What’s new in serverless Managed Service for Apache Spark
Vinay Londhe
Software Engineering Manager
Bhooshan Mogal
Senior Product Manager
Whether you use it for data preparation, real-time interactive queries, AI model training, or something entirely different, running Apache Spark at scale is demanding — you shouldn’t have to manage the underlying infrastructure too.
Late last year, we announced the general availability (GA) of our serverless Managed Service for Apache Spark runtime version 3.0, prioritizing speed, simplicity, and reliability. Since then, customer use of Managed Service for Apache Spark for data science has nearly doubled year over year. This is a testament to our belief that using Google Cloud is the easier, smarter, and faster place to run your Apache Spark workloads.
In this blog, let’s dive into a few key features that make our serverless Apache Spark offering a great fit for a wide range of workflows, including feature engineering, GPU-accelerated model training and tuning, semantic search, RAG, building AI agents and applications, and more.
Zero-setup onboarding
The most significant barrier to entry for a cloud service is often the "time to magic moment" — the interval between creating a project and running your first workload. Previously, with serverless Spark, you still needed to manually configure IAM roles, VPC networking, and firewall rules before submitting a single job.
In the serverless Spark 3.0 runtime version, zero-setup onboarding significantly reduces the time to launch your first workload on serverless Spark. It does so by automating the following steps:
-
Permissions: Necessary IAM roles and permissions are automatically provisioned to the appropriate service accounts.
-
Networking: Private Google Access is auto-enabled on subnets, and system firewall policies are configured automatically.
-
API management: Enabling APIs is now more efficient; you can just enable the Managed Service for Apache Spark API instead of manually having to enable several different APIs, as you did previously.
Fast startup for SLA-sensitive workloads
Latency matters, especially for interactive data science and SLA-sensitive batch pipelines. Historically, serverless Spark startup times could take several minutes. With the 3.0 runtime, we’ve dropped startup times by 75% across both standard and premium tiers, delivered automatically without any code or configuration changes and at no additional cost.
This massive improvement qualifies serverless Spark for a much broader range of SLA-sensitive workloads, and we’re always looking to optimize startup times even further.
"Serverless Spark allowed us to quickly reap benefits by removing the need for fine-grain machine management. This drove faster model development and significantly reduced our data processing costs." - César Narnajo, Principal Engineer, Moloco

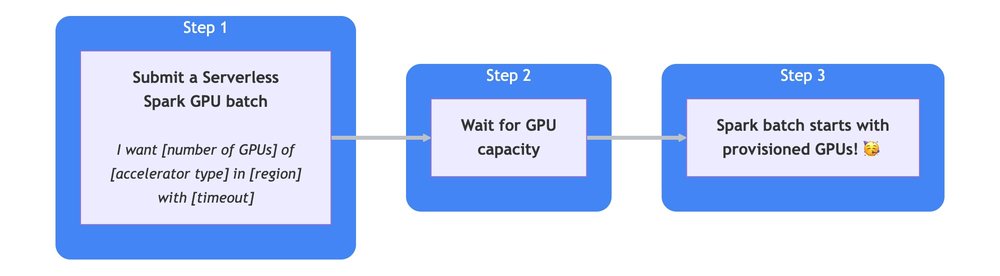
Better GPU obtainability
Support for Dynamic Workload Scheduler (DWS) Flex Start Mode in the serverless 3.0 runtime version allows serverless Spark to queue customer requests for a configurable duration when GPUs are unavailable. This feature addresses the obtainability challenges for high-demand accelerators like NVIDIA A100 and L4 that are the subject of frequent regional shortages. By pausing workloads until the necessary GPU capacity becomes accessible with DWS, you can dramatically increase obtainability and reliability for your latency-sensitive AI/ML workloads.
First-class support for Apache Spark 4.x
The serverless Spark 3.0 runtime version supports current and upcoming Apache Spark 4.x innovations, including Spark Connect, which supports a decoupled client-server architecture that enables remote connectivity from any client.
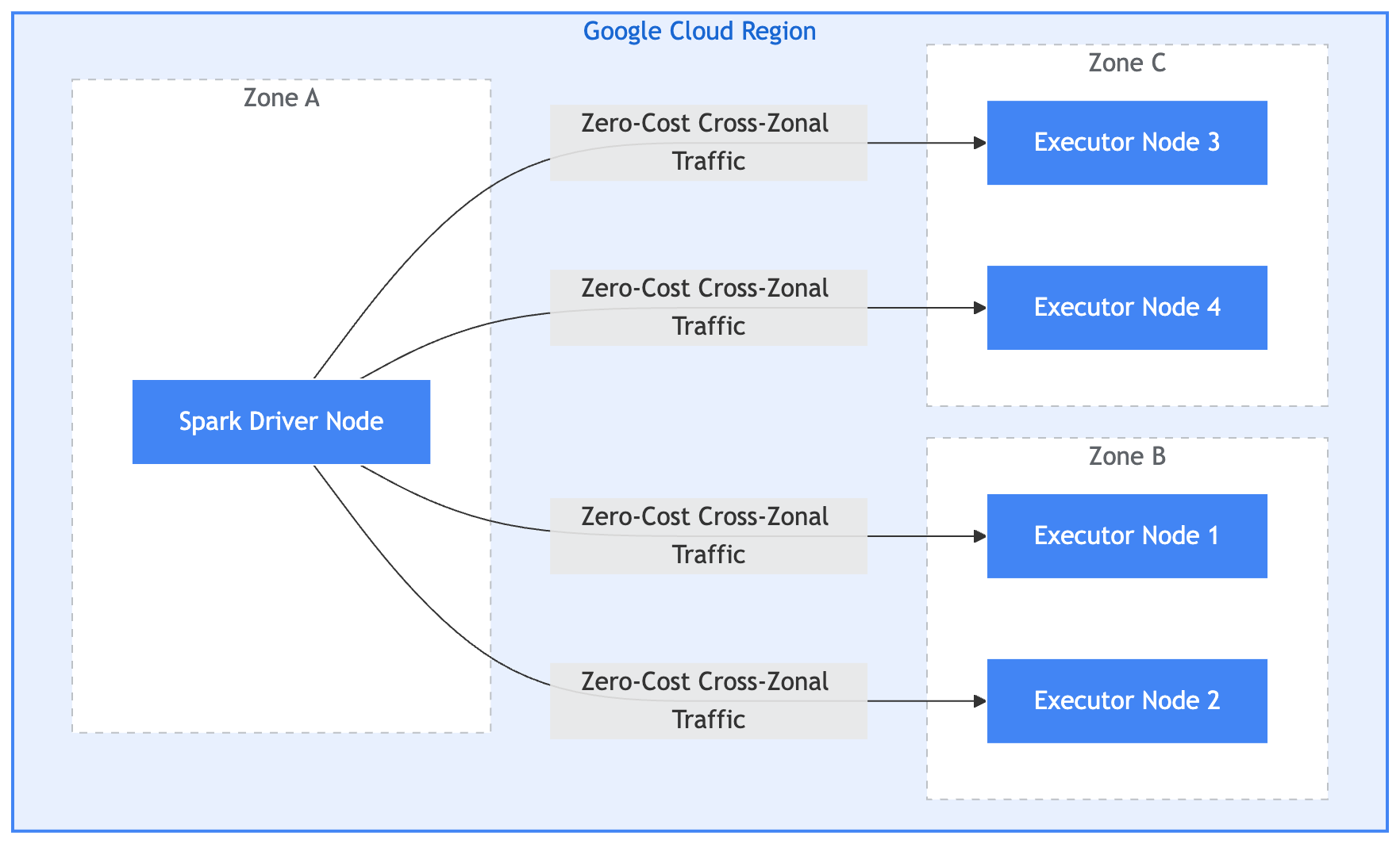
Enhanced multi-zonal support
To protect global enterprise workloads from zonal outages or hardware stockouts, the serverless Spark 3.0 runtime introduces enhanced multi-zonal support by default. The service can now automatically allocate execution nodes across multiple zones within a single region to help ensure obtainability.
Crucially, we do not charge for cross-zonal network traffic between nodes in a region, providing high availability without the traditional multi-zone tax. This is another benefit that you can realize by bringing your global Apache Spark workloads to Google Cloud.
Looking ahead
In addition to the above, we’re also continuing to innovate and push the boundaries of ease of use in areas such as history-based autotuning and goal based autoscaling.
Get started today
You can take advantage of these features today by specifying runtime_version: 3.0 in your batch workloads or interactive sessions. To run your first workload on serverless Spark, perform the following simple steps:
-
Enable the Managed Service for Apache Spark API.
-
If you aren’t the project owner, ask your project admin for the serverless Managed Service for Apache Spark Editor (
roles/dataproc.serverlessEditor) role on the project.
Now you’re ready to start running your workloads on the Serverless 3.0 runtime version. For more details, visit our updated documentation and access serverless Managed Service for Apache Spark in the Google Cloud console.

