
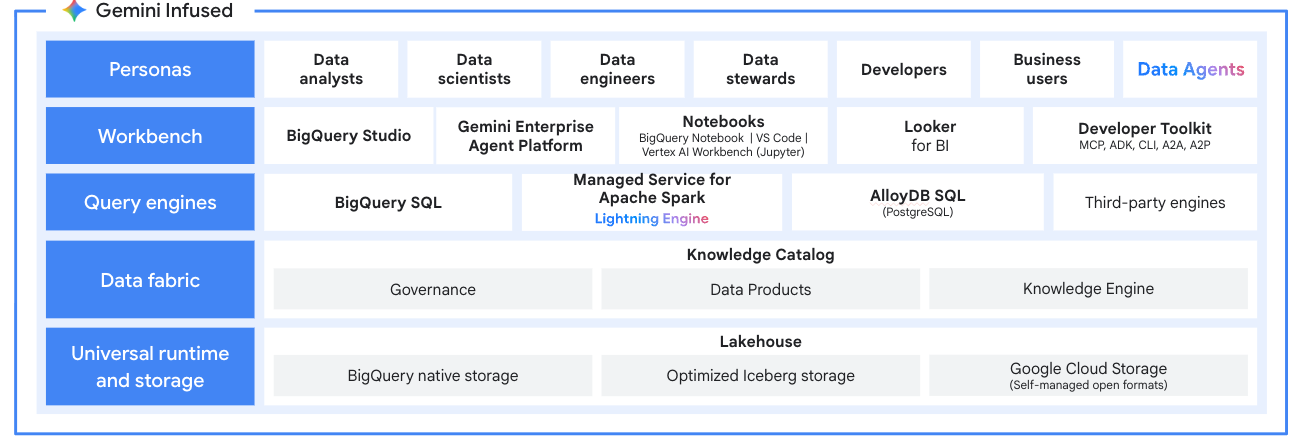
Managed Service for Apache Spark(旧称 Dataproc)
Spark をより簡単に、よりスマートに、より速く
ゼロオペレーションのサーバーレス Spark またはマネージド クラスタで Apache Spark ワークロードを実行できます。エージェント型 AI ワークフローで開発を加速し、Lightning Engine でパフォーマンスを向上させます。
新規のお客様には、Managed Service for Apache Spark や他の Google Cloud プロダクトをお試しいただける無料クレジット $300 分を差し上げます。
Apache Spark は Apache Software Foundation の商標です。

機能
Lightning Engine による業界トップクラスのパフォーマンス
レイクハウスの柔軟な相互運用性
エンジン非依存を保証するオープン レイクハウス アーキテクチャを構築します。Apache Iceberg などのオープン形式でデータを Google Cloud Storage から直接処理します。BigQuery と Knowledge Catalog(旧 Dataplex)とシームレスに統合して、分析とガバナンスを統合し、変換レイヤなしで真のマルチエンジン相互運用性を確保します。
AI を活用した統合デベロッパー エクスペリエンス
質問に答えるだけでなく、行動するデータ エージェントでバックログを解消します。VSCode エージェント拡張機能に組み込まれた Gemini を使用してワークフローを加速し、開発から本番環境までの Spark ワークロードの生産性を向上させます。任意の IDE を使用することもできます。データ エンジニアリング エージェントとデータ サイエンス エージェントを活用して、データ ラングリングの自動化、自然言語からのパイプラインの構築、PySpark コードの生成を行います。Gemini Cloud Assist を使用して、破損した Spark ジョブを自動的にトラブルシューティングできます。SQL と Spark を単一の統合された AI ファーストのノートブックで組み合わせます。
エンタープライズ AI / ML 対応
ML ライフサイクル全体を構築して運用します。 NVIDIA RAPIDS を利用した GPU サポートと、PyTorch および XGBoost 用の事前構成済み ML ランタイムにより、モデルのトレーニングと推論を加速します。Google Cloud AI エコシステムと統合して、エンドツーエンドの MLOps をオーケストレートし、Gemini Enterprise Agent Platform Model Registry の統合でアセットを管理します。
安全でスケーラブルなシームレスな移行
IAM、VPC Service Controls、Kerberos を使用して、セキュリティ ポスチャーとシームレスに統合できます。Managed Service for Apache Spark のテンプレートとツールを使用して、クラウド ワークロードとレガシー Spark ワークロードを簡単に移行できます。コードのリファクタリングをすぐに行うことなく、Spark 2.x から Spark 4.0 までのサポートでワークロードをリフト&シフトできます。
マルチテナントの効率性と FinOps の管理
リソース使用率を最大化し、アイドル状態のコストを削減します。最大 800 人のユーザーがコンピューティング リソースを共有できるマルチテナント Spark クラスタをデプロイし、データと環境の厳格な分離を維持します。ゼロへのスケーリング機能、秒単位の課金、柔軟なワークロードに対応する Spot VM サポートにより、請求額を管理できます。
オープンで柔軟なエコシステム
ベンダー ロックインを回避します。Apache Spark 向けに最適化されていますが、Google のマネージド クラスタは、Apache Hadoop、Flink、Trino など、30 以上のオープンソース ツールをサポートしています。Managed Service for Apache Airflow などのオーケストレーターとシームレスに統合し、Kubernetes と Docker で拡張して最大限の柔軟性を実現します。
デプロイのオプション
| デプロイのオプション | ワークロードに最適なオプションとして、マネージド クラスタによるきめ細かい制御と、サーバーレス エクスペリエンスによるゼロオペレーションのシンプルさから選択できます。 | ||
|---|---|---|---|
| デプロイモード: | 概要 | 対象ユーザー: | 支払い対象: |
サーバーレス | サービスとしての Spark ジョブ。 マネージド Spark、マネージド インフラストラクチャ。 | 新しいパイプライン、インタラクティブ分析、ゼロオペレーションのジョブ単位課金モデルが適したスパイク ワークロード。 | ジョブの実行時間 |
クラスタ | サービスとしての Spark クラスタ。 マネージド Spark、ご利用のインフラストラクチャ。 | 以前の Spark または OSS ワークロードの移行、永続クラスタの実行、オープンソースの高度なカスタマイズが必要。 | クラスタの稼働時間 |
デプロイのオプション
ワークロードに最適なオプションとして、マネージド クラスタによるきめ細かい制御と、サーバーレス エクスペリエンスによるゼロオペレーションのシンプルさから選択できます。
サーバーレス
サービスとしての Spark ジョブ。
マネージド Spark、マネージド インフラストラクチャ。
新しいパイプライン、インタラクティブ分析、ゼロオペレーションのジョブ単位課金モデルが適したスパイク ワークロード。
ジョブの実行時間
クラスタ
サービスとしての Spark クラスタ。
マネージド Spark、ご利用のインフラストラクチャ。
以前の Spark または OSS ワークロードの移行、永続クラスタの実行、オープンソースの高度なカスタマイズが必要。
クラスタの稼働時間
大規模なデータ エンジニアリング
自動化された ETL パイプライン
自動化された ETL パイプライン
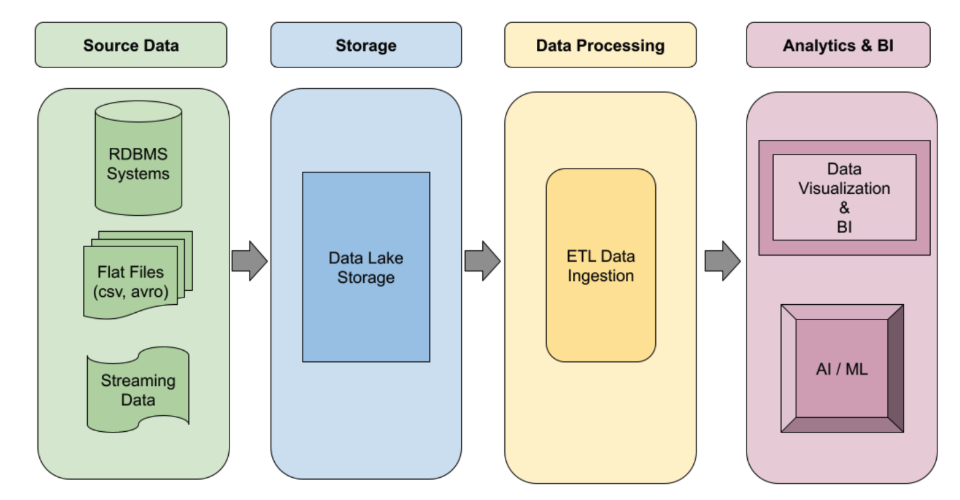
オンデマンドで自動的にスケーリングする、堅牢なイベント ドリブン Spark ETL パイプラインを構築します。急増するワークロードにはサーバーレス実行を、永続的なジョブにはマネージド クラスタを活用します。ワークフロー テンプレートを使用すると、本番環境レベルの最も重要なデータ処理ジョブをエンドツーエンドで自動化できます。


チュートリアル、クイックスタート、ラボ
自動化された ETL パイプライン
自動化された ETL パイプライン
オンデマンドで自動的にスケーリングする、堅牢なイベント ドリブン Spark ETL パイプラインを構築します。急増するワークロードにはサーバーレス実行を、永続的なジョブにはマネージド クラスタを活用します。ワークフロー テンプレートを使用すると、本番環境レベルの最も重要なデータ処理ジョブをエンドツーエンドで自動化できます。
データ サイエンスと ML
インタラクティブなデータ サイエンス
インタラクティブなデータ サイエンス
データ サイエンティストがデータを探索し、Spark ML モデルを反復処理できるようにします。VSCode エージェント拡張機能またはお好みの IDE で Gemini を使用して SQL と Spark を統合し、サーバーレス実行を使用して PySpark でデータ探索からモデル構築までをシームレスに移行します。1 つのコマンドで GPU をアタッチできます。


チュートリアル、クイックスタート、ラボ
インタラクティブなデータ サイエンス
インタラクティブなデータ サイエンス
データ サイエンティストがデータを探索し、Spark ML モデルを反復処理できるようにします。VSCode エージェント拡張機能またはお好みの IDE で Gemini を使用して SQL と Spark を統合し、サーバーレス実行を使用して PySpark でデータ探索からモデル構築までをシームレスに移行します。1 つのコマンドで GPU をアタッチできます。
レイクハウスのモダナイゼーション
オープンデータ レイクハウス
オープンデータ レイクハウス
Managed Service for Apache Spark を最新のデータ レイクハウスの処理エンジンとして使用します。Apache Iceberg などのオープン形式でデータをデータレイクから直接処理し、データサイロを排除します。BigQuery および Lakehouse for Apache Iceberg と統合して、統合されたマルチエンジン分析プラットフォームを実現します。

チュートリアル、クイックスタート、ラボ
オープンデータ レイクハウス
オープンデータ レイクハウス
Managed Service for Apache Spark を最新のデータ レイクハウスの処理エンジンとして使用します。Apache Iceberg などのオープン形式でデータをデータレイクから直接処理し、データサイロを排除します。BigQuery および Lakehouse for Apache Iceberg と統合して、統合されたマルチエンジン分析プラットフォームを実現します。
料金
| Managed Service for Apache Spark の料金の仕組み | 料金は、選択したデプロイモデルによって異なります。サーバーレスはジョブの実行ごとに課金されるのに対し、クラスタは基盤となるコンピューティングと稼働時間に対して課金されます。 | |
|---|---|---|
| デプロイモード: | 課金の対象: | お支払い額: |
サーバーレス | 支払いは従量制です。コンピューティング、GPU、シャッフル ストレージは秒単位で課金されます。ゼロへのスケーリングにより、アイドル状態の容量に対して料金を支払う必要がなくなります。 | 目安 DCU 時間あたり $0.06 |
プレミアム ティアとアクセラレータ: Lightning Engine にアクセスしてパフォーマンスを最大 4.9 倍高速化するか、NVIDIA GPU をアタッチして AI/ML ワークロードを処理できます。 | 目安 DCU 時間あたり $0.089 サーバーレス プレミアム ティア | |
クラスタ | クラスタの稼働時間に応じて料金が発生します。基盤となる Compute Engine リソースの料金に加えて、一律の管理手数料が課金されます。Spot VM とゼロスケールを活用して費用を最適化します。 | 目安 vCPU 時間あたり $0.01 管理料金 |
Lightning Engine アドオン: クラスタに画期的なパフォーマンスをもたらします。オープンソースの Spark と比較して最大 4.9 倍高速な実行を実現。 | 目安 vCPU 時間あたり $0.0025 | |
Managed Service for Apache Spark の料金の詳細を確認します。すべての料金の詳細を見る。
Managed Service for Apache Spark の料金の仕組み
料金は、選択したデプロイモデルによって異なります。サーバーレスはジョブの実行ごとに課金されるのに対し、クラスタは基盤となるコンピューティングと稼働時間に対して課金されます。
サーバーレス
支払いは従量制です。コンピューティング、GPU、シャッフル ストレージは秒単位で課金されます。ゼロへのスケーリングにより、アイドル状態の容量に対して料金を支払う必要がなくなります。
Starting at
DCU 時間あたり $0.06
プレミアム ティアとアクセラレータ:
Lightning Engine にアクセスしてパフォーマンスを最大 4.9 倍高速化するか、NVIDIA GPU をアタッチして AI/ML ワークロードを処理できます。
Starting at
DCU 時間あたり $0.089
サーバーレス プレミアム ティア
クラスタ
クラスタの稼働時間に応じて料金が発生します。基盤となる Compute Engine リソースの料金に加えて、一律の管理手数料が課金されます。Spot VM とゼロスケールを活用して費用を最適化します。
Starting at
vCPU 時間あたり $0.01
管理料金
Lightning Engine アドオン:
クラスタに画期的なパフォーマンスをもたらします。オープンソースの Spark と比較して最大 4.9 倍高速な実行を実現。
Starting at
vCPU 時間あたり $0.0025
Managed Service for Apache Spark の料金の詳細を確認します。すべての料金の詳細を見る。
ビジネスケース
お客様の成功事例

「品質チェックの所要時間が 11 時間から数分に短縮されました。」
Dun & Bradstreet、最高技術責任者、Michael Manos 氏
Google Cloud への移行により、Dun & Bradstreet はデータフローの速度を大幅に向上させ、品質チェック プロセスを数時間から数分に短縮し、新しいデータを公開するまでの時間を半分に短縮しました。この強固なデータ基盤により、Dun & Bradstreet は最先端のデータと AI テクノロジーを含む Google Cloud のエコシステムの力を最大限に活用することもできます。



Managed Service for Apache Spark の特長
柔軟なデプロイ オプションによるゼロオペレーションの生産性。サーバーレス実行またはフルマネージド クラスタを選択して、インフラストラクチャのオーバーヘッドと手動チューニングの負担を排除できます。
エージェント型 AI の開発。VSCode エージェント拡張機能に組み込まれた Gemini や、お好みの IDE とデータ エージェントを使用してワークフローを加速できます。データ エージェントは、PySpark コーディング、データ ラングリング、ジョブのトラブルシューティングを統合ノートブックで自動化します。
業界トップクラスのパフォーマンスを Lightning Engine で実現。最も要求の厳しい ETL およびデータ サイエンスのワークロードを最大 4.9 倍高速化し、総所有コストを大幅に削減します。










その他のリソース:
よくある質問
Dataproc とサーバーレス Spark はどうなったのですか?
エクスペリエンスを簡素化するために、Dataproc と Google Cloud Serverless for Apache Spark を 1 つのプロダクト、Managed Service for Apache Spark に統合しました。まったく同じ強力な機能を利用できますが、単一の統合インターフェースから、ゼロオペレーションのサーバーレスまたはフルマネージド クラスタという好みのデプロイモデルを選択するだけです。両方のデプロイモードを詳しく比較する。
サーバーレス クラスタとマネージド クラスタのどちらを選択すべきですか?
インフラストラクチャ管理を一切行わずにコードに純粋に集中したい場合は、サーバーレスを選択します。これは、新しいパイプラインやアドホック分析に最適です。マネージド クラスタは、きめ細かな制御が必要な場合、レガシーまたはクラウドの Spark やその他の OSS ワークロードを移行する場合、多様なオープンソース ツールを備えた永続クラスタが必要な場合に選択します。
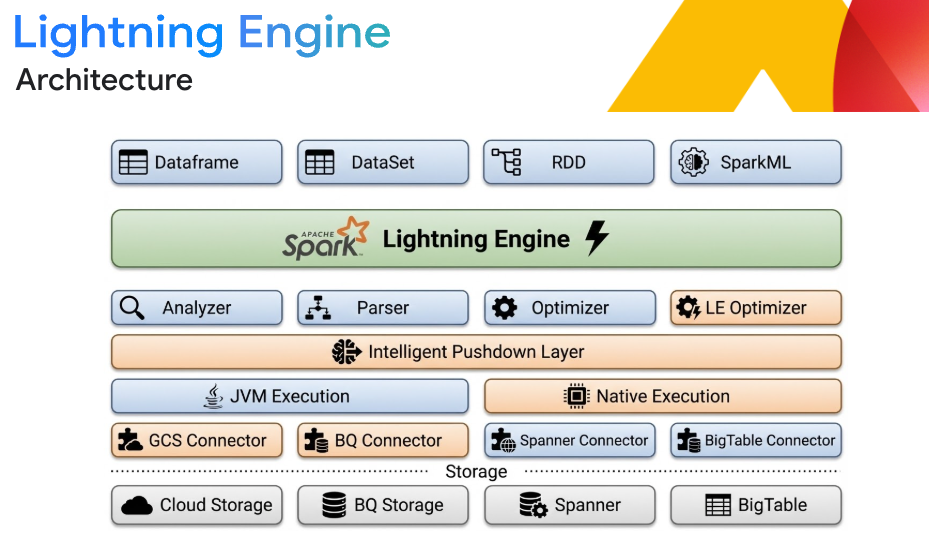
Lightning Engine とは
Lightning Engine は、Google Cloud のネイティブで高度に最適化された実行エンジンです。C++ ライブラリで構築されており、高スループットのストレージ コネクタからインテリジェントなキャッシュ保存まで、あらゆるレイヤを最適化します。標準の Spark より最大 4.9 倍のパフォーマンスを実現し、主要な高速 Spark の代替製品よりも 2 倍の費用対効果を発揮します。また、コードを変更することなく、サーバーレス デプロイやクラスタ デプロイにシームレスに統合できます。
PyTorch などの独自の ML ライブラリをインストールする必要がありますか?
いいえ。AI/ML ワークロードを実行している場合は、事前構成済みの ML ランタイムを使用できます。これらの環境には、PyTorch、XGBoost、scikit-learn などの一般的なライブラリが組み込まれており、最適化された NVIDIA GPU ドライバも含まれているため、複雑な設定は不要です。
Managed Service for Apache Spark はオープンソースと完全に互換性がありますか?
はい。Google は、100% オープンソース互換の Apache Spark 環境を提供しています。既存の Spark コードを修正せずに実行できるため、ワークロードの完全なポータビリティが確保され、ベンダー ロックインを回避できます。
Gemini AI は Spark 開発にどのように役立ちますか?
Gemini AI を任意の IDE に直接組み込んで、AI Co-pilot として使用できます。PySpark コードの作成とデバッグを迅速化するのに役立ちます。また、Gemini Cloud Assist は、失敗したジョブの根本原因分析とトラブルシューティングの推奨事項を自動的に提供します。
このサービスを使用してオープン データ レイクハウスを構築できますか?
もちろんです。Managed Service for Apache Spark は、Google Cloud のオープン レイクハウスのコア処理エンジンです。Apache Iceberg などのオープン フォーマットのデータを Cloud Storage から直接処理でき、BigQuery や Apache Iceberg 用 Knowledge Catalog とシームレスに統合できます。
スタンダードとプレミアムの料金ティアはどのように機能しますか?
現在、スタンダード ティアとプレミアム ティアはサーバーレス デプロイにのみ適用されます。スタンダードは、費用対効果の高い汎用バッチ処理と ETL に最適です。プレミアム ティアは、最も要求の厳しいワークロード向けに設計されており、Lightning Engine を使用してオープンソースの Apache Spark と比較して 4.9 倍のパフォーマンス向上を実現。GPU アクセラレーテッド AI/ML 機能へのアクセスを提供します。


















