logica di riserva se il gruppo di entità non esiste.
Questa strategia consente una migrazione graduale da un modello di dati esistente a un nuovo modello di dati basato su gruppi di entità che riduce al minimo il rischio di problemi causati dalla coerenza eventuale. In pratica, questo approccio dipende da casi d'uso e requisiti specifici per la sua applicazione a un sistema reale.
Passare alla modalità degradata
Al momento, è difficile rilevare in modo programmatico una situazione in cui la coerenza di un'applicazione è peggiorata. Tuttavia, se dovessi stabilire con altri mezzi che la coerenza di un'applicazione è peggiorata, potrebbe essere possibile implementare una modalità di degradazione che può essere attivata o disattivata per disattivare alcune aree della logica dell'applicazione che richiedono una coerenza rigorosa. Ad esempio, anziché mostrare un risultato di query incoerente in una schermata del report di fatturazione, potrebbe essere visualizzato un messaggio di manutenzione per quella determinata schermata. In questo modo, gli altri servizi dell'applicazione possono continuare a essere pubblicati e, di conseguenza, ridurre l'impatto sull'esperienza utente.
Ridurre al minimo il tempo necessario per ottenere una coerenza completa
In un'applicazione di grandi dimensioni con milioni di utenti o terabyte di entità Datastore, è possibile che l'utilizzo improprio di Datastore porti a una consistenza peggiorata. Queste pratiche includono:
- Numerazione sequenziale nelle chiavi delle entità
- Troppi indici
Queste pratiche non influiscono sulle piccole applicazioni. Tuttavia, quando l'applicazione diventa molto grande, queste pratiche aumentano la possibilità che siano necessari tempi più lunghi per la coerenza. Pertanto, è meglio evitarli nelle fasi iniziali della progettazione dell'applicazione.
Anti-pattern 1: numerazione sequenziale delle chiavi di entità
Prima del rilascio dell'SDK App Engine 1.8.1, Datastore utilizzava una sequenza di ID interi di piccole dimensioni con pattern generalmente consecutivi come nomi di chiavi predefiniti generati automaticamente. In alcuni documenti viene definito "criterio precedente" per la creazione di entità che non hanno un nome della chiave specificato dall'applicazione. Questo criterio precedente generava nomi di chiavi delle entità con numerazione sequenziale, ad esempio 1000, 1001, 1002. Tuttavia, come abbiamo discusso in precedenza, Datastore memorizza le entità in base all'ordine alfabetico dei nomi delle chiavi, pertanto è molto probabile che queste entità vengano memorizzate sugli stessi server Datastore. Se un'applicazione attira un traffico molto elevato, questa numerazione sequenziale potrebbe causare una concentrazione di operazioni su un server specifico, con una conseguente latenza più lunga per garantire la coerenza.
Nell'SDK App Engine 1.8.1, Datastore ha introdotto un nuovo metodo di numerazione degli ID con un criterio predefinito che utilizza ID sparsi (vedi la documentazione di riferimento). Questo criterio predefinito genera una sequenza casuale di ID con un massimo di 16 cifre, distribuiti in modo approssimativamente uniforme. Se utilizzi questo criterio, è probabile che il traffico dell'applicazione di grandi dimensioni venga distribuito meglio tra un insieme di server Datastore con tempi ridotti per la coerenza. Ti consigliamo di utilizzare il criterio predefinito, a meno che la tua applicazione non richieda specificamente la compatibilità con il criterio precedente.
Se imposti esplicitamente i nomi delle chiavi nelle entità, lo schema di denominazione deve essere progettato per accedere alle entità in modo uniforme nell'intero spazio dei nomi delle chiavi. In altre parole, non concentrare l'accesso in un determinato intervallo, poiché sono ordinati in base all'ordine alfabetico dei nomi delle chiavi. In caso contrario, potrebbe verificarsi lo stesso problema della numerazione sequenziale.
Per comprendere la distribuzione non uniforme dell'accesso nello spazio delle chiavi, prendi in considerazione un esempio in cui le entità vengono create con i nomi delle chiavi sequenziali come mostrato nel seguente codice:
p1 = Person(key_name='0001') p2 = Person(key_name='0002') p3 = Person(key_name='0003') ...
Il pattern di accesso all'applicazione potrebbe creare un "hotspot" in un determinato intervallo di nomi delle chiavi, ad esempio avere accesso concentrato sulle entità Person create di recente. In questo caso, le chiavi a cui si accede di frequente avranno tutte ID più elevati. Il carico può quindi essere concentrato su un server Datastore specifico.
In alternativa, per comprendere la distribuzione uniforme nello spazio delle chiavi, ti consigliamo di utilizzare stringhe casuali lunghe per i nomi delle chiavi. Questo è illustrato nel seguente esempio:
p1 = Person(key_name='t9P776g5kAecChuKW4JKCnh44uRvBDhU') p2 = Person(key_name='hCdVjL2jCzLqRnPdNNcPCAN8Rinug9kq') p3 = Person(key_name='PaV9fsXCdra7zCMkt7UX3THvFmu6xsUd') ...
Ora le entità Person create di recente saranno sparse nello spazio chiavi e su più server. Si presume che esista un numero sufficientemente elevato di entità Person.
Antipattern 2: troppi indici
In Datastore, un aggiornamento di un'entità comporterà l'aggiornamento di tutti gli indici definiti per quel tipo di entità. Se un'applicazione utilizza molti indici personalizzati, un aggiornamento potrebbe comportare decine, centinaia o addirittura migliaia di aggiornamenti nelle tabelle di indice. In un'applicazione di grandi dimensioni, un uso eccessivo di indici personalizzati potrebbe comportare un aumento del carico sul server e della latenza per ottenere la coerenza.
Nella maggior parte dei casi, gli indici personalizzati vengono aggiunti per soddisfare requisiti di assistenza come l'assistenza clienti, la risoluzione dei problemi o le attività di analisi dei dati. BigQuery è un motore di query estremamente scalabile in grado di eseguire query ad hoc su set di dati di grandi dimensioni senza indici predefiniti. È più adatto a casi d'uso come l'assistenza clienti, la risoluzione dei problemi o l'analisi dei dati che richiedono query complesse rispetto a Datastore.
Una pratica consiste nel combinare Datastore e BigQuery per soddisfare diversi requisiti aziendali. Utilizza Datastore per l'elaborazione transazionale online (OLTP) necessaria per la logica di base dell'applicazione e BigQuery per l'elaborazione analitica online (OLAP) per le operazioni di backend. Potrebbe essere necessario implementare un flusso di esportazione continua dei dati da Datastore a BigQuery per spostare i dati necessari per queste query.
Oltre a un'implementazione alternativa per gli indici personalizzati, un altro consiglio è specificare esplicitamente le proprietà non indicizzate (vedi Proprietà e tipi di valore). Per impostazione predefinita, Datastore crea una tabella di indici diversa per ogni proprietà indicizzabile di un tipo di entità. Se hai 100 proprietà per un tipo, ci saranno 100 tabelle di indici per quel tipo e altri 100 aggiornamenti per ogni aggiornamento di un'entità. Una best practice, quindi, è impostare le proprietà non indicizzate, se possibile, se non sono necessarie per una condizione di query.
Oltre a ridurre la possibilità di aumentare i tempi per la coerenza, queste ottimizzazioni degli indici possono comportare una riduzione significativa dei costi di archiviazione di Datastore in un'applicazione di grandi dimensioni che utilizza molto gli indici.
Conclusione
La coerenza finale è un elemento essenziale dei database non relazionali che consente agli sviluppatori di trovare un equilibrio ottimale tra scalabilità, prestazioni e coerenza. È importante capire come gestire il bilanciamento tra coerenza finale e coerenza forte per progettare un modello di dati ottimale per la tua applicazione. In Datastore, l'utilizzo di gruppi di entità e query sugli antenati è il modo migliore per garantire elevata coerenza in un ambito di entità. Se la tua applicazione non può incorporare gruppi di entità a causa delle limitazioni descritte in precedenza, puoi prendere in considerazione altre opzioni, ad esempio l'utilizzo di query solo con chiavi o Memcache. Per le applicazioni di grandi dimensioni, applica le best practice, come l'utilizzo di ID sparsi e l'indicizzazione ridotta, per ridurre il tempo necessario per la coerenza. Potrebbe anche essere importante combinare Datastore con BigQuery per soddisfare i requisiti aziendali per query complesse e ridurre al massimo l'utilizzo degli indici di Datastore.
Risorse aggiuntive
Le seguenti risorse forniscono ulteriori informazioni sugli argomenti trattati in questo documento:
- Google App Engine: archiviazione dei dati
- Panoramica di Datastore
- Blog Google Cloud Platform
- Cloud SQL
- Utilizzare App Engine per Python con Cloud SQL
- Bigtable: un sistema di archiviazione distribuito per i dati strutturati
- È stato rilasciato l'SDK App Engine 1.5.2
- Megastore: archiviazione scalabile e altamente disponibile per i servizi interattivi
[1] Un gruppo di entità può essere formato anche specificando una sola chiave dell'entità principale o principale, senza memorizzare le entità effettive per l'entità principale o principale, perché le funzioni del gruppo di entità sono tutte implementate in base alle relazioni tra le chiavi.
[2] Il limite supportato è un aggiornamento al secondo per gruppo di entità al di fuori delle transazioni o una transazione al secondo per gruppo di entità. Se raggruppi più aggiornamenti in un'unica transazione, la dimensione massima della transazione è limitata a 10 MB e alla frequenza di scrittura massima del server Datastore.