
Managed Service for Apache Spark (ehemals Dataproc)
Die neue Art, Spark zu nutzen: einfacher, intelligenter, schneller
Führen Sie Apache Spark-Arbeitslasten serverlos oder mit verwalteten Clustern aus. Beschleunigen Sie die Entwicklung mit agentischen KI-Workflows und steigern Sie die Leistung mit der Lightning Engine.
Neukundinnen und Neukunden erhalten ein Startguthaben von 300 $, um den Managed Service for Apache Spark und andere Google Cloud-Produkte selbst auszuprobieren.
Apache Spark ist eine Marke der Apache Software Foundation.

Features
Branchenführende Leistung mit der Lightning Engine
Beschleunigen Sie umfangreiche ETL- und SQL-Arbeitslasten um bis zu 4,9‑mal im Vergleich zu Open-Source-Apache Spark – ohne Codeänderungen. Lightning Engine nutzt eine native C++-Engine für die vektorisierte Ausführung, intelligentes Caching und optimiertes spaltenbasiertes Shuffling. Kombinieren Sie dies mit der intelligenten automatischen Abstimmung von Spark, um die manuelle Abstimmung überflüssig zu machen, den Speicher zu optimieren und OOM-Fehler automatisch zu verhindern.
*Die Abfragen sind von den Standards TPC-DS und TPC-H abgeleitet
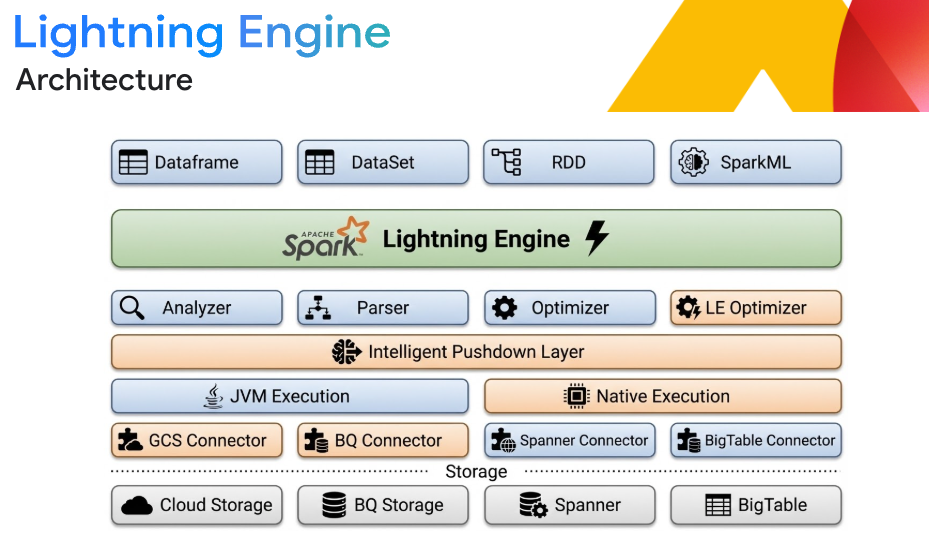
Flexible Interoperabilität von Lakehouses
Entwickeln Sie eine offene Lakehouse-Architektur, die für Unabhängigkeit von Engines sorgt. Daten in offenen Formaten wie Apache Iceberg direkt aus Google Cloud Storage verarbeiten. Nahtlose Integration in BigQuery und Knowledge Catalog (ehemals Dataplex) für einheitliche Analysen und Governance, die eine echte Interoperabilität mehrerer Engines ohne Übersetzungsebenen ermöglicht.
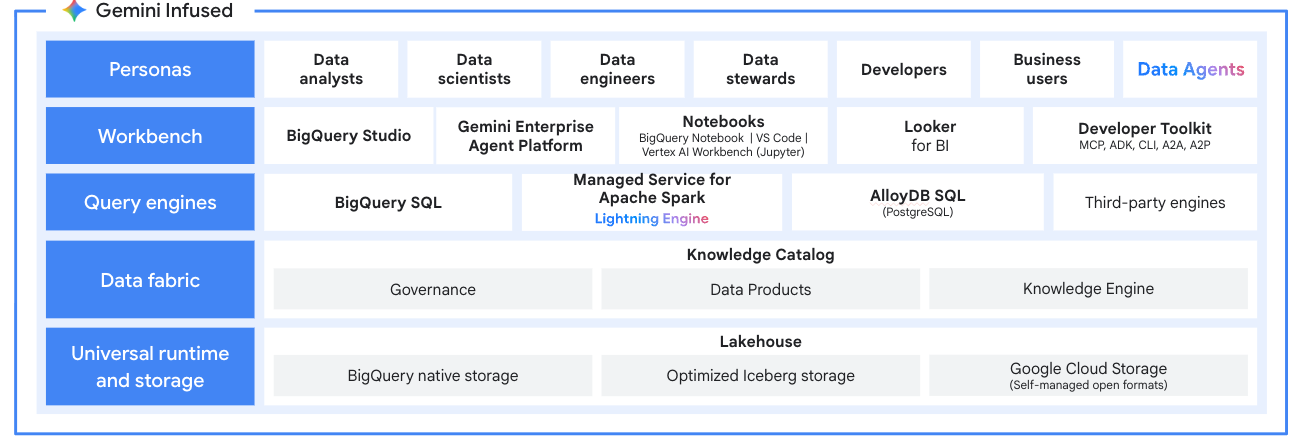
Einheitliche KI-basierte Entwicklungsumgebung
Mit Daten-Agenten, die nicht nur Fragen beantworten, sondern auch Maßnahmen ergreifen, können Sie Ihren Backlog abarbeiten. Beschleunigen Sie Ihren Workflow mit Gemini, das in die agentische VSCode-Erweiterung eingebunden ist, um die Produktivität von Spark-Arbeitslasten von der Entwicklung bis zur Produktion zu steigern. Sie können aber auch die IDE Ihrer Wahl verwenden. Nutzen Sie die Data Engineering- und Data Science-Agenten, um Data Wrangling zu automatisieren, Pipelines aus natürlicher Sprache zu erstellen und PySpark-Code zu generieren. Mit Gemini Cloud Assist können Sie Fehler in Spark-Jobs automatisch beheben. Sie können SQL und Spark in einem einzigen, einheitlichen KI-Notebook kombinieren.
Bereit für KI/ML auf Unternehmensniveau
Erstellen und operationalisieren Sie den gesamten Lebenszyklus des maschinellen Lernens. Beschleunigen Sie das Modelltraining und die Inferenz mit GPU-Unterstützung durch NVIDIA RAPIDS und vorkonfigurierten ML-Laufzeiten für PyTorch und XGBoost. Sie können die Lösung in das Google Cloud AI-Ökosystem einbinden, um End-to-End-MLOps zu orchestrieren und Assets mit der Gemini Enterprise Agent Platform Model Registry-Integration zu verwalten.
Sichere, skalierbare und nahtlose Migrationen
Ermöglichen Sie eine nahtlose Einbindung in Ihren Sicherheitsstatus mit IAM, VPC Service Controls und Kerberos. Mit den Vorlagen und Tools von Managed Service for Apache Spark können Sie Cloud- und Legacy-Spark-Arbeitslasten einfach migrieren. Sie können Arbeitslasten mit Unterstützung für Spark 2.x bis Spark 4.0 ohne sofortiges Code-Refactoring per Lift-and-Shift migrieren.
Effizienz für mehrere Mandanten und FinOps-Kontrollen
Ressourcennutzung maximieren und Kosten für ungenutzte Ressourcen reduzieren. Sie können mandantenfähige Spark-Cluster bereitstellen, die es bis zu 800 Nutzern ermöglichen, Rechenressourcen gemeinsam zu nutzen, während gleichzeitig eine strenge Daten- und Umgebungsisolierung aufrechterhalten wird. Mit der Skalierung auf null, der sekundengenauen Abrechnung und der Unterstützung von Spot-VMs für flexible Arbeitslasten haben Sie Ihre Kosten im Griff.
Offenes und flexibles Ökosystem
Vermeiden Sie die Anbieterbindung. Unsere verwalteten Cluster sind zwar für Apache Spark optimiert, unterstützen aber mehr als 30 Open-Source-Tools, darunter Apache Hadoop, Flink und Trino. Lässt sich nahtlos in Orchestratoren wie Managed Service for Apache Airflow einbinden und mit Kubernetes und Docker erweitern, um maximale Flexibilität zu erreichen.
Optionen der Bereitstellung
| Optionen der Bereitstellung | Sie haben die Wahl zwischen der detaillierten Steuerung verwalteter Cluster und der aufwandlosen Einfachheit einer serverlosen Umgebung – je nachdem, was für Ihre Arbeitslast am besten geeignet ist. | ||
|---|---|---|---|
| Bereitstellungsmodus: | Beschreibung: | Ideal für: | Bezahlen für: |
Serverlos | Spark-Jobs als Dienst Verwaltetes Spark, verwaltete Infrastruktur | Neue Pipelines, interaktive Analysen und Arbeitslasten mit Spitzen, bei denen ein Zero-Ops-Modell mit nutzungsabhängiger Abrechnung bevorzugt wird. | Ausführungszeit des Jobs |
Cluster | Spark-Cluster als Dienst Managed Spark, Ihre Infrastruktur | Migration von Legacy-Spark- oder OSS-Arbeitslasten, Ausführung persistenter Cluster oder umfangreiche Open-Source-Anpassungen erforderlich. | Cluster-Verfügbarkeit |
Optionen der Bereitstellung
Sie haben die Wahl zwischen der detaillierten Steuerung verwalteter Cluster und der aufwandlosen Einfachheit einer serverlosen Umgebung – je nachdem, was für Ihre Arbeitslast am besten geeignet ist.
Serverlos
Spark-Jobs als Dienst
Verwaltetes Spark, verwaltete Infrastruktur
Neue Pipelines, interaktive Analysen und Arbeitslasten mit Spitzen, bei denen ein Zero-Ops-Modell mit nutzungsabhängiger Abrechnung bevorzugt wird.
Ausführungszeit des Jobs
Cluster
Spark-Cluster als Dienst
Managed Spark, Ihre Infrastruktur
Migration von Legacy-Spark- oder OSS-Arbeitslasten, Ausführung persistenter Cluster oder umfangreiche Open-Source-Anpassungen erforderlich.
Cluster-Verfügbarkeit
Funktionsweise
Mit serverlosen oder verwalteten Clustern ohne Betriebsaufwand wird Spark einfacher. Mit Gemini in Ihrer bevorzugten IDE können Sie dank agentischer KI die PySpark-Entwicklung beschleunigen. Mit der Lightning Engine können Sie Jobs schneller ausführen und mit Knowledge Catalog eine einheitliche Governance für Ihr offenes Lakehouse aufrechterhalten.
Mit serverlosen oder verwalteten Clustern ohne Betriebsaufwand wird Spark einfacher. Mit Gemini in Ihrer bevorzugten IDE können Sie dank agentischer KI die PySpark-Entwicklung beschleunigen. Mit der Lightning Engine können Sie Jobs schneller ausführen und mit Knowledge Catalog eine einheitliche Governance für Ihr offenes Lakehouse aufrechterhalten.
Data Engineering im großen Maßstab
Automatisierte ETL-Pipelines
Automatisierte ETL-Pipelines
Erstellen Sie robuste, ereignisgesteuerte Spark-ETL-Pipelines, die bei Bedarf automatisch skaliert werden. Nutzen Sie die serverlose Ausführung für Arbeitslasten mit Spitzen oder verwaltete Cluster für dauerhafte Jobs. Mit Workflow-Vorlagen können Sie Ihre wichtigsten Datenverarbeitungsjobs von Anfang bis Ende automatisieren.


Tutorials, Kurzanleitungen und Labs
Automatisierte ETL-Pipelines
Automatisierte ETL-Pipelines
Erstellen Sie robuste, ereignisgesteuerte Spark-ETL-Pipelines, die bei Bedarf automatisch skaliert werden. Nutzen Sie die serverlose Ausführung für Arbeitslasten mit Spitzen oder verwaltete Cluster für dauerhafte Jobs. Mit Workflow-Vorlagen können Sie Ihre wichtigsten Datenverarbeitungsjobs von Anfang bis Ende automatisieren.
Data Science und Machine Learning
Interaktive Datenwissenschaft
Interaktive Datenwissenschaft
Data Scientists können Daten untersuchen und Spark ML-Modelle iterativ verbessern. Vereinheitlichen Sie SQL und Spark mit Gemini über die VSCode-Agentenerweiterung oder Ihre bevorzugte IDE und wechseln Sie nahtlos von der Datenexploration zur Modellentwicklung mit PySpark und serverloser Ausführung. Hängen Sie GPUs mit einem einzigen Befehl an.


Tutorials, Kurzanleitungen und Labs
Interaktive Datenwissenschaft
Interaktive Datenwissenschaft
Data Scientists können Daten untersuchen und Spark ML-Modelle iterativ verbessern. Vereinheitlichen Sie SQL und Spark mit Gemini über die VSCode-Agentenerweiterung oder Ihre bevorzugte IDE und wechseln Sie nahtlos von der Datenexploration zur Modellentwicklung mit PySpark und serverloser Ausführung. Hängen Sie GPUs mit einem einzigen Befehl an.
Lakehouse-Modernisierung
Offenes Data Lakehouse
Offenes Data Lakehouse
Verwenden Sie Managed Service for Apache Spark als Verarbeitungs-Engine für Ihr modernes Data Lakehouse. Verarbeiten Sie Daten in offenen Formaten wie Apache Iceberg direkt aus Ihrem Data Lake, um Datensilos zu vermeiden. Einbindung in BigQuery und Lakehouse for Apache Iceberg für eine einheitliche, Multi-Engine-Analyseplattform

Tutorials, Kurzanleitungen und Labs
Offenes Data Lakehouse
Offenes Data Lakehouse
Verwenden Sie Managed Service for Apache Spark als Verarbeitungs-Engine für Ihr modernes Data Lakehouse. Verarbeiten Sie Daten in offenen Formaten wie Apache Iceberg direkt aus Ihrem Data Lake, um Datensilos zu vermeiden. Einbindung in BigQuery und Lakehouse for Apache Iceberg für eine einheitliche, Multi-Engine-Analyseplattform
Preise
| Preise für Managed Service for Apache Spark | Die Preise richten sich nach dem von Ihnen gewählten Bereitstellungsmodell. Bei serverlosen Diensten wird die Ausführung von Jobs abgerechnet, bei Clustern die zugrunde liegenden Rechenressourcen und die Betriebszeit. | |
|---|---|---|
| Bereitstellungsmodus: | Wofür Sie zahlen: | Gezahlter Betrag: |
Serverlos | Sie zahlen nur für das, was Sie tatsächlich nutzen. Sekundengenaue Abrechnung für Rechenleistung, GPUs und Shuffle-Speicher. Durch die automatische Skalierung auf null zahlen Sie nie für ungenutzte Kapazitäten. | Ab 0,06 $ pro DCU-Stunde |
Premium-Stufe und Beschleuniger: Mit der Lightning Engine können Sie die Leistung um das bis zu 4,9‑fache steigern oder NVIDIA-GPUs für KI-/ML-Arbeitslasten anhängen. | Ab 0,089 $ pro DCU-Stunde Serverlose Premium-Stufe | |
Cluster | Für Clusterbetriebszeit bezahlen Abrechnung der zugrunde liegenden Compute Engine-Ressourcen zuzüglich einer Pauschalgebühr für die Verwaltung. Nutzen Sie Spot-VMs und die Skalierung auf null, um Kosten zu optimieren. | Ab 0,01 $ pro vCPU/Stunde Verwaltungsgebühr |
Lightning Engine-Add-on: Bringen Sie bahnbrechende Leistung in Ihre Cluster. Bis zu 4,9‑mal schnellere Ausführung als mit Open-Source-Spark. | Ab 0,0025 $ pro vCPU/Stunde | |
Weitere Informationen zu den Preisen für Managed Service for Apache Spark. Vollständige Preisinformationen
Preise für Managed Service for Apache Spark
Die Preise richten sich nach dem von Ihnen gewählten Bereitstellungsmodell. Bei serverlosen Diensten wird die Ausführung von Jobs abgerechnet, bei Clustern die zugrunde liegenden Rechenressourcen und die Betriebszeit.
Serverlos
Sie zahlen nur für das, was Sie tatsächlich nutzen. Sekundengenaue Abrechnung für Rechenleistung, GPUs und Shuffle-Speicher. Durch die automatische Skalierung auf null zahlen Sie nie für ungenutzte Kapazitäten.
Starting at
0,06 $ pro DCU-Stunde
Premium-Stufe und Beschleuniger:
Mit der Lightning Engine können Sie die Leistung um das bis zu 4,9‑fache steigern oder NVIDIA-GPUs für KI-/ML-Arbeitslasten anhängen.
Starting at
0,089 $ pro DCU-Stunde
Serverlose Premium-Stufe
Cluster
Für Clusterbetriebszeit bezahlen Abrechnung der zugrunde liegenden Compute Engine-Ressourcen zuzüglich einer Pauschalgebühr für die Verwaltung. Nutzen Sie Spot-VMs und die Skalierung auf null, um Kosten zu optimieren.
Starting at
0,01 $ pro vCPU/Stunde
Verwaltungsgebühr
Lightning Engine-Add-on:
Bringen Sie bahnbrechende Leistung in Ihre Cluster. Bis zu 4,9‑mal schnellere Ausführung als mit Open-Source-Spark.
Starting at
0,0025 $ pro vCPU/Stunde
Weitere Informationen zu den Preisen für Managed Service for Apache Spark. Vollständige Preisinformationen
Anwendungsszenario
Erfolgsgeschichten von Kunden

„Einige unserer Qualitätsprüfungen dauerten vorher 11 Stunden, jetzt nur noch wenige Minuten.“
Michael Manos, Chief Technology Officer von Dun & Bradstreet
Durch die Migration zu Google Cloud konnte Dun & Bradstreet die Geschwindigkeit der Datenflüsse erheblich steigern. Die Prozesse zur Qualitätsprüfung dauern nun nur noch Minuten statt Stunden und die Zeit, die für die Veröffentlichung neuer Daten benötigt wird, wurde halbiert. Diese solide Datengrundlage ermöglicht es Dun & Bradstreet außerdem, das gesamte Potenzial des Google Cloud-Ökosystems zu nutzen, einschließlich modernster Daten- und KI-Technologien.



Die Vorteile von Managed Service for Apache Spark
Produktivität ohne Betriebsaufwand dank flexibler Bereitstellungsoptionen. Wählen Sie eine serverlose Ausführung oder vollständig verwaltete Cluster, um den Infrastrukturaufwand und die manuelle Abstimmung zu reduzieren.
Entwicklung agentischer KI. Beschleunigen Sie Ihren Workflow mit Gemini, das in die agentische VSCode-Erweiterung eingebunden ist, oder mit Ihrer bevorzugten IDE sowie mit Datenagenten, die PySpark-Programmierung, Datenaufbereitung und Fehlerbehebung in einem einheitlichen Notebook automatisieren.
Branchenführende Leistung mit der Lightning Engine. Beschleunigen Sie Ihre anspruchsvollsten ETL- und Data-Science-Arbeitslasten um bis zu 4,9-mal und senken Sie so Ihre Gesamtbetriebskosten erheblich.










Zusätzliche Ressourcen:
FAQs
Was ist mit Dataproc und Serverless Spark passiert?
Um die Nutzung zu vereinfachen, haben wir Dataproc und Google Cloud Serverless for Apache Spark zu einem einzigen Produkt zusammengefasst: Managed Service for Apache Spark. Sie erhalten genau dieselben leistungsstarken Funktionen, können aber jetzt einfach über eine einheitliche Oberfläche Ihr bevorzugtes Bereitstellungsmodell auswählen – serverlos ohne Betriebsaufwand oder vollständig verwaltete Cluster. Vergleichen sie die beiden Bereitstellungsmodi.
Wann sollte ich serverlose Cluster und wann verwaltete Cluster verwenden?
Serverlos ist die richtige Wahl, wenn Sie sich ganz auf den Code konzentrieren möchten, ohne sich um die Infrastruktur kümmern zu müssen. Das ist ideal für neue Pipelines und Ad-hoc-Analysen. Wählen Sie verwaltete Cluster, wenn Sie eine detaillierte Kontrolle benötigen, Legacy- oder Cloud-Spark- oder andere OSS-Arbeitslasten migrieren oder persistente Cluster mit verschiedenen Open-Source-Tools benötigen.
Was ist die Lightning Engine?
Lightning Engine ist die native, hochoptimierte Ausführungs-Engine von Google Cloud. Es wurde mit C++-Bibliotheken entwickelt und optimiert jede Ebene – von Speicherkonnektoren mit hohem Durchsatz bis hin zu intelligentem Caching. Geboten wird eine bis zu 4,9‑mal höhere Leistung im Vergleich zu Standard-Spark und ein bis zu 2‑mal besseres Preis-Leistungs-Verhältnis als die führende Hochgeschwindigkeits-Spark-Alternative. Lightning Engine lässt sich nahtlos in Ihre serverlosen oder Cluster-Bereitstellungen einbinden, ohne dass Codeänderungen erforderlich wären.
Muss ich meine eigenen ML-Bibliotheken wie PyTorch installieren?
Nein. Wenn Sie KI-/ML-Arbeitslasten ausführen, können Sie unsere vorkonfigurierten ML-Laufzeiten verwenden. Diese Umgebungen enthalten gängige Bibliotheken wie PyTorch, XGBoost und scikit-learn sowie optimierte NVIDIA-GPU-Treiber, sodass keine komplexe Einrichtung erforderlich ist.
Ist Managed Service for Apache Spark vollständig mit Open-Source-Lösungen kompatibel?
Ja. Wir bieten eine 100 % Open-Source-kompatible Apache Spark-Umgebung. Sie können Ihren vorhandenen Spark-Code ohne Änderungen ausführen, wodurch die vollständige Portabilität der Arbeitslasten gewährleistet und ein Vendor Lock-in vermieden wird.
Wie unterstützt Gemini AI die Spark-Entwicklung?
Gemini AI kann direkt in die IDE Ihrer Wahl eingebunden werden und als KI-Copilot fungieren. Sie können damit schneller PySpark-Code schreiben und debuggen. Gemini Cloud Assist bietet eine automatisierte Ursachenanalyse und Empfehlungen zur Fehlerbehebung für fehlgeschlagene Jobs.
Kann ich mit diesem Dienst ein offenes Data Lakehouse erstellen?
Selbstverständlich. Managed Service for Apache Spark ist eine zentrale Verarbeitungs-Engine für das offene Lakehouse von Google Cloud. Sie können Daten in offenen Formaten wie Apache Iceberg direkt aus Cloud Storage verarbeiten und nahtlos in BigQuery und Knowledge Catalog für Apache Iceberg einbinden.
Wie funktionieren die Preisstufen „Standard“ und „Premium“?
Die Standard- und Premium-Stufen gelten derzeit nur für serverlose Bereitstellungen. Die Standard-Stufe ist ideal für kostengünstige Batchverarbeitung und ETL für allgemeine Zwecke. Die Premium-Stufe ist für anspruchsvolle Arbeitslasten konzipiert. Mit der Lightning Engine erzielen Sie eine 4,9‑mal höhere Leistung als mit Open-Source-Apache Spark und haben Zugriff auf GPU-beschleunigte KI-/ML-Funktionen.











